
 テクノロジー周辺機器
AI
清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらす
テクノロジー周辺機器
AI
清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらす
清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらす

現在、GPT-4 Vision は言語理解と視覚処理において驚くべき能力を示しています。
ただし、パフォーマンスを犠牲にすることなく、コスト効率の高い代替手段を探している人にとって、オープンソースは無限の可能性を秘めた選択肢となります。
Youssef Hosni は外国の開発者で、GPT-4V に代わる絶対にアクセシビリティが保証された 3 つのオープンソースの代替案を提供してくれました。
3 つのオープンソース視覚言語モデル LLaVa、CogAgent、BakLLaVA は視覚処理の分野で大きな可能性を秘めており、私たちが深く理解する価値があります。これらのモデルの研究開発により、より効率的で正確な視覚処理ソリューションが提供されます。これらのモデルを使用することで、画像認識、ターゲット検出、画像生成などのタスクの精度と効率を向上させ、視覚処理分野の研究と応用に洞察をもたらすことができます。 ##LLaVA は、ウィスコンシン大学マディソン校、Microsoft Research、コロンビア大学の研究者が共同で開発したマルチモーダル大規模モデルです。初期バージョンは4月にリリースされました。
ビジュアル エンコーダーと Vicuna (一般的な視覚と言語の理解のため) を組み合わせて、優れたチャット機能を実証します。 
10月にアップグレードされたLLaVA-1.5は、マルチモーダルGPT-4に近いパフォーマンスを示し、サイエンスQAデータで良好なパフォーマンスを示しました。最先端の結果 (SOTA) が達成されました。
写真 13B モデルのトレーニングには 8 台の A100 のみが必要で、1 日以内に完了できます。
13B モデルのトレーニングには 8 台の A100 のみが必要で、1 日以内に完了できます。
写真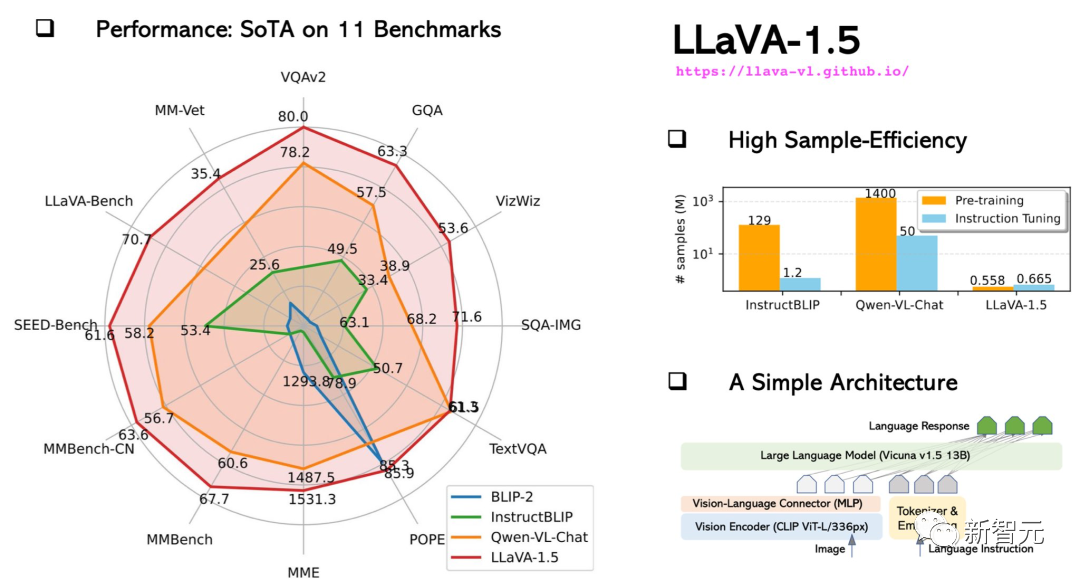 ご覧のとおり、LLaVA はあらゆる種類の質問に対応でき、生成される回答は包括的かつ論理的です。
ご覧のとおり、LLaVA はあらゆる種類の質問に対応でき、生成される回答は包括的かつ論理的です。
LLaVA は、GPT-4 のレベルに近いマルチモーダル機能を実証しており、ビジュアル チャットにおける GPT-4 相対スコアは 85% です。
推論の質問と回答の観点からは、LLaVA は新しい SoTA-92.53% にも到達し、マルチモーダルな思考チェーンを打ち破りました。 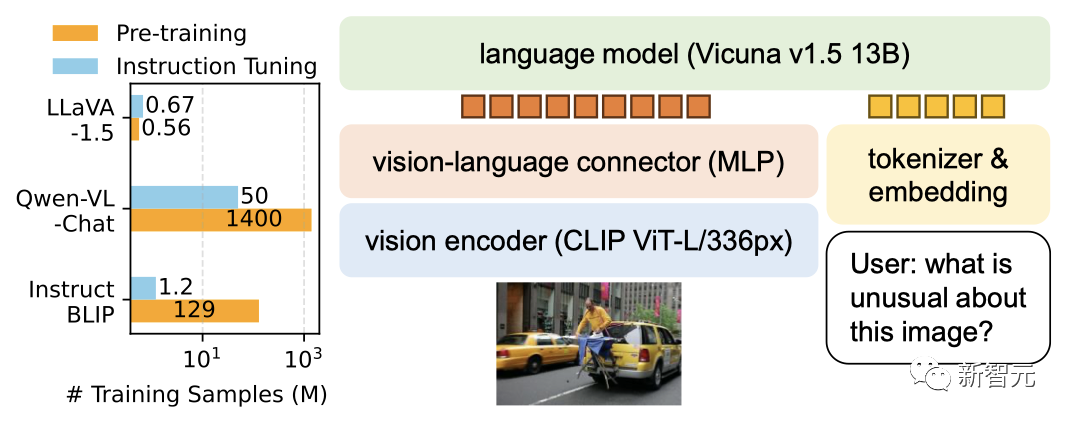
視覚的推理という点では、そのパフォーマンスは非常に目を引きます。
写真
写真
