

マルチモーダル RAG システムを構築する方法: CLIP と LLM を使用する

オープンソースの大規模言語マルチモーダルを使用して、検索拡張生成 (RAG) システムを構築する方法について説明します。私たちの焦点は、フレームワークの依存関係の追加を避けるために、LangChain や LLlama インデックスに依存せずにこれを達成することです。

RAGとは
人工知能の分野で、検索拡張世代の出現RAG テクノロジーの導入により、大規模言語モデル (Large Language Model) に革命的な改善がもたらされました。 RAG の本質は、モデルが外部ソースからリアルタイム情報を動的に取得できるようにすることで、人工知能の応答性を向上させることです。この技術の導入により、AIがユーザーのニーズによりきめ細かく対応できるようになります。外部ソースから情報を取得して融合することで、RAG はより正確で包括的な回答を生成し、より価値のあるコンテンツをユーザーに提供できます。この機能の向上により、インテリジェントな顧客サービス、インテリジェントな検索、知識の質問と回答システムなど、人工知能の応用分野に幅広い展望がもたらされました。 RAG の出現は、言語モデルのさらなる開発を示し、人工知能をもたらします
このアーキテクチャは、動的検索プロセスと生成機能をシームレスに組み合わせ、人工知能が常に変化する情報のさまざまな分野に適応できるようにします。 。微調整や再トレーニングとは異なり、RAG は、AI がモデル全体を変更せずに最新の関連情報を取得できる、コスト効率の高いソリューションを提供します。この機能の組み合わせにより、RAG は急速に変化する情報環境に対応する際の利点が得られます。
RAG の役割
1. 精度と信頼性の向上:
大きな言語でモデル (LLM) は信頼できる情報源を直接導き、その予測不可能性の問題を解決し、誤った情報や古い情報を提供するリスクを軽減し、応答の正確性と信頼性を高めます。
2. 透明性と信頼性の向上:
