

2023 年テレコム AI 企業サミットの論文と競合他社の共有

近年、チャイナテレコムは人工知能技術の方向に熱心に取り組み続けています。 2023 年 11 月 28 日、中国電信デジタル知能技術分公司は正式に中国電信人工知能技術有限公司 (以下「電信 AI 会社」といいます) に社名を変更しました。 2023 年、Telecom AI Company は 21 の国内外のトップ AI コンペティションで連続受賞し、100 件以上の特許を申請し、CVPR、ACM MM、ICCV などのトップ会議やジャーナルで 30 以上の論文を発表し、そのパフォーマンスを実証しました。国有中央企業人工知能技術分野における予備的な成果
中国電信が人工知能ビジネスを実行する専門会社として、Telecom AI Company はテクノロジーベース、能力ベース、プラットフォームベースの企業です。同社は、人工知能の中核技術を征服し、最先端技術を研究し、産業空間の拡大を促進することに尽力し、数百億レベルの人工知能サービスプロバイダーになることを目指しています。過去 2 年間、Telecom AI Company は、Galaxy AI Algorithm Warehouse Empowerment Platform、Nebula AI Level 4 Computing Power Platform、Star Universal Basic Large Model など、一連の革新的なアプリケーション成果の独自開発に成功してきました。現在、同社の従業員数は800名を超え、平均年齢は31歳で、そのうち8割が研究開発担当者、7割が国内外の大手インターネット企業や大手AI企業出身者となっている。大型モデルの時代における研究開発の進歩を加速するために、同社は A100 と同等の計算能力を備えた 2,500 枚を超えるトレーニング カードと 300 人を超えるフルタイムのデータ アノテーション スタッフを擁しています。同時に、同社は上海人工知能研究所、西安交通大学、北京郵電大学、知源研究所などの科学研究機関とも協力し、世界クラスの人工知能技術と中国向け技術を共同で開発します。テレコムの 6,000 万のビデオ ネットワークと数億のユーザー シナリオ。
次に、2023 年に通信 AI 企業が達成したいくつかの重要な科学研究結果をレビューし、共有します。この共有では、ICCV 2023 イベントの時間的アクション ローカリゼーション トラック チャンピオンシップで優勝した AI R&D センターの CV アルゴリズム チームの技術的成果を紹介します。 ICCV は、コンピュータ ビジョン分野における国際的な 3 つのトップカンファレンスの 1 つであり、2 年ごとに開催され、業界で高い評価を得ています。この記事では、この課題でチームが採用したアルゴリズムのアイデアとソリューションを共有しますICCV 2023 知覚テスト チャレンジタイム アクション ポジショニング チャンピオン テクノロジー共有

DeepMind が開始した ICCV 2023 の最初の知覚テスト チャレンジは、ビデオ、オーディオ、テキスト モダリティにおけるモデルの機能を評価することを目的としています。このコンテストでは、4 つのスキル領域、4 つの推論タイプ、および 6 つの計算タスクを対象として、マルチモーダル知覚モデルの機能を包括的に評価します。その中でも、時間的動作位置特定トラックの中心的なタスクは、未編集のビデオ コンテンツを深く理解し、正確な動作位置を特定することであり、この技術は自動運転システムやビデオ監視分析などのさまざまなアプリケーション シナリオにとって非常に重要です##。
# 本コンテストでは、テレコム AI カンパニーのトラフィック アルゴリズム ディレクションのメンバーで構成されたチーム (CTCV と呼ばれます) が参加します。通信 AI 企業は、コンピューター ビジョン テクノロジーの分野で徹底的な研究を行い、豊富な経験を蓄積してきました。その技術成果は都市ガバナンスや交通セキュリティなど多くのビジネス分野で幅広く活用され、多くのユーザーに提供され続けています
序文は記事の始まりであり、読者に興味を持ってもらい、背景情報を提供することを目的としています。優れた導入部は読者の注意を引き、記事のトピックを要約し、読み続けたいと思わせるものです。紹介文を書くときは、簡潔で明確な言葉と正確で強力な内容に注意を払う必要があります。導入の目的は、読者を記事の主題に導くことであるため、関連する事実、データ、または示唆に富む質問を引用する必要があります。つまり、導入部分は記事への入り口であり、読者が読み続けるかどうかを決定することができます。
