

過去 1 年にわたり、大型モデルが次々と画期的な進歩を遂げ、ロボット研究の分野を再構築しました。
最先端の大型モデルがロボットの「頭脳」となり、ロボットは想像を超えるスピードで進化しています。
7 月、Google DeepMind は RT-2 の発売を発表しました。これは、ロボットを制御するための世界初のビジョン言語アクション (VLA) モデルです。
対話のようにコマンドを入力するだけで、大量の写真の中からスウィフトを特定し、彼女に「ハッピーウォーター」の入った瓶を渡すことができます。

#積極的に考えることもでき、「絶滅する動物を選ぶ」ことから、テーブルの上のプラスチック製の恐竜をつかむまで、多段階の推論の飛躍を完了します。

RT-2 の後、Google DeepMind は Q-Transformer を提案しました。ロボット工学の世界にも独自の Transformer があります。 Q-Transformer を使用すると、ロボットは高品質の実証データへの依存を打破し、独立した「思考」に依存して経験を蓄積することができるようになります。
リリースからわずか 2 か月後、RT-2 はロボットにとって新たな ImageNet の瞬間を迎えています。 Google DeepMind とその他の機関は、万能ロボットをトレーニングするための新しいアイデアである Open を立ち上げました。
ロボット アシスタントに「家を掃除して」や「美味しくて健康的な食事を作って」などの簡単なリクエストを与えるだけで、これらのタスクを完了できることを想像してください。人間にとってこれらの作業は単純かもしれませんが、ロボットにとっては世界を深く理解する必要があり、それは簡単ではありません。 ロボット トランスフォーマーの分野における長年の研究に基づいて、Google は最近、ロボットがより迅速かつ効率的に意思決定を行うのに役立つ AutoRT、SARA-RT、RT-Trajectory という一連のロボット研究の進歩を発表しました。彼らが置かれている環境を理解し、タスクを完了するために自分自身をより適切に導きます。 Google は、AutoRT、SARA-RT、RT-Trajectory などの研究結果の発表により、現実世界のロボットのデータ収集、速度、一般化能力の向上がもたらされると考えています。 次に、これらの重要な研究を振り返ってみましょう。AutoRT: 大規模モデルを活用してロボットをより適切にトレーニングする