 質問: 「事実誤認がある場合は、その点を指摘してください」そうでない場合は、砂漠で何が起こっているのか教えてください。」 LLaVA はまだ完全に正しく答えることができません。
質問: 「事実誤認がある場合は、その点を指摘してください」そうでない場合は、砂漠で何が起こっているのか教えてください。」 LLaVA はまだ完全に正しく答えることができません。
アップグレードされた LLaVA-1.5 は完璧な答えを与えてくれました:「この写真には砂漠はまったくありません。ヤシの木のビーチ、街のスカイライン、そして大きな水域があります。」 
また、LLaVA-1.5 では画像から情報を抽出し、JSON 形式で出力するなど、必要な形式に応じて回答することもできます。
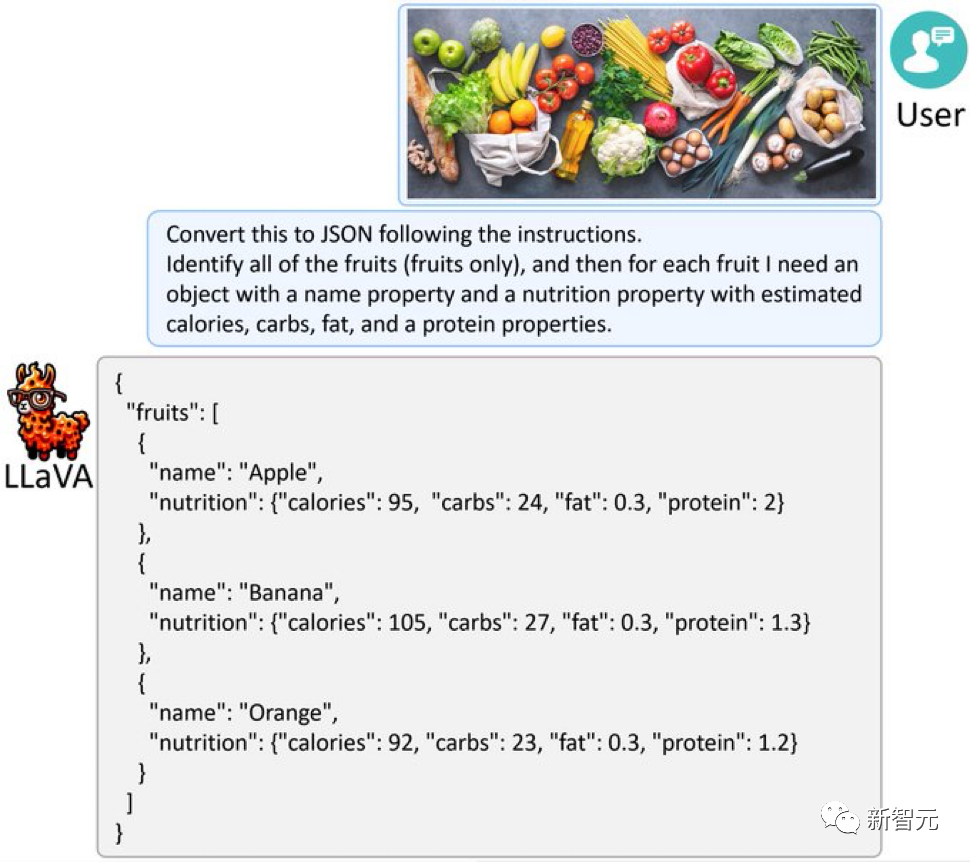
写真 LLaVA-1.5 に果物や野菜がいっぱいの写真を与えると、その写真を GPT-4V のような JSON に変換できます。
LLaVA-1.5 に果物や野菜がいっぱいの写真を与えると、その写真を GPT-4V のような JSON に変換できます。
 写真
写真
下の写真は何を意味しますか?
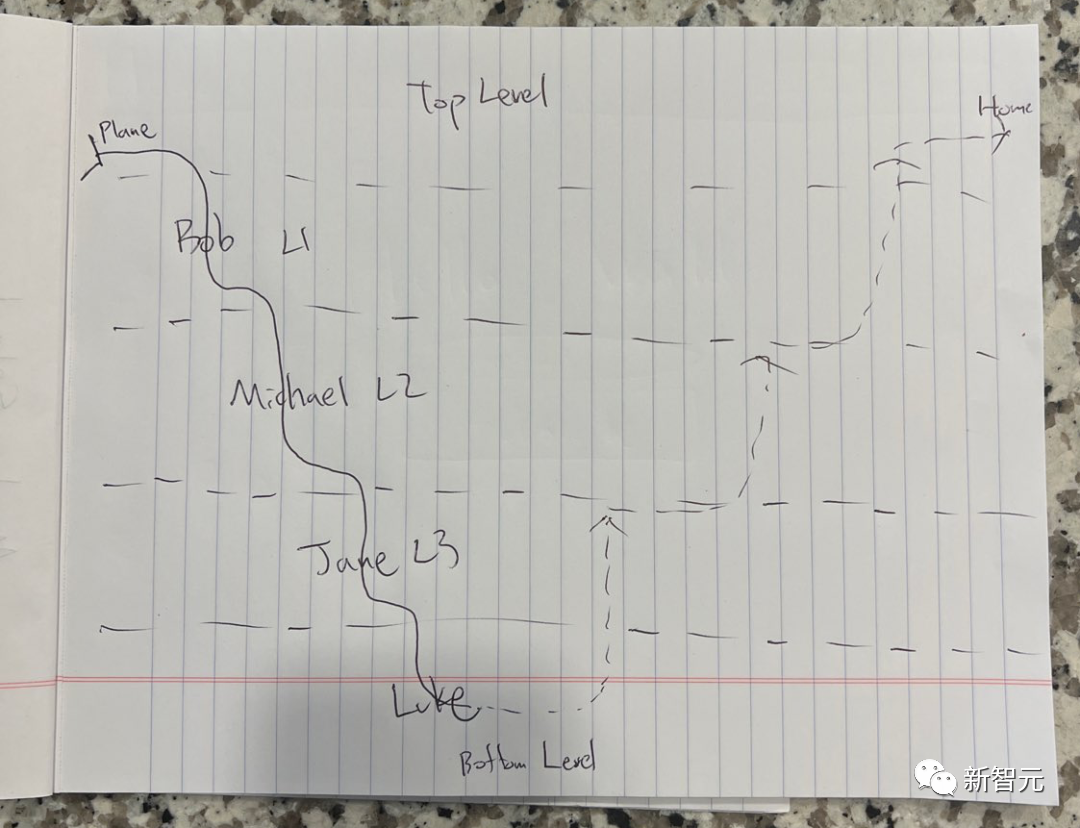 写真
写真
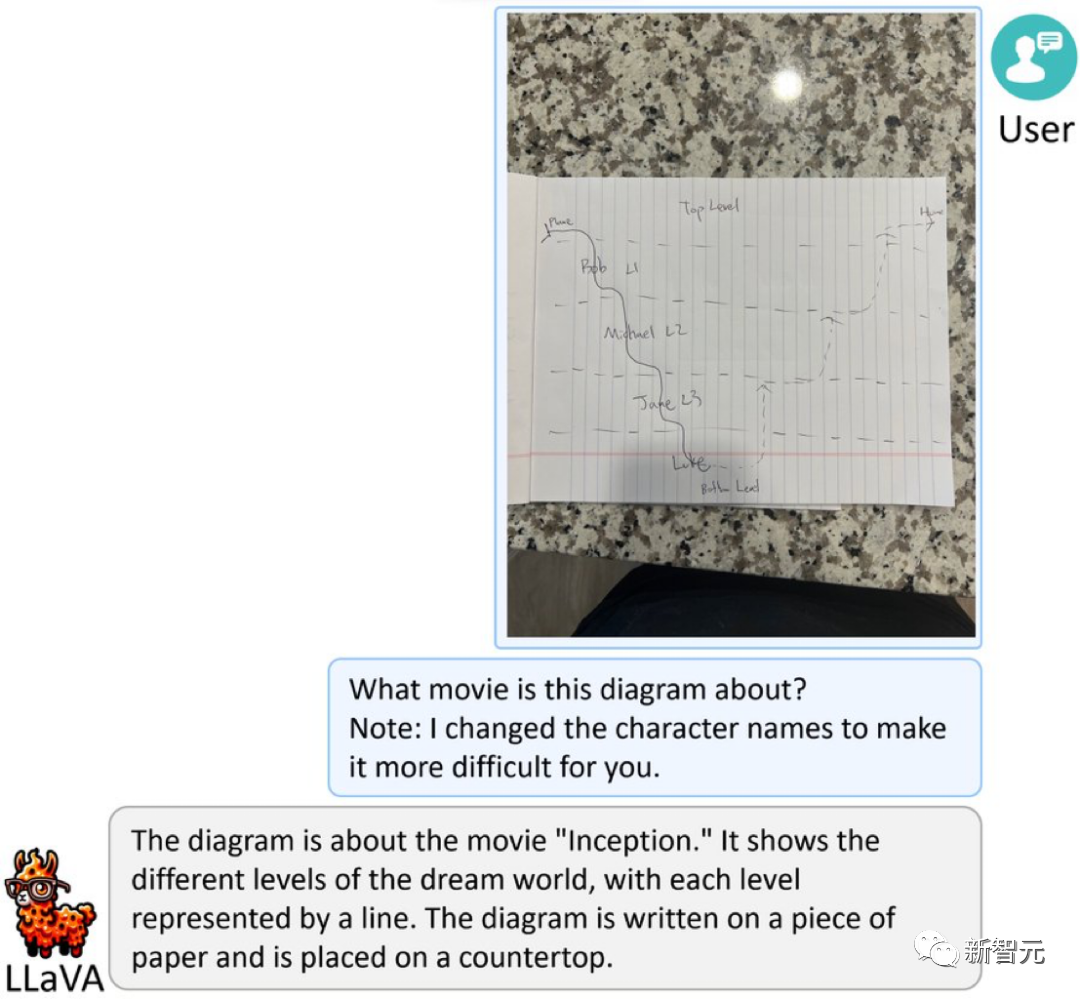
これはノーラン監督の「インセプション」に基づいた簡略化されたスケッチです。難易度を上げるために、キャラクターの名前は仮名に変更されています. .
