

GPT-4の知能レベルの低下に関する新たな解釈

GPT-4 は、リリース以来世界で最も強力な言語モデルの 1 つとみなされていますが、残念ながら一連の信頼の危機を経験しました。
今年初めの「断続的インテリジェンス」インシデントを OpenAI による GPT-4 アーキテクチャの再設計と結び付けると、GPT-4 が「怠惰」になったという最近の報告があります。噂はさらに興味深いものです。誰かがテストした結果、GPT-4 に「冬休みです」と伝えると、冬眠状態に入ったかのように怠惰になることがわかりました。
新しいタスクにおけるモデルのゼロサンプルのパフォーマンスが低いという問題を解決するには、次の方法を採用できます。 1. データの強化: 既存のデータを拡張および変換することで、モデルの汎化能力を高めます。たとえば、画像データは、回転、拡大縮小、平行移動などによって、または新しいデータ サンプルを合成することによって変更できます。 2. 転移学習: 他のタスクでトレーニングされたモデルを使用して、そのパラメーターと知識を新しいタスクに転送します。これにより、既存の知識と経験を活用して改善できます。
最近、カリフォルニア大学サンタクルーズ校の研究者らは、パフォーマンスの根本的な理由を説明できる可能性がある新しい発見を論文で発表しました。 GPT-4の分解。

