

A800 は Llama2 推論 RTX3090 および 4090 を大幅に上回り、優れたレイテンシーとスループットを実現します。
Jan 04, 2024 pm 01:05 PM大規模言語モデル (LLM) は、学術界と産業界の両方で大きな進歩を遂げました。しかし、LLM のトレーニングと展開には非常に費用がかかり、大量のコンピューティング リソースとメモリが必要となるため、研究者は LLM の事前トレーニング、微調整、推論を高速化するための多くのオープンソース フレームワークと手法を開発してきました。ただし、ハードウェアおよびソフトウェア スタックが異なると実行時のパフォーマンスが大幅に異なる場合があるため、最適な構成を選択することが困難になります。
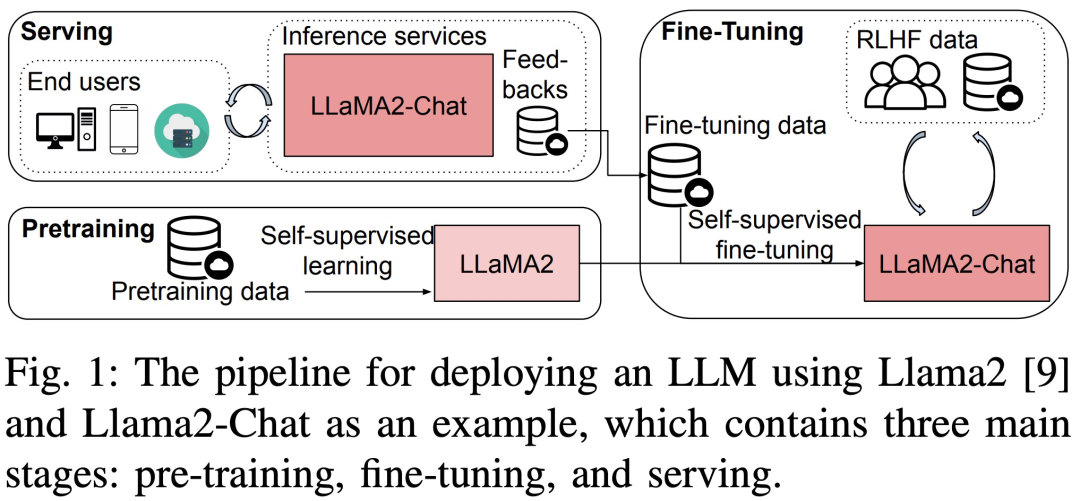
最近、「大規模言語モデルのトレーニング、微調整、および推論の実行時パフォーマンスの分析」というタイトルの新しい論文が発表されました。 LLM のトレーニング、微調整、推論をマクロとミクロの観点から詳細に分析します。

論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2311.03687.pdf
具体的には、この調査ではまず、事前トレーニング、微調整、およびサービスを変更することなく、3 つの 8 GPU で異なるサイズ (7B、13B、および 70B パラメーター) の LLM のフルプロセス パフォーマンス ベンチマーク テストを実施しました。本来の意味です。テストでは、ZeRO、Quantize、Recalculate、FlashAttendant などの個別の最適化テクノロジを備えたプラットフォームと備えていないプラットフォームを対象にしました。さらに、この調査では、LLM の計算および通信演算子のサブモジュールの詳細な実行時分析が提供されます。