AutoRT は、大規模言語モデル (LLM) やビジュアル言語モデル (VLM) などの大規模な基本モデルとロボット制御を組み合わせます。モデル (RT-1 または RT-2) を使用して、新しい環境にロボットを展開してトレーニング データを収集できるシステムを作成します。 AutoRT は、ビデオ カメラとエンド エフェクターを備えた複数のロボットを同時にガイドして、さまざまな環境でさまざまなタスクを実行できます。 具体的には、各ロボットは、AutoRT に基づいて、視覚言語モデル (VLM) を使用して「周囲を見渡し」、その視線内の環境とオブジェクトを理解します。次に、大規模言語モデルは、「テーブルにスナックを置く」などの一連の創造的なタスクを提案し、ロボットが実行するタスクを選択する意思決定者の役割を果たします。 研究者は、現実世界の設定で AutoRT の広範な 7 か月にわたる評価を実施しました。実験により、AutoRT システムは同時に最大 20 台、合計で最大 52 台のロボットを安全に調整できることが証明されています。研究者らは、さまざまなオフィスビル内でさまざまなタスクを実行するようにロボットを誘導することで、6,650 の固有のタスクを含む 77,000 件のロボット試行にわたる多様なデータセットを収集しました。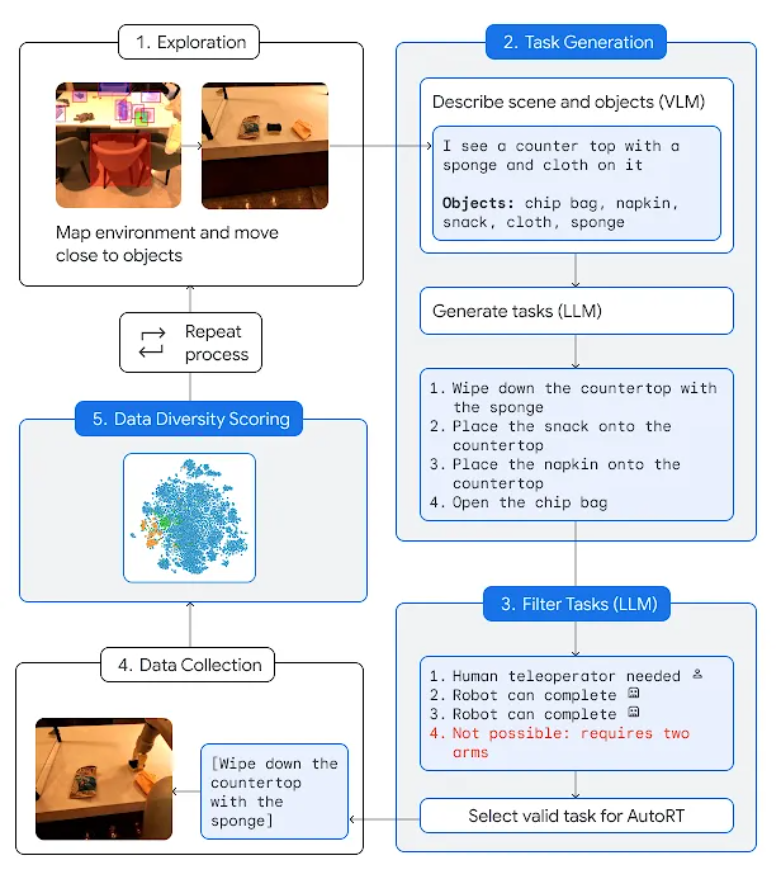
AutoRT は現時点では単なるデータ収集システムですが、現実世界における自律ロボットの初期段階と考えてください。安全ガードレールが特徴で、そのうちの 1 つは、ロボットが LLM ベースの決定を下す際に従うべき基本ルールを提供する、安全に焦点を当てた一連の合図ワードです。
これらのルールは、アイザック アシモフのロボット工学の 3 原則から部分的にインスピレーションを得ており、その中で最も重要なのは、ロボットが「人間に危害を加えてはいけない」ということです。安全規則では、ロボットが人間、動物、鋭利な物体、または電気製品が関与する作業を試みないことも求められています。