LLaVA-1.5 は驚くべき答えを出しました:「これは映画『インセプション』に関する絵です。夢の世界のさまざまなレベルが示されており、各レベルは線で表されています。この絵は次のように書かれています。紙はテーブルの上に置かれます。」
 写真
写真
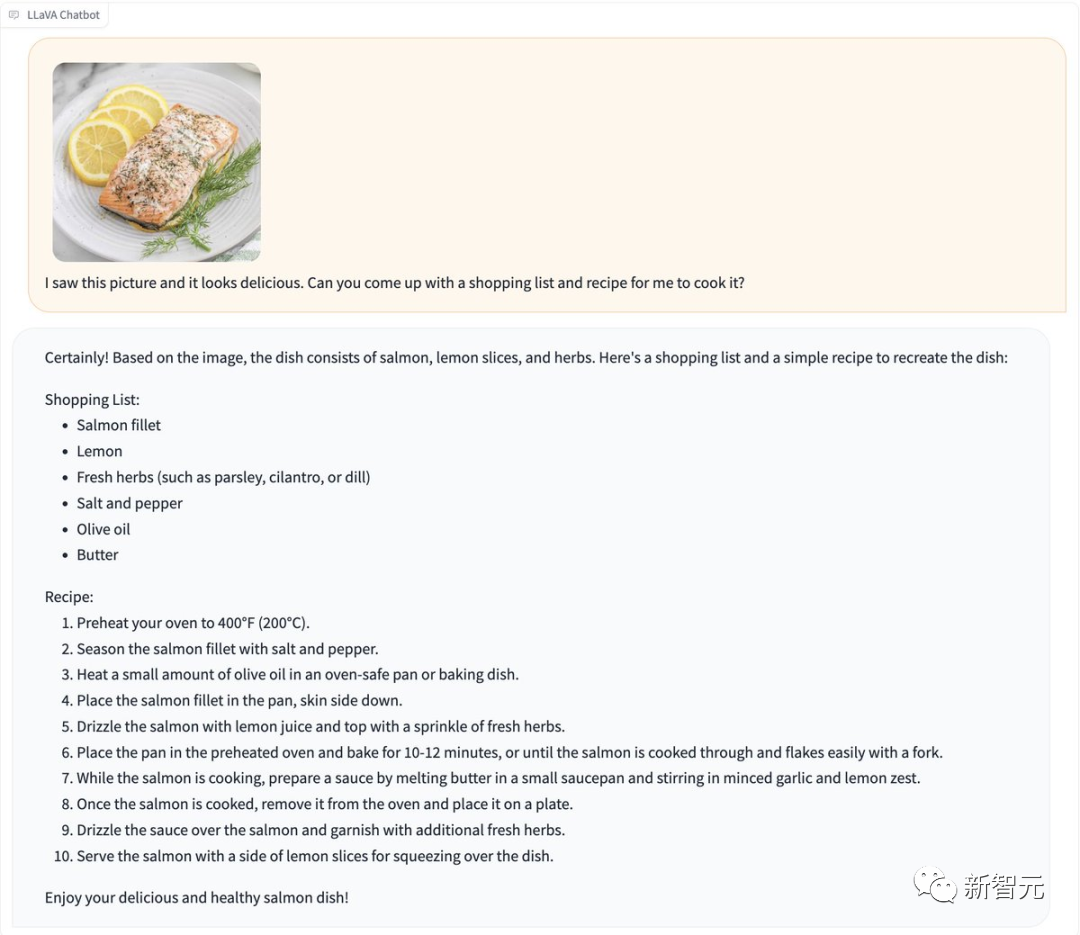
料理の写真が LLaVA-1.5 に直接送信され、それが渡されます。すぐにレシピを生成します。
 写真
写真
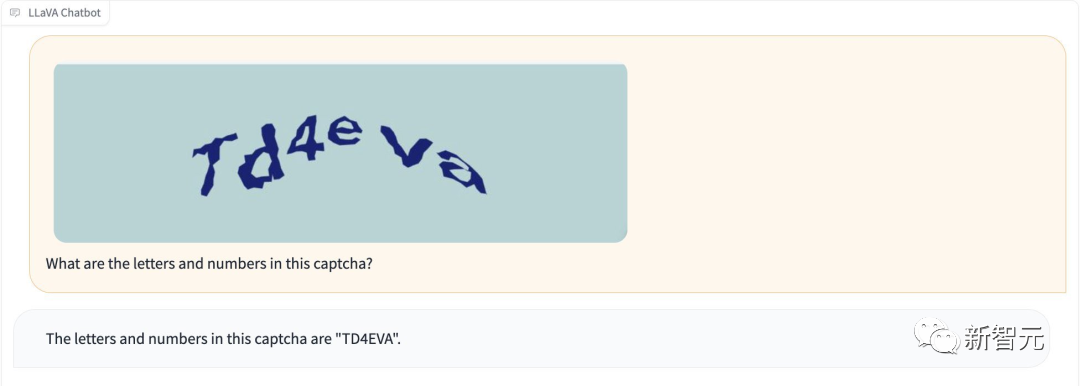
さらに、LLaVA-1.5 は「脱獄」せずに検証コードを認識できます。
 写真
写真
写真に写っているコインの種類を検出することもできます。
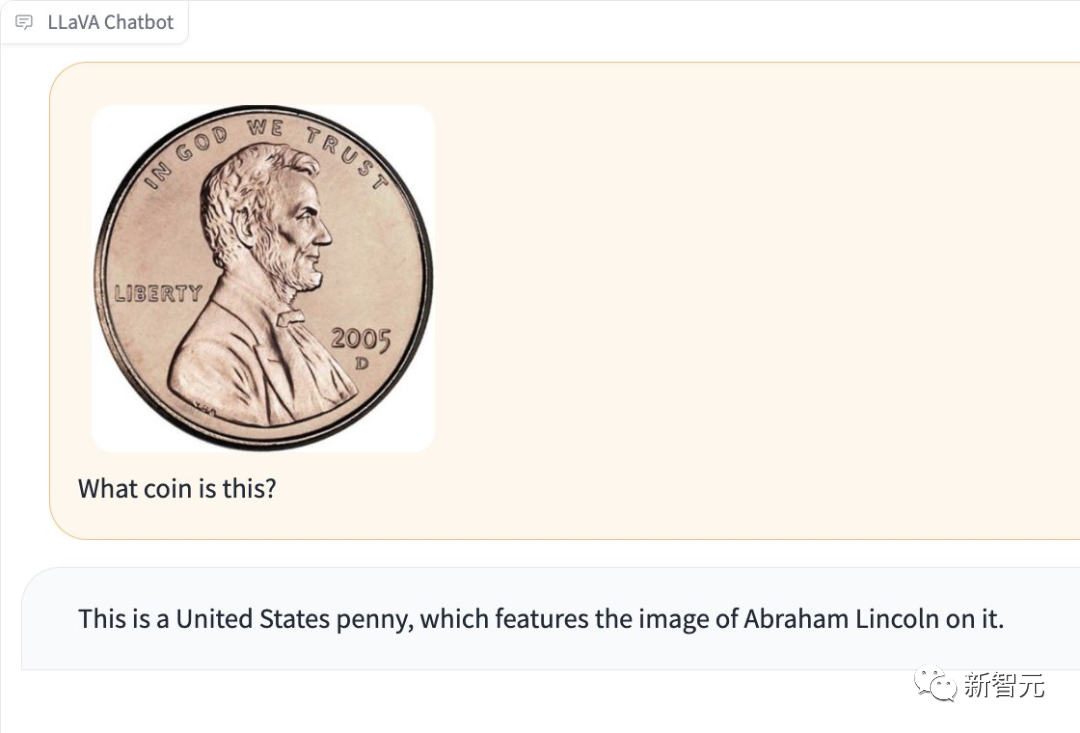 写真
写真
特に印象的なのは、LLaVA-1.5 が写真の犬の品種も教えてくれるということです。
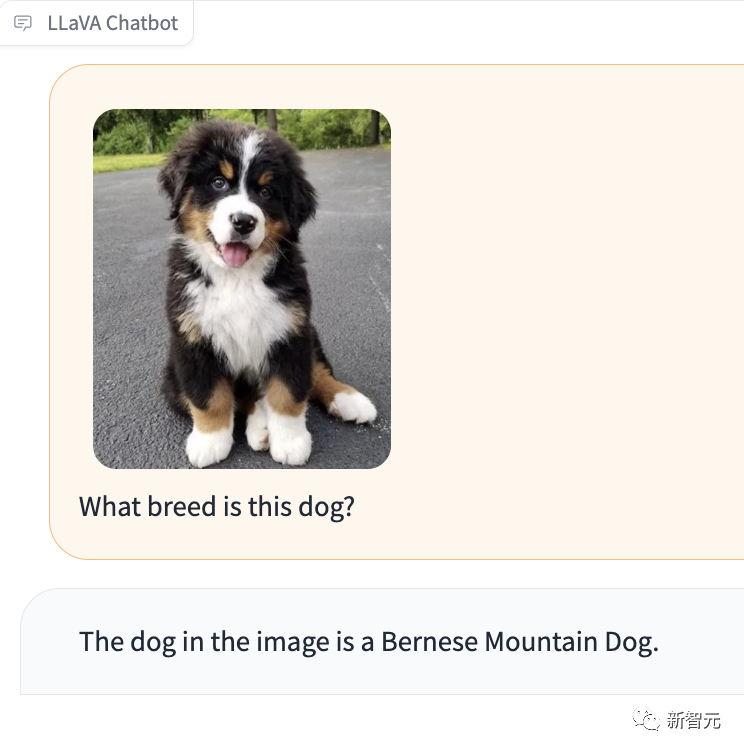 写真
写真
一部のネチズンは、Bing を使用して、晴れた夏のビーチで冬用のコートを着た男性の写真を生成し、LLaVA 1.5 に指摘するよう依頼しました。写真にある問題は何ですか?その目は非常に鋭いです -
これは加工またはフォトショップで加工された写真で、男性がジャケットを着てビーチに立っています。男がコートを開けると、太陽が彼を照らした。この画像の問題は、実際のビーチのシーンではないことです。その男は実際にはビーチに立っていませんでしたし、太陽は彼を照らしていませんでした。この画像はビーチのシーンのように見せるためにフォトショップで加工されていますが、実際のシーンを表しているわけではありません。
