

Python プログラミングの歴史的進化

| プログラミングの道を歩み始めたら、コーディングの問題を理解していないと、キャリアを通じてその問題が幽霊のように付きまとうことになり、さまざまな超自然的な出来事が次から次へと続いて尾を引くことになります。プログラマーの最後まで戦う精神を発揮してこそ、コーディングの問題によるトラブルを完全になくすことができます。 |
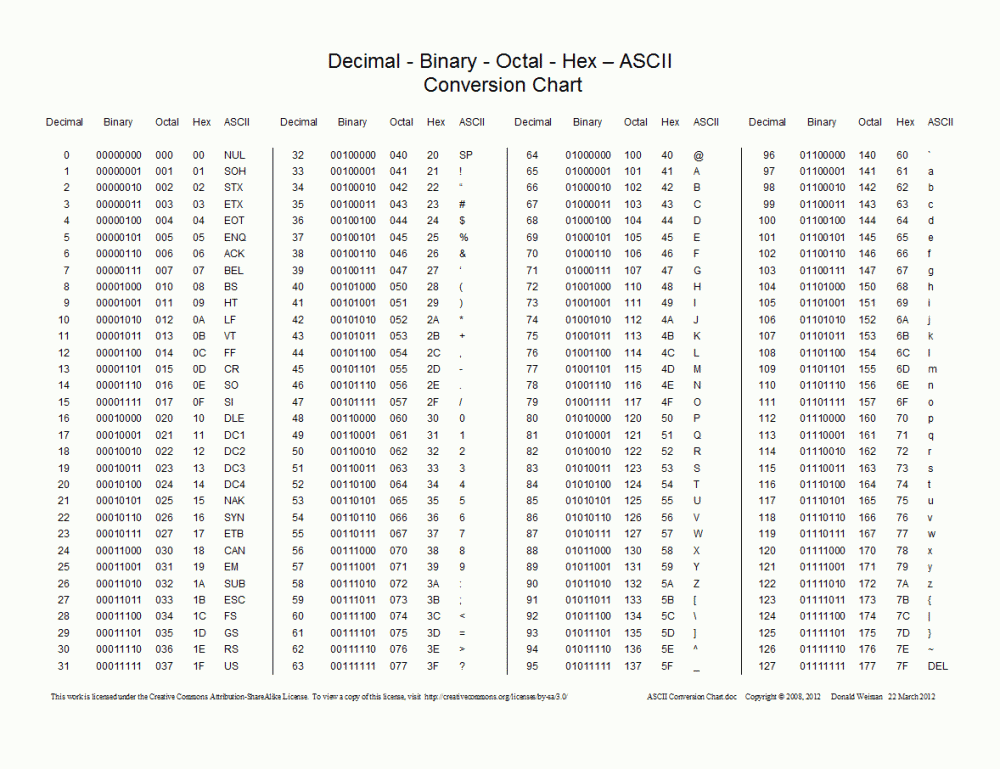
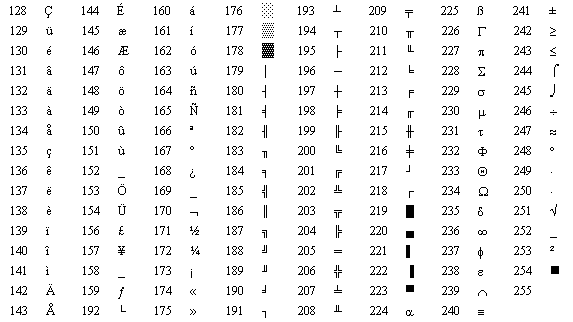


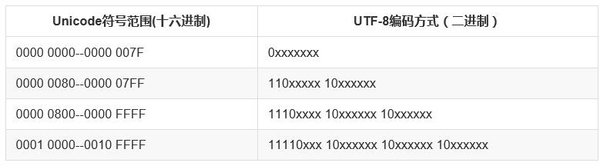
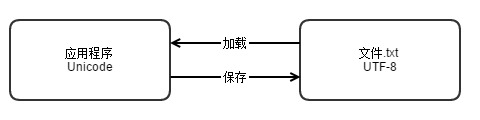
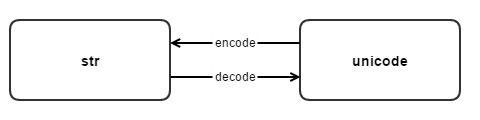 リーリー
リーリー