方法の概要
調査のベンチマークテストではトップダウン アプローチが採用されており、図 3 に示すように、3 つの 8 GPU ハードウェア プラットフォーム上の Llama2 のエンドツーエンドのステップ時間パフォーマンス、モジュールレベルの時間パフォーマンス、およびオペレーター時間のパフォーマンスがカバーされます。
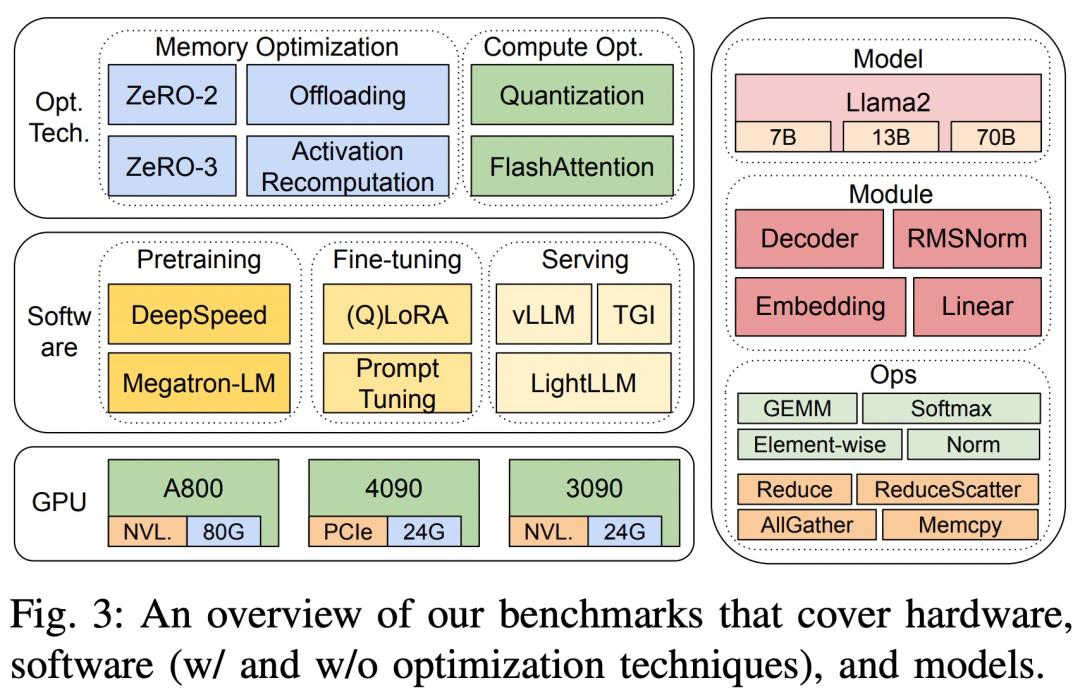
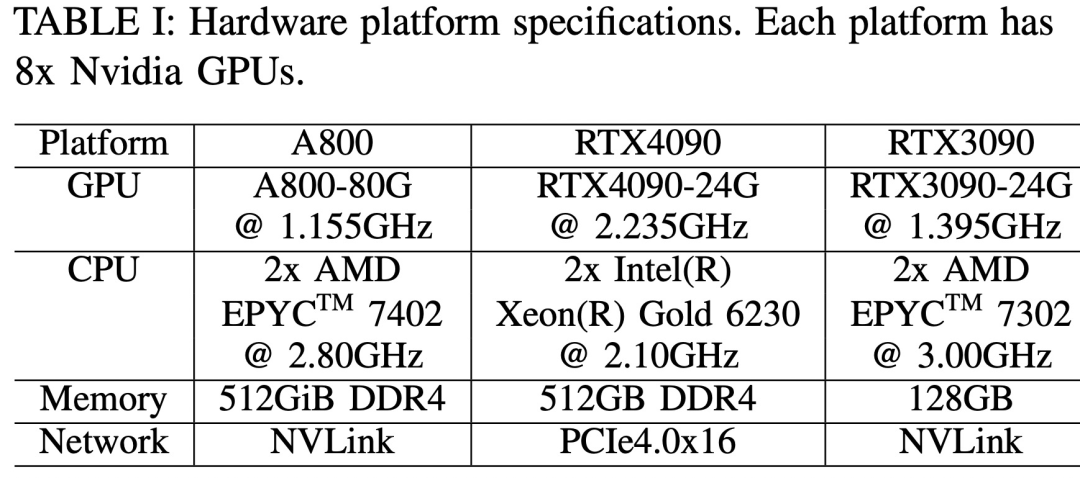
#3 つのハードウェア プラットフォームは RTX4090、RTX3090、A800 で、具体的な仕様は以下の表 1 に示されています。
ソフトウェア面では、この研究では DeepSpeed と Megatron-LM をエンドツーエンドで比較しています。事前トレーニングとステップ時間の微調整。最適化手法を評価するために、調査では DeepSpeed を使用して次の最適化を 1 つずつ有効にしました: ZeRO-2、ZeRO-3、オフロード、アクティベーション再計算、量子化、FlashAttending を使用して、パフォーマンスの向上と時間とメモリ消費量の削減を測定しました。
LLM サービスに関しては、vLLM、LightLLM、TGI という 3 つの高度に最適化されたシステムがあり、この調査では 3 つのテスト プラットフォームでそれらのパフォーマンス (レイテンシとスループット) を比較しました。
結果の精度と再現性を確保するために、この研究では、一般的に使用される LLM データセット alpaca の命令、入力、出力の平均長、つまり 350 トークンを計算しました。サンプルごとに、シーケンス長が 350 になるように文字列をランダムに生成します。
