

PowerInfer は、消費者グレードのハードウェアで AI を実行する効率を向上させます
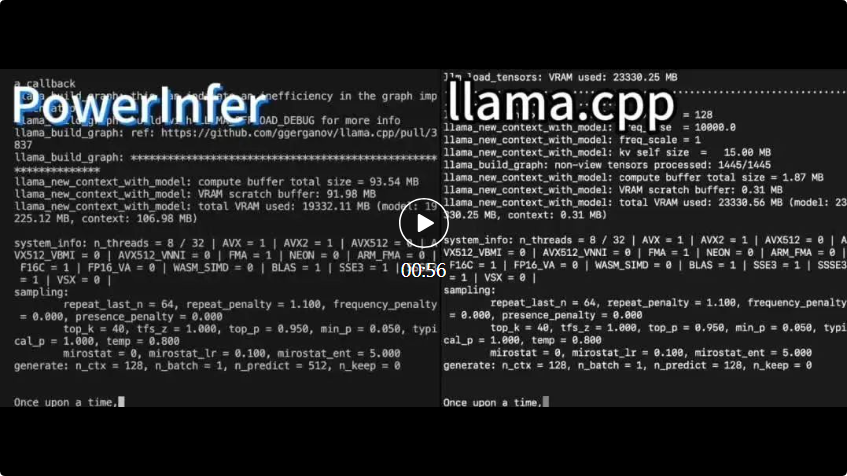 PowerInfer と llama.cpp はどちらも同じハードウェア上で実行され、RTX 4090 の VRAM を最大限に活用します。
PowerInfer と llama.cpp はどちらも同じハードウェア上で実行され、RTX 4090 の VRAM を最大限に活用します。 
PowerInfer は 1 日で 2,000 個のスターを獲得することに成功しました
この研究を見た後、ネチズンは興奮を表明しました。現在、1 枚のカード 4090 で 175B の大規模モデルを実行できるようになりました、それはもはや単なる夢ではありません
 PowerInfer アーキテクチャ
PowerInfer アーキテクチャ
PowerInfer 設計の鍵は高度な局所性を活用することですLLM 推論に固有の性質であり、ニューロン活性化
におけるべき乗則分布によって特徴付けられます。この分布は、ホット ニューロンと呼ばれるニューロンの小さなサブセットが入力全体にわたって一貫して活性化するのに対し、コールド ニューロンの大部分は特定の入力に応じて変化することを示唆しています。 PowerInfer は、このメカニズムを利用して GPU-CPU ハイブリッド推論エンジンを設計します。以下の図 7 を参照してください。これは、オフライン コンポーネントとオンライン コンポーネントを含む PowerInfer のアーキテクチャの概要を示しています。オフライン コンポーネントは、ホット ニューロンとコールド ニューロンを区別しながら、LLM の活性化スパース性を処理する役割を果たします。オンライン段階では、推論エンジンは両方のタイプのニューロンを GPU と CPU にロードし、実行時に低遅延の方法で LLM リクエストを処理します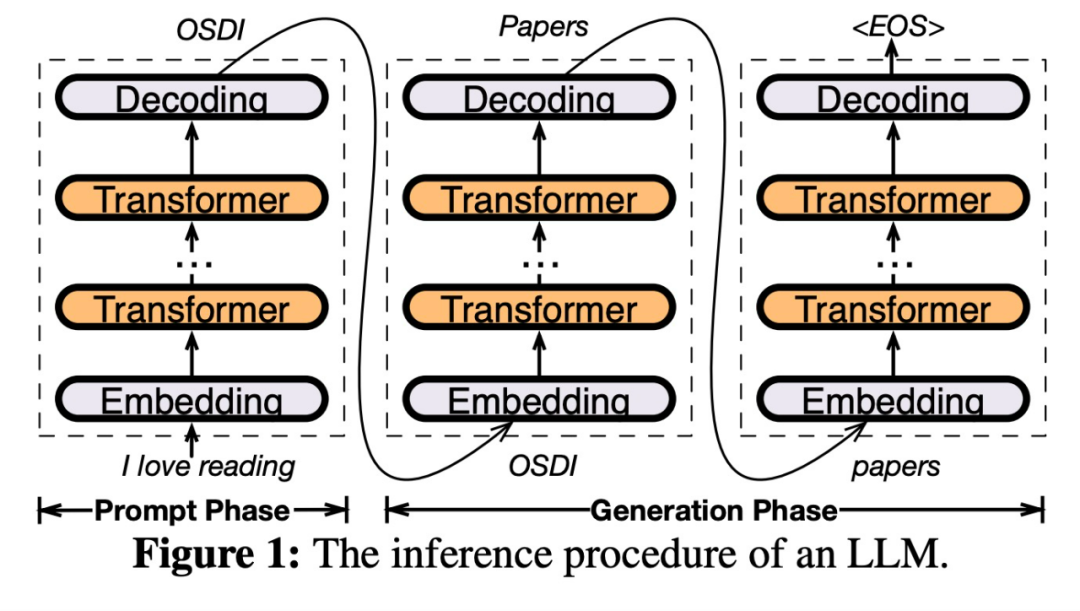