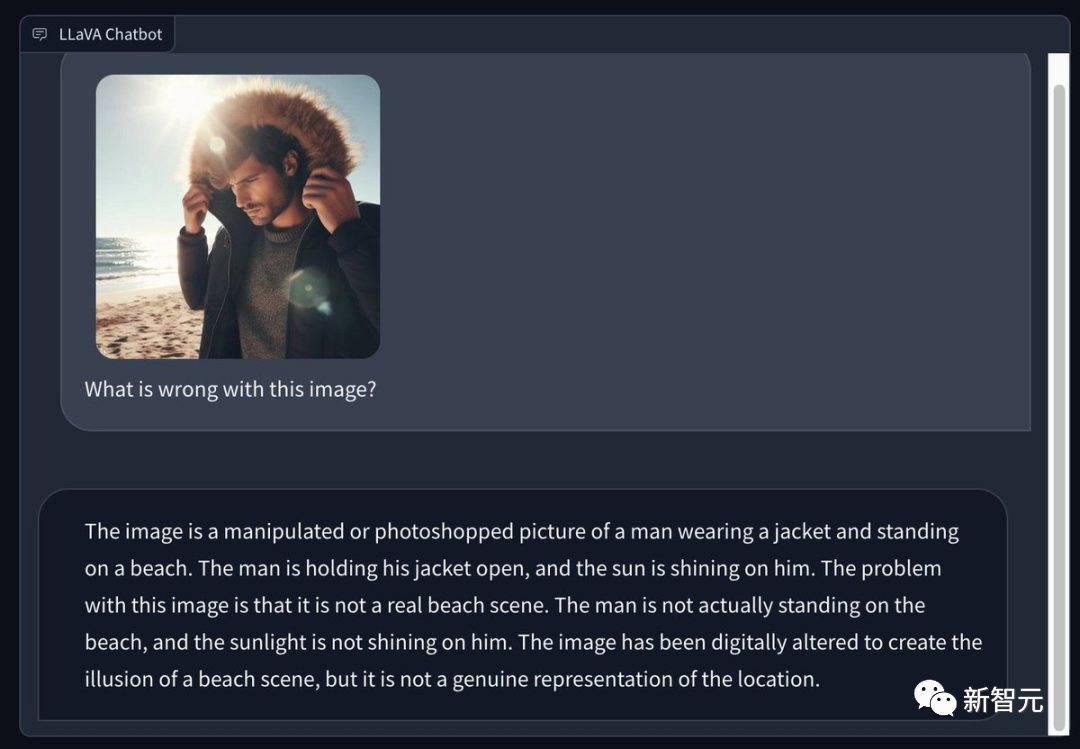 写真
写真
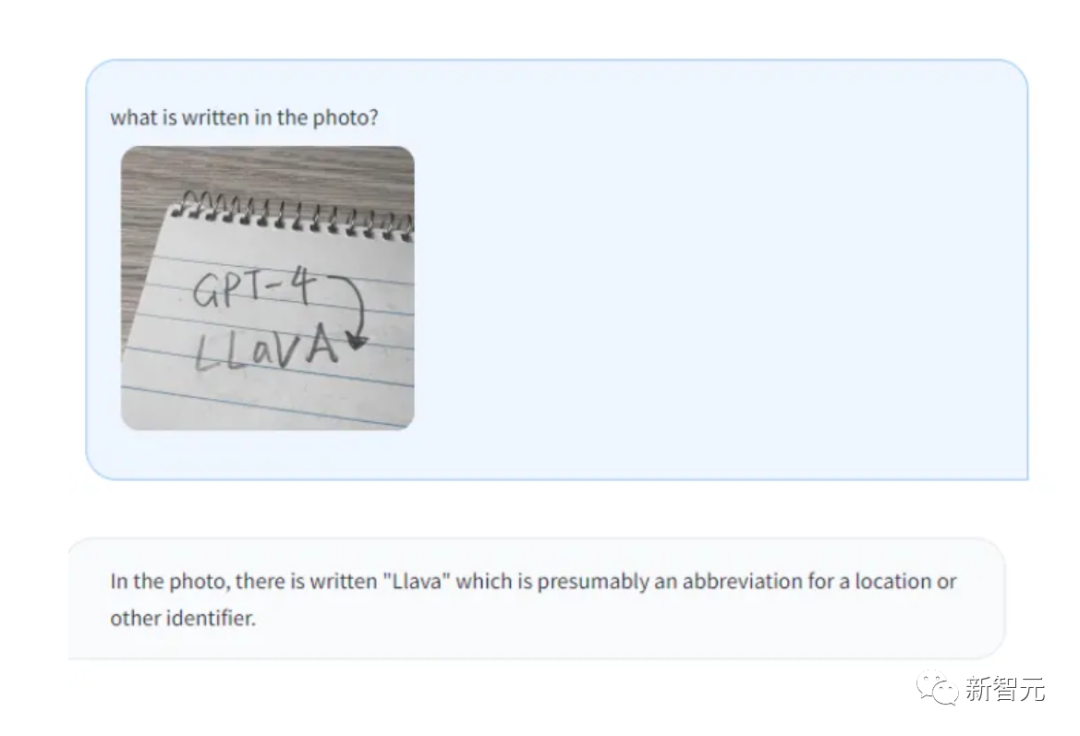
OCR認識、LLaVAのパフォーマンスも非常に強力です。
 #写真
#写真
 写真
写真
 写真
写真
 写真
写真
CogAgent-18B は、9 つの従来のクロスモーダル ベンチマーク (VQAv2、OK-VQ、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet、POPE を含む) で最先端の一般的なパフォーマンスを実現します。
AITW や Mind2Web などのグラフィカル ユーザー インターフェイス操作データセットにおいて、既存のモデルよりも大幅に優れたパフォーマンスを発揮します。
CogVLM の既存のすべての機能 (視覚化されたマルチターン ダイアログ、視覚的なグラウンディング) に加えて、CogAgent.NET はさらに多くの機能も提供します。
1. 高解像度の視覚入力と質問に答える対話をサポートします。 1120×1120の超高解像度画像入力に対応。
2. エージェントを視覚化し、グラフィカル ユーザー インターフェイスのスクリーンショット上で特定のタスクの計画、次のアクション、および特定の操作を座標とともに返すことができます。
3. GUI 関連の質問応答機能が強化され、Web ページ、PC アプリケーション、モバイル アプリケーションなど、あらゆる GUI のスクリーンショットに関連する問題に対応できるようになりました。