「LLM は、トレーニング データの作成日より前にリリースされたデータセットで驚くほど優れたパフォーマンスを発揮することがわかりました。データセットは後でリリースされました。」
「既知の」タスクでは良好なパフォーマンスを発揮しますが、新しいタスクではパフォーマンスが低下します。これは、LLM が近似検索に基づいて知性を模倣する方法にすぎず、主に理解レベルを問わず物事を暗記することを意味します。
はっきり言って、LLM の汎化能力は「言われているほど強力ではない」です。基礎がしっかりしていないため、実戦では必ずミスが発生します。
この結果の主な原因の 1 つは、データ汚染の一種である「タスク汚染」です。これまでよく知られてきたデータ汚染はテスト データ汚染です。これは、トレーニング前のデータにテスト データの例とラベルが含まれていることです。 「タスクの汚染」とは、タスクのトレーニング例がトレーニング前のデータに追加されることで、ゼロサンプルまたは少数サンプルの方法での評価が現実的で効果的ではなくなります。
研究者は、論文で初めてデータ汚染問題の体系的な分析を実施しました:

論文リンク: https://arxiv.org/pdf/2312.16337.pdf
論文を読んだ後、誰かが「悲観的に」言いました:
これは、継続的に学習する能力、つまり ML モデル トレーニング後に重みは固定されますが、入力分布は変化し続けるため、モデルがこの変化に適応し続けることができない場合、モデルは徐々に低下します。
