

心の知能指数が高く、手を伸ばせばすぐに次の行動に協力してくれるNPCが登場します。

仮想現実、拡張現実、ゲーム、人間とコンピューターの対話の分野では、多くの場合、仮想キャラクターが画面外のプレイヤーと対話できるようにする必要があります。このインタラクションはリアルタイムであり、仮想キャラクターがオペレーターの動きに応じて動的に調整する必要があります。アバターで椅子を動かすなど、一部のインタラクションにはオブジェクトが関与するため、オペレーターの手の正確な動きに特別な注意が必要です。インテリジェントでインタラクティブな仮想キャラクターの出現は、人間のプレイヤーと仮想キャラクターの間の社会体験を大幅に強化し、新しいエンターテイメントの方法をもたらします。
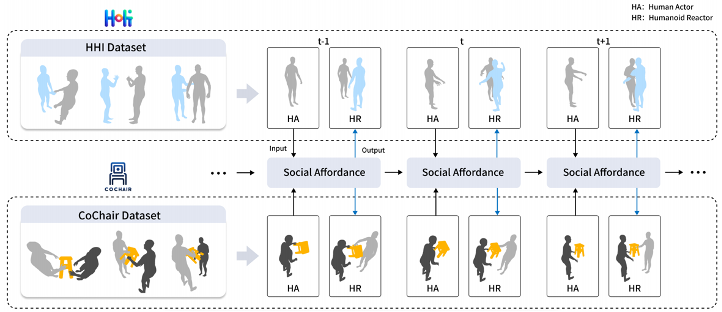
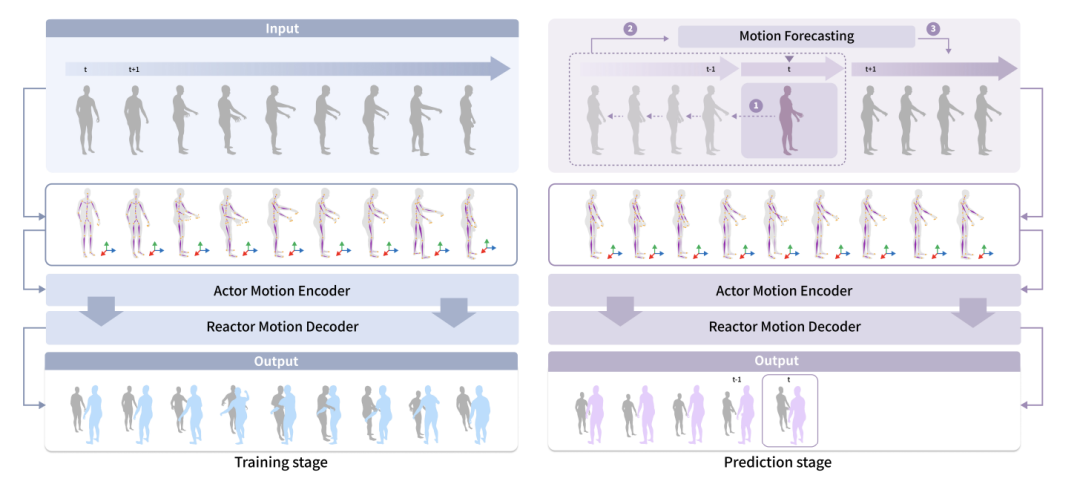
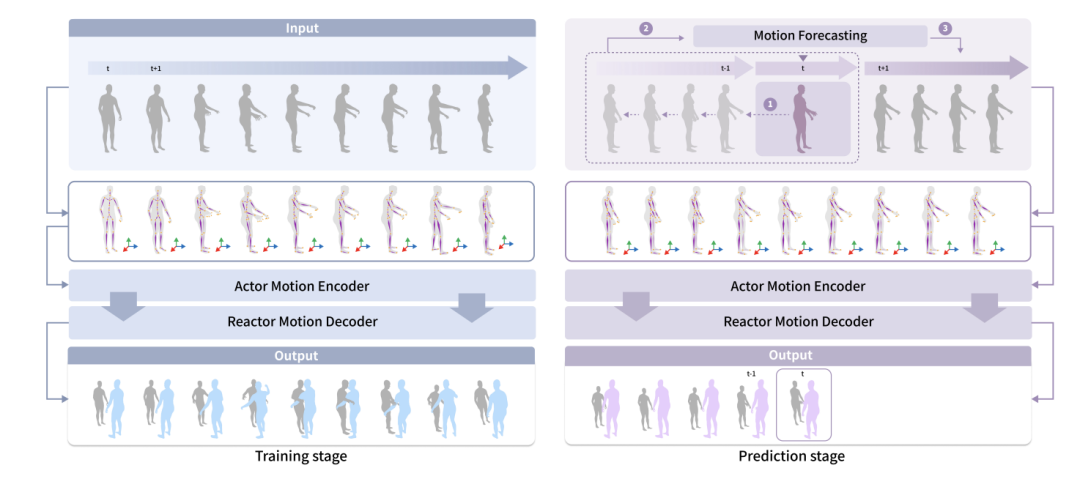
本研究では、人間と仮想人間の間のインタラクションタスク、特に物体を伴うインタラクションタスクに焦点を当て、オンライン全身動作応答合成と呼ばれる新しいタスクを提案します。新しいタスクは、人間の動きに基づいて仮想人間の反応を生成します。これまでの研究は主に人間と人間のインタラクションに焦点を当てており、タスク内のオブジェクトは考慮されておらず、生成される身体反応には手の動きは含まれていませんでした。また、これまでの作品ではタスクをオンライン推論として扱っておらず、実際の状況では仮想人間が実装状況に基づいて次のステップを予測します。
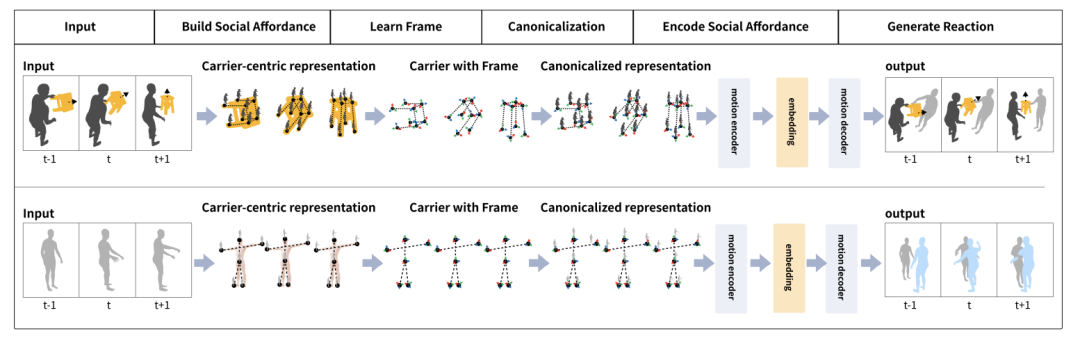
新しいタスクをサポートするために、著者らはまず、それぞれ HHI と CoChair という名前の 2 つのデータセットを構築し、統一された手法を提案しました。具体的には、著者はまず社会的アフォーダンス表現を構築します。これを行うために、彼らは社会的アフォーダンス ベクトルを選択し、SE (3) 等変ニューラル ネットワークを使用してベクトルのローカル座標系を学習し、最後にその社会的アフォーダンスを正規化します。さらに、著者は仮想人間が予測に基づいて意思決定できるようにするための社会的アフォーダンス予測のスキームも提案しています。
研究結果によると、この方法は HHI および CoChair データセットに対して高品質のリアクション アクションを効果的に生成でき、1 秒あたり 25 フレームのリアルタイム推論速度を達成できます。 A100。さらに、著者らは、既存の人間のインタラクション データセットである Interhuman および Chi3D での検証を通じて、この手法の有効性も実証しています。