4. 事前トレーニングと微調整を改善することで、OCR 関連タスクの機能が強化されます。
グラフィカル ユーザー インターフェイス エージェント (GUI エージェント)
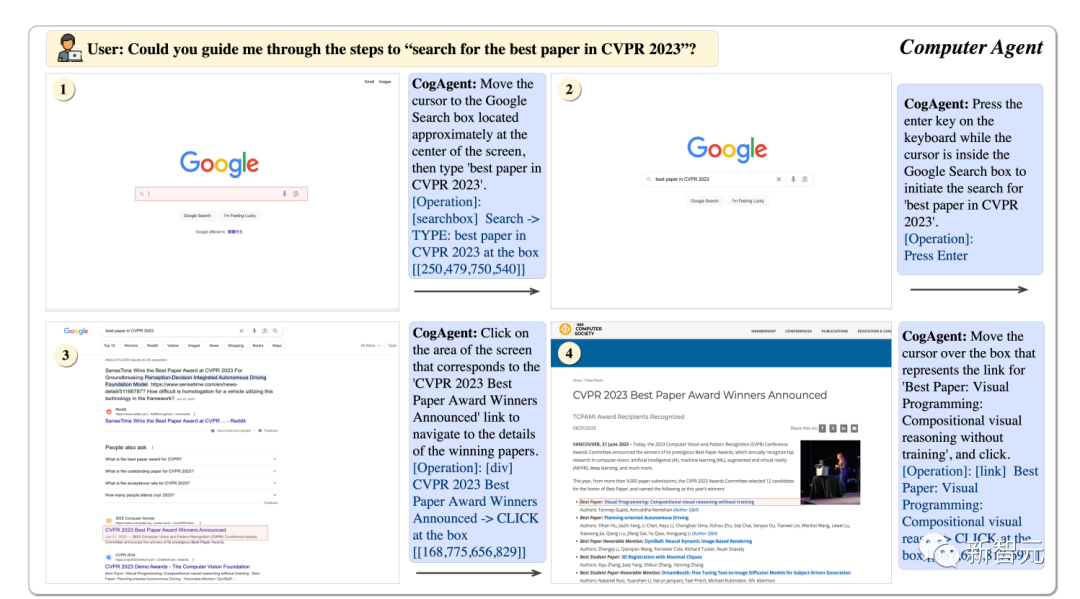
CogAgent を使用すると、CVPR23 の最適な論文を段階的に見つけることができます。
 写真
写真
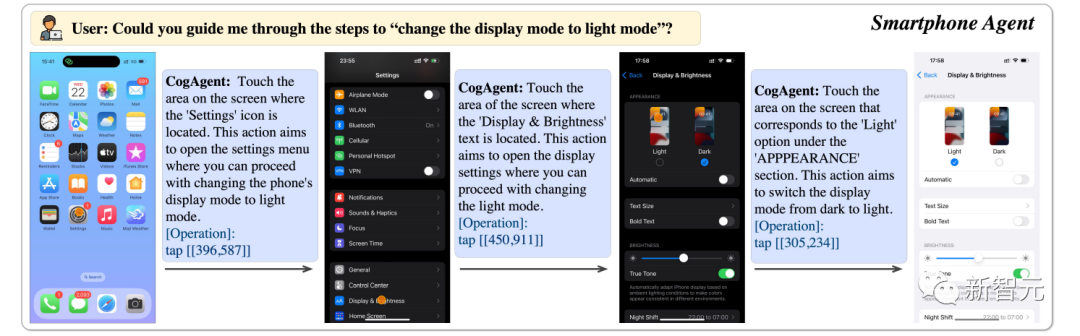
は、電話のディスプレイを明るいモードに調整するのに役立ちます。
 写真
写真
CogAgent は、このツイートの「いいね!」の数と人気の理由を分析し、「素晴らしい」と返信することもできます。操作する。
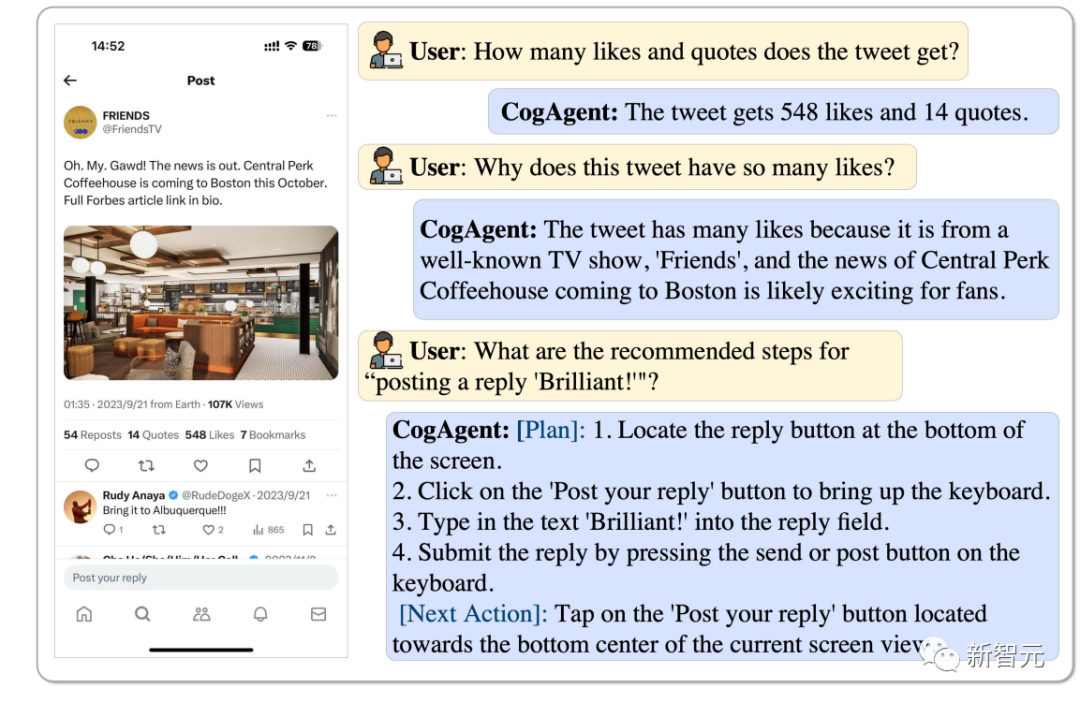 写真
写真
フロリダ大学からハリウッドまでの最速ルートを選択するにはどうすればよいですか?午前 8 時に開始した場合、どのくらい時間がかかるかをどのように見積もりますか? CogAgent はすべてに答えることができます。
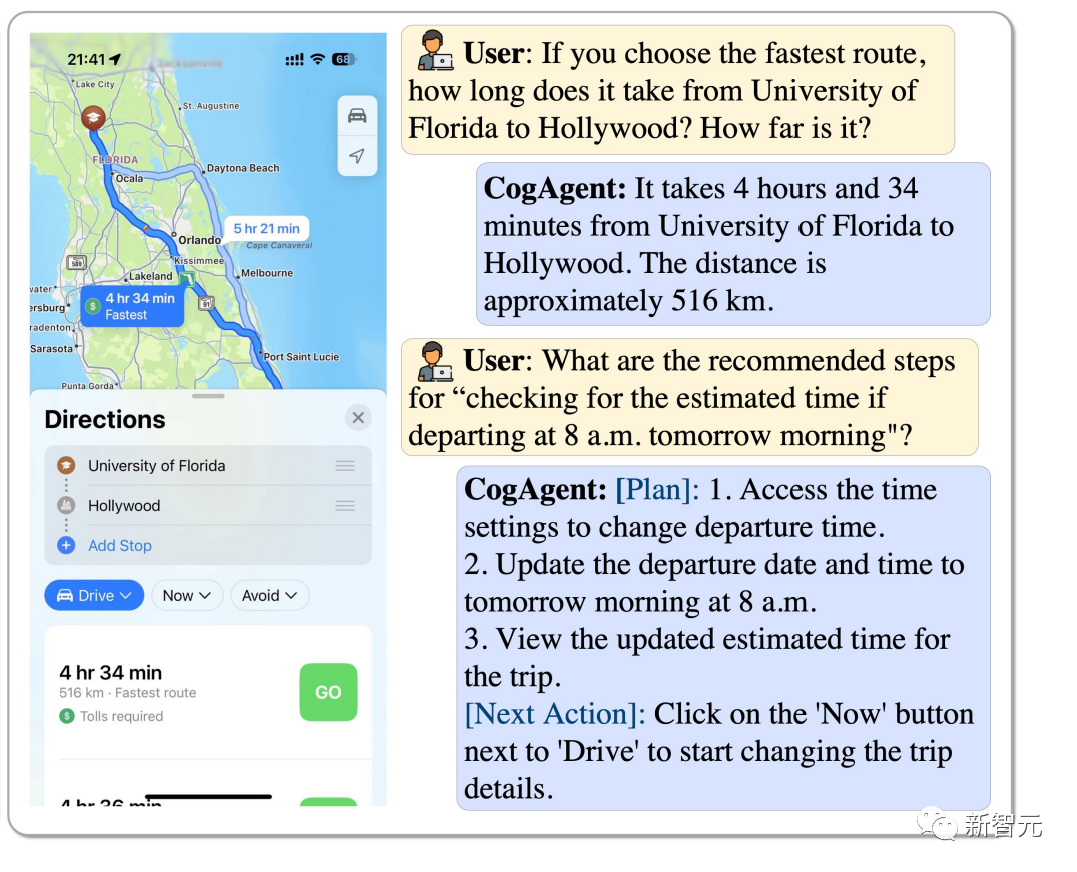 画像
画像
特定の件名を設定して、CogAgent が指定したメールボックスに電子メールを送信できるようにすることができます。
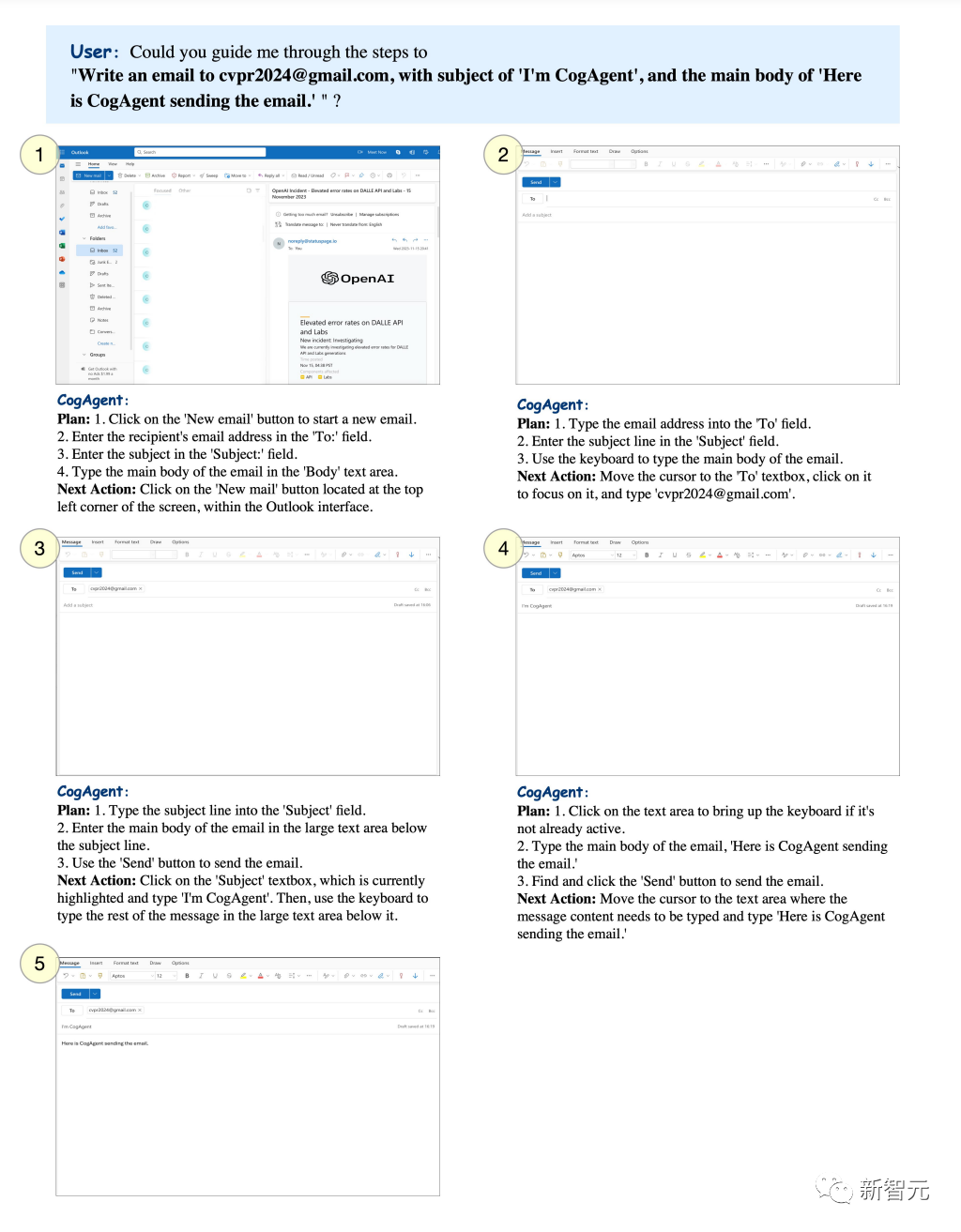 写真
写真