推論サービスでは、コンピューティング リソースを包括的に利用し、フレームワークの堅牢性と効率性を評価するために、すべてのリクエストがバースト モードでスケジュールされます。実験データセットは 1000 の合成文で構成され、各文には 512 個の入力トークンが含まれています。この調査では、結果の一貫性と比較可能性を確保するために、同じ GPU プラットフォームでのすべての実験で「生成されたトークンの最大長」パラメーターを常に維持しています。
元の意味、プロセス全体のパフォーマンスを変更する必要はありません
この調査事前トレーニングと微調整に合格し、異なるサイズ (7B、13B、70B) の Llama2 モデルのステップ時間、スループット、メモリ消費量を推測して、元の意味を変えることなく 3 つのテスト プラットフォームで完全なパフォーマンスを測定します。広く使用されている 3 つの推論サービス システムである TGI、vLLM、LightLLM も、レイテンシ、スループット、メモリ消費量などのメトリクスに焦点を当てて評価されます。
モジュール レベルのパフォーマンス
LLM は通常、一連のモジュール (またはレイヤー) で構成されます。 )、これらのモジュールは独自のコンピューティングおよび通信特性を備えている場合があります。たとえば、Llama2 モデルを構成する主要なモジュールは、Embedding、LlamaDecoderLayer、Linear、SiLUActivation、LlamaRMSNorm です。
プレトレーニング結果
プレトレーニング実験セッションでは、研究者はまず、異なるサイズのモデル (7B、13B、および 70B) のプレトレーニングを分析しました。 3 つのテスト プラットフォームのパフォーマンス (反復時間またはスループット、メモリ消費量) をテストし、モジュール レベルと運用レベルでマイクロ ベンチマークを実施しました。
元の意味、プロセス全体のパフォーマンスを変更する必要はありません
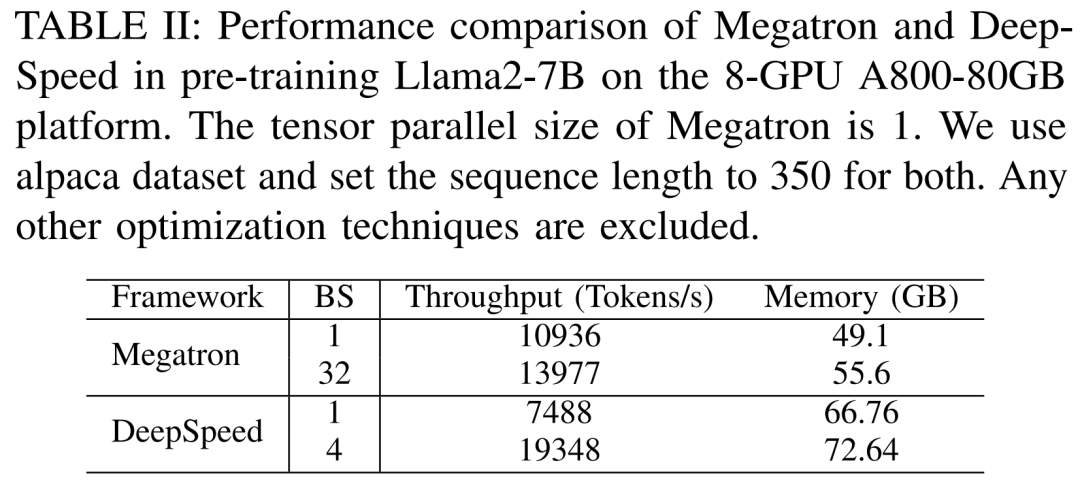
