

Huake、Aliなどが共同開発したTF-T2V技術でAI動画制作コストを削減!

過去 2 年間で、LAION-5B のような大規模なグラフィックおよびテキスト データセットの公開により、画像生成の分野では安定拡散などの驚くべき効果をもたらす一連の手法が登場しました。 、DALL-E 2、ControlNet、および Composer 。これらの方法の出現により、画像生成の分野に大きな進歩と進歩がもたらされました。画像生成の分野は、過去 2 年間で急速に発展しました。
しかし、ビデオ生成は依然として大きな課題に直面しています。まず、画像生成と比較して、ビデオ生成では高次元のデータを処理する必要があり、追加の時間次元を考慮する必要があるため、タイミング モデリングの問題が生じます。時間ダイナミクスの学習を推進するには、より多くのビデオとテキストのペアのデータが必要です。ただし、ビデオの正確な時間的アノテーションは非常に高価であり、ビデオ テキスト データセットのサイズが制限されます。現在、既存の WebVid10M ビデオ データセットには 1,070 万のビデオとテキストのペアしか含まれておらず、LAION-5B 画像データセットと比較すると、データ サイズが大きく異なります。これにより、ビデオ生成モデルの大規模な拡張の可能性が大幅に制限されます。
上記の問題を解決するために、華中科技大学、アリババ グループ、浙江大学、アント グループの共同研究チームは最近、TF-T2V ビデオ ソリューションをリリースしました。