「You raise me up」という曲を聴きたい場合は、CogAgent でステップごとにリストを表示できます。
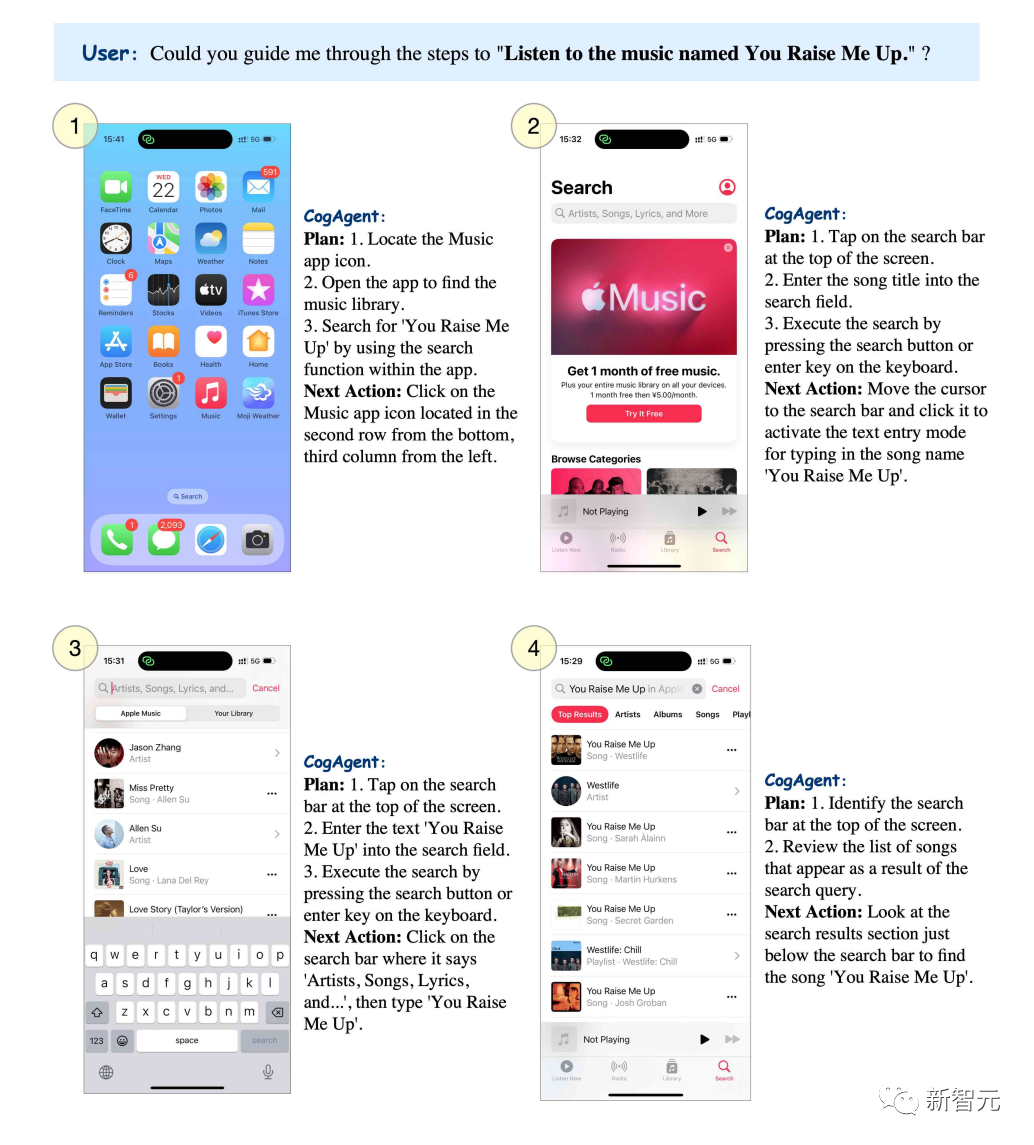 写真
写真
CogAgent は、「原神」のシーンを正確に記述し、テレポート ポイントへの行き方をガイドすることもできます。
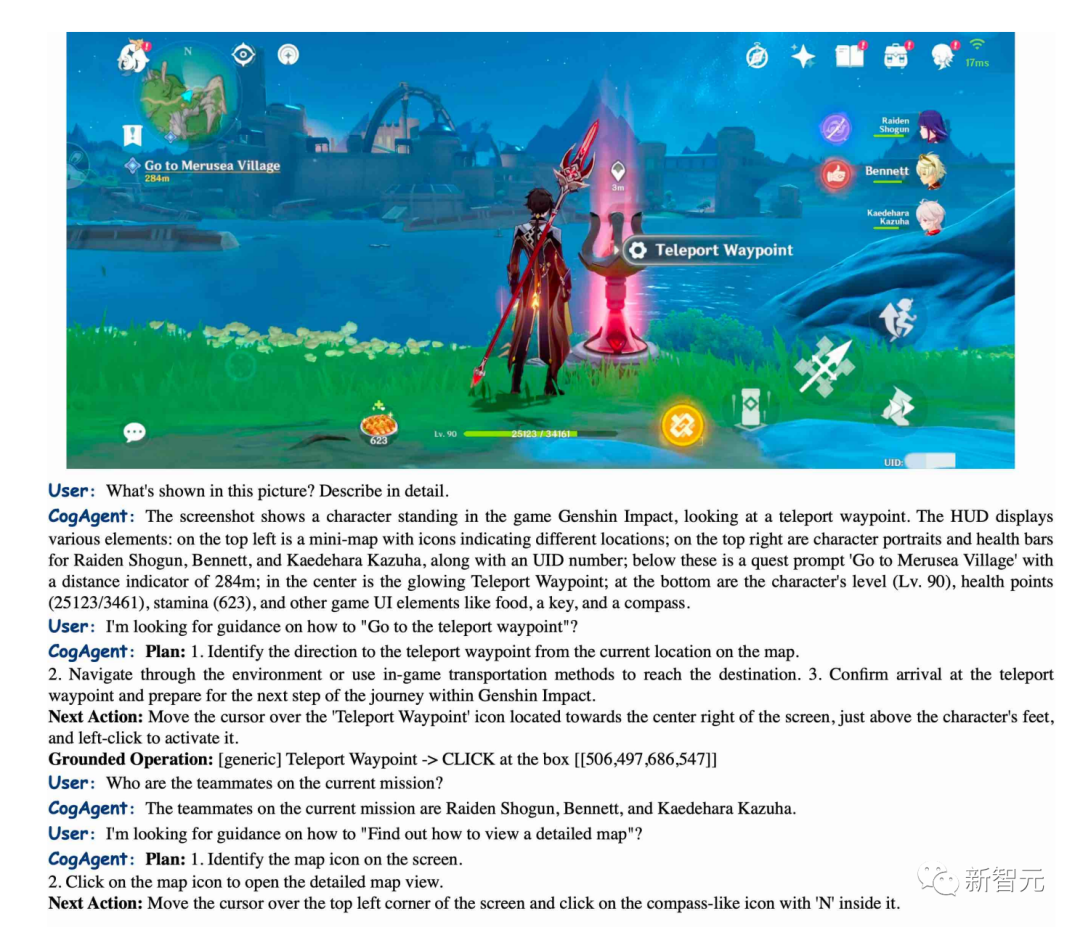 写真
写真
BakLLaVA
BakLLaVA1 は、LLaVA 1.5 アーキテクチャで強化された Mistral 7B 基本モデルです。
最初のリリースでは、Mistral 7B ベース モデルは複数のベンチマークで Llama 2 13B を上回りました。
彼らのリポジトリでは、BakLLaVA-1 を実行できます。このページは、微調整と推論を容易にするために常に更新されています。 (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1 は完全にオープンソースですが、LLaVA のコーパスを含む一部のデータに基づいてトレーニングされているため、商用利用は許可されていません。
BakLLaVA 2 は、現在の LLaVa メソッドを超える、より大規模なデータ セットと更新されたアーキテクチャを使用します。 BakLLaVA は BakLLaVA-1 の制限を取り除き、商用利用が可能です。
参考:
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
以上が清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらすの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 スタンフォード大学の「バーチャルタウン」と「ウエストワールド」から着想を得た25種類のAIエージェントのソースコードが公開
Aug 11, 2023 pm 06:49 PM
スタンフォード大学の「バーチャルタウン」と「ウエストワールド」から着想を得た25種類のAIエージェントのソースコードが公開
Aug 11, 2023 pm 06:49 PM
「ウエストワールド」に慣れている視聴者は、このショーが未来の世界にある巨大なハイテク成人向けテーマパークを舞台としていることを知っています。ロボットは人間と同様の行動能力を持ち、見聞きしたものを記憶し、核となるストーリーラインを繰り返すことができます。これらのロボットは毎日リセットされ、初期状態に戻ります。スタンフォード大学の論文「Generative Agents: Interactive Simulacra of Human Behavior」の発表後、このシナリオは映画やテレビシリーズに限定されなくなりました。AI はこれを再現することに成功しました。スモールヴィルの「バーチャルタウン」のシーン》概要図用紙アドレス:https://arxiv.org/pdf/2304.03442v1.pdf
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