研究者最初に、Megatron-LM と DeepSpeed のパフォーマンスを比較する実験を実施しました。どちらも、A800-80GB サーバーで Llama2-7B を事前トレーニングする際に、メモリ最適化テクノロジ (ZeRO など) を使用しませんでした。
彼らは 350 のシーケンス長を使用し、Megatron-LM と DeepSpeed に対して 1 から最大バッチ サイズまでの 2 セットのバッチ サイズを提供しました。トレーニング スループット (トークン/秒) とコンシューマ GPU メモリ (GB 単位) に対してベンチマークされた結果を以下の表 II に示します。
結果は、バッチ サイズが 1 の場合、Megatron-LM が DeepSpeed よりわずかに高速であることを示しています。ただし、バッチサイズが最大に達した場合のトレーニング速度は DeepSpeed が最も速くなります。バッチ サイズが同じ場合、DeepSpeed はテンソル並列ベースの Megatron-LM よりも多くの GPU メモリを消費します。バッチ サイズが小さい場合でも、両方のシステムが大量の GPU メモリを消費し、RTX4090 または RTX3090 GPU サーバーでメモリ オーバーフローを引き起こしました。
Llama2-7B (シーケンス長 350、バッチ サイズ 2) をトレーニングするとき、研究者は量子化を備えた DeepSpeed を使用して、さまざまなスケーリング効率を研究しました。ハードウェアプラットフォーム。結果は以下の図 4 に示されており、A800 はほぼ直線的にスケーリングしますが、RTX4090 と RTX3090 のスケーリング効率はそれぞれ 90.8% と 85.9% とわずかに低くなります。 RTX3090 プラットフォームでは、NVLink 接続は NVLink を使用しない場合よりも 10% 効率が高くなります。
