

大規模モデルでは、簡単な会話だけで画像に注釈を付けることができます。清華大学とNUSの研究結果

マルチモーダル大規模モデルに検出およびセグメンテーション モジュールが統合された後、画像の切り出しが容易になります。
私たちのモデルは、自然言語の説明を通じて探しているオブジェクトにすばやくラベルを付け、テキストによる説明を提供して、タスクを簡単に完了できるようにします。
シンガポール国立大学の NExT 研究室と清華大学の Liu Zhiyuan チームによって開発された新しいマルチモーダル大規模モデルは、私たちに強力なサポートを提供します。このモデルは、パズルを解くプロセス中にプレイヤーに包括的なヘルプとガイダンスを提供するために慎重に作成されています。複数のモダリティからの情報を組み合わせて、プレーヤーに新しいパズル解決方法と戦略を提示します。このモデルの適用はプレイヤーに利益をもたらします

GPT-4v の発売により、マルチモーダル分野では LLaVA、BLIP-2 などの一連の新しいモデルが導入されました。 、など待ってください。これらのモデルの出現は、マルチモーダル タスクのパフォーマンスと有効性の向上に大きく貢献しました。
マルチモーダル大規模モデルの地域理解能力をさらに向上させるために、研究チームはNExT-Chatと呼ばれるマルチモーダルモデルを開発しました。このモデルには、対話、検出、セグメンテーションを同時に実行する機能があります。
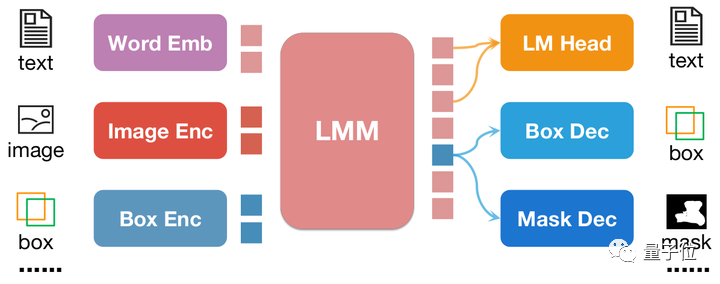
NExT-Chat の最大のハイライトは、マルチモーダル モデルに位置入出力を導入できることです。この機能により、NExT-Chat は対話中にユーザーのニーズをより正確に理解し、応答できるようになります。 NExT-Chat は、位置入力を通じて、ユーザーの地理的位置に基づいて関連情報や提案を提供できるため、ユーザー エクスペリエンスが向上します。 NExT-Chat は、位置情報の出力を通じて、特定の地理的位置に関する関連情報をユーザーに伝え、より良い情報を提供することができます。
このうち、位置入力機能は、指定されたエリアに基づいて質問に答えることを指し、位置出力機能は、会話で言及されたオブジェクトの場所を指定します。これら 2 つの能力はパズル ゲームにおいて非常に重要です。

