
 テクノロジー周辺機器
AI
Google の DeepMind ロボットが 3 回連続で結果を発表しました。両方の機能が向上し、データ収集システムは同時に 20 台のロボットを管理できるようになりました。
テクノロジー周辺機器
AI
Google の DeepMind ロボットが 3 回連続で結果を発表しました。両方の機能が向上し、データ収集システムは同時に 20 台のロボットを管理できるようになりました。
Google の DeepMind ロボットが 3 回連続で結果を発表しました。両方の機能が向上し、データ収集システムは同時に 20 台のロボットを管理できるようになりました。

スタンフォード大学の「エビフライと皿洗い」ロボットとほぼ同時に、Google DeepMind も最新の身体化されたインテリジェンスの結果を発表しました。

そして 3 連発 :
まず、意思決定スピードの向上に重点を置いた新モデル, let ロボットの動作速度 (オリジナル Robotics Transformer との比較) は 14% 向上しました。高速でありながら品質は低下せず、精度も 10.6% 向上しました。

次に、一般化機能に特化した新しいフレームワークがあり、ロボットの動作軌跡プロンプトを作成し、それを実行させることができます。これまでに見たことのない 41 のタスクに直面し、63% の成功率を達成しました。
 この配列を過小評価しないでください。
この配列を過小評価しないでください。
以前の 29% と比較すると、改善はかなり大きいです。。 ついに登場した
ロボット データ収集システム これは一度に 20 台のロボットを管理でき、現在その活動から 77,000 件の実験データを収集しています。これらは Google のより良い取り組みに役立ちます。その後のトレーニングの仕事。