プロンプトワードに取り組むだけでは、実際のアプリケーションにおけるロボットの安全性を完全に保証することはできません。したがって、AutoRT システムには、ロボット工学の古典的な設計である実用的な安全対策の層も含まれています。たとえば、協働ロボットは、関節にかかる力が所定のしきい値を超えた場合に自動的に停止するようにプログラムされており、すべての自律制御ロボットは、物理的な無効化スイッチを介して人間の監視者の視線内に制限できます。
SARA-RT: ロボット Transformer (RT) をより高速かつ合理化する
もう 1 つの成果である SARA-RT は、ロボット Transformer (RT) のモデルを変換できます。より効率的なバージョンに変換されます。
Google チームが開発した RT ニューラル ネットワーク アーキテクチャは、RT-2 モデルを含む最新のロボット制御システムで使用されています。最も優れた SARA-RT-2 モデルは、簡単な画像履歴が与えられた場合、RT-2 モデルよりも 10.6% 精度が高く、14% 高速です。 Googleによれば、これは品質を損なうことなくコンピューティング能力を向上させる、初めてのスケーラブルな注目メカニズムだという。
Transformer は強力ですが、計算要件によって制限される可能性があり、意思決定が遅くなります。 Transformer は主に 2 次複雑さの Attention モジュールに依存します。これは、RT モデルへの入力が 2 倍になると (たとえば、ロボットにより多くの、またはより高解像度のセンサーを装備するなど)、その入力を処理するために必要な計算リソースが 4 倍に増加し、その結果、意思決定が遅くなるということを意味します。
SARA-RT は、モデルの効率を向上させるために、新しいモデル微調整方法 (「アップトレーニング」と呼ばれます) を採用しています。アップトレーニングは二次計算量を純粋な線形計算量に変換し、計算要件を大幅に削減します。この変換により、元のモデルの速度が向上するだけでなく、品質も維持されます。
Google は、多くの研究者や実務家がこの実用的なシステムをロボット工学やその他の分野に適用することを期待しています。 SARA は、計算コストのかかる事前トレーニングを必要とせずに、Transformer を高速化するための一般的なアプローチを提供するため、このアプローチは、Transformer テクノロジーを大規模に拡張する可能性があります。 SARA-RT では、さまざまなオープンソースの線形バリアントが利用できるため、追加のコーディングは必要ありません。