ビデオ理解における困難な問題は、ビデオ内のアクションをローカライズして分類するタスク、つまり時間的アクション ローカリゼーション (TAL) です。TAL テクノロジーは最近大きく進歩しました。たとえば、TadTR と ReAct は、アクション検出に DETR と同様の Transformer ベースのデコーダを採用し、アクション インスタンスを学習可能なセットとしてモデル化します。 TallFormer は、Transformer ベースのエンコーダーを使用してビデオ表現を抽出します
上記の方法は時間的アクションの位置決めにおいて良好な結果を達成しましたが、ビデオ認識能力にはいくつかの制限があります。アクション インスタンスをより適切にローカライズするには、信頼性の高いビデオ特徴表現が鍵となります。私たちのチームはまず VideoMAE-v2 フレームワークを採用し、アダプター線形層を追加し、2 つの異なるバックボーン ネットワークを使用してアクション カテゴリ予測モデルをトレーニングし、モデル分類層の前の層を使用して TAL タスクの特徴を抽出しました。次に、改良された ActionFormer フレームワークを使用して TAL タスクをトレーニングし、TAL タスクに適応するように WBF メソッドを変更しました。最終的に、私たちの手法は評価セットで mAP 0.50 を達成し、第 1 位にランクされ、2 位のチームより 3 パーセントポイント上回っており、Google DeepMind が提供するベースライン モデルよりも 34 パーセントポイント高かったです。
2 競合ソリューション
アルゴリズムの概要を以下に示します:
2.1 データの強化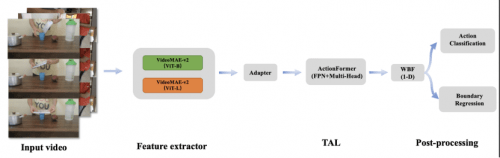
時間的アクション ローカリゼーション トラックでは、CTCV チームが使用するデータ セットは、アクション ローカリゼーション用にトリミングされていないビデオであり、高解像度で、複数のアクション インスタンスの特性が含まれています。データ セットを分析したところ、トレーニング セットには検証セットと比較して 3 つのカテゴリ ラベルが欠けていることがわかりました。モデル検証の適切性を確保し、競技の要件を満たすために、チームは少量のビデオ データを収集し、それをトレーニング データ セットに追加してトレーニング サンプルを充実させました。同時に、注釈プロセスを簡素化するために、各ビデオ プリセットにはアクションが 1 つだけ含まれています
図 2 の自分で収集したビデオ サンプルを参照してください
2.2 行動認識と特徴抽出
近年、大規模データトレーニングに基づいた多くの基本モデルが登場しており、これらのモデルは、ゼロサンプル認識、線形検出、プロンプト微調整などの方法を通じて、基本モデルの強力な一般化機能を複数の下流タスクに適用しています。調整、微調整を行い、人工知能分野のさまざまな側面での進歩を効果的に促進します。
TAL トラックでの動きの位置特定と認識は非常に困難です。たとえば、「何かを引き裂くふりをする」と「何かをバラバラに引き裂く」という 2 つのアクションは非常に似ており、これは間違いなく機能レベルに大きな課題をもたらします。したがって、既存の事前トレーニング済みモデルを直接使用して特徴を抽出する効果は理想的ではありませんしたがって、私たちのチームは、JSON アノテーション ファイルを解析することによって、TAL データ セットをアクション認識データ セットに変換しました。次に、Vit-B と Vit-L をバックボーン ネットワークとして使用し、VideoMAE-v2 ネットワークの後に分類用のアダプター層と線形層を追加し、同じデータ ドメインでアクション分類器をトレーニングします。また、アクション分類モデルから線形レイヤーを削除し、それをビデオ特徴抽出に使用します。 VitB モデルのフィーチャー次元は 768 ですが、ViTL モデルのフィーチャー次元は 1024 です。これら 2 つの特徴を同時に連結すると、次元 1792 の新しい特徴が生成されます。これは、時間的アクション位置特定モデルをトレーニングするための代替として使用されます。トレーニングの初期段階では音声機能を試しましたが、実験の結果、mAP インデックスが低下することがわかりました。したがって、その後の実験ではオーディオ機能
を考慮しませんでした。
2.3 タイミングアクションの位置決めActionformer は、時間順にアクションを配置するように設計されたアンカーフリー モデルです。これには、時間次元におけるマルチスケールの機能と局所的な自己注意が組み込まれています。このコンペティションで、CTCV チームは、アクション ポジショニングのベンチマーク モデルとして Actionformer を選択しました。これは、アクションの境界 (開始時間と終了時間) とカテゴリを予測するために使用されます