 それでは、これら 3 つの結果は具体的には何でしょうか?一つずつ見ていきましょう。
それでは、これら 3 つの結果は具体的には何でしょうか?一つずつ見ていきましょう。
ロボットを日常化するための最初のステップ: 目に見えないタスクを直接実行できる
Google は、現実世界に真に参入できるロボットを実現するには、2 つの基本的な課題を達成する必要があると指摘しました。解決しました。
1. 新しいタスクを推進する能力
2. 意思決定速度の向上
この 3 部構成のシリーズの最初の 2 つの成果は、主に次の 2 つの領域の改善です。すべては Google の基本ロボット モデル Robotics Transformer
(略して RT)に基づいて構築されています。 まずは最初の
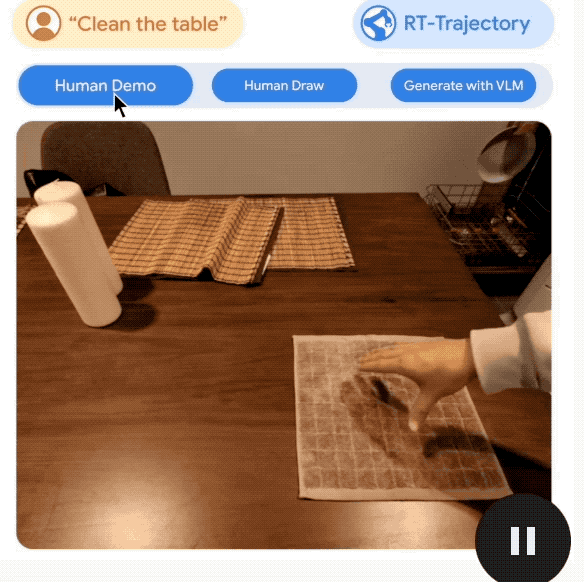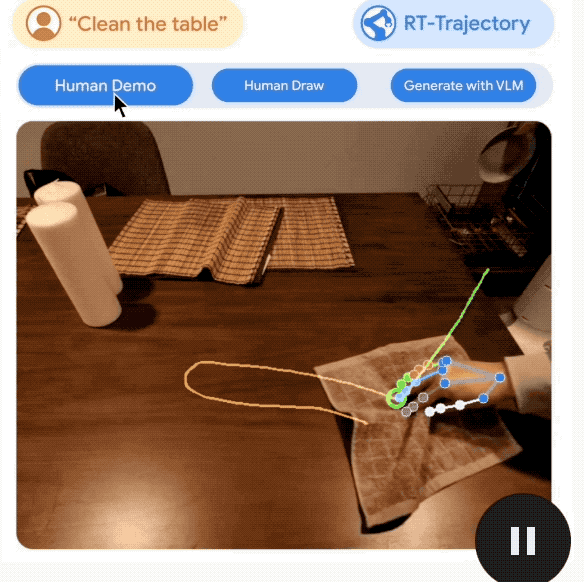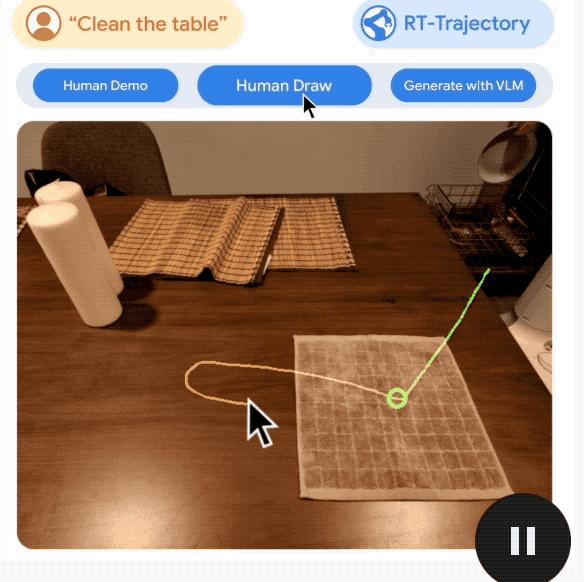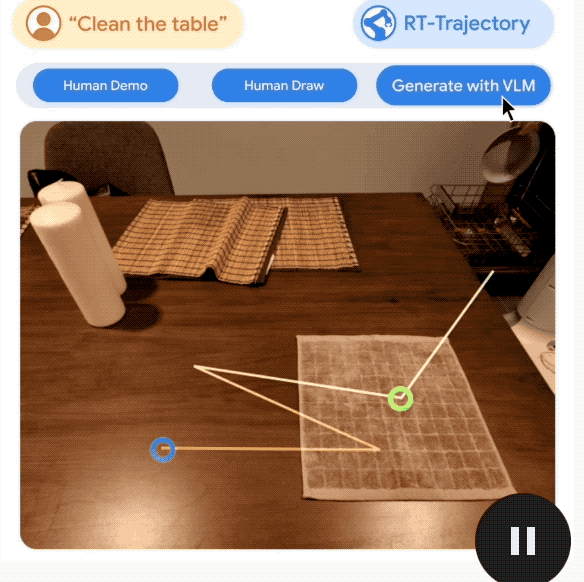
RT-Trajectory を見てみましょう。これはロボットの一般化に役立ちます。 人間にとって、テーブルの掃除などの作業はわかりやすいですが、ロボットにはよくわかりません。
しかし幸いなことに、この命令をさまざまな方法で伝えることができ、実際の物理的な動作を実行できるようになります。
一般的に、従来の方法は、タスクを特定のアクションにマッピングし、ロボット アームにそれを完了させることです。たとえば、テーブルを拭く作業は、「クランプを閉じる、テーブルに移動する」に分解できます。左に移動し、左にクランプを閉じます。「右に移動」。
明らかに、この方法の一般化能力は非常に貧弱です。