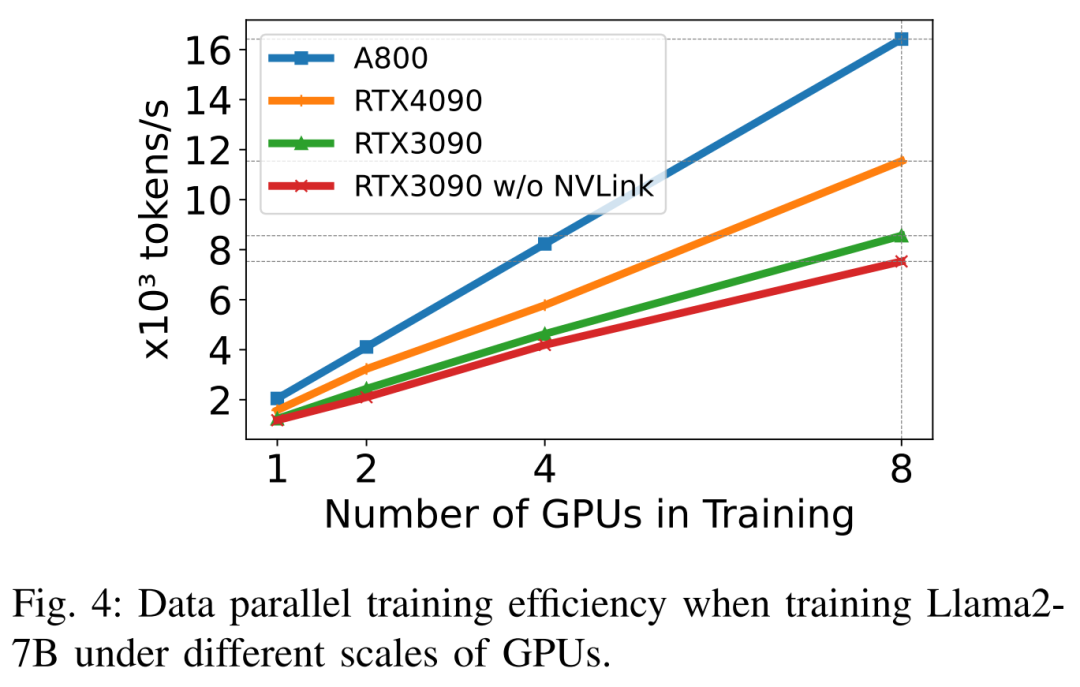
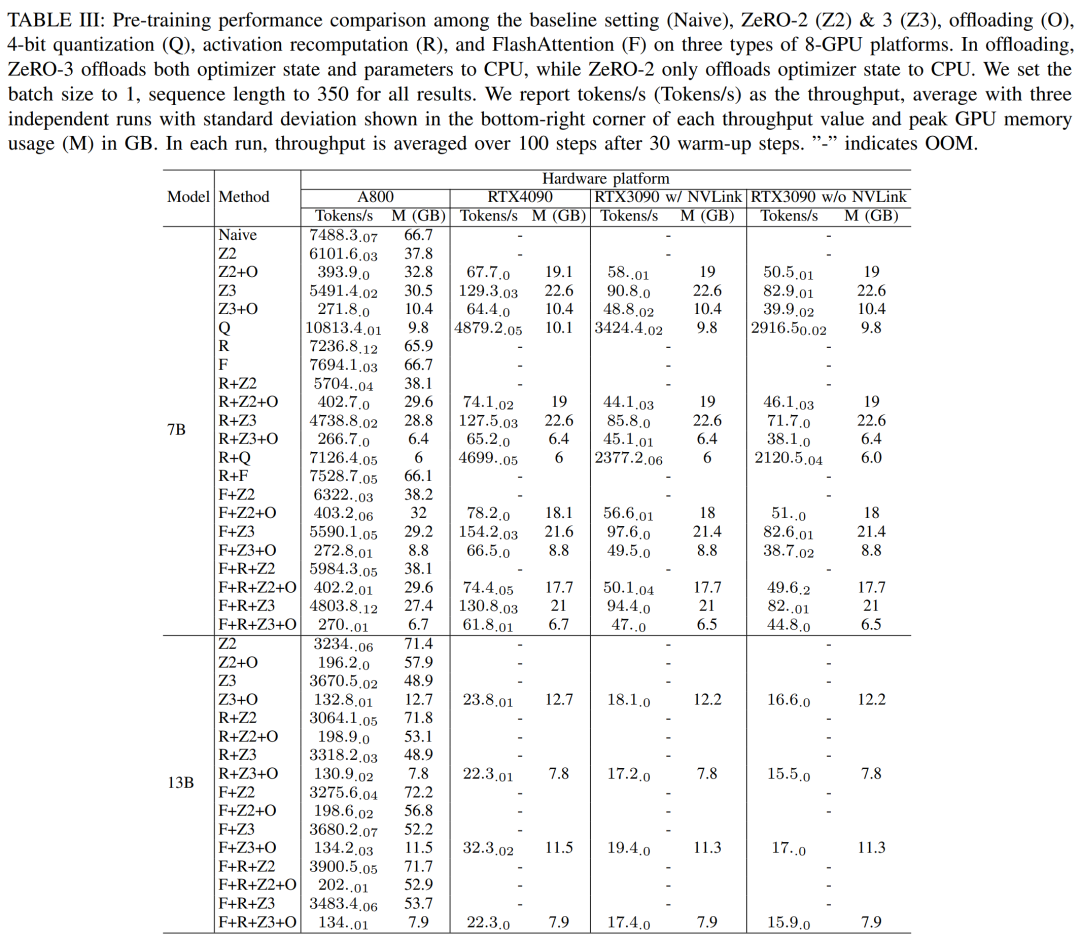
研究者らは、DeepSpeed を使用して、さまざまなメモリと計算効率の高い方法でのトレーニング パフォーマンスを評価しました。公平性を保つために、すべての評価はシーケンス長 350、バッチ サイズ 1、およびデフォルトのロードされたモデルの重み bf16 に設定されます。
オフロード機能を備えた ZeRO-2 および ZeRO-3 の場合、オプティマイザー状態とオプティマイザー状態モデルをそれぞれ CPU RAM にオフロードします。量子化には、デュアル量子化を備えた 4 ビット構成が使用されました。 NVLink が無効になっている場合 (つまり、すべてのデータが PCIe バス経由で転送される場合) の RTX3090 のパフォーマンスも報告されています。結果を以下の表3に示す。
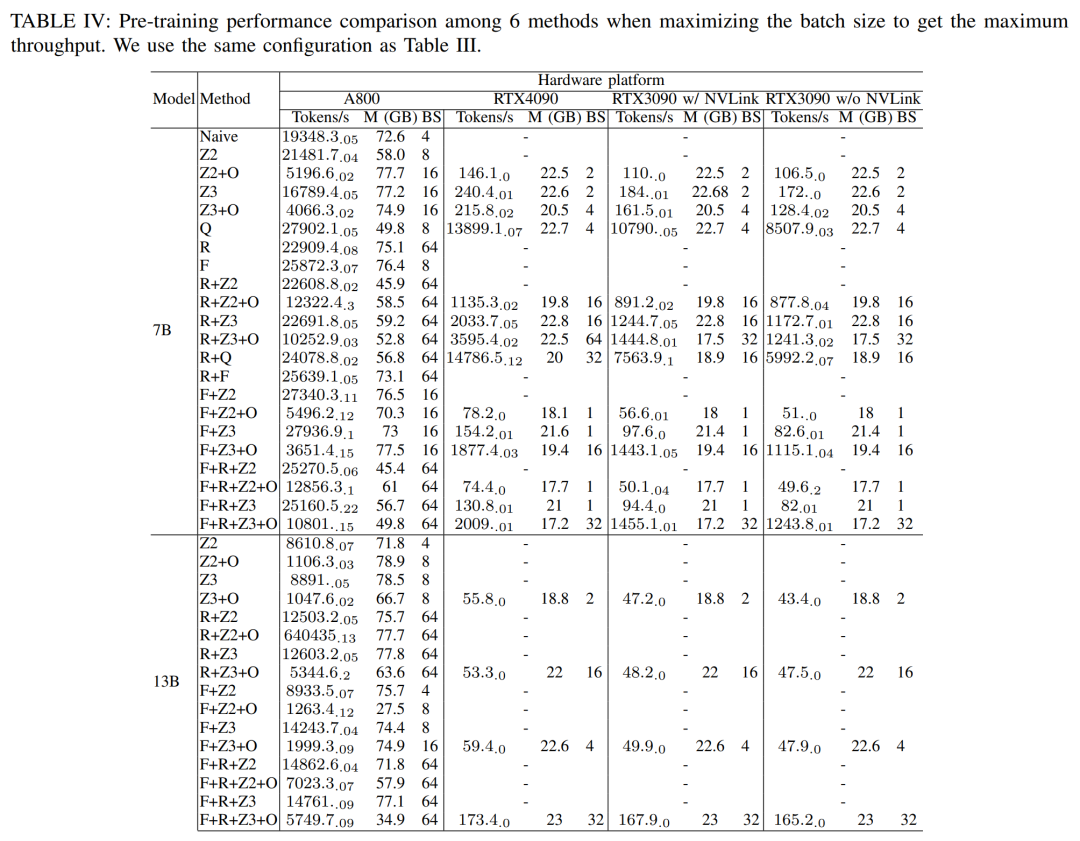
#最大のスループットを得るために、研究者らは各メソッドのバッチ サイズを最大化することで、さまざまな GPU サーバーのコンピューティング能力をさらに活用しました。結果を表 IV に示します。これは、バッチ サイズを増やすことでトレーニング プロセスを簡単に改善できることを示しています。したがって、高帯域幅と大容量メモリを備えた GPU サーバーは、コンシューマ グレードの GPU サーバーよりもフルパラメータ混合精度トレーニングに適しています
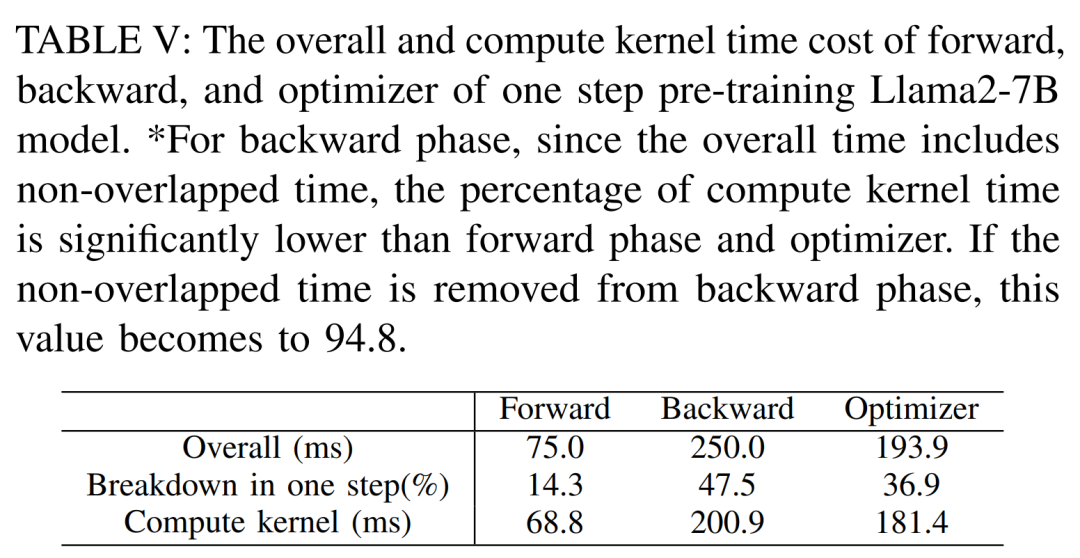
モジュール レベルの分析