これは、プログラミング言語が常に更新されるにつれて、LLM ベースのコーディング ツールも劣化することを意味します。これが、このような壊れやすいツールに過度に依存する必要がない理由の 1 つです。
これらのモデルを継続的に再トレーニングするコストは高くつくため、遅かれ早かれ、誰かがこれらの非効率な方法を諦めるでしょう。
以前のエンコード タスクに重大な中断やパフォーマンスの損失を引き起こすことなく、変化する入力分布に確実かつ継続的に適応できる ML モデルはまだありません。
そして、これは生物学的ニューラル ネットワークが得意とする分野の 1 つです。生物学的ニューラル ネットワークの強力な汎化能力により、さまざまなタスクを学習すると、システムのパフォーマンスがさらに向上します。これは、1 つのタスクから得られた知識が、「メタ学習」と呼ばれる学習プロセス全体の改善に役立つためです。
「タスク汚染」の問題はどれくらい深刻ですか?紙面の内容を見てみましょう。
モデルとデータセット
実験では 12 個のモデルが使用されています (表 1 を参照)。そのうちの 5 つは独自のものです。 GPT-3 シリーズ モデルのうち 7 つは、ウェイトに自由にアクセスできるオープン モデルです。
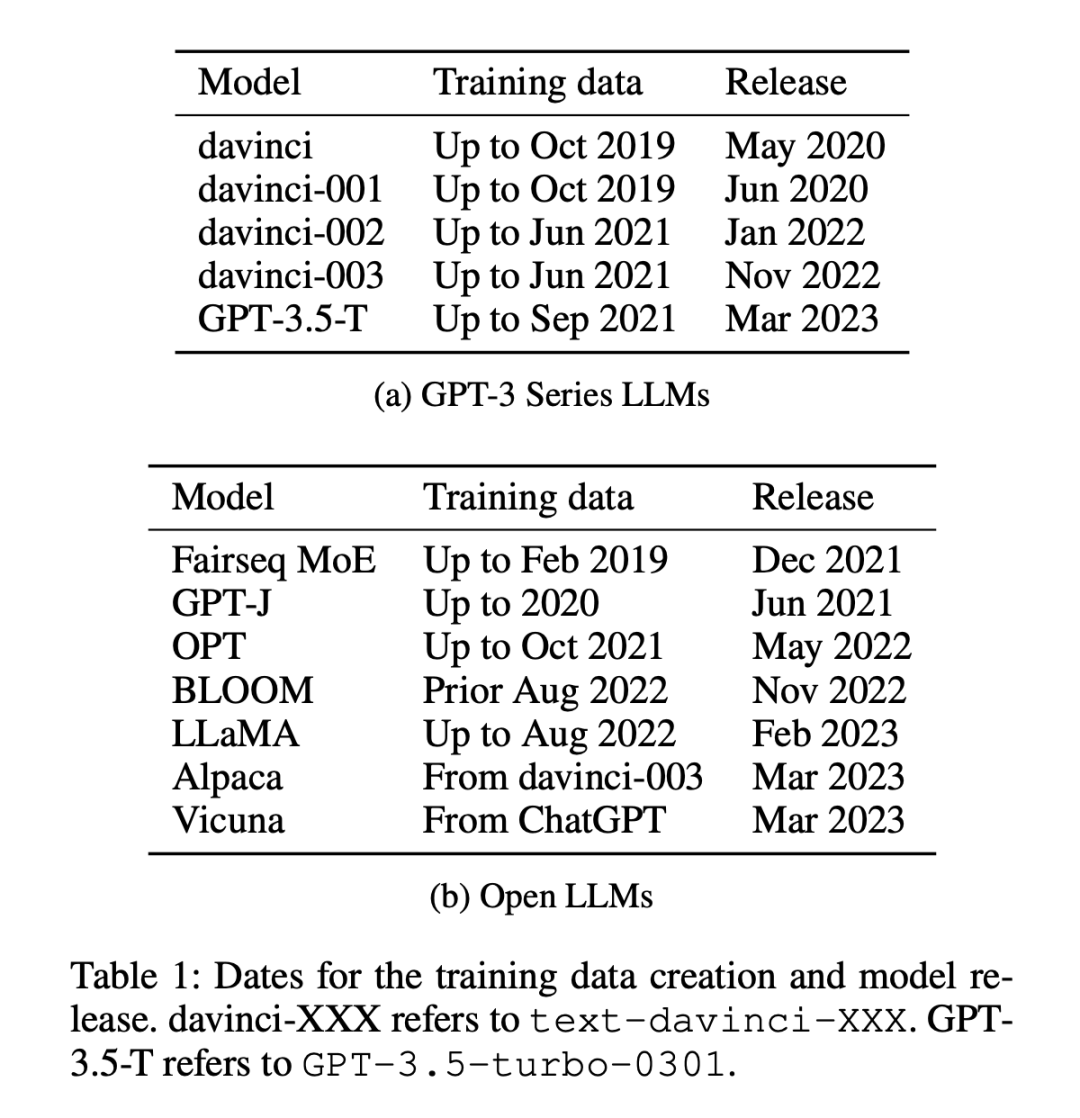
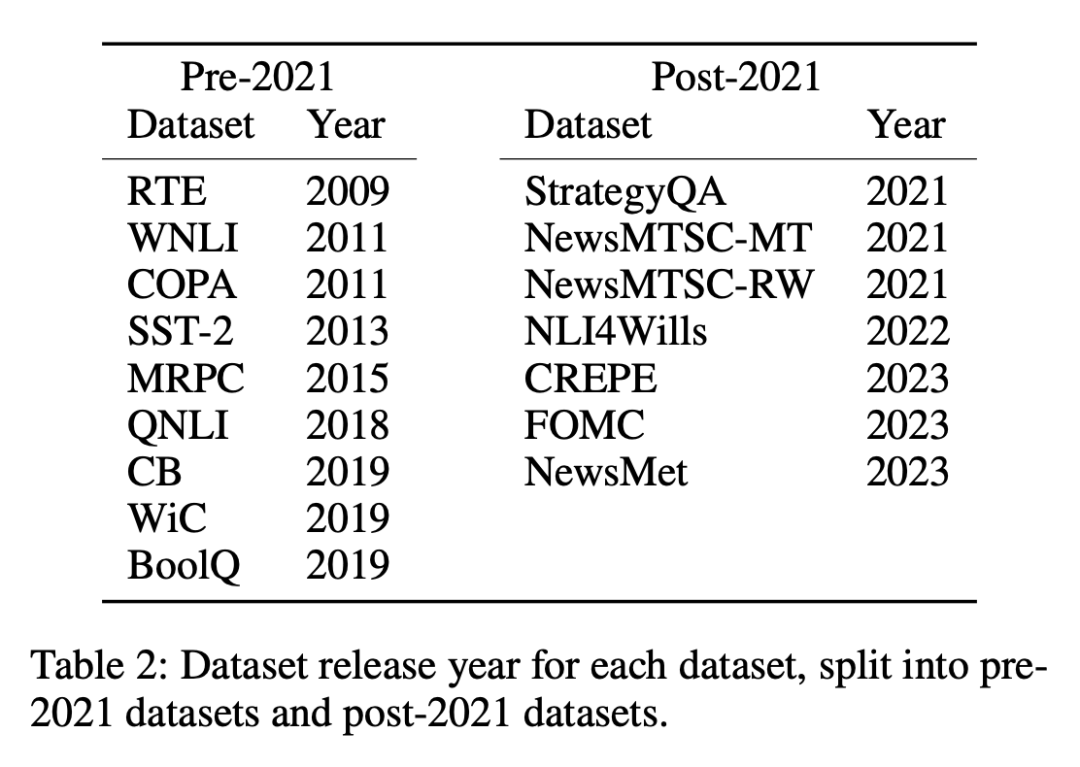