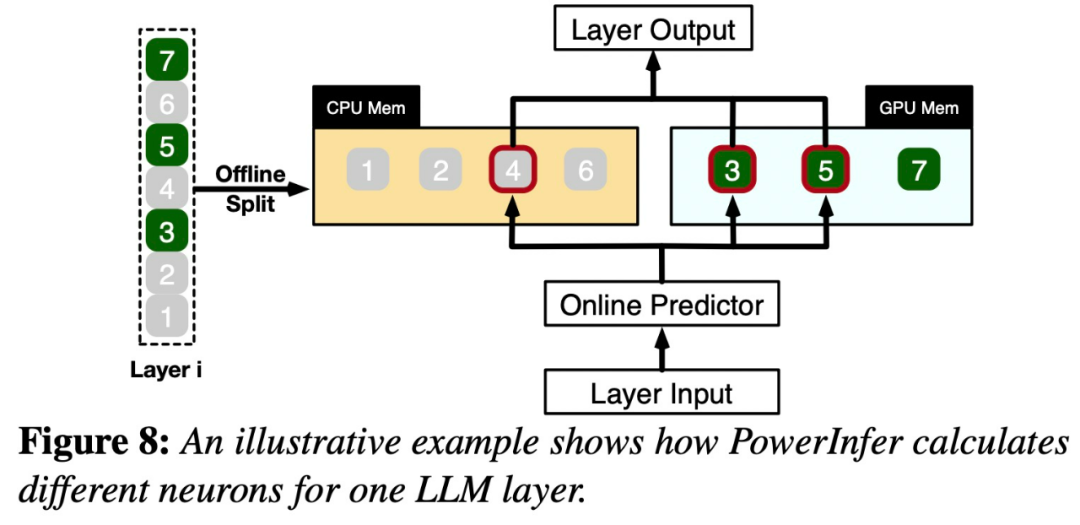
# #図 8 は、PowerInfer がどのように機能するかを示していますGPU と CPU 処理ニューロン間のレイヤーを調整して機能します。 PowerInfer はオフライン データを通じてニューロンを分類し、アクティブなニューロン (インデックス 3、5、7 など) を GPU メモリに割り当て、他のニューロンを CPU メモリに割り当てます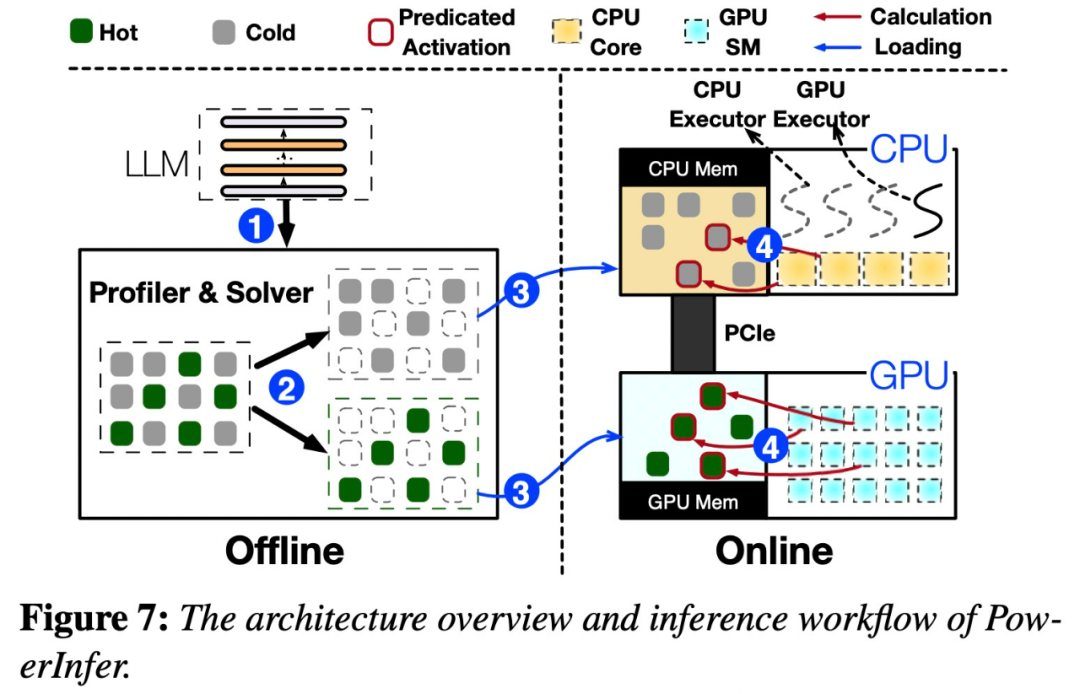
入力が受信されると、予測子は現在の層で活性化される可能性のあるニューロンを特定します。オフライン統計分析を通じて特定された熱活性化ニューロンは、実行時の実際の活性化動作と一致しない可能性があることに注意してください。たとえば、ニューロン 7 は熱的に活性化されているとラベル付けされていますが、実際にはそうではありません。 CPU と GPU は、すでに活性化されているニューロンを処理し、活性化されていないニューロンを無視します。 GPU はニューロン 3 と 5 の計算を担当し、CPU はニューロン 4 を処理します。ニューロン 4 の計算が完了すると、その出力は結果統合のために GPU に送信されます。
元の意味を変えずに内容を書き換えるために、言語を中国語で書き直す必要があります。元の文を表示する必要はありません
研究は、さまざまなパラメータを備えた OPT モデルを使用して実施されました 元の意味を変更せずに内容を書き直すには、言語が次のことを必要とします中国語に書き換えられます。原文の提示は不要で、パラメータ範囲は6.7B~175B、Falcon(ReLU)-40B、LLaMA(ReGLU)-70Bモデルも含まれます。 175B パラメータ モデルのサイズが GPT-3 モデル に匹敵することは注目に値します。