以下の表 V は、シングルステップで事前トレーニングされた Llama2 のフォワード、バックワード、およびオプティマイザーの全体的な計算コア時間を示しています。 -7Bモデルのコスト。逆方向フェーズの場合、合計時間には非重複時間が含まれるため、計算コア時間は順方向フェーズおよびオプティマイザーよりもはるかに小さくなります。逆位相から非重複時間を除くと94.8となる。
FlashAttendant の影響を再計算して再評価する必要があります
#事前トレーニングを高速化する手法は、メモリの節約、バッチ サイズの増加、コンピューティング コアの高速化の 2 つのカテゴリに大別できます。以下の図 5 に示すように、GPU は、順方向フェーズ、逆方向フェーズ、およびオプティマイザー フェーズ中にアイドル時間の 5 ~ 10% を費やします。
研究者らは、このアイドル時間はバッチ サイズが小さいことが原因であると考え、利用可能な最大のバッチ サイズですべての手法をテストしました。最終的に、再計算を使用してバッチ サイズを増やし、FlashAttendant を使用してコア分析を高速化しました。
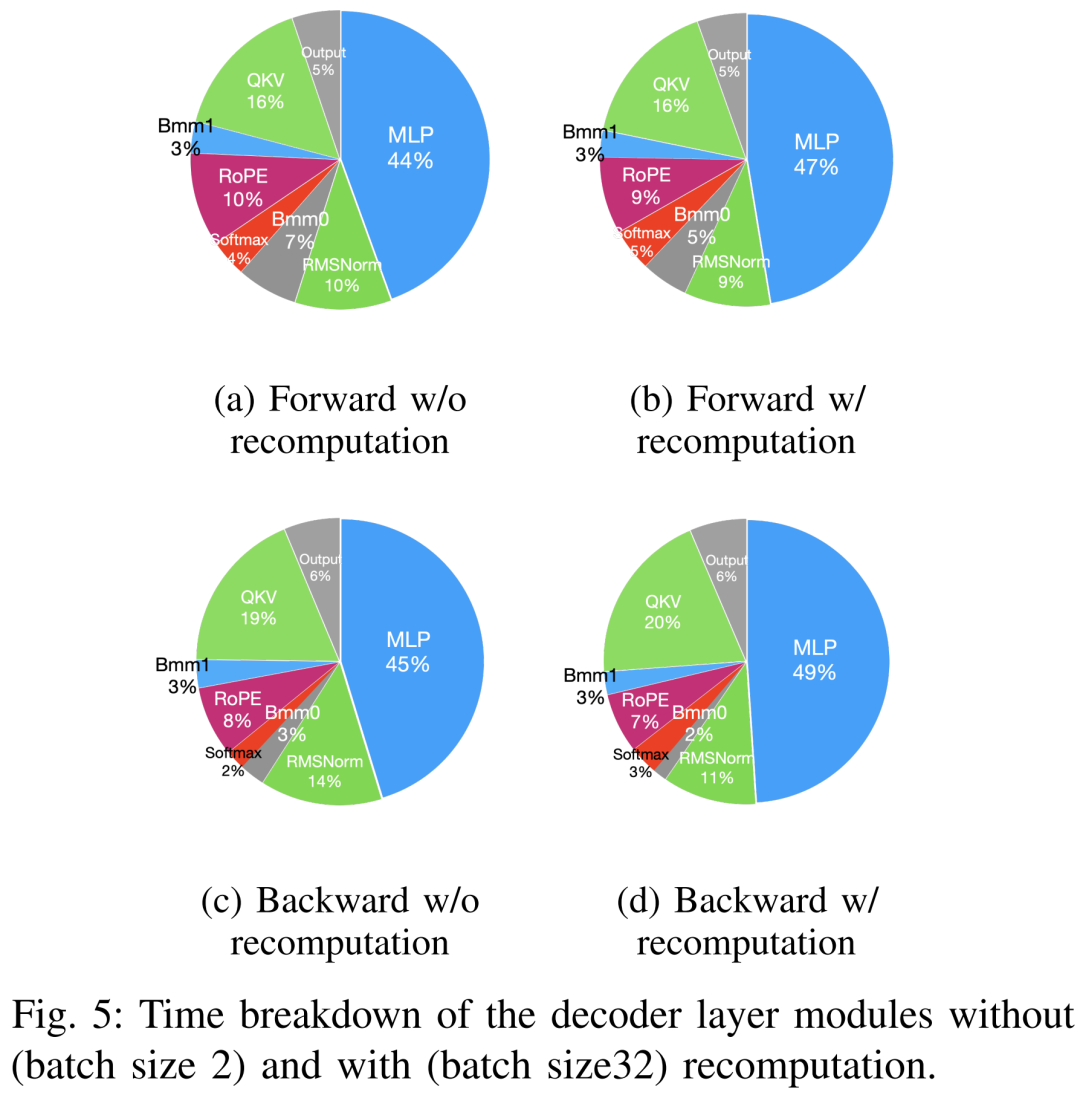
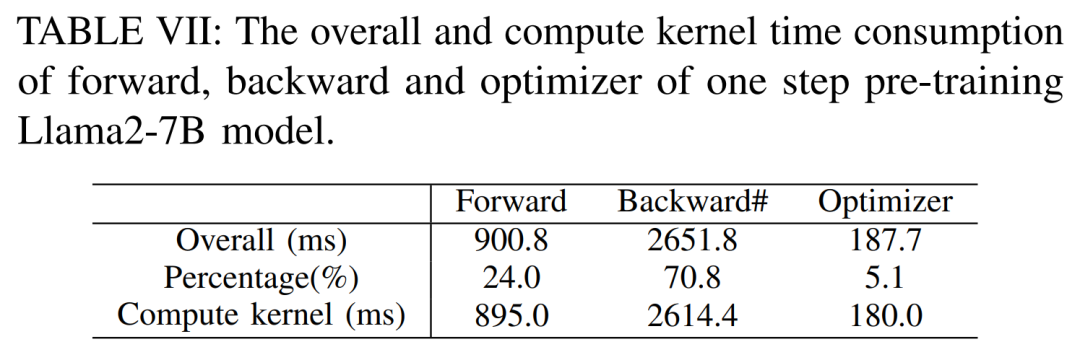
以下の表 VII に示すように、バッチ サイズが増加すると、順方向フェーズと逆方向フェーズの時間が大幅に増加し、GPU のアイドル時間がほとんどなくなります。
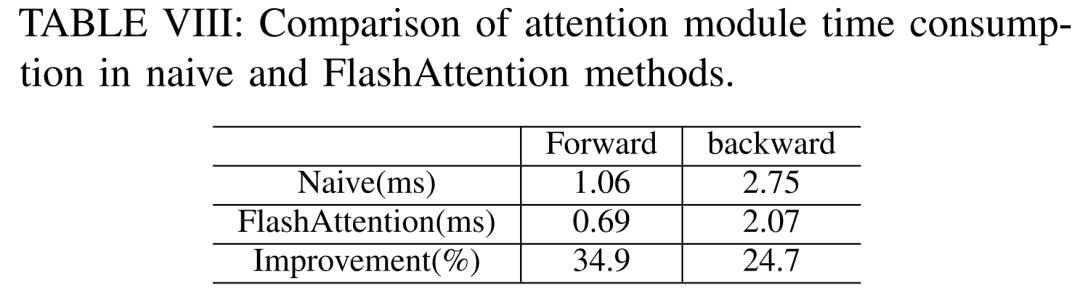
#以下の表 VIII によると、FlashAttendant は前方注意モジュールと後方注意モジュールをそれぞれ 34.9% と 24.7% 加速できます
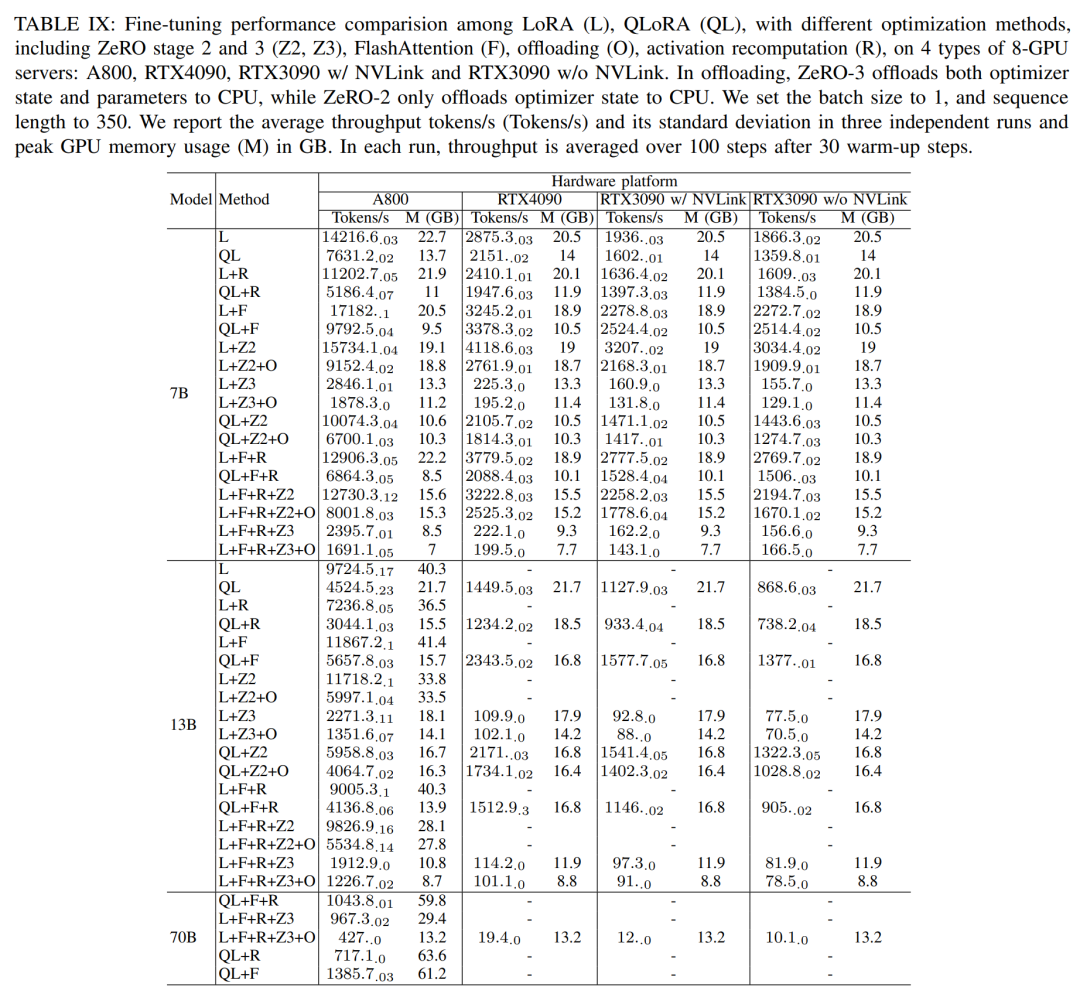