ここで、Google が新たに提案した RT-Trajectory は、視覚的な合図を提供することでロボットにタスクを完了するよう教えます。
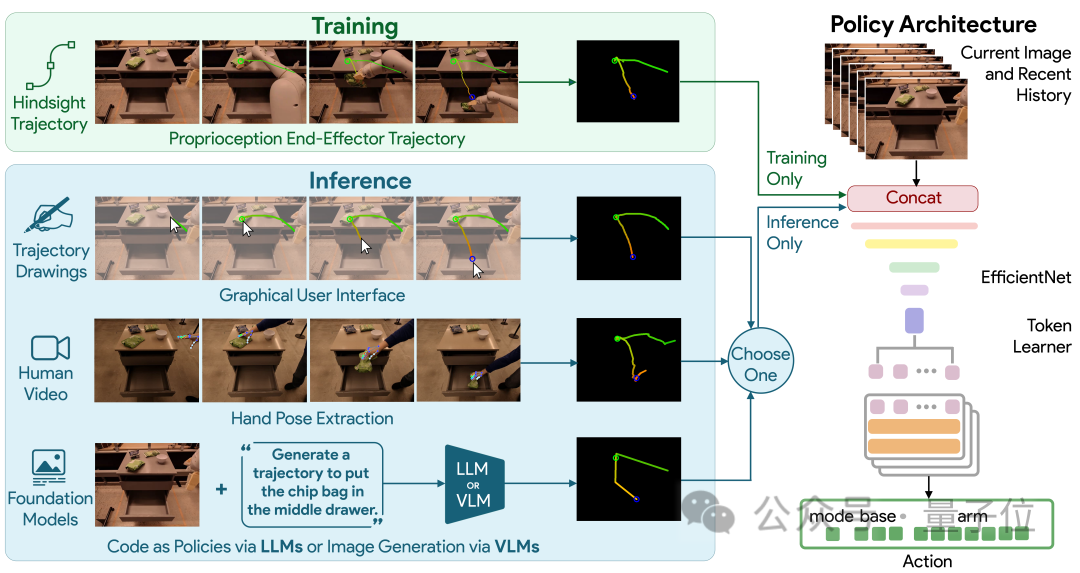 具体的には、RT-Trajectory によって制御されるロボットは、トレーニング中に 2D 軌道強化データを追加します。
具体的には、RT-Trajectory によって制御されるロボットは、トレーニング中に 2D 軌道強化データを追加します。
これらの軌跡は、ルートやキーポイントを含む RGB 画像として表示され、ロボットがタスクの実行を学習する際に、低レベルではあるが非常に役立つヒントを提供します。
このモデルを使用すると、これまでに見たことのないタスクを実行するロボットの成功率が直接 1 倍に増加しました
(Google の基本的なロボット モデル RT-2 と比較して、29%= > 63%)。 さらに言及する価値があるのは、RT-Trajectory がさまざまな方法で軌道を作成できることです。 ) ### 引き起こす。
#日常ロボット化の第 2 ステップ: 意思決定のスピードが速くなければなりません
 Google の RT モデルは Transformer アーキテクチャを使用しています。Transformer は強力ですが、二次複雑さを持つ Attendance モジュールに大きく依存しています。
Google の RT モデルは Transformer アーキテクチャを使用しています。Transformer は強力ですが、二次複雑さを持つ Attendance モジュールに大きく依存しています。
したがって、RT モデルへの入力が 2 倍になると (たとえば、ロボットに高解像度のセンサーを装備することで)
、その処理に必要な計算リソースは 4 倍になります。意思決定が大幅に遅くなります。 Google は、ロボットの速度を向上させるために、基本モデル Robotics Transformer で SARA-RTを開発しました。
