

LLM は互いに戦うことを学び、基本モデルはグループの革新をもたらす可能性がある

金庸の武侠小説に左右格闘という武術スタントがあるが、これは周伯通が桃花島の洞窟で10年以上修行して編み出した武術である。自分の楽しみのために左手と右手を使って戦うという考えでした。幸せです。このアイデアは、武道の練習に使用できるだけでなく、ここ数年で大流行した敵対的生成ネットワーク (GAN) などの機械学習モデルのトレーニングにも使用できます。
今日のラージ モデル (LLM) の時代において、研究者は左右の相互作用の微妙な使用法を発見しました。最近、カリフォルニア大学ロサンゼルス校のGu Quanquan氏のチームは、SPIN (Self-Play Fine-Tuning) と呼ばれる新しい方法を提案しました。この方法では、追加の微調整データを使用せずに、セルフ ゲームのみで LLM の機能を大幅に向上させることができます。 Gu Quanquan 教授は次のように述べています。「誰かに釣りを教えるよりも、釣りを教えるほうが良いのです。セルフゲーム微調整 (SPIN) を通じて、すべての大型モデルを弱い状態から強い状態に改善することができます。」
この研究はソーシャル ネットワークでも多くの議論を引き起こしました。たとえば、ペンシルベニア大学ウォートン スクールのイーサン モリック教授は次のように述べています。「さらなる証拠は、 AI は、人間が作成したコンテンツのトレーニングに利用できるリソースによって制限されません。この論文は、AI が作成したデータを使用して AI をトレーニングすると、人間が作成したデータのみを使用するよりも高品質の結果を達成できることを再度示しています。」
さらに、多くの研究者がこの手法に興奮しており、2024 年の関連方向の進歩に大きな期待を寄せています。 Gu Quanquan 教授は Machine Heart に対し、「GPT-4 を超える大規模モデルをトレーニングしたい場合、これは間違いなく試してみる価値のあるテクノロジーです。」

論文のアドレスは https://arxiv.org/pdf/2401.01335.pdf です。
大規模言語モデル (LLM) は、複雑な推論と専門知識を必要とする幅広いタスクを解決する並外れた機能を備えた、汎用人工知能 (AGI) の画期的な時代の到来をもたらしました。 LLM の専門分野には、数学的推論/問題解決、コード生成/プログラミング、テキスト生成、要約とクリエイティブライティングなどが含まれます。
LLM の主な進歩の 1 つは、トレーニング後の調整プロセスです。これにより、モデルが要件に沿って動作するようになりますが、このプロセスは多くの場合、コストのかかる人間がラベル付けしたデータに依存します。古典的な調整方法には、人間のデモンストレーションに基づく教師あり微調整 (SFT) と人間の好みのフィードバック (RLHF) に基づく強化学習が含まれます。
これらの位置合わせ方法はすべて、人間がラベル付けした大量のデータを必要とします。したがって、位置合わせプロセスを合理化するために、研究者らは人間のデータを効果的に活用する微調整方法を開発したいと考えています。
これは、この研究の目標でもあります。新しい微調整手法を開発して、微調整されたモデルが引き続き強力になるようにすることです。この微調整プロセスには、データセットの微調整以外での人間の使用 データにラベルを付ける。
実際、機械学習コミュニティは、追加のトレーニング データを使用せずに、弱いモデルを強力なモデルに改善する方法に常に関心を持ってきました。この分野の研究は、ブースティングにまで遡ることができます。アルゴリズム。研究では、自己トレーニング アルゴリズムにより、追加のラベル付きデータを必要とせずに、ハイブリッド モデルで弱い学習者を強い学習者に変換できることも示されています。ただし、外部の指導なしに LLM を自動的に改善する機能は複雑であり、研究も不十分です。これは次の疑問につながります:
人間がラベル付けしたデータを追加せずに LLM の自己改善を行うことはできるでしょうか?
方法
技術的な詳細では、次のように示される LLM を変換できます。 pθt は、人間が注釈を付けた SFT データセット内のプロンプト x に対する応答 y' を生成します。次の目標は、人間が与えた応答 y から pθt によって生成された応答 y' を区別する能力を持つ新しい LLM pθ{t 1} を見つけることです。
このプロセスは 2 人のプレイヤー間のゲーム プロセスとみなすことができます。メイン プレイヤーは新しい LLM pθ{t 1} であり、その目標は相手プレイヤーの反応を区別することです。 pθt と人間生成の応答。対戦相手のプレイヤーは古い LLM pθt で、そのタスクは人間が注釈を付けた SFT データセットにできるだけ近い応答を生成することです。
新しい LLM pθ{t 1} は、古い LLM pθt を微調整することによって取得されます。トレーニング プロセスにより、新しい LLM pθ{t 1} は、によって生成された応答 y' を区別する優れた能力を持つことができます。 pθt と人間によって与えられる応答 y。このトレーニングにより、新しい LLM pθ{t 1} がメイン プレーヤーとして優れた識別能力を達成できるだけでなく、新しい LLM pθ{t 1} が次の反復で対戦相手プレーヤーとしてより整列された SFT データを提供できるようになります。応答。次の反復では、新しく取得された LLM pθ{t 1} が応答を生成した対戦相手プレイヤーになります。
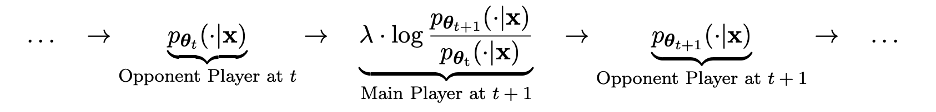