LLM のような生成 AI モデルは透明性に欠けていることが多く、人々が信頼することが困難になります。出力。 RAG は、より優れた制御を提供することで、バイアス、信頼性、コンプライアンスに関する懸念に対処します。
3. 幻覚を減らす:
LLM は幻覚反応を起こしやすく、一貫性はあるが不正確または捏造された情報を提供します。 RAG は、信頼できる情報源に依存して対応力を確保することで、主要部門への誤解を招くアドバイスのリスクを軽減します。
4. 費用対効果の高い適応性:
RAG は、大規模な再トレーニングや罰金を必要とせずに AI 出力を向上させる費用対効果の高い方法を提供します。 -チューニング。必要に応じて特定の詳細を動的に取得することで、情報を最新かつ関連性の高い状態に保つことができ、変化する情報に対する AI の適応性を確保します。
マルチモーダル モーダル モデル
マルチモーダルには、CLIP を例として、複数の入力があり、それらを 1 つの出力に結合することが含まれます。 CLIP はテキストと画像のペアであり、モデルは比較学習を通じてテキストと画像のペアの一致関係を学習できます。
このモデルは、同じものを表す異なる入力に対して同じ (非常に類似した) 埋め込みベクトルを生成します。
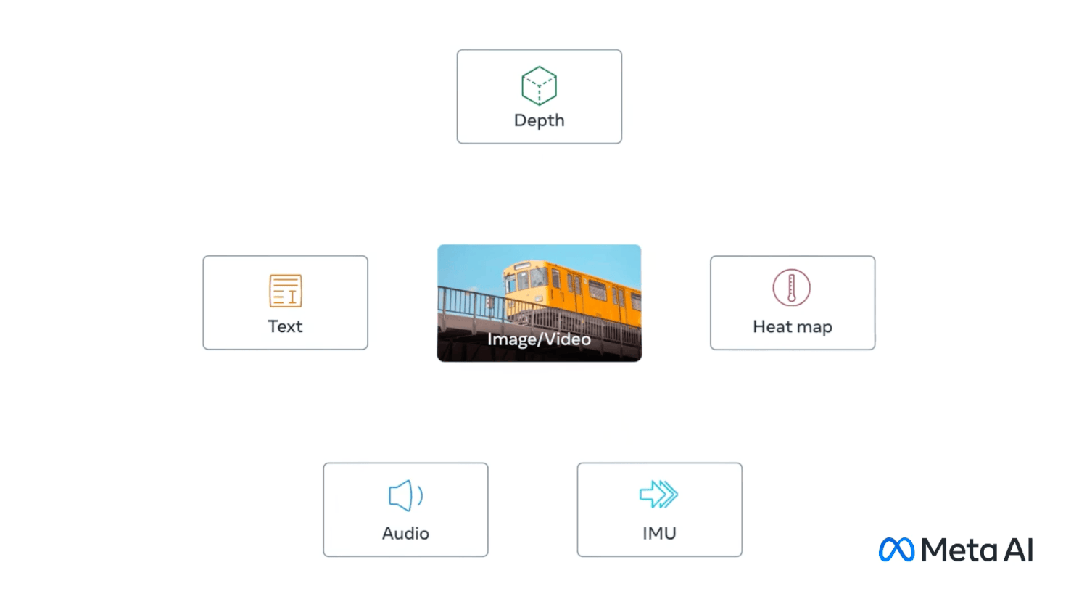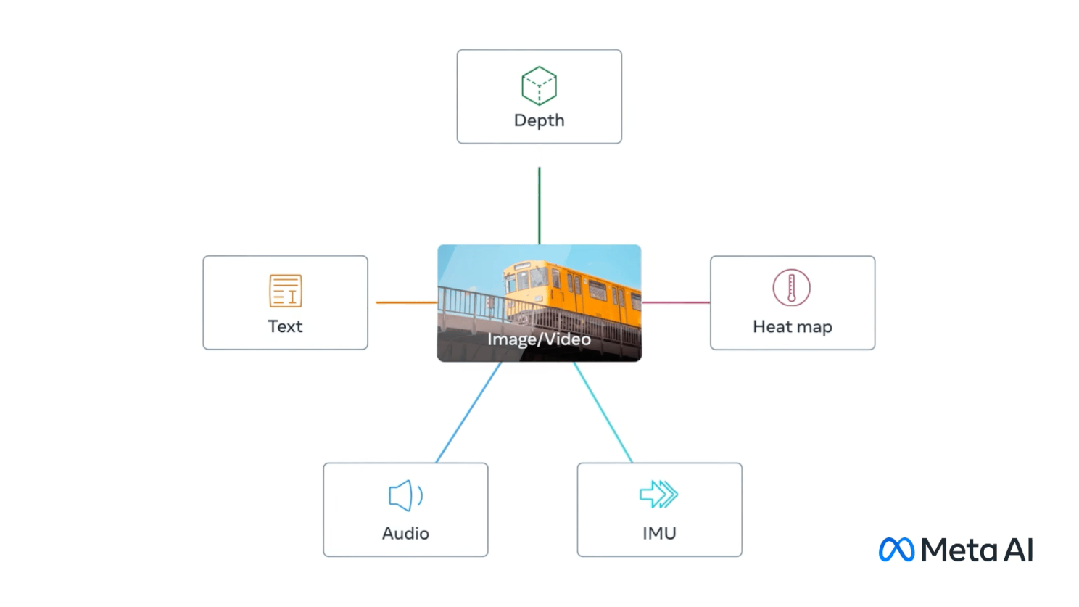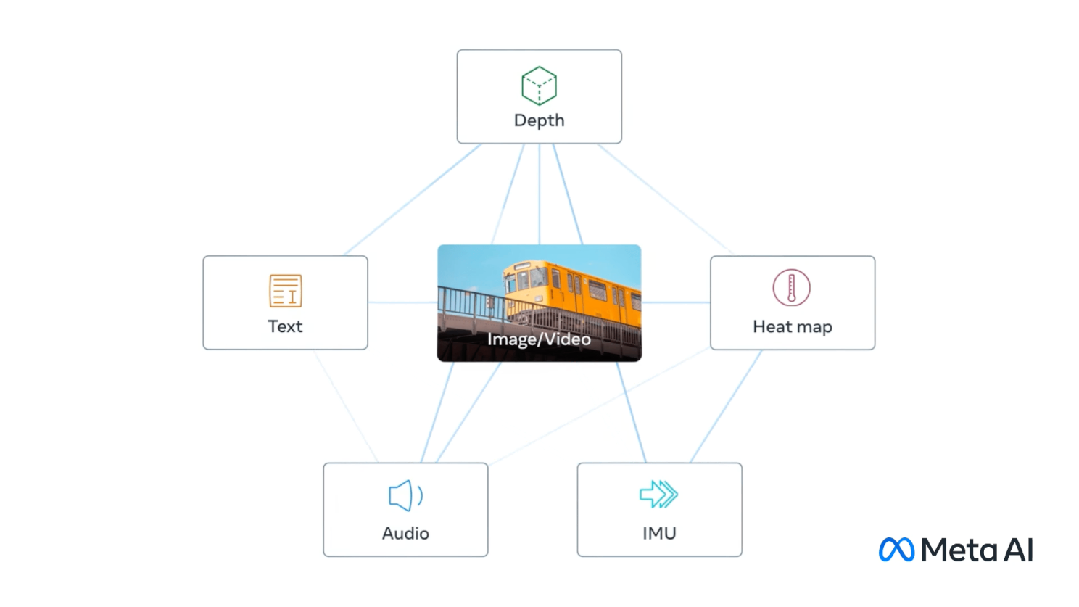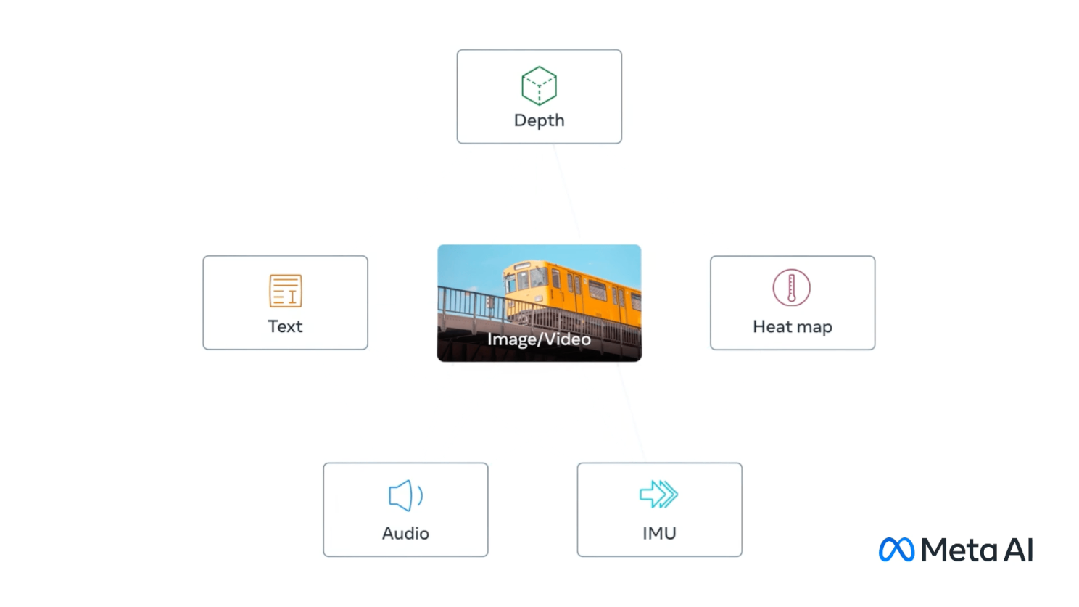
##マルチモード
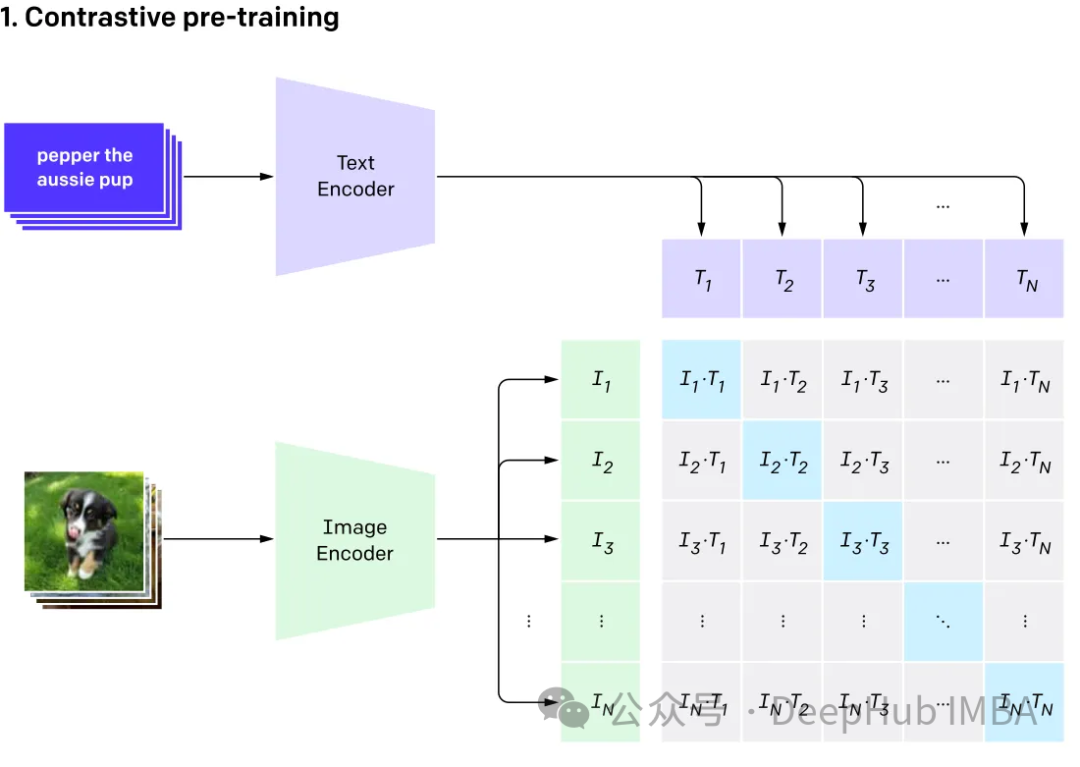
マルチモーダル大規模言語
GPT4v と Gemini ビジョンは、さまざまなデータ型 (画像、テキスト、言語、音声など) を統合するマルチモーダル大規模言語を探索します。 モーダル言語モデル (MLLM)。 GPT-3、BERT、RoBERTa などの大規模言語モデル (LLM) はテキストベースのタスクではうまく機能しますが、他のデータ型の理解と処理では課題に直面しています。この制限に対処するために、マルチモーダル モデルはさまざまなモダリティを組み合わせて、さまざまなデータをより包括的に理解できるようにします。
マルチモーダル大規模言語モデル 従来のテキストベースの方法を超えています。 GPT-4 を例に挙げると、これらのモデルは、画像やテキストなどのさまざまなデータ タイプをシームレスに処理して、情報をより包括的に理解できます。
RAG と組み合わせる
ここでは、Clip を使用して画像とテキストを埋め込み、これらの埋め込みを ChromDB ベクター データベースに保存します。大規模なモデルは、取得された情報に基づいてユーザー チャット セッションに参加するために利用されます。
Kaggle の画像と Wikipedia の情報を使用して、花の専門家チャットボットを作成します
最初にソフトウェア パッケージをインストールします:
! pip install -q timm einops wikipedia chromadb open_clip_torch !pip install -q transformers==4.36.0 !pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
データを前処理する手順は非常に簡単です。画像とテキストをフォルダーに置くだけです
可以随意使用任何矢量数据库,这里我们使用ChromaDB。
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
ChromaDB需要自定义嵌入函数
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
这里将创建2个集合,一个用于文本,另一个用于图像
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collection对于Clip,我们可以像这样使用文本检索图像
from matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()
也可以使用图像检索相关的图像