SARA-RT は、新しいモデル微調整方法を使用して、元の RT モデルをより効率的にします。
この手法は Google では「アップ トレーニング」と呼ばれており、その主な機能は 元の 2 次複雑度を線形複雑度に変換することです。同時に処理を維持することです。品質。
SARA-RT を数十億のパラメーターを持つ RT-2 モデルに適用すると、後者はさまざまなタスクでより高速な演算速度とより高い精度を達成できます。
SARA-RT は、費用のかかる事前トレーニングなしで Transformer を高速化する ユニバーサル メソッドを提供するため、十分に推進できることにも言及する価値があります。
データが足りませんか?独自に作成する
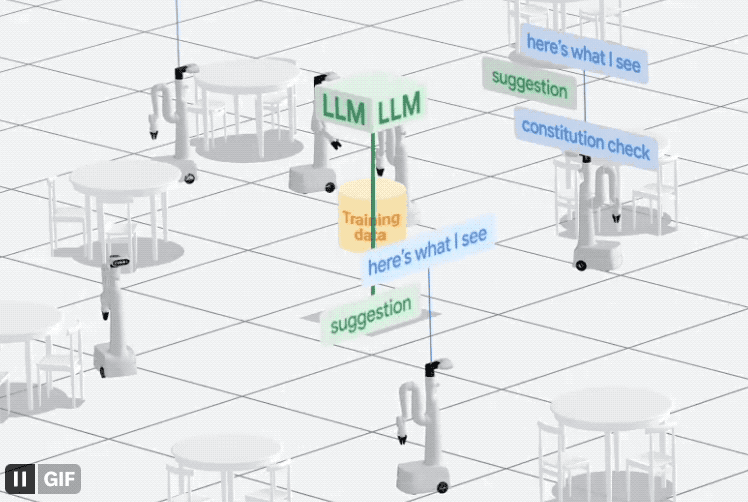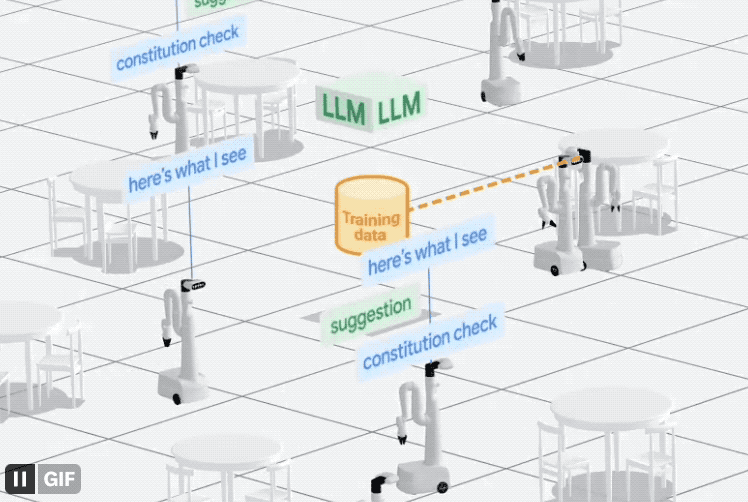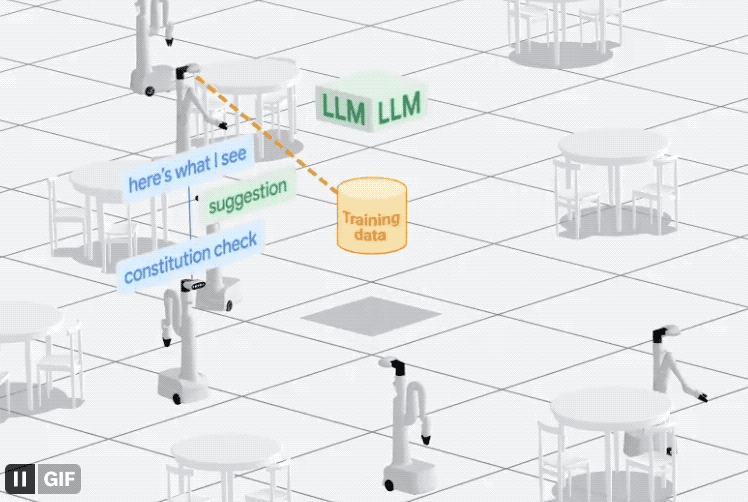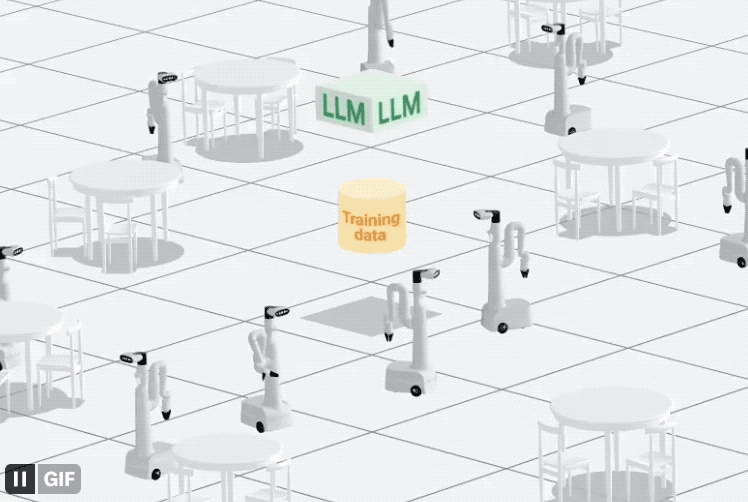
最後に、ロボットが人間によって割り当てられたタスクをよりよく理解できるようにするために、Google はデータから開始し、収集システムである AutoRT を直接構築しました。
このシステムは、大規模モデル (LLM および VLM を含む) とロボット制御モデル (RT) を組み合わせて、現実のさまざまなタスクを実行するようにロボットに継続的に命令します。データを生成および収集するタスク。
具体的なプロセスは次のとおりです。
ロボットを環境に「自由に」接触させ、ターゲットに近づけます。
次に、カメラと VLM モデルを使用して、特定のアイテムを含む目の前のシーンを説明します。