このセルフ ゲーム プロセスの目標は、LLM を作成することです。最終的に pθ∗ = p_data に収束すると、可能な限り最も強力な LLM は、以前のバージョンや人間が生成した応答と変わらない応答を生成します。
興味深いことに、この新しい方法は、Rafailov らによって最近提案された直接優先最適化 (DPO) 方法との類似点を示していますが、新しい方法の明らかな違いは、自己優先を使用することです。ゲームの仕組み。したがって、この新しい方法には、人間の嗜好データを追加する必要がないという重要な利点があります。
さらに、この新しい方法と敵対的生成ネットワーク (GAN) の類似点も明確にわかります。ただし、新しい方法では識別子 (メイン プレーヤー) とジェネレーターが異なる点が異なります (相手は、2 つの隣接する反復後の同じ LLM のインスタンスです。
チームは、この新しい手法の理論的証明も実施しました。その結果、LLM の分布がターゲット データの分布と等しい場合にのみ、この手法が収束できることがわかりました。は、 p_θ_t=p_data の場合です。
実験
実験では、チームは、Mistral-7B に基づいて微調整された LLM インスタンス zephyr-7b-sft-full を使用しました。 。
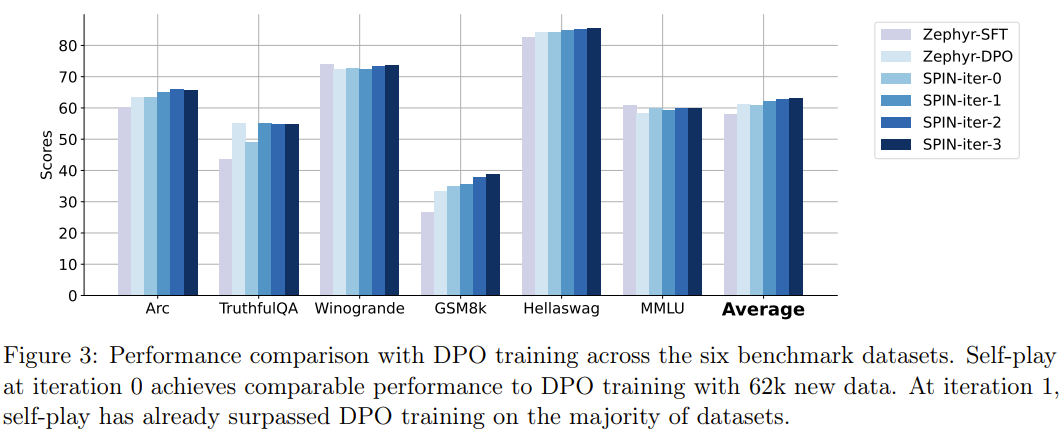
結果は、新しいメソッドが連続反復で zephyr-7b-sft-full を改善し続けることができることを示しています。また、比較として、SFT メソッドを使用して SFT で継続的にトレーニングを行った場合も同様です。データセット Ultrachat200k、評価スコアはパフォーマンスのボトルネックに達するか、低下する可能性があります。
さらに興味深いのは、新しい方法で使用されるデータセットは、Ultrachat200k データセットの 50k サイズのサブセットにすぎないということです。