複雑な位置決め問題も解決できます:

オブジェクトの位置決めに加えて、NExT-Chat は記述も行うことができます画像またはその一部:
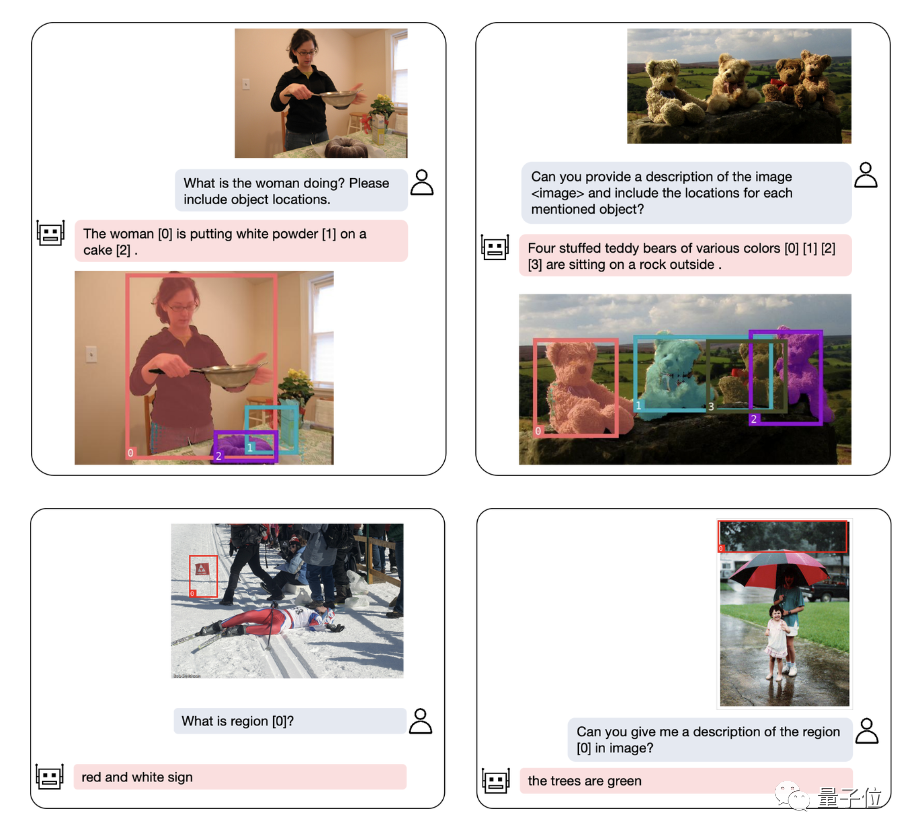
画像の内容を分析した後、NExT-Chat は取得した情報を使用して推論を行うことができます:

NExT-Chat のパフォーマンスを正確に評価するために、研究チームは複数のタスク データ セットに対してテストを実施しました。
複数のデータセットで SOTA を達成する
著者は最初に、参照表現セグメンテーション (RES) タスクに関する NExT-Chat の実験結果を示しました。
非常に少量のセグメンテーション データのみを使用しているにもかかわらず、NExT-Chat は、一連の教師ありモデル (MCN、VLT など) を破り、5 回の LISA メソッドを使用するなど、優れた参照セグメンテーション機能を実証しました。上記のセグメンテーション マスク アノテーションの場合。
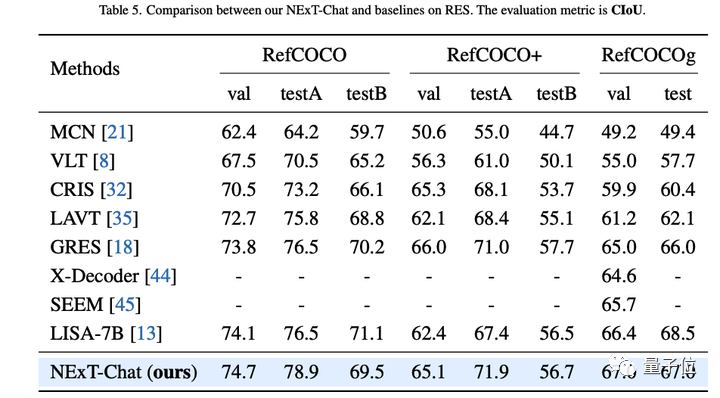
△RESタスクにおけるNExT-Chatの結果
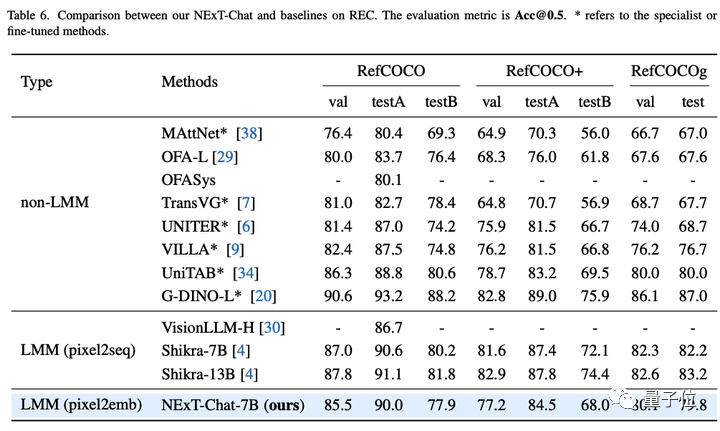
次に、研究チームはRECタスクにおけるNExT-Chatの実験結果を示しました。
以下の表に示すように、NExT-Chat は一連の教師ありメソッド (UNITER など) よりも優れた結果を達成できます。
興味深い発見は、NExT-Chat は同様のボックス トレーニング データを使用する Shikra よりも効果がわずかに低いということです。
作者は、これは、pix2emb 法の LM 損失と検出損失のバランスを取るのがより難しく、Shikra が既存の平文大規模モデルの事前学習形式に近いためであると推測しています。
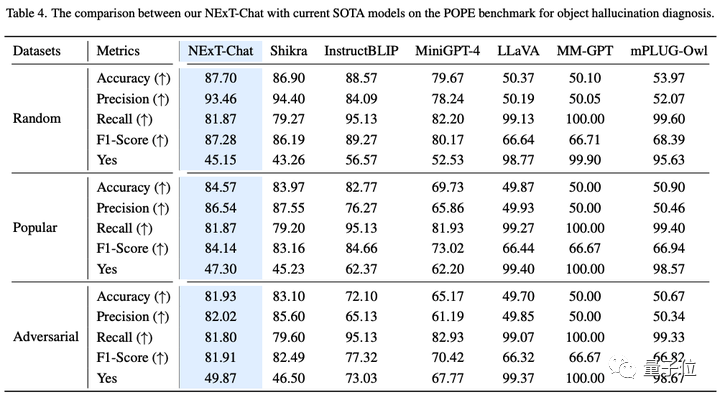
△POPE データセットでの NExT-Chat の結果
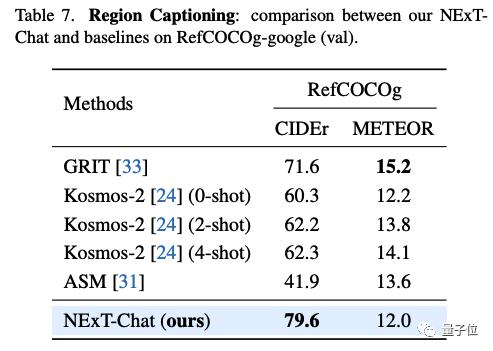
エリア記述タスクでは、NExT-Chat は最高の CIDEr パフォーマンスを達成することもでき、このインジケーターの 4 ショットのケースでは Kosmos- を上回ります。 2.