次に、LLM はこの情報を使用して、いくつかの異なるタスクを生成します。
ロボットは生成後すぐに実行されるわけではないことに注意してください。代わりに、LLM を使用して フィルタ どのタスクが独立して完了できるか、どのタスクが人間を必要とするかが決まります。リモコン、そしてどれ それは単に完了することができません。
「ポテトチップスの袋を開ける」ことは、2 つのロボット アーム (デフォルトでは 1 つだけ) が必要なため、実行できません。
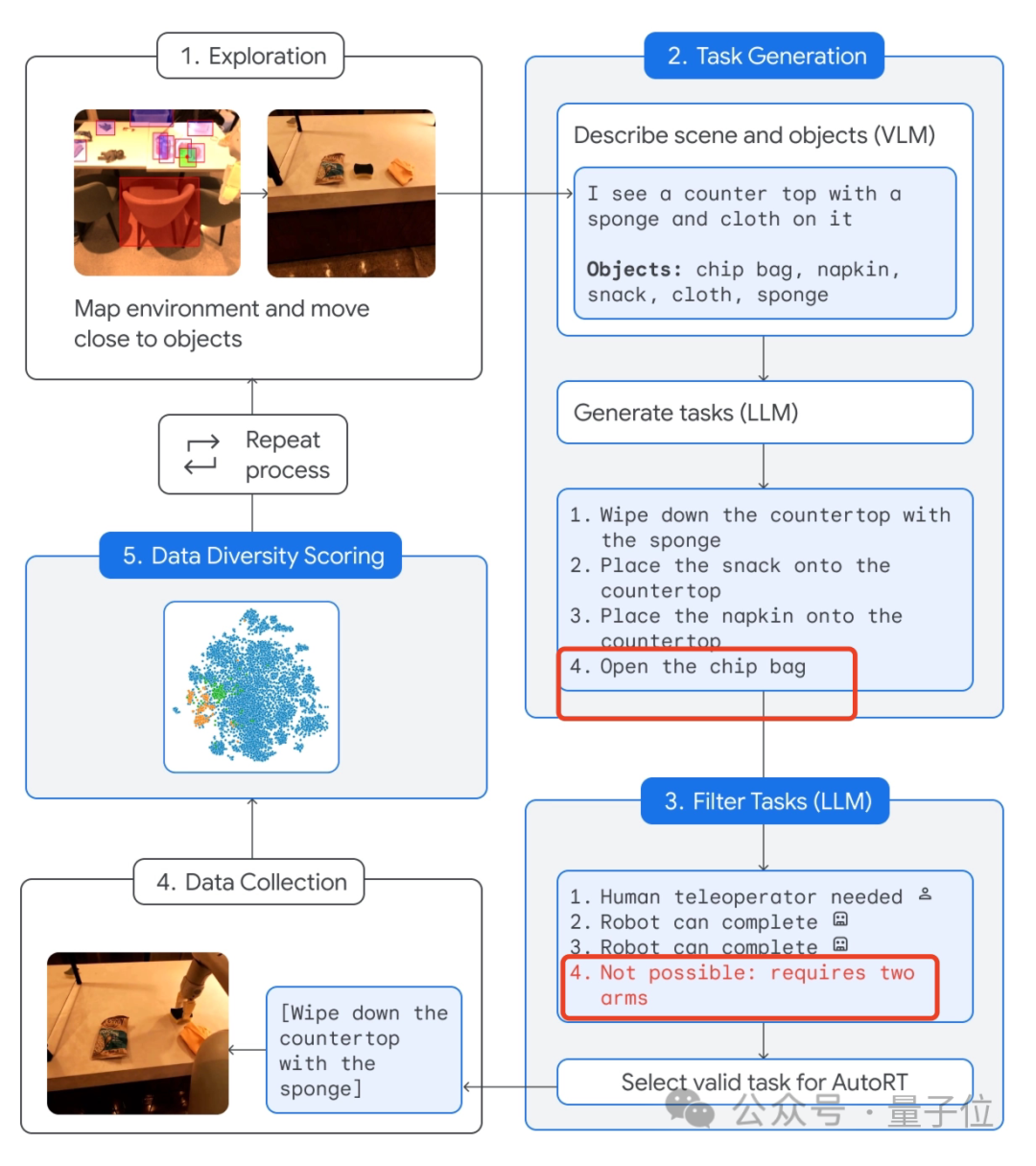
このスクリーニング タスクが完了すると、ロボットは実際にそれを実行できるようになります。
最後に、AutoRT システムはデータ収集を完了し、多様性評価を実行します。
レポートによると、AutoRT は一度に最大 20 台のロボットを調整でき、7 か月以内に 6,650 の固有タスクを含む合計 77,000 のテスト データが収集されました。
最後に、このシステムに関して、Google は セキュリティ も重視しています。
結局のところ、AutoRT の収集タスクは現実世界に影響を与えるため、「安全ガードレール」が不可欠です。
具体的には、基本安全コードは、ロボットのタスク スクリーニングを実行する LLM によって提供されており、部分的にはアイザック アシモフのロボット工学の 3 原則 (何よりもまず「ロボット」は人間に危害を加えてはなりません) に影響を受けています。
2 番目の要件は、ロボットが人間、動物、鋭利な物体、または電化製品が関与するタスクを試みてはいけないということです。
しかし、これだけでは十分ではありません。
そこで、AutoRT も装備されています。従来のロボット工学に見られる実用的な安全対策は何層にもわたっています。