微調整セッションでは、研究者は主にパラメータ効率の良い微調整方法 (PEFT) について議論しました。 ) を示し、さまざまなモデル サイズとハードウェア設定の下で LoRA と QLoRA の微調整されたパフォーマンスを実証しました。シーケンス長 350、バッチ サイズ 1 を使用し、デフォルトでモデルの重みを bf16 にロードします。
以下の表 IX の結果によると、LoRA と QLoRA を使用して Llama2-13B を微調整した後のパフォーマンス傾向は、Llama2-7B と一致しています。 Llama2-7B と比較すると、微調整された Llama2-13B のスループットは約 30% 低下しました。
#推論結果
元の意味を変更する必要がなく、完全なパフォーマンス
以下の図 6 は、さまざまなハードウェア プラットフォームおよび推論フレームワークでのスループットの包括的な分析を示しています。Llama2-70B の関連推論データは省略されています。その中でも、TGI フレームワークは、特に RTX3090 や RTX4090 などの 24GB メモリを搭載した GPU で優れたスループットを実証しました。さらに、LightLLM は、A800 GPU プラットフォーム上で TGI および vLLM を大幅に上回り、スループットがほぼ 2 倍になっています。
これらの実験結果は、TGI 推論フレームワークが 24GB メモリ GPU プラットフォーム上で優れたパフォーマンスを発揮する一方、LightLLM 推論フレームワークが A800 80GB GPU プラットフォーム上で最高のスループットを示すことを示しています。この発見は、LightLLM が A800/A100 シリーズの高性能 GPU 向けに特に最適化されていることを示唆しています。
#さまざまなハードウェア プラットフォームと推論フレームワークにおける遅延パフォーマンスを図 7、8、9、10 に示します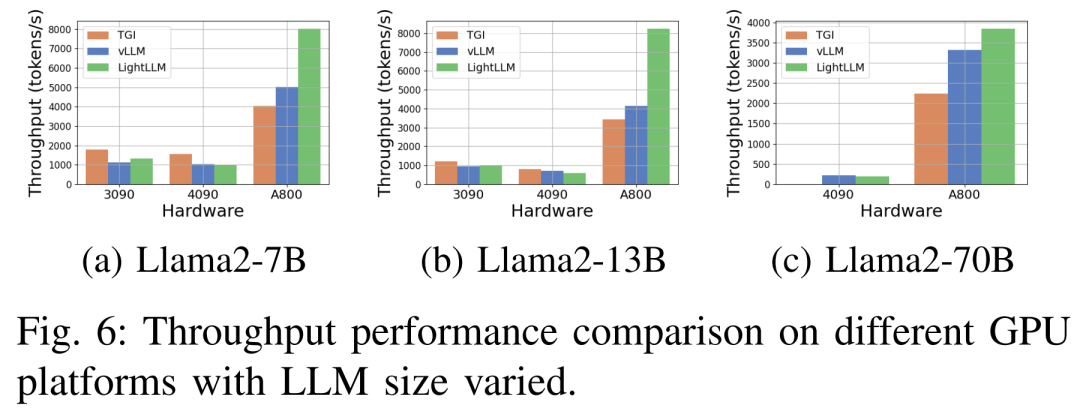
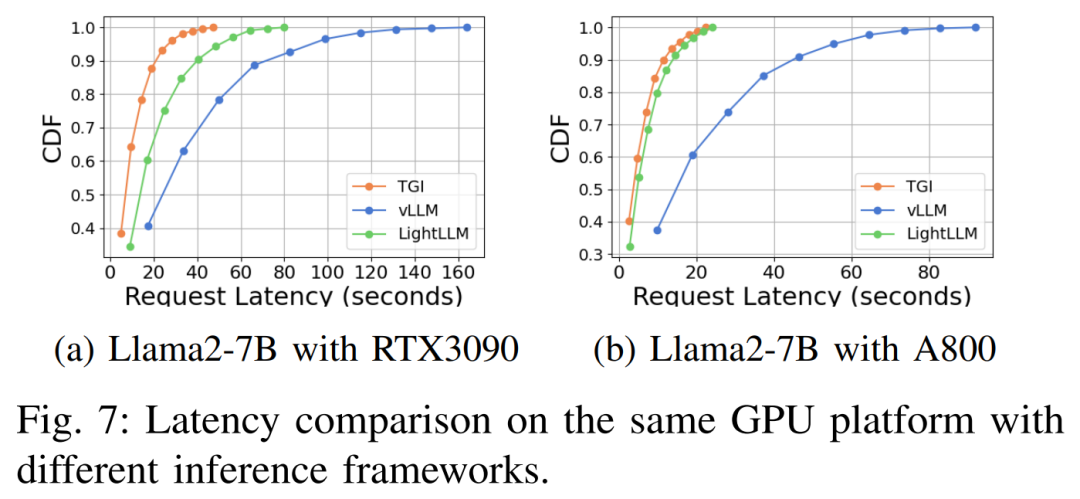
