

写真とアクションコマンドだけで、Animate124 は簡単に 3D ビデオを生成できます

Animate124 を使用すると、1 枚の写真を簡単に 3D ビデオに変換できます。

- プロジェクトのホームページ: https://animate124.github.io/
- 論文アドレス: https://animate124.github.io/
- ://arxiv.org/abs/2311.14603

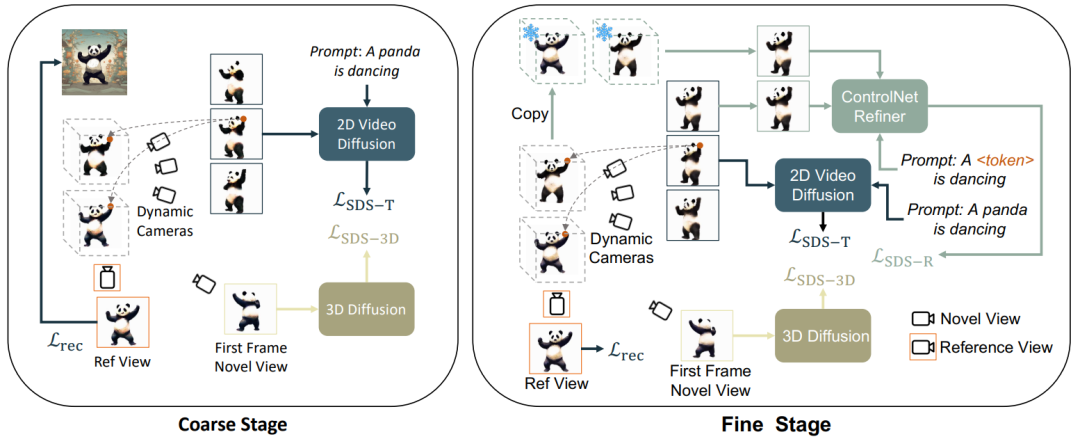 静的最適化と動的最適化、粗い最適化と細かい最適化に従って、この記事では 3D ビデオ生成を 3 つの段階に分割します: 1) 静的生成段階: 鹿肉グラフと 3D グラフ拡散モデルを使用して、単一の画像から 3D オブジェクトを生成します。2)動的ラフ生成ステージ: Vincent ビデオ モデルを使用して、言語記述に基づいてアクションを最適化します; 3) セマンティック最適化ステージ: さらに、パーソナライズされた微調整 ControlNet を使用して、第 2 ステージで言語記述によって引き起こされるオフセットを最適化および改善します。
静的最適化と動的最適化、粗い最適化と細かい最適化に従って、この記事では 3D ビデオ生成を 3 つの段階に分割します: 1) 静的生成段階: 鹿肉グラフと 3D グラフ拡散モデルを使用して、単一の画像から 3D オブジェクトを生成します。2)動的ラフ生成ステージ: Vincent ビデオ モデルを使用して、言語記述に基づいてアクションを最適化します; 3) セマンティック最適化ステージ: さらに、パーソナライズされた微調整 ControlNet を使用して、第 2 ステージで言語記述によって引き起こされるオフセットを最適化および改善します。
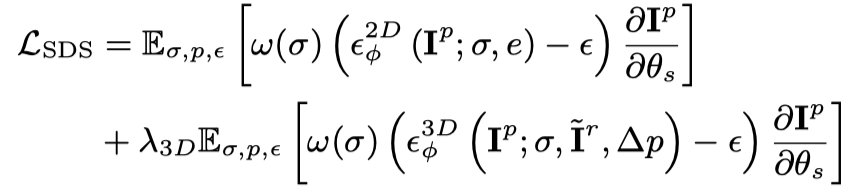
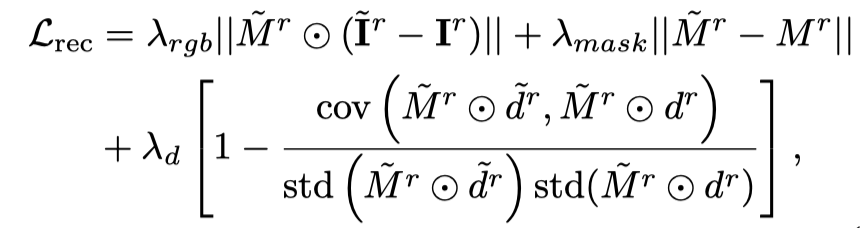
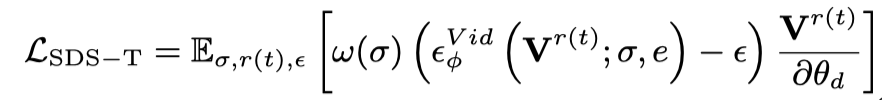 Vincent ビデオの蒸留損失のみを使用すると、3D モデルが画像の内容を忘れてしまい、ランダム サンプリングではビデオの初期段階と終了段階でのトレーニングが不十分になります。したがって、この論文の研究者は、開始タイムスタンプと終了タイムスタンプをオーバーサンプリングしました。また、最初のフレームをサンプリングするときに、最適化 (3D グラフの SDS 蒸留損失) のために追加の静的関数が使用されます。
Vincent ビデオの蒸留損失のみを使用すると、3D モデルが画像の内容を忘れてしまい、ランダム サンプリングではビデオの初期段階と終了段階でのトレーニングが不十分になります。したがって、この論文の研究者は、開始タイムスタンプと終了タイムスタンプをオーバーサンプリングしました。また、最初のフレームをサンプリングするときに、最適化 (3D グラフの SDS 蒸留損失) のために追加の静的関数が使用されます。
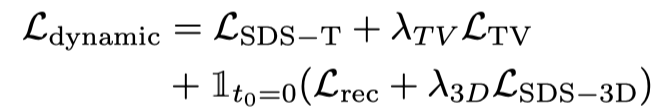
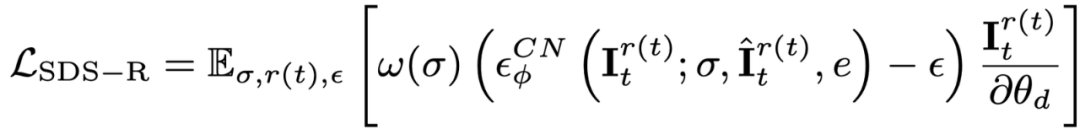
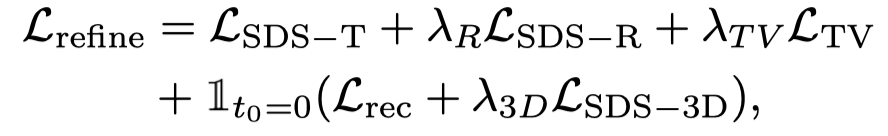