詳細については、次の論文アドレスを参照してください。 [https://arxiv.org/pdf/2312.08983.pdf]。これがパズルを解く方法を探しているプレイヤーの助けになれば幸いです。
謎解き方法の詳細については、プロジェクトのホームページ https://yunzeliu.github.io/iHuman/ をご覧ください。
データセット構築
この記事では、オンラインの全身動作反応合成タスクをサポートするために、著者は 2 つのデータセットを構築しました。 1 つは 2 人によるインタラクションのデータセット HHI で、もう 1 つは 2 人によるオブジェクトとのインタラクションのデータセット CoChair です。これら 2 つのデータセットは、全身運動合成の分野をさらに調査するための貴重なリソースを研究者に提供します。 HHI データセットは 2 人の人物間のさまざまなインタラクションを記録し、CoChair データセットは 2 人の人物とオブジェクト間のインタラクションを記録します。これらのデータ セットの確立により、研究者はより多くの実験を行うことができます
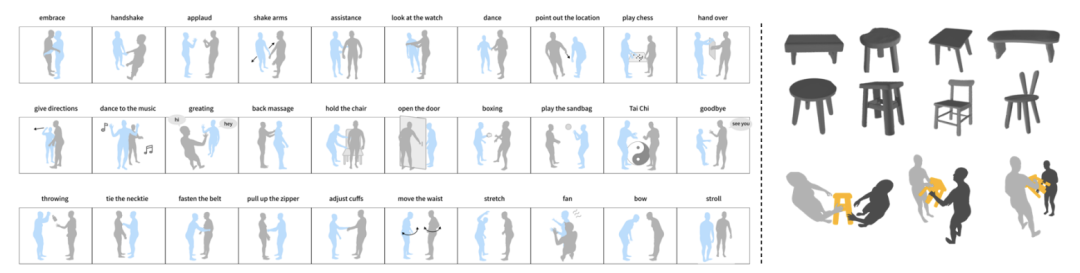
HHI データ セットは、大規模な全身動作反応データ セットです。インタラクション カテゴリ、10 ペアの人間の骨格タイプ、合計 5000 のインタラクション シーケンス。
#HHI データセットには 3 つの特徴があります。 1 つ目の特徴は、体と手のインタラクションを含む、複数人の全身インタラクションが含まれていることです。著者は、複数人での交流においては手の相互作用を無視することはできず、握手やハグ、引き継ぎなど手を通じて豊富な情報が伝達されると考えています。 2 番目の特徴は、HHI データセットが行動の開始者と応答者を明確に区別できることです。たとえば、握手、方向の指さし、挨拶、引き継ぎなどの状況において、HHI データセットはアクションの開始者を特定できるため、研究者が問題をより適切に定義して評価するのに役立ちます。 3 番目の特徴は、HHI データセットには、より多様なタイプのインタラクションと反応が含まれていることです。2 人の人物間の 30 種類のインタラクションだけでなく、同じアクターに対する複数の合理的な反応も含まれています。たとえば、誰かがあなたに挨拶したとき、うなずいたり、片手、または両手で応答したりすることができます。これも自然な特徴ですが、これまでのデータセットではほとんど注目されず、議論されていませんでした。CoChair は、大規模な複数人およびオブジェクトのインタラクション データセットであり、8 つの異なる椅子、5 つのインタラクション モード、10 ペアの異なるスケルトン、合計 3000 のシーケンスが含まれています。 