

Kafka 消費者グループの役割は何ですか

kafka コンシューマ グループの役割: 1. ロード バランシング; 2. フォールト トレランス; 3. ブロードキャスト モード; 4. 柔軟性; 5. 自動フェイルオーバーとリーダー選出; 6. 動的スケーラビリティ; 7. シーケンス保証; 6. 8. データ圧縮、9. トランザクションのサポート。詳細な紹介: 1. ロード バランシング: コンシューマ グループは Kafka ロード バランシングを実現するための中心的なメカニズムです. コンシューマをグループに編成することで、トピックのパーティションをグループ内の複数のコンシューマに割り当てることができ、それによってロード バランシングを実現します; 2. フォールト トレランス、消費者グループの設計により、フォールトトレランスなどが可能になります。

このチュートリアルのオペレーティング システム: Windows 10 システム、DELL G3 コンピューター。
Kafka コンシューマ グループは、同じ group.id を共有するコンシューマ インスタンスのグループです。コンシューマ グループの役割は主に次の側面に反映されます:
1. 負荷分散: コンシューマ グループは、Kafka 負荷分散を実現するための中心的なメカニズムです。コンシューマをグループに編成することにより、トピックのパーティションをグループ内の複数のコンシューマに割り当てることができ、それによって負荷分散が実現されます。このようにして、各コンシューマー インスタンスは一部のパーティションからのメッセージを処理するだけで済み、全体的な消費パフォーマンスが向上します。
2. フォールト トレランス: コンシューマー グループの設計により、フォールト トレランスが可能になります。グループ内のコンシューマに障害が発生した場合、他のコンシューマがそのパーティションを引き継ぐことができるため、メッセージが見逃されることがなく、1 つのコンシューマの障害がシステム全体の通常の動作に影響を与えるのを防ぐことができます。
3. ブロードキャスト モード: 複数のコンシューマ グループを作成することで、メッセージのブロードキャスト モードを実装できます。このモードでは、各コンシューマ グループがトピックからすべてのメッセージを受信するため、1 対多のメッセージングが実現されます。
4. 柔軟性: コンシューマー グループの構成を調整することで、パブリッシュ/サブスクライブ モデルやキュー モデルなど、さまざまな消費モデルを実装できます。パブリッシュ/サブスクライブ モードでは、メッセージは複数のコンシューマによって同時に使用できますが、キュー モードでは、メッセージは 1 つのコンシューマによってのみ使用できます。この柔軟性により、Kafka はさまざまなビジネス ニーズやデータ処理シナリオに適応できます。
5. 自動フェイルオーバーとリーダー選出: Kafka は、障害発生時にシステムの安定性と可用性を確保するために、自動フェイルオーバーとリーダー選出メカニズムを提供します。
6. 動的なスケーラビリティ: ビジネス規模の拡大または縮小に応じて、消費者グループのメンバーを動的に増減できます。新しく参加する消費者は既存のコピーから自動的にデータを取得して消費を開始しますが、脱退する消費者は自動的に感知して消費を停止します。この動的なスケーラビリティにより、Kafka はビジネスの発展に合わせて処理能力を柔軟に拡張できます。
7. 順序の保証: 単一のコンシューマー グループ内では、メッセージ消費の順序はパーティション内のメッセージの順序に従います。これにより、Kafka は単一のコンシューマ グループ内でのメッセージの順序を保証できます。グローバルな順序付けが必要な場合は、すべての関連メッセージを同じパーティションに送信し、単一のコンシューマーによって消費できます。
8. データ圧縮: Kafka はメッセージ圧縮機能をサポートしており、ストレージ容量が限られている場合にストレージに必要なディスク容量を削減できます。複数の連続するメッセージをまとめて圧縮し、それらを 1 回のディスク I/O 操作だけで書き込むことにより、スループットと効率を大幅に向上させることができます。
9. トランザクション サポート: Kafka はトランザクション メッセージ処理をサポートしており、メッセージの書き込みおよび読み取り中の操作の原子性と一貫性を保証できます。これは、分散システムにおける信頼性の高いデータ転送と一貫したデータ状態の実現に役立ちます。
実際のアプリケーションで Kafka コンシューマ グループを使用するには、コンシューマ インスタンスに同じコンシューマ グループ ID を設定する必要があります。さらに、コンシューマの構成を調整することで、パフォーマンスや耐障害性などのパラメータを最適化できます。たとえば、コンシューマの消費オフセット、コンシューマのプル タイムアウト、コンシューマの最大消費レートなどのパラメータを調整して、特定のビジネス ニーズを満たすことができます。
つまり、Kafka コンシューマ グループは、Kafka のロード バランシング、フォールト トレランス、柔軟性、その他の機能を実現するための中心的なメカニズムです。コンシューマ グループを適切に構成して使用することで、Kafka の全体的なパフォーマンスと信頼性を向上させ、さまざまなビジネス ニーズとデータ処理シナリオを満たすことができます。
以上がKafka 消費者グループの役割は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7548
7548
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 PHP と Kafka を使用してリアルタイム株価分析を実装する方法
Jun 28, 2023 am 10:04 AM
PHP と Kafka を使用してリアルタイム株価分析を実装する方法
Jun 28, 2023 am 10:04 AM
インターネットとテクノロジーの発展に伴い、デジタル投資への関心が高まっています。多くの投資家は、より高い投資収益率を得ることを期待して、投資戦略を模索し、研究し続けています。株式取引では、リアルタイムの株式分析が意思決定に非常に重要であり、Kafka のリアルタイム メッセージ キューと PHP テクノロジの使用は効率的かつ実用的な手段です。 1. Kafka の概要 Kafka は、LinkedIn によって開発された高スループットの分散型パブリッシュおよびサブスクライブ メッセージング システムです。 Kafka の主な機能は次のとおりです。