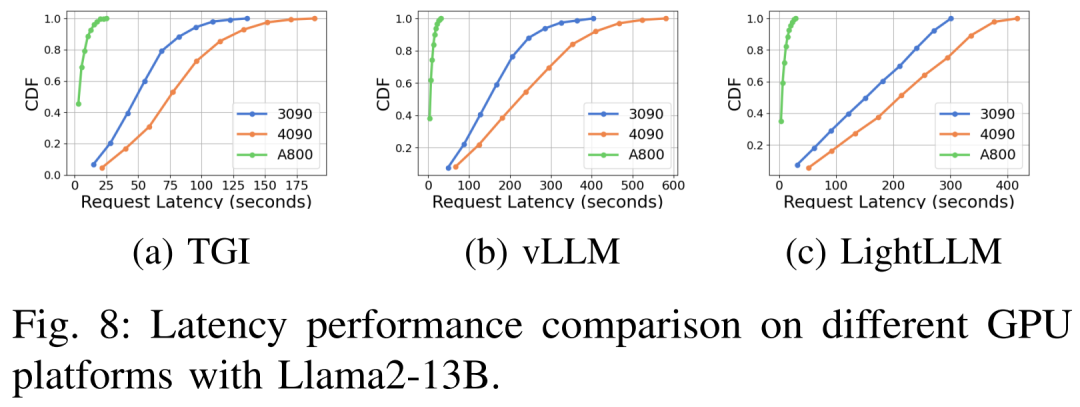
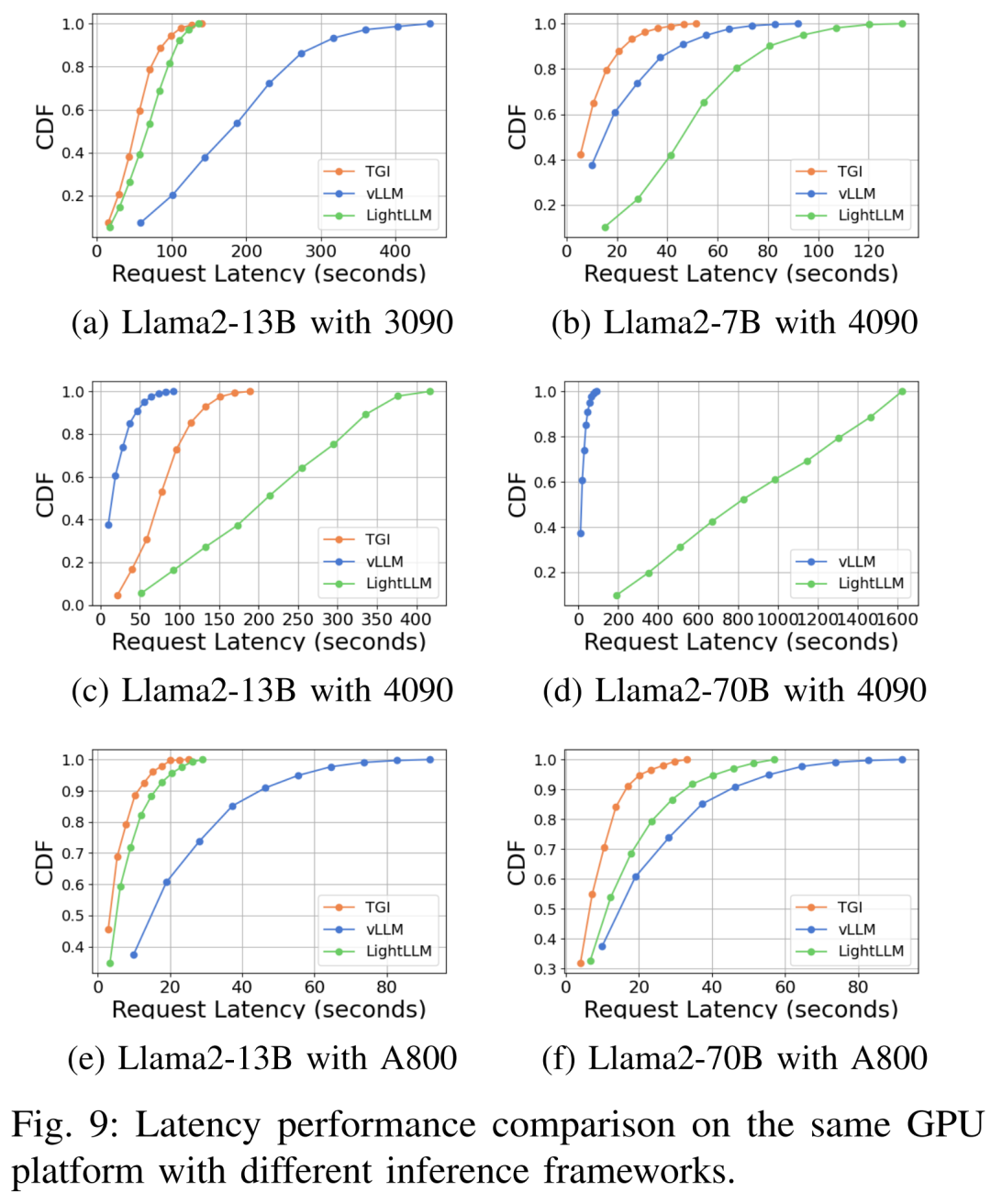
上に示したように、A800 プラットフォームは、スループットと遅延の点で、2 つのコンシューマー グレード プラットフォーム RTX4090 および RTX3090 よりも大幅に優れています。また、2 つのコンシューマ グレード プラットフォームの中で、RTX3090 は RTX4090 よりもわずかに優れています。 3 つの推論フレームワーク TGI、vLLM、および LightLLM は、コンシューマ グレードのプラットフォームで実行する場合、スループットに大きな違いはありません。比較すると、TGI はレイテンシの点で他の 2 つを常に上回っています。 A800 GPU プラットフォームでは、LightLLM はスループットの点で最高のパフォーマンスを発揮し、レイテンシも TGI フレームワークに非常に近くなります。 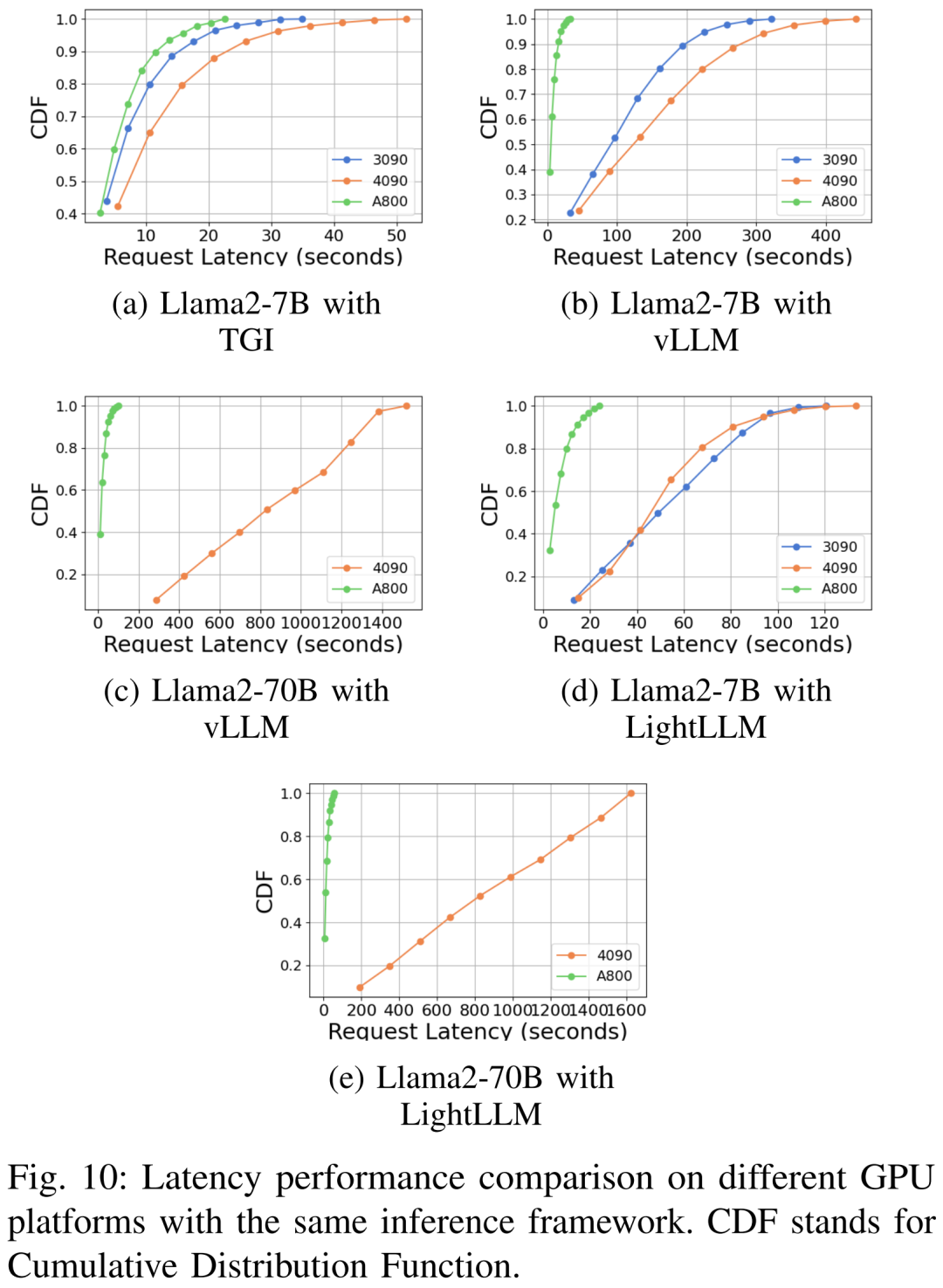
以上がA800 は Llama2 推論 RTX3090 および 4090 を大幅に上回り、優れたレイテンシーとスループットを実現します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

人気の記事


人気の記事

ホットな記事タグ

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7308
7308
 9
1623
14
1344
46
1259
25
1207
29
9
1623
14
1344
46
1259
25
1207
29

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