CoChair には 2 つの重要な特徴があります。 まず、CoChair にはコラボレーション プロセスにおける情報の非対称性があります。すべてのアクションには、実行者/開始者 (持ち込み荷物の目的地を知っている) と応答者 (目的地を知らない) がいます。第二に、さまざまな持ち運びモードがあります。データセットには、片手固定キャリー、片手移動キャリー、両手固定キャリー、両手移動キャリー、両手フレキシブルキャリーの 5 つの持ち運びモードが含まれています。 ソーシャル アフォーダンス ベクトルは、ソーシャル アフォーダンス情報をエンコードする物体または人を指します。人間が仮想人間と対話するとき、通常、人間は直接的または間接的に仮想人間と接触することになる。そして、物に関して言えば、人間は通常、物に触れます。 インタラクションにおける直接的または潜在的な接触情報をシミュレートするには、人間、ベクトル自体、およびそれらの間の関係を同時に表すベクトルを選択する必要があります。この研究では、キャリアとは、人間が接触する可能性のある物体または仮想人間テンプレートを指します。 これに基づいて、著者は社会的アフォーダンスのキャリア中心の表現を定義します。具体的には、ベクトルが与えられると、人間の行動をエンコードして、密な人間と車両の共同表現を取得します。この表現に基づいて、著者らは、人間の行動の動き、ベクトルの動的幾何学的特性、および各タイムステップでの人と車両の関係を含む社会的アフォーダンス表現を提案します。 ソーシャル アフォーダンス表現は、単一フレームの表現ではなく、開始時点から特定のタイム ステップまでのデータ フローを指すことに注意してください。この方法の利点は、キャリアの局所領域と人間の行動の動きを密接に関連付け、ネットワーク学習に便利な表現を形成することです。 著者は、ソーシャル アフォーダンス表現を通じて、表現空間を単純化するためにソーシャル アフォーダンス正規化をさらに採用します。最初のステップは、ベクトルのローカル フレームワークを学習することです。 SE (3) 等変ネットワークを通じて、キャリアのローカル座標系が学習されます。具体的には、まず人間の動作を各ローカル座標系の動作に変換する。次に、人間のキャラクターのアクションを各点の視点から高密度にエンコードして、高密度のベクトル中心のアクション表現を取得します。これは、「観察者」を車両上の各ローカル ポイントにバインドし、各「観察者」が一人称視点から人間の行動をコード化すると考えることができます。