##プロジェクトのホームページ: https://tf-t2v.github.io/
ソースコードは間もなくリリースされます: https://github.com/ali-vilab /i2vgen-xl (VGen プロジェクト) 。
このソリューションは、異なるアプローチを採用し、リッチ モーション ダイナミクスを学習できる、大規模なテキストなしの注釈付きビデオ データに基づくビデオ生成を提案します。
# まずは TF-T2V のビデオ生成効果を見てみましょう:
文生ビデオ タスク
プロンプトワード: 雪に覆われた土地に生息する大きな霜のような生き物のビデオを生成します。
 プロンプトワード: 漫画のミツバチのアニメーションビデオを生成します。
プロンプトワード: 漫画のミツバチのアニメーションビデオを生成します。
 プロンプト ワード: 未来的なファンタジー バイクを含むビデオを生成します。
プロンプト ワード: 未来的なファンタジー バイクを含むビデオを生成します。
 プロンプトワード: 幸せそうに笑っている小さな男の子のビデオを生成します。
プロンプトワード: 幸せそうに笑っている小さな男の子のビデオを生成します。
 プロンプトワード: 頭痛を感じている老人のビデオを生成します。
プロンプトワード: 頭痛を感じている老人のビデオを生成します。
 #結合ビデオ生成タスク
#結合ビデオ生成タスク
指定されたテキストと深度マップまたはテキストTF-T2V は、制御可能なビデオ生成を実行できます:
高解像度ビデオ合成も実行できます: 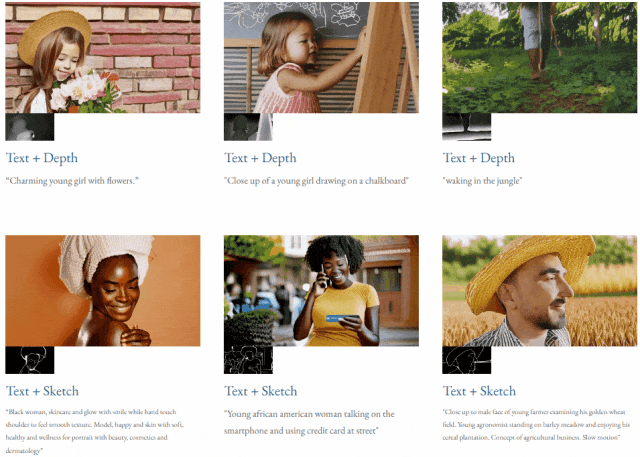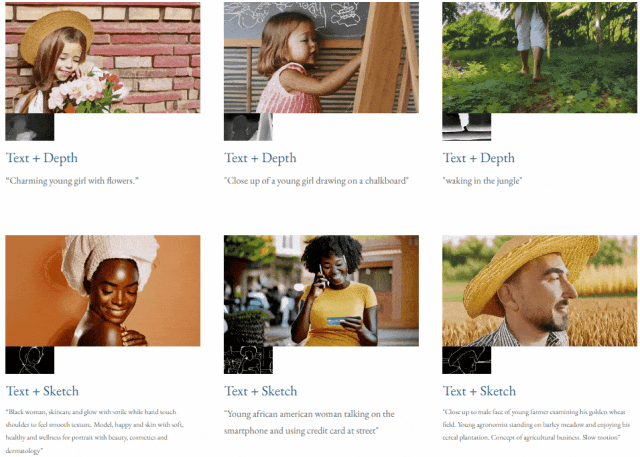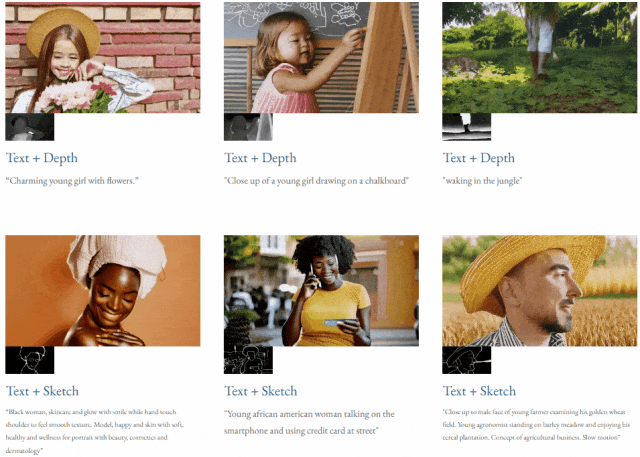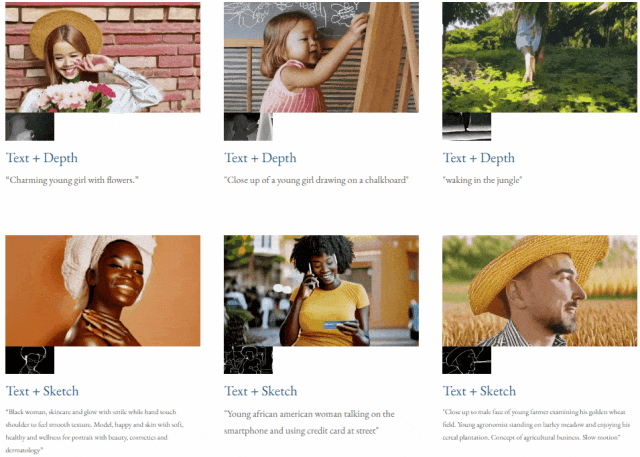
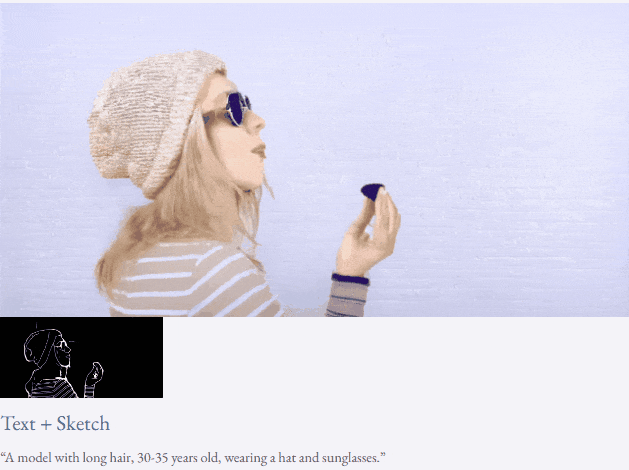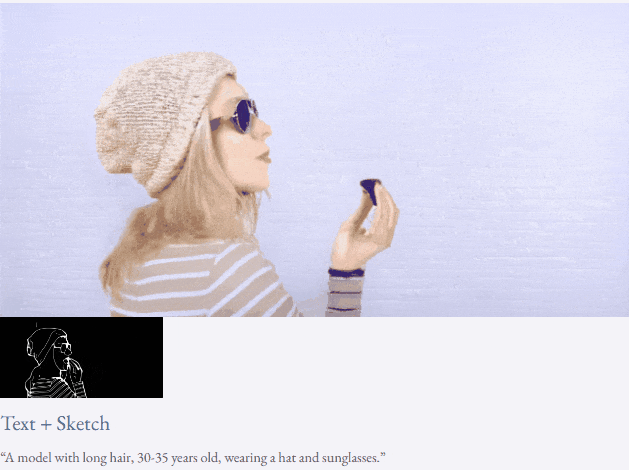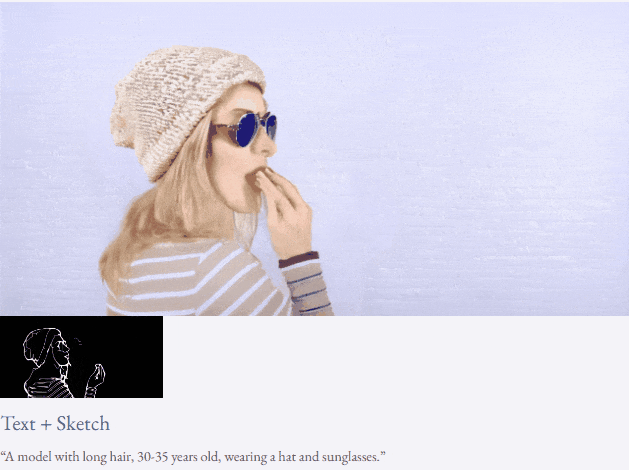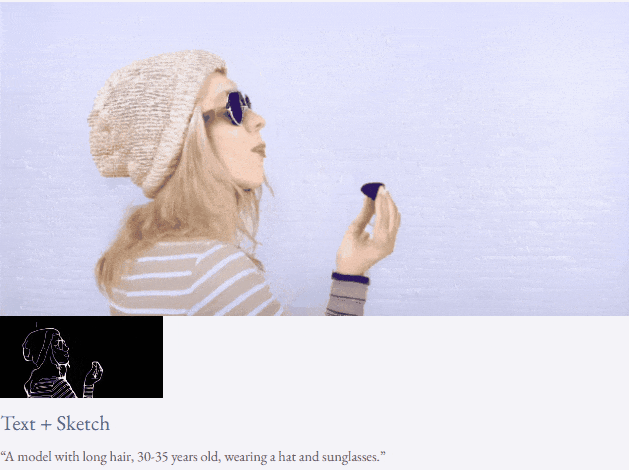
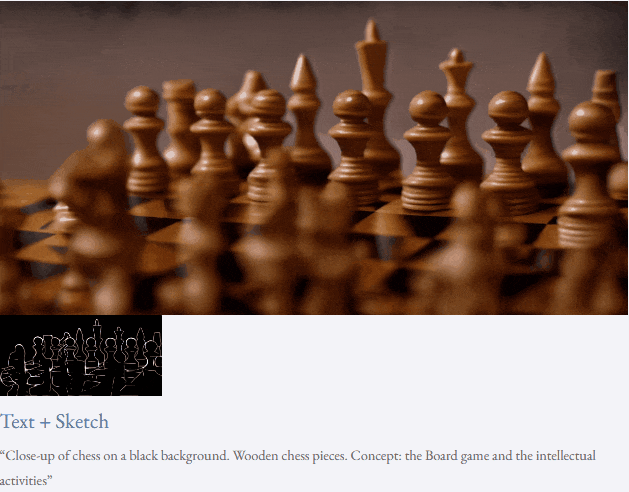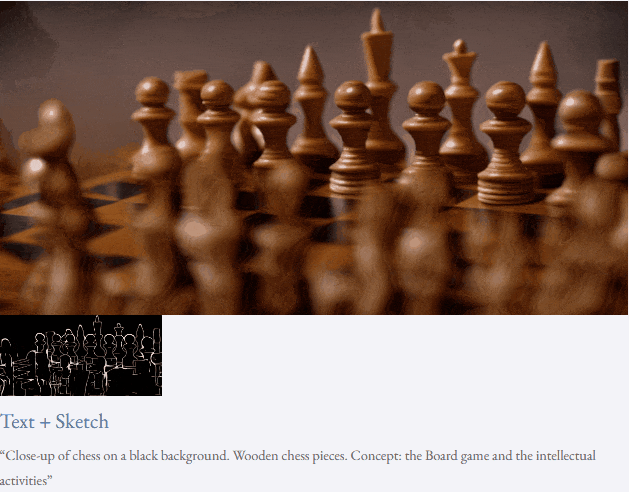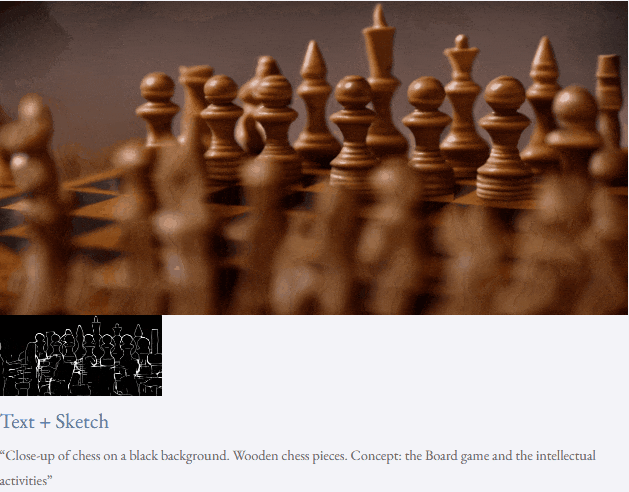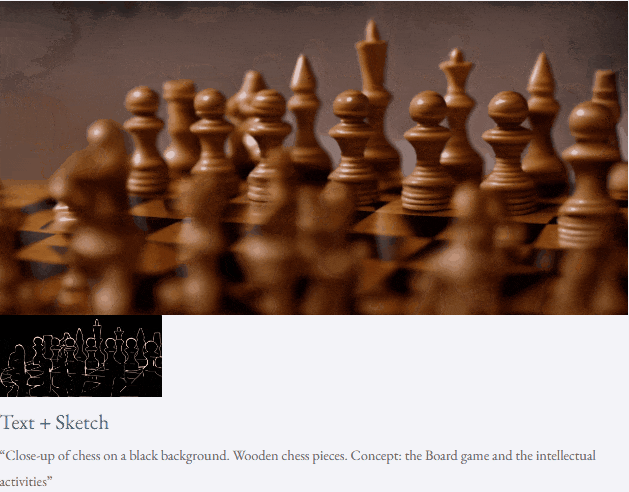
##
半教師あり設定
半教師あり設定の TF-T2V メソッドは、動きの記述に準拠したビデオを生成することもできます。 「人々は右から左へ走る」などのテキスト。


メソッドの紹介
中心となるアイデアTF-T2V モデルは動作ブランチと外観ブランチに分かれており、動作ブランチは運動ダイナミクスのモデル化に使用され、外観ブランチは視覚的な外観情報の学習に使用されます。これら 2 つのブランチは共同でトレーニングされ、最終的にテキスト駆動のビデオ生成を実現できます。