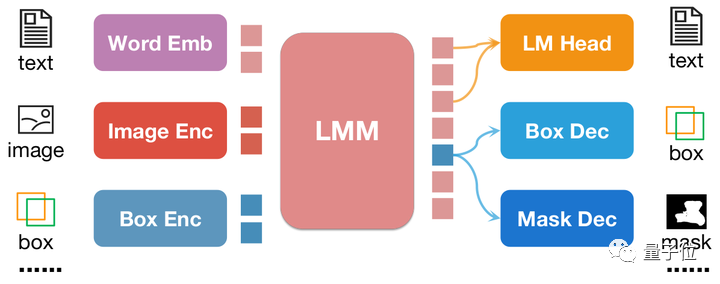 # △pix2emb メソッドの簡単な例
# △pix2emb メソッドの簡単な例
上図に示すように、位置入力は、対応するエンコーダーによって位置埋め込みにエンコードされ、出力されます。位置の埋め込みはボックス デコーダーとマスク デコーダーを介してボックスとマスクに変換されます。
これには 2 つの利点があります。
モデルの出力形式は、セグメンテーション マスクなどのより複雑な形式に簡単に拡張できます。- モデルは、タスク内の既存の実用的なメソッドを簡単に見つけることができます。たとえば、この記事の検出損失は L1 損失と GioU 損失を使用しています (pix2seq は損失の生成にテキストのみを使用できます)。このマスク デコーダは、この記事では、既存のメソッドである SAM を使用して初期化を行っています。
- pix2seq と pix2emb を組み合わせることで、著者は新しい NExT-Chat モデルをトレーニングしました。
NExT-Chat モデル
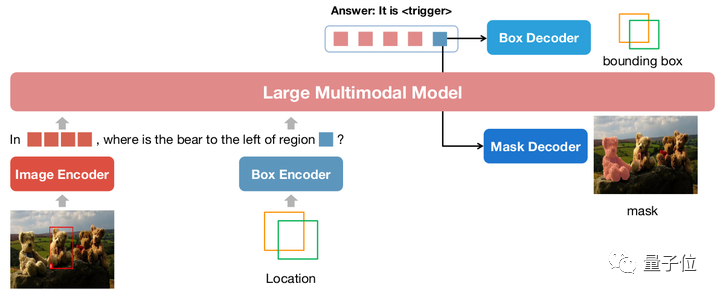 △NExT-Chat モデル アーキテクチャ
△NExT-Chat モデル アーキテクチャ
NExT-Chat は全体として LLaVA アーキテクチャを採用しています。画像エンコーダを介して画像情報をエンコードし、LLM に入力して理解します。これに基づいて、対応するボックス エンコーダと 2 つの位置出力のデコーダが追加されます。
LLM が言語の LM ヘッドまたは位置デコーダをいつ使用するかわからないという問題を解決するために、NExT-Chat は位置情報を識別するための新しいトークン タイプをさらに導入します。
モデルが出力する場合、トークンの埋め込みは、言語デコーダーではなく、デコードのために対応する位置デコーダーに送信されます。
さらに、入力ステージと出力ステージでの位置情報の一貫性を維持するために、NExT-Chat では追加の位置合わせ制約が導入されています:
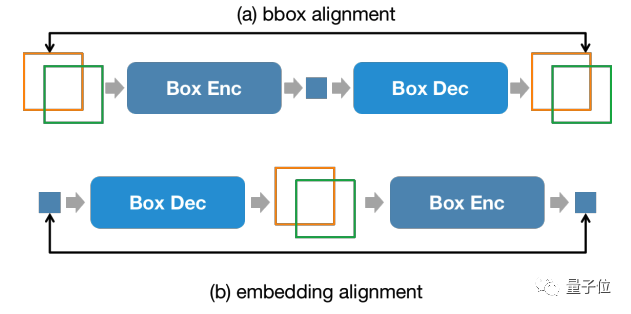 △位置入力、出力制約
△位置入力、出力制約