SARA-RT を数十億のパラメーターを備えた SOTA RT-2 モデルに適用すると、さまざまなロボット タスクにおける意思決定の迅速化とパフォーマンスの向上が可能になります。

#操作タスク用の SARA-RT-2 モデル。ロボットの動きは画像とテキストによる指示に基づいて調整されます。
SARA-RT は、その強固な理論的基盤により、さまざまな Transformer モデルに適用できます。たとえば、ロボットの深度カメラからの空間データを処理する点群変換器に SARA-RT を適用すると、速度が 2 倍以上向上します。RT-Trajectory: ロボットの一般化を支援
人間はテーブルの掃除方法を直感的に理解して学ぶことができますが、ロボットが指示を実際の物理的な動作に変換するには多くの可能な方法が必要です。 従来、ロボット アームのトレーニングは、抽象的な自然言語 (テーブルを拭く) を具体的な動作 (グリッパーを閉じる、左に移動する、右に移動する) にマッピングすることに依存しているため、モデルを新しいタスクに一般化することが困難です。対照的に、RT 軌道モデルを使用すると、RT モデルは、特定のロボットの動作 (ビデオやスケッチなど) を解釈することで、タスクが「どのように」達成されるかを理解できます。 RT 軌道モデルは、トレーニング ビデオ内のロボットの動きを説明する視覚的な輪郭を自動的に追加できます。 RT-Trajectory は、ロボット アームがタスクを実行するときに、トレーニング データセット内の各ビデオをグリッパーの 2D 軌道スケッチでオーバーレイします。これらの軌跡は、RGB 画像の形式で、モデルがロボット制御戦略を学習するための低レベルの実用的な視覚的手がかりを提供します。 トレーニング データには見られない 41 のタスクでテストしたところ、RT-Trajectory によって制御されたロボット アームのパフォーマンスは既存の SOTA RT モデルの 2 倍以上でした。タスクの成功率は 63% に達しました。 RT-2 の成功率はわずか 29% です。 このシステムは非常に多用途であるため、RT-Trajectory は必要なタスクの人間によるデモンストレーションを見て軌道を作成することもでき、さらには手描きのスケッチも受け入れることができます。