生成されたビデオの時間的一貫性を向上させるために、著者チームは、ビデオ フレーム間の連続性を明示的に学習するための時間的一貫性の損失も提案しました。
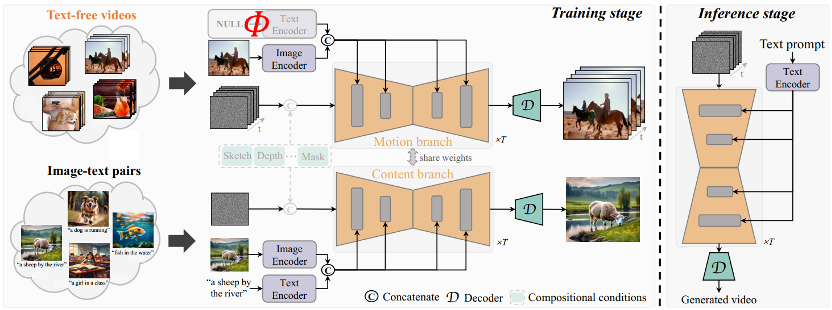
TF-T2V は、Vincent ビデオ タスクだけでなく、結合されたビデオ生成タスクにも適した一般的なフレームワークであることは言及する価値があります。 、スケッチからビデオへの変換、ビデオ修復、最初のフレームからビデオへの変換など。
具体的な詳細とさらなる実験結果については、元の論文またはプロジェクトのホームページを参照してください。
さらに、著者チームは TF-T2V を教師モデルとして使用し、一貫した蒸留技術を使用して VideoLCM モデルを取得しました。
論文アドレス: https://arxiv.org/abs/2312.09109
プロジェクトのホームページ: https://tf-t2v.github.io/
ソース コードは間もなくリリースされます: https://github.com/ali-vilab/i2vgen-xl (VGen プロジェクト)。
約 50 ステップの DDIM ノイズ除去を必要とする以前のビデオ生成手法とは異なり、TF-T2V に基づく VideoLCM 手法は、わずか約 4 ステップの推論ノイズ除去で忠実度の高いビデオを生成できます。ビデオ生成の効率が大幅に向上します。