上図に示すように、ボックスと位置埋め込みはそれぞれデコーダ、エンコーダ、デコーダ-エンコーダを介して結合され、前後で変更しないことが要求されます。
著者は、この方法が位置入力機能の収束を大幅に促進できることを発見しました。
NExT-Chat のモデル トレーニングには主に 3 つの段階があります:
第 1 段階: トレーニング モデル- 基本的なボックスの入出力の基本機能
- 。 NExT-Chat は、Flickr-30K、RefCOCO、VisualGenome、および事前トレーニング用のボックス入出力を含むその他のデータセットを使用します。トレーニング プロセス中に、すべての LLM パラメータがトレーニングされます。 第 2 段階: LLM の命令追従能力を調整します
- 。 Shikra-RD、LLaVA-instruct、およびその他の命令を通じてデータを微調整すると、モデルが人間の要件によりよく応答し、より人間らしい結果を出力できるようになります。 第 3 段階: NExT-Chat モデルにセグメンテーション機能を付与します
- 。上記の 2 つのトレーニング段階を通じて、モデルはすでに優れた位置モデリング機能を備えています。著者はこの機能をさらに拡張して、出力をマスクします。実験の結果、非常に少量のマスク注釈データとトレーニング時間 (約 3 時間) を使用することで、NExT-Chat はすぐに優れたセグメンテーション機能を実現できることがわかりました。 このようなトレーニング プロセスの利点は、検出フレーム データが豊富であり、トレーニングのオーバーヘッドが小さいことです。
NExT-Chat は、豊富な検出フレーム データに基づいて基本的な位置モデリング機能をトレーニングし、より困難で注釈が少ないセグメンテーション タスクにすぐに拡張できます。
以上が大規模モデルでは、簡単な会話だけで画像に注釈を付けることができます。清華大学とNUSの研究結果の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7752
7752
 15
1643
14
1398
52
1293
25
1234
29
15
1643
14
1398
52
1293
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