この記事では、CLIP と手動評価を使用して品質を生成しています。CLIP 指標には、テキストとの類似性、検索精度、画像品質が含まれます。類似性と時間的一貫性。手動評価指標には、テキストとの類似性、写真との類似性、ビデオ品質、動きのリアルさ、動きの振幅が含まれます。手動評価は、対応するメトリックにおける Animate124 の選択に対する単一モデルの比率で表されます。
2 つのベースライン モデルと比較して、Animate124 は CLIP 評価と手動評価の両方でより良い結果を達成しています。

##概要
以上が写真とアクションコマンドだけで、Animate124 は簡単に 3D ビデオを生成できますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
でももしかしたら公園の老人には勝てないかもしれない?パリオリンピックの真っ最中で、卓球が注目を集めています。同時に、ロボットは卓球のプレーにも新たな進歩をもたらしました。先ほど、DeepMind は、卓球競技において人間のアマチュア選手のレベルに到達できる初の学習ロボット エージェントを提案しました。論文のアドレス: https://arxiv.org/pdf/2408.03906 DeepMind ロボットは卓球でどれくらい優れていますか?おそらく人間のアマチュアプレーヤーと同等です: フォアハンドとバックハンドの両方: 相手はさまざまなプレースタイルを使用しますが、ロボットもそれに耐えることができます: さまざまなスピンでサーブを受ける: ただし、ゲームの激しさはそれほど激しくないようです公園の老人。ロボット、卓球用
 初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
8月21日、2024年世界ロボット会議が北京で盛大に開催された。 SenseTimeのホームロボットブランド「Yuanluobot SenseRobot」は、全製品ファミリーを発表し、最近、世界初の家庭用チェスロボットとなるYuanluobot AIチェスプレイロボット - Chess Professional Edition(以下、「Yuanluobot SenseRobot」という)をリリースした。家。 Yuanluobo の 3 番目のチェス対局ロボット製品である新しい Guxiang ロボットは、AI およびエンジニアリング機械において多くの特別な技術アップグレードと革新を経て、初めて 3 次元のチェスの駒を拾う機能を実現しました。家庭用ロボットの機械的な爪を通して、チェスの対局、全員でのチェスの対局、記譜のレビューなどの人間と機械の機能を実行します。
 クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
もうすぐ学校が始まり、新学期を迎える生徒だけでなく、大型AIモデルも気を付けなければなりません。少し前、レディットはクロードが怠け者になったと不満を漏らすネチズンでいっぱいだった。 「レベルが大幅に低下し、頻繁に停止し、出力も非常に短くなりました。リリースの最初の週は、4 ページの文書全体を一度に翻訳できましたが、今では 0.5 ページの出力さえできません」 !」 https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ というタイトルの投稿で、「クロードには完全に失望しました」という内容でいっぱいだった。
 世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
北京で開催中の世界ロボット会議では、人型ロボットの展示が絶対的な注目となっているスターダストインテリジェントのブースでは、AIロボットアシスタントS1がダルシマー、武道、書道の3大パフォーマンスを披露した。文武両道を備えた 1 つの展示エリアには、多くの専門的な聴衆とメディアが集まりました。弾性ストリングのエレガントな演奏により、S1 は、スピード、強さ、正確さを備えた繊細な操作と絶対的なコントロールを発揮します。 CCTVニュースは、「書道」の背後にある模倣学習とインテリジェント制御に関する特別レポートを実施し、同社の創設者ライ・ジエ氏は、滑らかな動きの背後にあるハードウェア側が最高の力制御と最も人間らしい身体指標(速度、負荷)を追求していると説明した。など)、AI側では人の実際の動きのデータが収集され、強い状況に遭遇したときにロボットがより強くなり、急速に進化することを学習することができます。そしてアジャイル
 ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
貢献者はこの ACL カンファレンスから多くのことを学びました。 6日間のACL2024がタイのバンコクで開催されています。 ACL は、計算言語学と自然言語処理の分野におけるトップの国際会議で、国際計算言語学協会が主催し、毎年開催されます。 ACL は NLP 分野における学術的影響力において常に第一位にランクされており、CCF-A 推奨会議でもあります。今年の ACL カンファレンスは 62 回目であり、NLP 分野における 400 以上の最先端の作品が寄せられました。昨日の午後、カンファレンスは最優秀論文およびその他の賞を発表しました。今回の優秀論文賞は7件(未発表2件)、最優秀テーマ論文賞1件、優秀論文賞35件です。このカンファレンスでは、3 つの Resource Paper Award (ResourceAward) と Social Impact Award (
 宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
今日の午後、Hongmeng Zhixingは新しいブランドと新車を正式に歓迎しました。 8月6日、ファーウェイはHongmeng Smart Xingxing S9およびファーウェイのフルシナリオ新製品発表カンファレンスを開催し、パノラマスマートフラッグシップセダンXiangjie S9、新しいM7ProおよびHuawei novaFlip、MatePad Pro 12.2インチ、新しいMatePad Air、Huawei Bisheng Withを発表しました。レーザー プリンタ X1 シリーズ、FreeBuds6i、WATCHFIT3、スマート スクリーン S5Pro など、スマート トラベル、スマート オフィスからスマート ウェアに至るまで、多くの新しいオールシナリオ スマート製品を開発し、ファーウェイは消費者にスマートな体験を提供するフル シナリオのスマート エコシステムを構築し続けています。すべてのインターネット。宏孟志興氏:スマートカー業界のアップグレードを促進するための徹底的な権限付与 ファーウェイは中国の自動車業界パートナーと提携して、
 Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
ビジョンとロボット学習の緊密な統合。最近話題の1X人型ロボットNEOと合わせて、2つのロボットハンドがスムーズに連携して服をたたむ、お茶を入れる、靴を詰めるといった動作をしていると、いよいよロボットの時代が到来するのではないかと感じられるかもしれません。実際、これらの滑らかな動きは、高度なロボット技術 + 精緻なフレーム設計 + マルチモーダル大型モデルの成果です。有用なロボットは多くの場合、環境との複雑かつ絶妙な相互作用を必要とし、環境は空間領域および時間領域の制約として表現できることがわかっています。たとえば、ロボットにお茶を注いでもらいたい場合、ロボットはまずティーポットのハンドルを掴んで、お茶をこぼさないように垂直に保ち、次にポットの口がカップの口と揃うまでスムーズに動かす必要があります。 、そしてティーポットを一定の角度に傾けます。これ
 7つの「ソラレベル」ビデオ生成アーティファクトをテストしました。誰が「鉄の玉座」に昇る能力を持っていますか?
Aug 05, 2024 pm 07:19 PM
7つの「ソラレベル」ビデオ生成アーティファクトをテストしました。誰が「鉄の玉座」に昇る能力を持っていますか?
Aug 05, 2024 pm 07:19 PM
Machine Power Report 編集者: Yang Wen AI ビデオ サークルの王になれるのは誰ですか?アメリカのテレビシリーズ「ゲーム・オブ・スローンズ」に「鉄の玉座」というものがあります。伝説によれば、それは最高の権威を象徴する敵が捨てた数千の剣を溶かした巨大なドラゴン「黒死病」によって作られたとされています。この鉄の椅子に座るために、主要な家族は争いと争いを始めました。 Sora の登場以来、AI ビデオ界では活発な「ゲーム オブ スローンズ」が立ち上がっています。このゲームの主なプレーヤーには、国内の Kuaishou Keling、ByteDream だけでなく、海の向こうの RunwayGen-3 や Luma も含まれます。およびZhimo。今日は、誰が AI ビデオサークルの「鉄の玉座」に座る資格があるかを評価して確認します。 -1- ヴィンセントビデオ