新しいメソッド SPIN にはもう 1 つの成果があります。HuggingFace Open LLM ランキングにおけるベース モデル zephyr-7b-sft-full の平均スコアを 58.14 から 63.16 に効果的に向上させることができます。 GSM8k と TruthfulQA では 10% 以上の驚くべき改善が見られ、MT-Bench では 5.94 から 6.78 に改善することもできます。
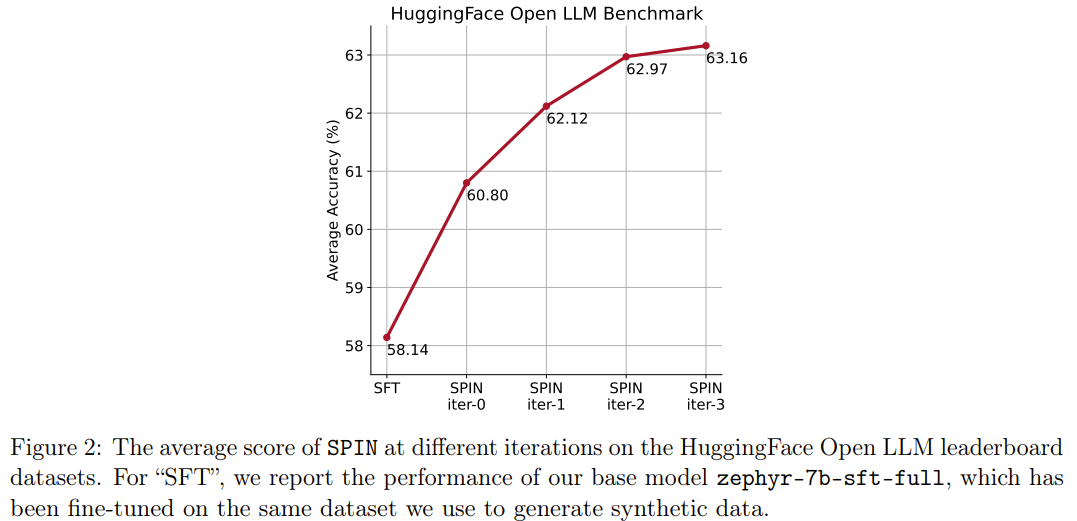
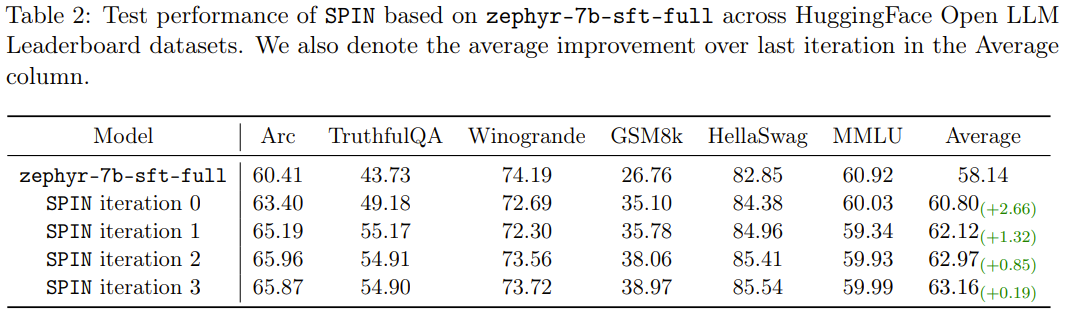
Open LLM ランキングでは、SPIN 微調整を使用するモデルは、追加の 62k 優先データセットを使用してトレーニングされたモデルは同等です。
結論
人間がラベル付けしたデータを最大限に活用することで、SPIN は大規模なモデルを信頼できるようにします。セルフゲームで弱点を克服し、強くなってください。人間の好みのフィードバック (RLHF) に基づく強化学習と比較して、SPIN を使用すると、人間による追加のフィードバックやより強力な LLM フィードバックを必要とせずに、LLM が自己改善できます。 HuggingFace Open LLM リーダーボードを含む複数のベンチマーク データセットでの実験では、SPIN は LLM のパフォーマンスを大幅かつ安定的に向上させ、追加の AI フィードバックでトレーニングされたモデルをも上回るパフォーマンスを示しました。
SPIN が大規模モデルの進化と改善に役立ち、最終的には人間のレベルを超えた人工知能を実現できると私たちは期待しています。
以上がLLM は互いに戦うことを学び、基本モデルはグループの革新をもたらす可能性があるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
17
10
15
1376
52
77
11
17
10

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