このアプローチの利点は、人間、仮想人間、およびオブジェクト間の接触によって生成される情報をモデル化しながら、ソーシャル アフォーダンスの正規化によってソーシャル アフォーダンスの分布が簡素化され、ネットワーク学習が促進されることです。 トレーニング段階では、仮想人間は人間のすべての行動を観察できます。現実世界の予測フェーズでは、仮想人間は人間の行動の過去のダイナミクスを観察することしかできません。提案された予測モジュールは、仮想人間の知覚を改善するために人間がとる行動を予測できます。著者らは、動き予測モジュールを使用して、人間のアクターの動作とオブジェクトの動作を予測します。 2 人の対話では、著者は HumanMAC を予測モジュールとして使用しました。 2 人の人物とオブジェクトのインタラクションでは、著者は InterDiff に基づいて動き予測モジュールを構築し、人物とオブジェクトの接触が安定しているという事前条件を追加して、オブジェクトの動きを予測する難しさを単純化しました。 ############実験############### 定量的テストにより、この調査方法がすべての指標において既存の方法よりも優れていることが示されています。この方法における各設計の有効性を検証するために、著者らは HHI データセットでアブレーション実験を実施しました。ソーシャル アフォーダンスの正規化がないと、この方法のパフォーマンスが大幅に低下することがわかります。これは、ソーシャル アフォーダンス正規化を使用して特徴空間の複雑さを簡素化する必要があることを示唆しています。ソーシャル アフォーダンスの予測がないと、私たちの方法は人間の俳優の行動を予測する能力を失い、パフォーマンスの低下につながります。ローカル座標系を使用する必要性を検証するために、グローバル座標系を使用した場合の効果も比較しましたが、ローカル座標系の方が大幅に優れていることがわかります。これは、ローカル座標系を使用してローカル ジオメトリと潜在的な接触を記述することの価値も示しています。 視覚化の結果から、過去と比較して、記事の方法を使用して訓練された仮想キャラクターはより速く反応し、より良くできることがわかります。ローカルのジェスチャーを正確にキャプチャし、共同でより現実的で自然な把握アクションを生成します。 研究の詳細については、元の論文を参照してください。 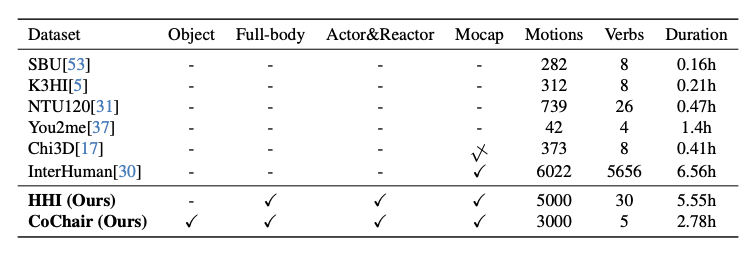
#方法
以上が心の知能指数が高く、手を伸ばせばすぐに次の行動に協力してくれるNPCが登場します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
16
10
15
1376
52
77
11
16
10

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