この記事では、PowerInfer と最先端のネイティブ LLM 推論フレームワークである llama.cpp も比較します。比較を容易にするために、この調査では OPT モデルをサポートするために llama.cpp も拡張しました
この記事の焦点が低遅延設定であることを考慮して、評価指標にはエンドツーエンドの生成速度という観点が採用されています。 1 秒あたりに生成されるトークンの数 (トークン/秒) 定量化用です。
この調査では、まず PowerInfer と llama.cpp のエンドツーエンドの推論パフォーマンスをバッチ サイズ 1
# で比較します。 ##NVIDIA RTX 4090 On PC-High を搭載したマシンでの、さまざまなモデルと入出力構成の生成速度を図 10 に示します。平均して、PowerInfer は 8.32 トークン/秒、最大 16.06 トークン/秒の生成速度を達成します。これは、llama.cpp よりも大幅に優れており、llama.cpp の 7.23 倍、Falcon-40B## の 11.69 倍です。#出力トークンの数が増加するにつれて、生成フェーズが全体の推論時間においてより重要な役割を果たすため、PowerInfer のパフォーマンス上の利点がより明らかになります。この段階では、少数のニューロンが CPU と GPU の両方でアクティブ化されるため、llama.cpp と比較して不必要な計算が削減されます。たとえば、OPT-30B の場合、生成されたトークンごとにアクティブになるニューロンはわずか約 20% であり、そのほとんどは GPU で処理されます。これが PowerInfer ニューロン対応推論の利点です。
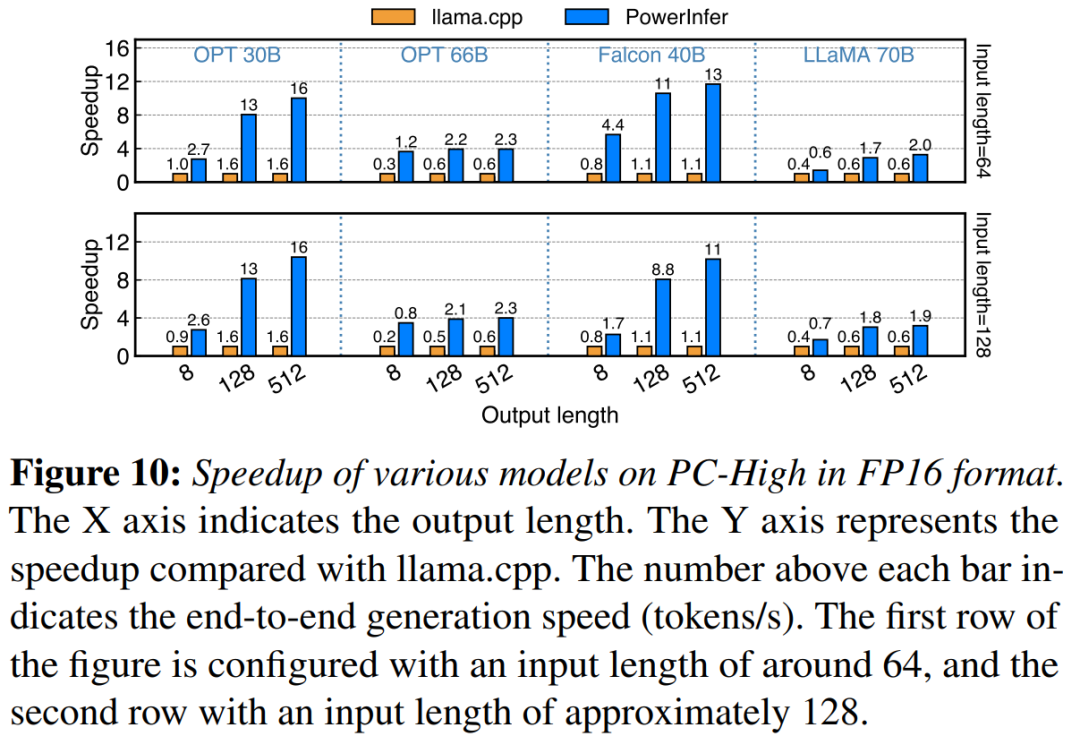 図 11 に示すように、PowerInfer は PC-Low にもかかわらず、平均 5.01 倍、ピーク 7.06 倍の速度向上という大幅なパフォーマンス向上を達成しました。