

時系列データへの適用に推奨されるニューラル ネットワーク

| この記事では、リカレント ニューラル ネットワーク RNN の開発プロセスを簡単に紹介し、勾配降下アルゴリズム、バックプロパゲーション、LSTM プロセスを分析します。 |
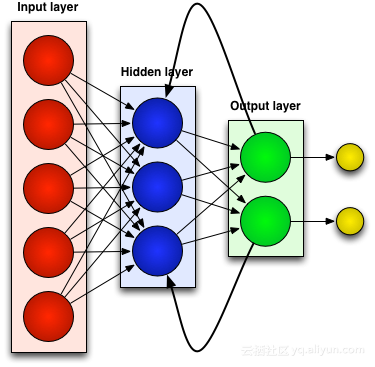
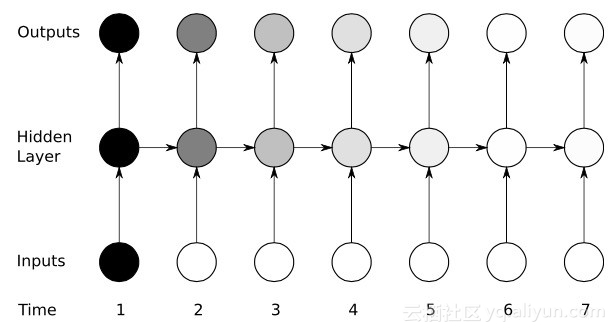
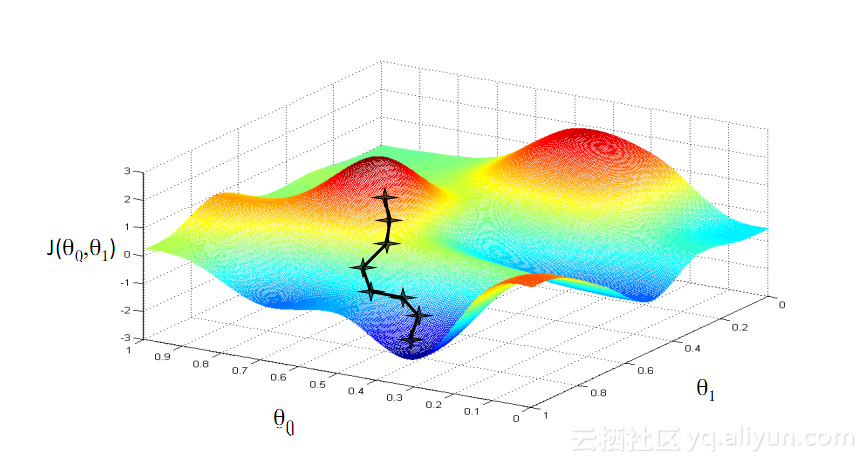
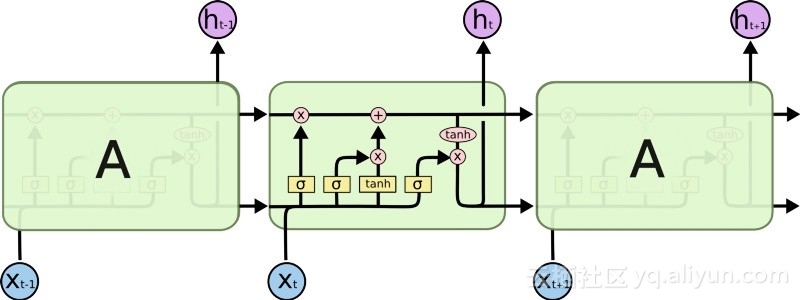
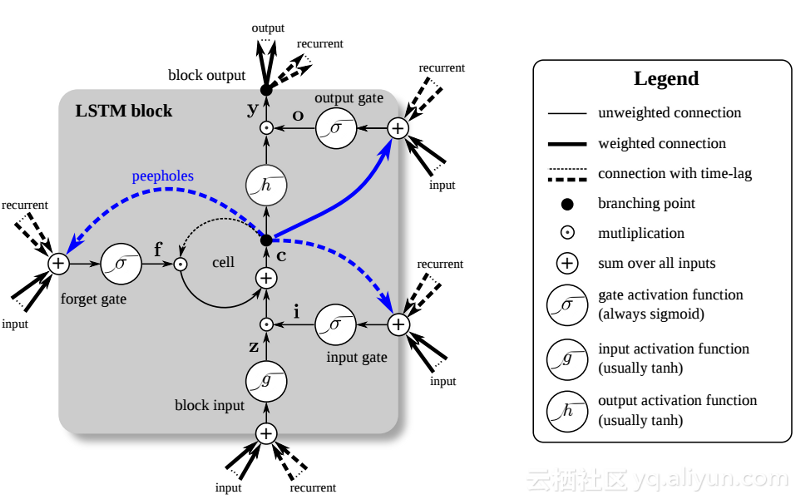
以上が時系列データへの適用に推奨されるニューラル ネットワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
Deepseek Webバージョンの入り口Deepseek公式ウェブサイトの入り口
Feb 19, 2025 pm 04:54 PM
DeepSeekは、Webバージョンと公式Webサイトの2つのアクセス方法を提供する強力なインテリジェント検索および分析ツールです。 Webバージョンは便利で効率的であり、公式ウェブサイトは包括的な製品情報、ダウンロードリソース、サポートサービスを提供できます。個人であろうと企業ユーザーであろうと、DeepSeekを通じて大規模なデータを簡単に取得および分析して、仕事の効率を向上させ、意思決定を支援し、イノベーションを促進することができます。
 DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールするには、Dockerコンテナ(最も便利な場合は、互換性について心配する必要はありません)を使用して、事前コンパイルパッケージ(Windowsユーザー向け)を使用してソースからコンパイル(経験豊富な開発者向け)を含む多くの方法があります。公式文書は慎重に文書化され、不必要なトラブルを避けるために完全に準備します。
 gate.ioインストールパッケージを無料で入手してください
Feb 21, 2025 pm 08:21 PM
gate.ioインストールパッケージを無料で入手してください
Feb 21, 2025 pm 08:21 PM
Gate.ioは、インストールパッケージをダウンロードしてデバイスにインストールすることで使用できる人気のある暗号通貨交換です。インストールパッケージを取得する手順は次のとおりです。Gate.ioの公式Webサイトにアクセスし、「ダウンロード」をクリックし、対応するオペレーティングシステム(Windows、Mac、またはLinux)を選択し、インストールパッケージをコンピューターにダウンロードします。スムーズなインストールを確保するために、インストール中に一時的にウイルス対策ソフトウェアまたはファイアウォールを一時的に無効にすることをお勧めします。完了後、ユーザーはGATE.IOアカウントを作成して使用を開始する必要があります。