CTCV チームは、アクション境界回帰タスクとアクション分類タスクを統合処理しました。ベースラインのトレーニング構造と比較して、ビデオ特徴はまずマルチスケールの Transformer にエンコードされます。次に、モデルの回帰および分類のヘッド ブランチに特徴ピラミッド レイヤーが導入され、ネットワークの特徴表現能力が強化され、各タイム ステップのヘッド ブランチでアクション候補が生成されます。同時に、ヘッド数を 32 個に増やし、fpn1D 構造を導入することで、モデルの位置決めおよび識別能力がさらに向上しました。
1-D の 2.4 WBF
Weighted Boxes Fusion (WBF) は、革新的な検出フレーム フュージョン方法です。この方法は、すべての検出フレームの信頼度を使用して最終予測フレームを構築し、画像ターゲットの検出で良好な結果を示します。 NMS およびソフト NMS 手法とは異なり、重み付きボックス フュージョンは予測を破棄しませんが、提案されたすべての境界ボックスの信頼スコアを利用して平均ボックスを構築します。この方法により、長方形の予測精度が大幅に向上します
WBF に触発されて、CTCV チームはアクションの 1 次元境界ボックスを 1 次元の線分に類推し、TAL タスクに適したものになるように WBF 手法を修正しました。図 3
に示すように、実験結果はこの方法の有効性を示しています。
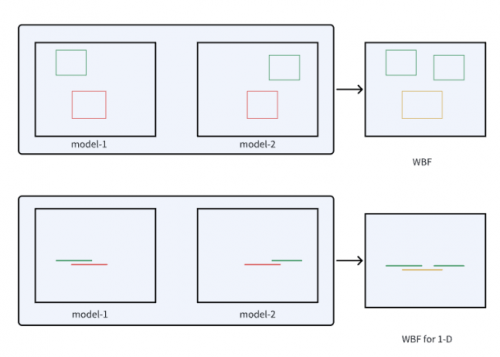 改良された 1 次元 WBF 図を図 3
改良された 1 次元 WBF 図を図 3
3 実験結果
3.1 評価指標。 評価基準###
今回のチャレンジで使用する評価指標はmAPです。 mAP は、さまざまなアクション カテゴリと IoU しきい値にわたる平均精度を計算することによって決定されます。 CTCV チームは、IoU しきい値を 0.1 から 0.5の範囲で 0.1 刻みで評価します。
3.2 実験の詳細は次のように書き換えられます:多様なモデルを取得するために、CTCV チームはトレーニング データセットの 80% を合計 5 回再サンプリングしました。 Vit-B、Vit-L、concat の機能をモデルのトレーニングに使用し、15 個の多様なモデルを取得することに成功しました。最後に、これらのモデルの評価結果が WBF モジュールに入力され、同じ融合重みが各モデル結果に割り当てられます
実験結果は次のとおりです:
さまざまな機能のパフォーマンス比較を表 1 に示します。 1 行目と 2 行目は、ViT-B および ViT-L 機能を使用した結果を示しています。 3 行目は、ViT-B および ViT-L 機能カスケードの結果を示します
実験中、CTCV チームは、カスケード フィーチャーの平均精度 (mAP) が ViT-L よりわずかに低いものの、それでも ViT-B よりは優れていることを発見しました。それにもかかわらず、検証セットでさまざまな手法を実行することにより、WBF の助けを借りて評価セットのさまざまな特徴の予測結果を融合し、最終的にシステムに送信された mAP は 0.50
でした。
書き直す必要がある内容は次のとおりです。 4 結論CTCV チームは、この大会でのパフォーマンスを向上させるために多くの戦略を採用しました。まず、データ収集を通じて、検証セット内の欠落しているクラスを使用してトレーニング データを強化しました。次に、VideoMAE-v2 フレームワークを使用して、ビデオ特徴抽出機能をトレーニングするためのアダプター層を追加し、改良された ActionFormer フレームワークを通じて TAL タスクをトレーニングしました。さらに、テスト結果を効率的に融合するために WBF メソッドを修正しました。最終的に、CTCV チームは評価セットで mAP 0.50 を達成し、1 位にランクされました。 通信 AI 企業は常に、「テクノロジーはビジネスから生まれ、ビジネスに行く」という開発哲学を堅持してきました。同社は、コンテストを技術力を試し、向上させるための重要なプラットフォームとして捉えており、顧客により質の高いサービスを提供するために、コンテストへの参加を通じて技術ソリューションの最適化と改善を続けています。同時に、コンテストへの参加は、チームメンバーにとって貴重な学習と成長の機会を提供します
以上が2023 年テレコム AI 企業サミットの論文と競合他社の共有の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7762
7762
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