たとえば、関節にかかる力が所定の閾値を超えるとロボットは自動的に停止し、すべての動作は人間の視界内にある物理的なスイッチで制御できます。

Google の最新の結果について詳しく知りたいですか?
良いニュースです。ただし、RT-Trajectory にはオンライン ペーパーしかありません。 、残りは次のとおりです コードと論文は一緒にリリースされており、皆さんもぜひチェックしてみてください ~
One More Thing
Google ロボットといえば、RT- 2(この記事のすべての結果も).
このモデルは、54 人の Google 研究者によって 7 か月間構築され、今年 7 月末に発表されました。 .
埋め込みビジュアルテキスト マルチモーダル大規模モデル VLM は、「人間の音声」を理解できるだけでなく、「人間の音声」について推論し、1 ステップでは実行できないいくつかのタスクを実行することもできます。ライオン、クジラ、恐竜の3つのプラスチックのおもちゃから情報を抽出。「絶滅した動物」を正確に拾えるのはすごい。

#汎化能力を獲得意思決定のスピードはわずか 5 か月強です。ロボットの急速な進歩にはため息をつかずにはいられません。ロボットが実際にどのくらいの速さで何千もの家庭に浸透するのか想像できません。
以上がGoogle の DeepMind ロボットが 3 回連続で結果を発表しました。両方の機能が向上し、データ収集システムは同時に 20 台のロボットを管理できるようになりました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7471
7471
 15
1377
52
77
11
19
30
15
1377
52
77
11
19
30

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