 OUYI OKXインストールパッケージが直接含まれています
Feb 21, 2025 pm 08:00 PM
OUYI OKXインストールパッケージが直接含まれています
Feb 21, 2025 pm 08:00 PM
世界をリードするデジタル資産交換であるOuyi Okxは、安全で便利な取引体験を提供するために、公式のインストールパッケージを開始しました。 OUYIのOKXインストールパッケージは、ブラウザに直接インストールでき、ユーザー向けの安定した効率的な取引プラットフォームを作成できます。インストールプロセスは、簡単で理解しやすいです。
 Bitget公式ウェブサイトのインストール(2025初心者ガイド)
Feb 21, 2025 pm 08:42 PM
Bitget公式ウェブサイトのインストール(2025初心者ガイド)
Feb 21, 2025 pm 08:42 PM
Bitgetは、スポット取引、契約取引、デリバティブなど、さまざまな取引サービスを提供する暗号通貨交換です。 2018年に設立されたこのExchangeは、シンガポールに本社を置き、安全で信頼性の高い取引プラットフォームをユーザーに提供することに取り組んでいます。 Bitgetは、BTC/USDT、ETH/USDT、XRP/USDTなど、さまざまな取引ペアを提供しています。さらに、この取引所はセキュリティと流動性について評判があり、プレミアム注文タイプ、レバレッジド取引、24時間年中無休のカスタマーサポートなど、さまざまな機能を提供します。
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 OUYI Exchangeダウンロード公式ポータル
Feb 21, 2025 pm 07:51 PM
OUYI Exchangeダウンロード公式ポータル
Feb 21, 2025 pm 07:51 PM
OKXとしても知られるOUYIは、世界をリードする暗号通貨取引プラットフォームです。この記事では、OUYIの公式インストールパッケージのダウンロードポータルを提供します。これにより、ユーザーはさまざまなデバイスにOUYIクライアントをインストールすることが容易になります。このインストールパッケージは、Windows、Mac、Android、およびiOSシステムをサポートします。インストールが完了した後、ユーザーはOUYIアカウントに登録またはログインし、暗号通貨の取引を開始し、プラットフォームが提供するその他のサービスを楽しむことができます。
 システムの再起動後にUnixSocketの権限を自動的に設定する方法は?
Mar 31, 2025 pm 11:54 PM
システムの再起動後にUnixSocketの権限を自動的に設定する方法は?
Mar 31, 2025 pm 11:54 PM
システムが再起動した後、UnixSocketの権限を自動的に設定する方法。システムが再起動するたびに、UnixSocketの許可を変更するために次のコマンドを実行する必要があります:sudo ...
