

新しいパスの探索 - IO 待機の診断ツール

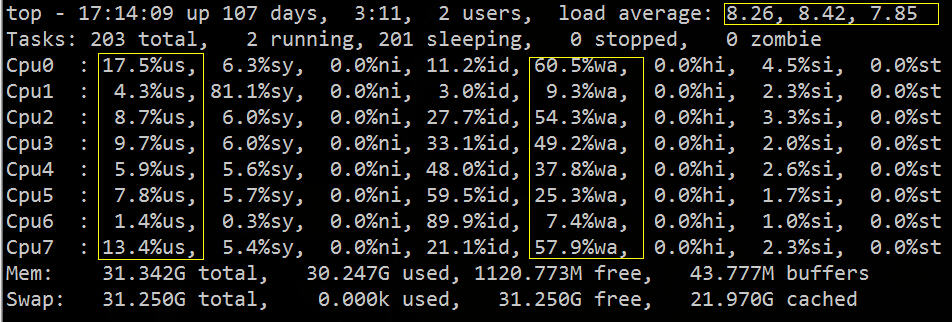
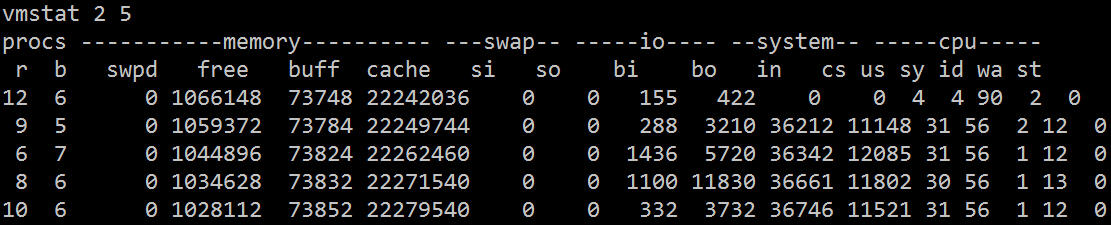
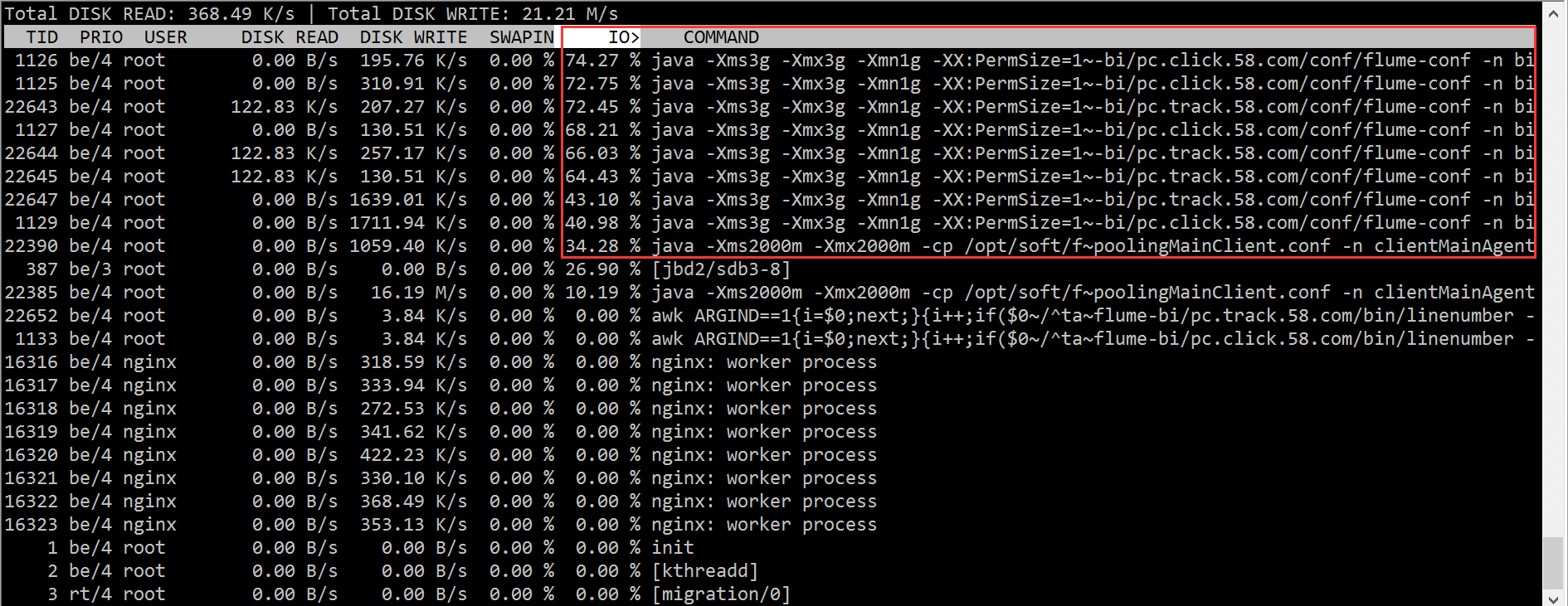
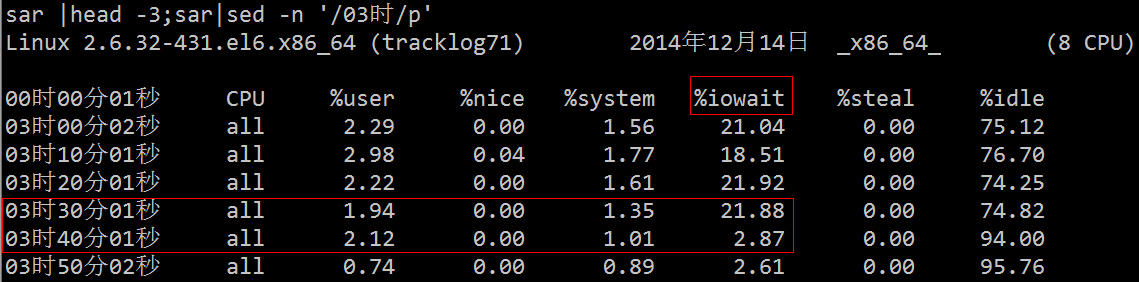
| 最近、ログのリアルタイム同期を行っています。オンラインにする前に、オンライン ログ ストレス テストを 1 回だけ実行しました。メッセージ キュー、クライアント、ローカル マシンには問題はありませんでしたが、 2 番目のログがアップロードされた後、次のような質問が来るとは予想していませんでした: |

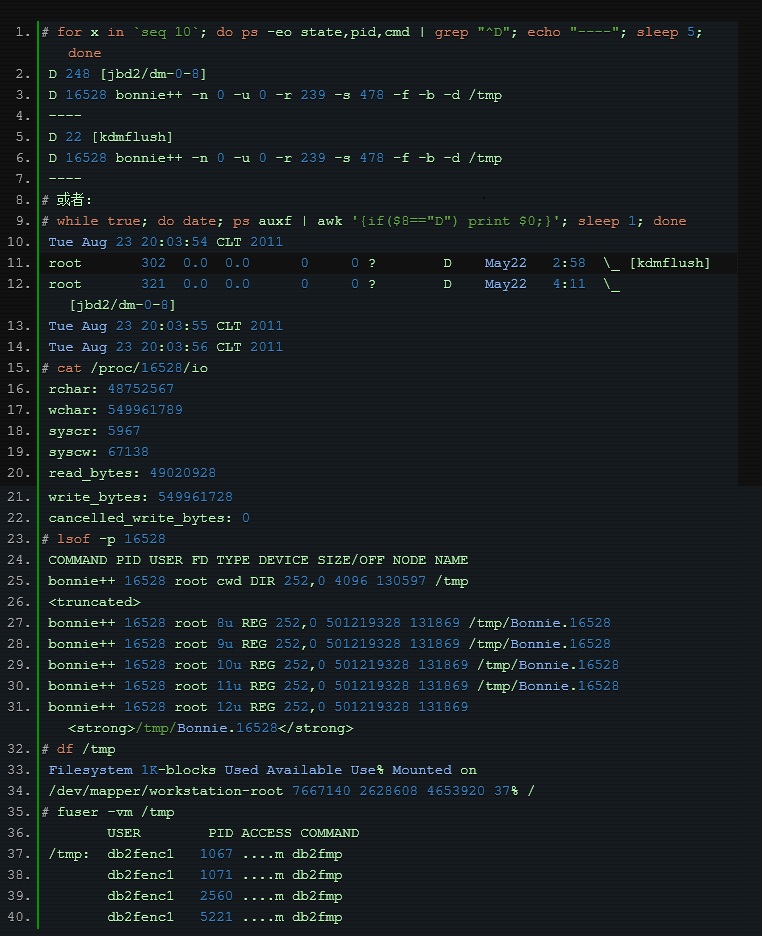
以上が新しいパスの探索 - IO 待機の診断ツールの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1318
25
1269
29
1248
24
14
1423
52
1318
25
1269
29
1248
24

 Linuxアーキテクチャ:5つの基本コンポーネントを発表します
Apr 20, 2025 am 12:04 AM
Linuxアーキテクチャ:5つの基本コンポーネントを発表します
Apr 20, 2025 am 12:04 AM
Linuxシステムの5つの基本コンポーネントは次のとおりです。1。Kernel、2。Systemライブラリ、3。Systemユーティリティ、4。グラフィカルユーザーインターフェイス、5。アプリケーション。カーネルはハードウェアリソースを管理し、システムライブラリは事前コンパイルされた機能を提供し、システムユーティリティはシステム管理に使用され、GUIは視覚的な相互作用を提供し、アプリケーションはこれらのコンポーネントを使用して機能を実装します。
 GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
GITの倉庫アドレスを確認する方法
Apr 17, 2025 pm 01:54 PM
gitリポジトリアドレスを表示するには、次の手順を実行します。1。コマンドラインを開き、リポジトリディレクトリに移動します。 2。「git remote -v」コマンドを実行します。 3.出力と対応するアドレスでリポジトリ名を表示します。
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
NotePadはJavaコードを直接実行することはできませんが、他のツールを使用することで実現できます。コマンドラインコンパイラ(Javac)を使用してByteCodeファイル(filename.class)を生成します。 Javaインタープリター(Java)を使用して、バイトコードを解釈し、コードを実行し、結果を出力します。
 コードを書いた後に崇高に実行する方法
Apr 16, 2025 am 08:51 AM
コードを書いた後に崇高に実行する方法
Apr 16, 2025 am 08:51 AM
Sublimeでコードを実行するには6つの方法があります。ホットキー、メニュー、ビルドシステム、コマンドライン、デフォルトビルドシステムの設定、カスタムビルドコマンド、プロジェクト/ファイルを右クリックして個々のファイル/プロジェクトを実行します。ビルドシステムの可用性は、崇高なテキストのインストールに依存します。
 Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な目的は何ですか?
Apr 16, 2025 am 12:19 AM
Linuxの主な用途には、1。Serverオペレーティングシステム、2。EmbeddedSystem、3。Desktopオペレーティングシステム、4。開発およびテスト環境。 Linuxはこれらの分野で優れており、安定性、セキュリティ、効率的な開発ツールを提供します。
 Laravelインストールコード
Apr 18, 2025 pm 12:30 PM
Laravelインストールコード
Apr 18, 2025 pm 12:30 PM
Laravelをインストールするには、これらの手順を順番に進みます。コンポーザー(MacOS/LinuxとWindows用)インストールLaravelインストーラーをインストールします。
 GITソフトウェアのインストール
Apr 17, 2025 am 11:57 AM
GITソフトウェアのインストール
Apr 17, 2025 am 11:57 AM
GITソフトウェアのインストールには、次の手順が含まれています。インストールパッケージをダウンロードしてインストールパッケージを実行して、インストール構成gitインストールgitバッシュ(Windowsのみ)を確認します
 崇高なPythonを実行する方法
Apr 16, 2025 am 08:54 AM
崇高なPythonを実行する方法
Apr 16, 2025 am 08:54 AM
崇高なテキストでPythonスクリプトを実行する方法:崇高なテキストにPythonインタープリター構成インタープリターパスをインストールしますCtrl B(Windows/Linux)またはCMD B(MACOS)にインタラクティブコンソールが必要な場合は、Ctrl \(Windows/Linux)またはCMD \(MACOS)を押します