以上がPython プログラミングの歴史的進化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Linuxは実際に何に適していますか?
Apr 12, 2025 am 12:20 AM
Linuxは実際に何に適していますか?
Apr 12, 2025 am 12:20 AM
Linuxは、サーバー、開発環境、埋め込みシステムに適しています。 1.サーバーオペレーティングシステムとして、Linuxは安定して効率的であり、多くの場合、高電流アプリケーションの展開に使用されます。 2。開発環境として、Linuxは効率的なコマンドラインツールとパッケージ管理システムを提供して、開発効率を向上させます。 3.埋め込まれたシステムでは、Linuxは軽量でカスタマイズ可能で、リソースが限られている環境に適しています。
 LinuxでDockerを使用:包括的なガイド
Apr 12, 2025 am 12:07 AM
LinuxでDockerを使用:包括的なガイド
Apr 12, 2025 am 12:07 AM
LinuxでDockerを使用すると、開発と展開の効率が向上する可能性があります。 1。Dockerのインストール:スクリプトを使用して、ubuntuにDockerをインストールします。 2.インストールの確認:sudodockerrunhello-worldを実行します。 3。基本的な使用法:NginxコンテナDockerrun-Namemy-Nginx-P8080を作成します:80-Dnginx。 4。高度な使用法:カスタム画像を作成し、DockerFileを使用してビルドして実行します。 5。最適化とベストプラクティス:マルチステージビルドとドッケルコンポスを使用して、DockerFilesを作成するためのベストプラクティスに従ってください。
 Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache 80ポートが占有されている場合、ソリューションは次のとおりです。ポートを占有するプロセスを見つけて閉じます。ファイアウォールの設定を確認して、Apacheがブロックされていないことを確認してください。上記の方法が機能しない場合は、Apacheを再構成して別のポートを使用してください。 Apacheサービスを再起動します。
 Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを開始する手順は次のとおりです。Apache(コマンド:sudo apt-get install apache2または公式Webサイトからダウンロード)をインストールします(linux:linux:sudo systemctl start apache2; windows:apache2.4 "serviceを右クリックして「開始」を右クリック) (オプション、Linux:Sudo SystemCtl
 Oracleの監視を開始する方法
Apr 12, 2025 am 06:00 AM
Oracleの監視を開始する方法
Apr 12, 2025 am 06:00 AM
Oracleリスナーを開始する手順は次のとおりです。Windowsのリスナーステータス(LSNRCTLステータスコマンドを使用)を確認し、LinuxとUNIXのOracle Services Managerで「TNSリスナー」サービスを開始し、LSNRCTL Startコマンドを使用してリスナーを起動してLSNRCTLステータスコマンドを実行してリスナーを確認します。
 DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
この記事では、Debianシステム上のNginxサーバーのSSLパフォーマンスを効果的に監視する方法について説明します。 Nginxexporterを使用して、NginxステータスデータをPrometheusにエクスポートし、Grafanaを介して視覚的に表示します。ステップ1:NGINXの構成最初に、NGINX構成ファイルのSTUB_STATUSモジュールを有効にして、NGINXのステータス情報を取得する必要があります。 NGINX構成ファイルに次のスニペットを追加します(通常は/etc/nginx/nginx.confにあるか、そのインクルードファイルにあります):location/nginx_status {stub_status
 Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
この記事では、デビアンシステムでリサイクルビンを構成する2つの方法を紹介します:グラフィカルインターフェイスとコマンドライン。方法1:Nautilusグラフィカルインターフェイスを使用して、ファイルマネージャーを開きます。デスクトップまたはアプリケーションメニューでNautilusファイルマネージャー(通常は「ファイル」と呼ばれる)を見つけて起動します。リサイクルビンを見つけてください:左ナビゲーションバーのリサイクルビンフォルダーを探してください。見つからない場合は、「他の場所」または「コンピューター」をクリックして検索してみてください。リサイクルビンプロパティの構成:「リサイクルビン」を右クリックし、「プロパティ」を選択します。プロパティウィンドウで、次の設定を調整できます。最大サイズ:リサイクルビンで使用可能なディスクスペースを制限します。保持時間:リサイクルビンでファイルが自動的に削除される前に保存を設定します
 Oracleにリスナーを追加する方法
Apr 11, 2025 pm 08:51 PM
Oracleにリスナーを追加する方法
Apr 11, 2025 pm 08:51 PM
Oracleリスナーを追加するには:1。構成パラメーターを含むリスナー構成ファイルを作成します。 2。$ oracle_home/network/admin/ristener.oraで構成ファイルを保存します。 3. LSNRCTL STARTリスナーコマンドを使用して、リスナーを起動します。 4. LSNRCTLステータスリスナーコマンドを使用して、リスナーが実行されていることを確認します。