ただし、これらの改善は PC-High に比べて小さく、主に PC-Low の 11GB GPU メモリ制限によるものです。この制限は、特に約 30B 以上のパラメーターを持つモデルの場合、GPU に割り当てることができるニューロンの数に影響し、その結果、多数のアクティブ化されたニューロンを処理するために CPU への依存度が高くなります
図 11 に示すように、PowerInfer は PC-Low にもかかわらず、平均 5.01 倍、ピーク 7.06 倍の速度向上という大幅なパフォーマンス向上を達成しました。ただし、これらの改善は PC-High に比べて小さく、主に PC-Low の 11GB GPU メモリ制限によるものです。この制限は、特に約 30B 以上のパラメーターを持つモデルの場合、GPU に割り当てることができるニューロンの数に影響し、その結果、多数のアクティブ化されたニューロンを処理するために CPU への依存度が高くなります
#図 12 は、PowerInfer と llama.cpp の間の CPU と GPU 間のニューロン負荷分散を示しています。特に、PC-High では、PowerInfer は GPU のニューロン負荷シェアを平均 20% から 70% に大幅に増加させます。これは、GPU が活性化されたニューロンの 70% を処理していることを示しています。ただし、モデルのメモリ要件が GPU の容量をはるかに超える場合 (11GB 2080Ti GPU で 60GB モデルを実行する場合など)、GPU のニューロン負荷は 42% に減少します。この減少は、GPU のメモリが限られていることによるもので、アクティブ化されたニューロンすべてを収容するには十分ではないため、CPU はニューロンの一部を計算する必要があります。図13は、PowerInferの効果的なサポートINT4量子化圧縮LLMの使用を示す。 