さらに、いつでもさまざまなロボットプラットフォームに適応できます。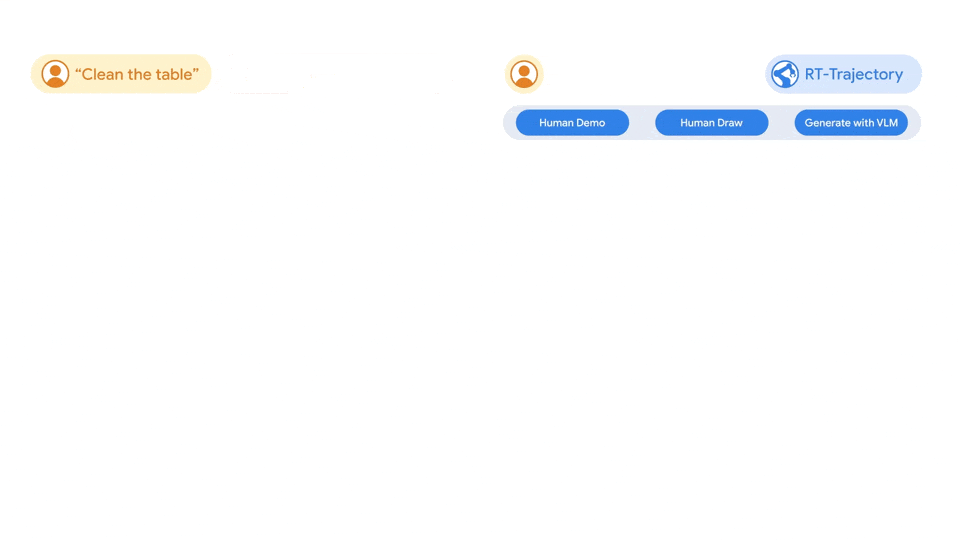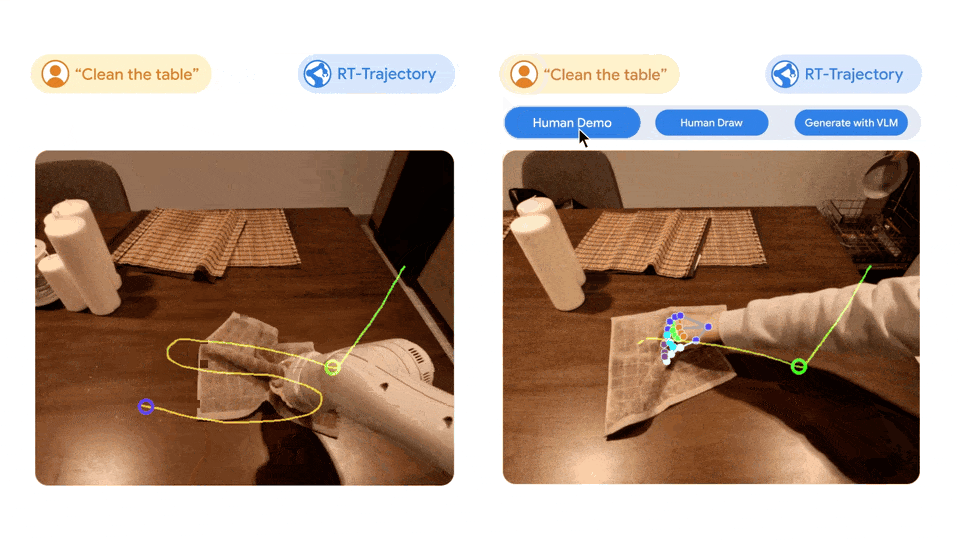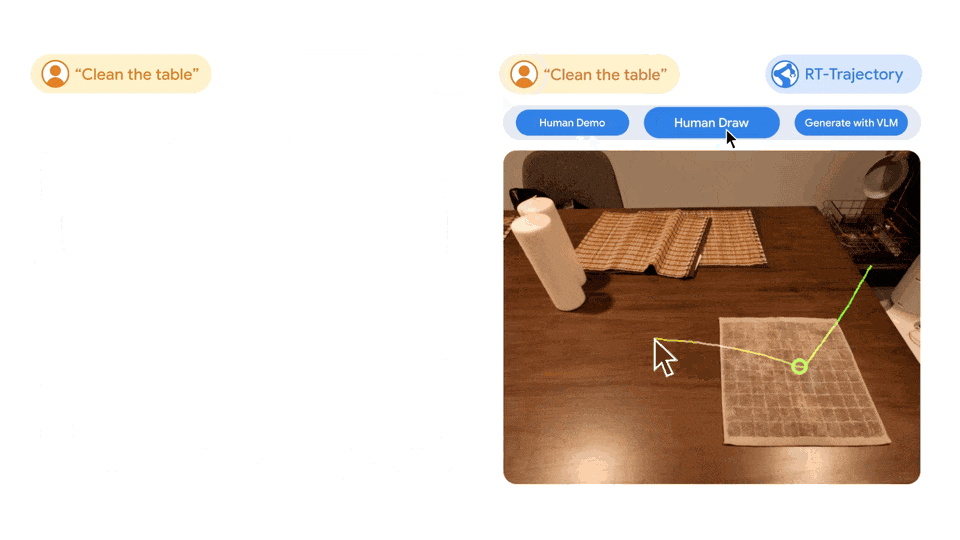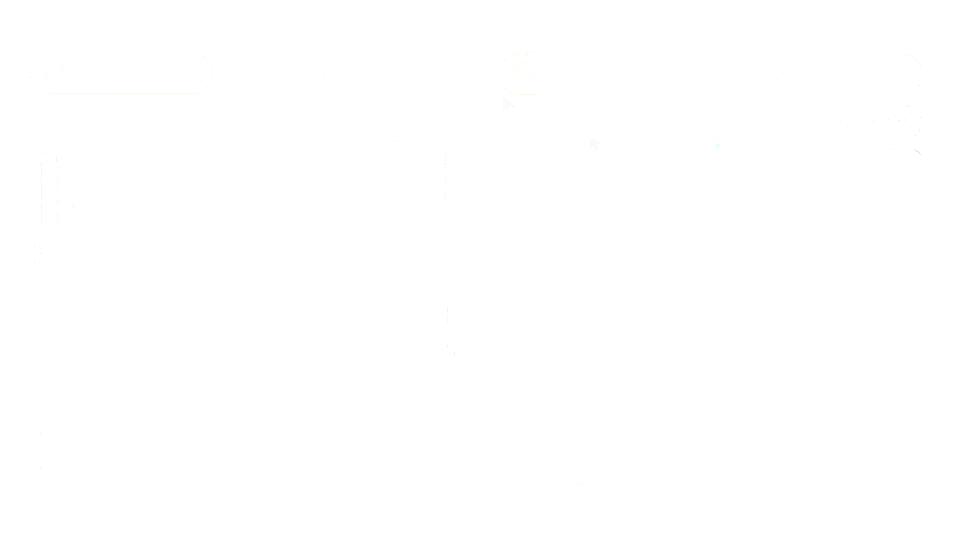 左の図: 自然言語データセットのみを使用してトレーニングされた RT モデルによって制御されたロボットは、テーブルを拭くという新しいタスクを実行するときにイライラしましたが、RT 軌道によって制御されたロボットはモデルは 2D 軌跡で強化された同じデータセットでトレーニングした後、ワイピング軌跡が正常に計画され、実行されました。右: トレーニングされた RT 軌道モデルに新しいタスク (テーブルを拭く) が与えられると、人間の助けを借りて、または視覚言語モデルを使用して独自に、さまざまな方法で 2D 軌道を作成できます。
左の図: 自然言語データセットのみを使用してトレーニングされた RT モデルによって制御されたロボットは、テーブルを拭くという新しいタスクを実行するときにイライラしましたが、RT 軌道によって制御されたロボットはモデルは 2D 軌跡で強化された同じデータセットでトレーニングした後、ワイピング軌跡が正常に計画され、実行されました。右: トレーニングされた RT 軌道モデルに新しいタスク (テーブルを拭く) が与えられると、人間の助けを借りて、または視覚言語モデルを使用して独自に、さまざまな方法で 2D 軌道を作成できます。
RT 軌跡は、すべてのロボット データセットに存在するが、現在十分に活用されていない豊富なロボット モーション情報を活用します。 RT-Trajectory は、新しいタスクのために効率的かつ正確に移動するロボットを作成するための新たな一歩を示すだけでなく、既存のデータセットからの知識の発見も可能にします。
以上がGoogle Deepmind は、ロボットを再発明し、大きなモデルに具現化されたインテリジェンスをもたらす未来を構想していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