#VideoLCM の 4 ステップのノイズ除去推論の結果を見てみましょう:

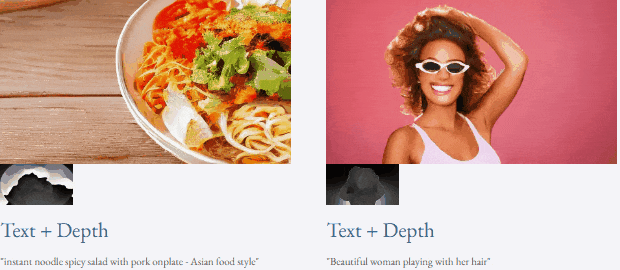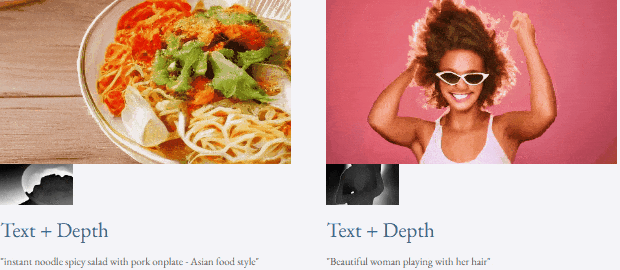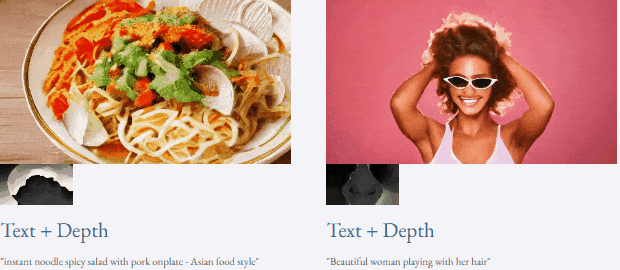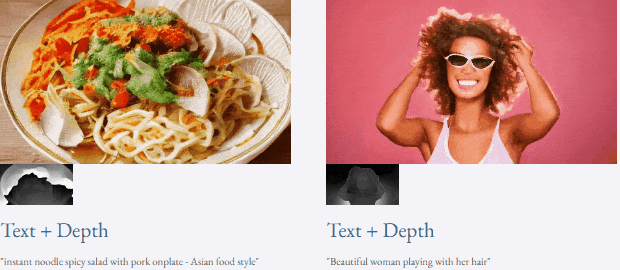

つまり、TF-T2V ソリューションはビデオ生成の分野に新しいアイデアをもたらし、データ セットのサイズとラベル付けの難しさによって引き起こされる課題を克服します。 TF-T2V は、大規模なテキストフリーの注釈ビデオ データを活用して高品質のビデオを生成でき、さまざまなビデオ生成タスクに適用されます。このイノベーションはビデオ生成技術の開発を促進し、より幅広い応用シナリオとビジネスチャンスをあらゆる階層にもたらします。
以上がHuake、Aliなどが共同開発したTF-T2V技術でAI動画制作コストを削減!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1419
52
1311
25
1261
29
1234
24
14
1419
52
1311
25
1261
29
1234
24

 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