 springboot+kafka で @KafkaListener を使用して複数のトピックを動的に指定する方法
May 20, 2023 pm 08:58 PM
springboot+kafka で @KafkaListener を使用して複数のトピックを動的に指定する方法
May 20, 2023 pm 08:58 PM
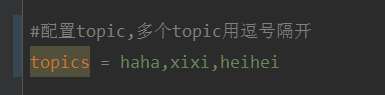
このプロジェクトは springboot+kafak 統合プロジェクトであるため、springboot で kafak 消費アノテーション @KafkaListener を使用していることを説明し、まず application.properties でカンマで区切られた複数のトピックを設定します。方法: Spring の SpEl 式を使用してトピックを次のように構成します: @KafkaListener(topics="#{’${topics}’.split(’,’)}") プログラムを実行します。コンソールの印刷効果は次のとおりです。
 SpringBoot が Kafka 構成ツール クラスを統合する方法
May 12, 2023 pm 09:58 PM
SpringBoot が Kafka 構成ツール クラスを統合する方法
May 12, 2023 pm 09:58 PM
spring-kafka は Java バージョンの kafkaclient と spring の統合に基づいています. 操作を容易にするためにさまざまなメソッドをカプセル化する KafkaTemplate を提供します. Apache の kafka-client をカプセル化しており、組織に依存するクライアントをインポートする必要はありません.springframework.kafkaspring-kafkaYML 設定.kafka:#bootstrap-servers:server1:9092,server2:9093#kafka 開発アドレス,#プロデューサー設定プロデューサー:#Kafka によって提供されるシリアル化および逆シリアル化クラス キー
 React と Apache Kafka を使用してリアルタイム データ処理アプリケーションを構築する方法
Sep 27, 2023 pm 02:25 PM
React と Apache Kafka を使用してリアルタイム データ処理アプリケーションを構築する方法
Sep 27, 2023 pm 02:25 PM
React と Apache Kafka を使用してリアルタイム データ処理アプリケーションを構築する方法 はじめに: ビッグ データとリアルタイム データ処理の台頭により、リアルタイム データ処理アプリケーションの構築が多くの開発者の追求となっています。人気のあるフロントエンド フレームワークである React と、高性能分散メッセージング システムである Apache Kafka を組み合わせることで、リアルタイム データ処理アプリケーションを構築できます。この記事では、React と Apache Kafka を使用してリアルタイム データ処理アプリケーションを構築する方法を紹介します。
 Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafka 視覚化ツールの 5 つのオプション ApacheKafka は、大量のリアルタイム データを処理できる分散ストリーム処理プラットフォームです。これは、リアルタイム データ パイプライン、メッセージ キュー、イベント駆動型アプリケーションの構築に広く使用されています。 Kafka の視覚化ツールは、ユーザーが Kafka クラスターを監視および管理し、Kafka データ フローをより深く理解するのに役立ちます。以下は、5 つの人気のある Kafka 視覚化ツールの紹介です。 ConfluentControlCenterConfluent
 Kafka 視覚化ツールの比較分析: 最適なツールを選択するには?
Jan 05, 2024 pm 12:15 PM
Kafka 視覚化ツールの比較分析: 最適なツールを選択するには?
Jan 05, 2024 pm 12:15 PM
適切な Kafka 視覚化ツールを選択するにはどうすればよいですか? 5 つのツールの比較分析 はじめに: Kafka は、ビッグ データの分野で広く使用されている、高性能、高スループットの分散メッセージ キュー システムです。 Kafka の人気に伴い、Kafka クラスターを簡単に監視および管理するためのビジュアル ツールを必要とする企業や開発者が増えています。この記事では、読者がニーズに合ったツールを選択できるように、一般的に使用される 5 つの Kafka 視覚化ツールを紹介し、その特徴と機能を比較します。 1.カフカマネージャー
 複数のkafkaを構成するspringbootプロジェクトのサンプルコード
May 14, 2023 pm 12:28 PM
複数のkafkaを構成するspringbootプロジェクトのサンプルコード
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. 設定ファイル関連情報 kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#同時に消費できるスレッドの数 (通常は一貫しています)パーティションの数で) kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 go-zero と Kafka+Avro の実践: 高性能対話型データ処理システムの構築
Jun 23, 2023 am 09:04 AM
go-zero と Kafka+Avro の実践: 高性能対話型データ処理システムの構築
Jun 23, 2023 am 09:04 AM
近年、ビッグ データと活発なオープン ソース コミュニティの台頭により、ますます多くの企業が増大するデータ ニーズを満たすために高性能の対話型データ処理システムを探し始めています。このテクノロジー アップグレードの波の中で、go-zero と Kafka+Avro はますます多くの企業に注目され、採用されています。 go-zero は、Golang 言語をベースに開発されたマイクロサービス フレームワークで、高いパフォーマンス、使いやすさ、拡張の容易さ、メンテナンスの容易さという特徴を備えており、企業が効率的なマイクロサービス アプリケーション システムを迅速に構築できるように設計されています。その急速な成長