PC-High では、PowerInfer の平均応答速度は 13.20 トークン/秒、ピーク応答速度は 29.08 トークン/秒です。 llama.cpp と比較すると、平均速度向上は 2.89 倍、最大速度向上は 4.28 倍です。 PC-Low では、平均速度向上は 5.01 倍、ピークは 8.00 倍です。量子化によりメモリ要件が軽減されるため、PowerInfer はより大規模なモデルをより効率的に管理できるようになります。たとえば、PC-High で OPT-175B モデルを使用するには、元の意味を変えずに内容を書き直すために、言語を中国語に書き直す必要がありました。元の文に登場する必要はありませんが、PowerInfer は 1 秒あたりほぼ 2 トークンに達し、llama.cpp を 2.66 倍上回ります。 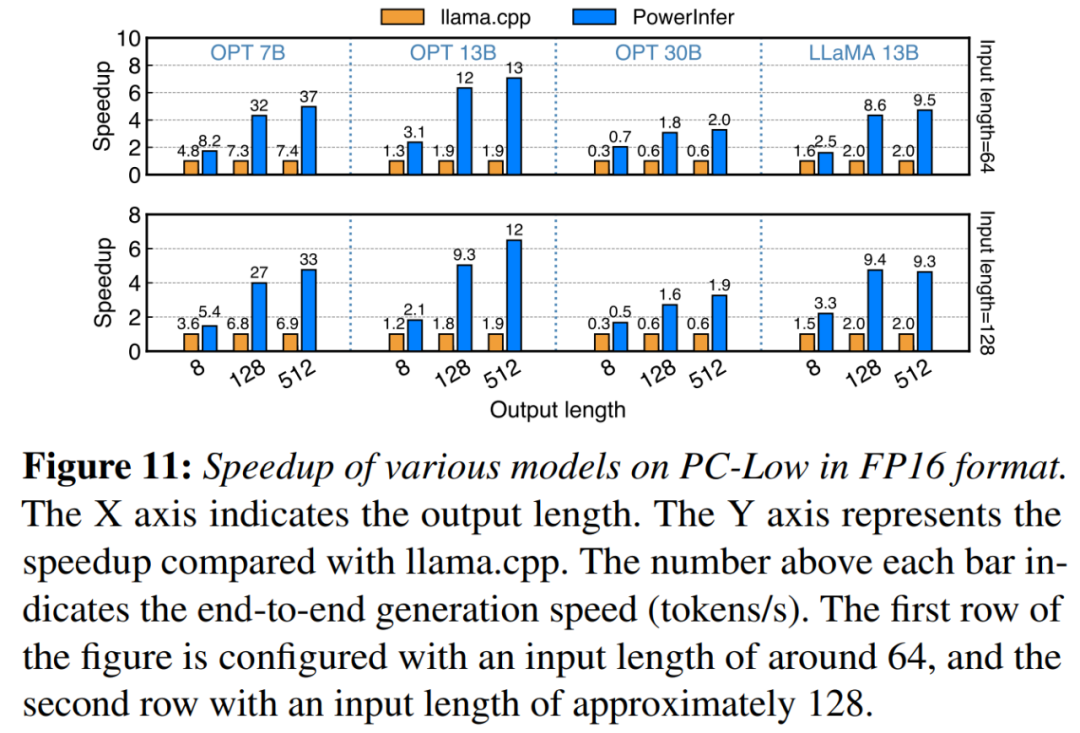
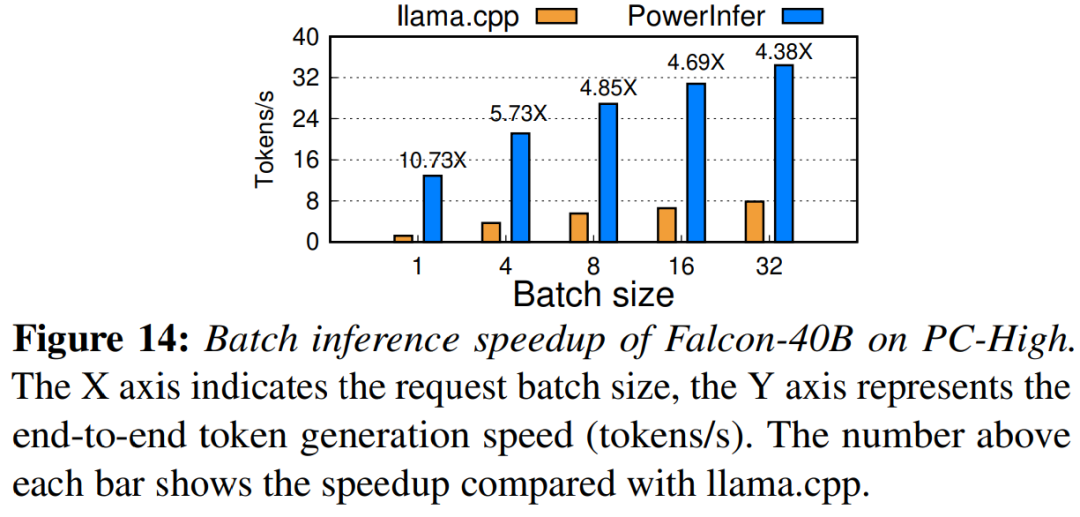
最後に、この研究では、さまざまなバッチ サイズでの PowerInfer のエンドツーエンド推論パフォーマンスも評価しました。図 14 に示すように、バッチ サイズが 32 未満の場合、PowerInfer は大きな利点を示し、llama と比較して平均パフォーマンスが 6.08 倍向上しました。バッチ サイズが増加すると、PowerInfer による高速化は減少します。ただし、バッチ サイズを 32 に設定しても、PowerInfer は依然として大幅な高速化を維持します。
参考リンク: https://weibo.com/1727858283 / NxZ0Ttdnz
詳細については、元の論文を参照してください
以上が4090 ジェネレーター: A100 プラットフォームと比較して、トークン生成速度はわずか 18% 未満であり、推論エンジンへの送信は熱い議論を獲得しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