文本集合如下所示
# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )然后使用上面的文本集合获取嵌入
results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
结果如下:
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}或使用图片获取文本
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

上图的结果如下:
A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
我们是用visheratin/LLaVA-3b
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")加载tokenizer
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")然后定义处理器,方便我们以后调用
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
下面就可以直接使用了
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()得到的结果如下:

结果还包含了我们需要的大部分信息

这样我们整合就完成了,最后就是创建聊天模板,
prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
https://www.php.cn/link/71eee742e4c6e094e6af364597af3f05
以上がマルチモーダル RAG システムを構築する方法: CLIP と LLM を使用するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) は徐々に普及しており、従来のベクトル検索方法を強力に補完するものとなっています。この方法では、グラフ データベースの構造的特徴を利用してデータをノードと関係の形式で編成し、それによって取得された情報の深さと文脈の関連性が強化されます。グラフには、相互に関連する多様な情報を表現および保存するという自然な利点があり、異なるデータ型間の複雑な関係やプロパティを簡単に把握できます。ベクトル データベースはこの種の構造化情報を処理できず、高次元ベクトルで表される非構造化データの処理に重点を置いています。 RAG アプリケーションでは、構造化グラフ データと非構造化テキスト ベクトル検索を組み合わせることで、両方の利点を同時に享受できます。これについてこの記事で説明します。構造
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