上記のアプローチの背後にある考慮事項は、ゼロショット評価と少数ショット評価では、モデルがトレーニング中に一度も見たことがないか、数回しか見たことがないタスクについての予測を行う必要があるということです。完了すべき特定のタスクにさらされることで、学習能力の公正な評価が保証されます。ただし、汚染されたモデルは、事前トレーニング中にタスク例に基づいてトレーニングされているため、実際にさらされていない、または数回しかさらされていない能力があるかのような錯覚を与える可能性があります。時系列のデータセットでは、重複や異常が明らかになるため、このような不一致を検出するのは比較的簡単です。
#測定方法 研究者らは、「タスクの汚染」を測定するために 4 つの方法を使用しました。- トレーニング データの検査: タスク トレーニングのサンプルのトレーニング データを検索します。
- タスク例の抽出: 既存のモデルからタスク例を抽出します。命令調整されたモデルのみを抽出でき、この分析はトレーニング データやテスト データの抽出にも使用できます。タスクの汚染を検出するために、抽出されたタスクの例が既存のトレーニング データの例と正確に一致する必要はないことに注意してください。タスクを実証するあらゆる例は、ゼロショット学習と少数ショット学習の混入の可能性を示しています。
- メンバーの推論: この方法はビルド タスクにのみ適用されます。入力インスタンスのモデル生成コンテンツが元のデータセットとまったく同じであることを確認します。正確に一致する場合、それが LLM トレーニング データのメンバーであると推測できます。これは、生成された出力が完全に一致するかどうかチェックされるという点で、タスク例の抽出とは異なります。オープンエンド生成タスクでの完全一致は、モデルが「超能力」を持ち、データで使用されている正確な表現を知っている場合を除き、モデルがトレーニング中にこれらの例を見たということを強く示唆します。 (これはビルド タスクにのみ使用できることに注意してください。)
- 時系列分析: 既知の時間枠中にトレーニング データが収集されたモデル セットの場合、既知のリリース日のデータセットでパフォーマンスを測定します。汚染の証拠については、一時的な証拠チェックを使用します。
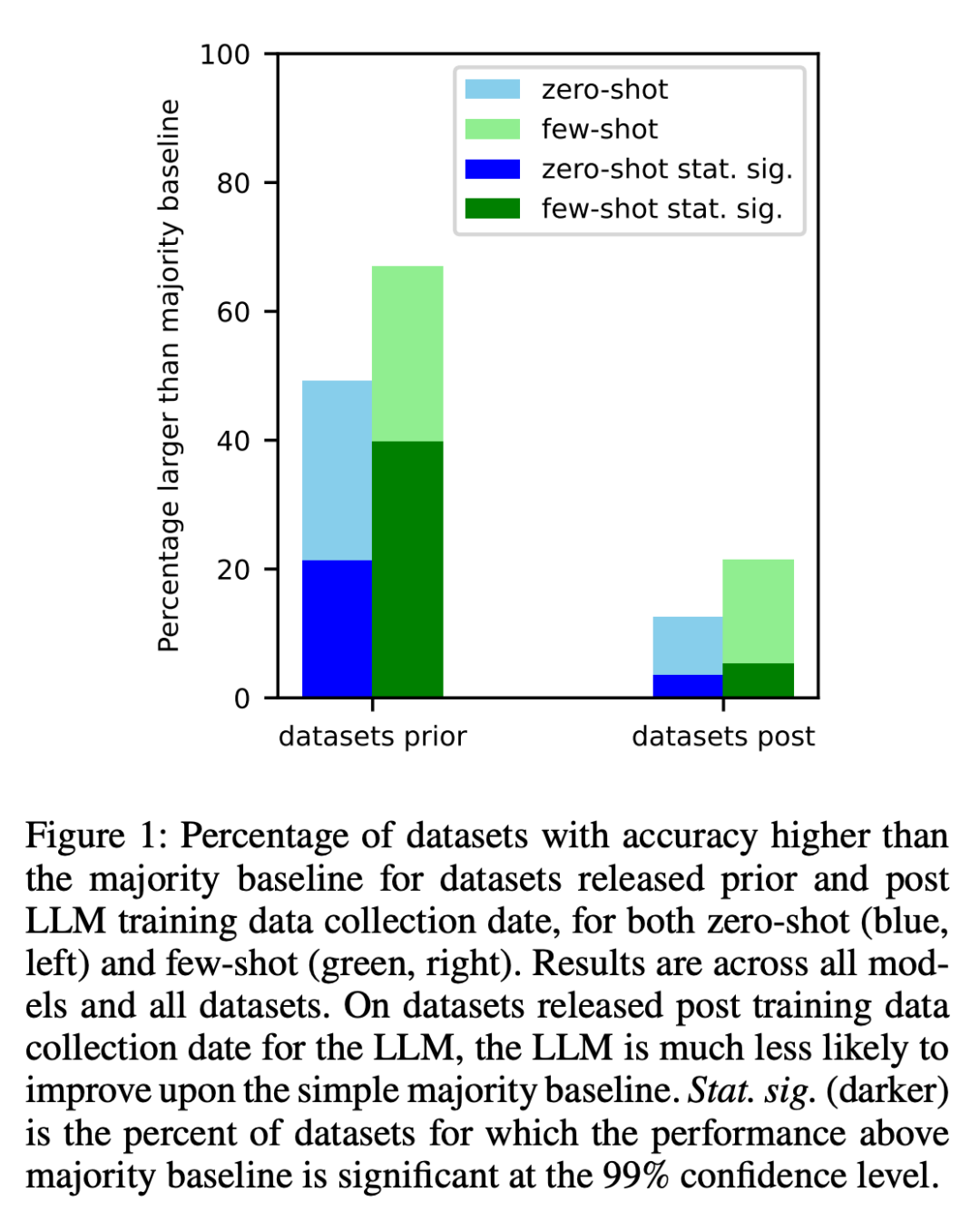
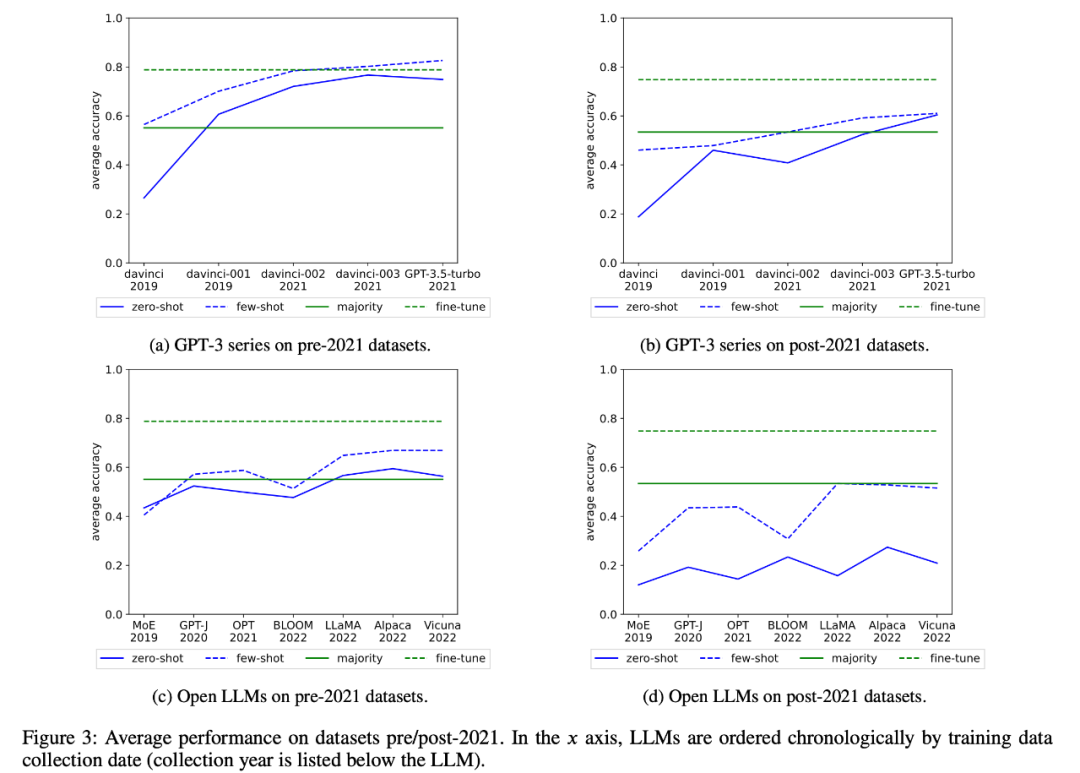
#2. 研究者は、タスク汚染の可能性を見つけるために、トレーニング データの検査とタスク例の抽出を実施しました。タスクの汚染が考えられない分類タスクでは、ゼロショットか少数ショットかにかかわらず、モデルがタスクの範囲全体で単純多数派ベースラインを超える統計的に有意な改善を達成することはほとんどないことがわかりました (図 2)。
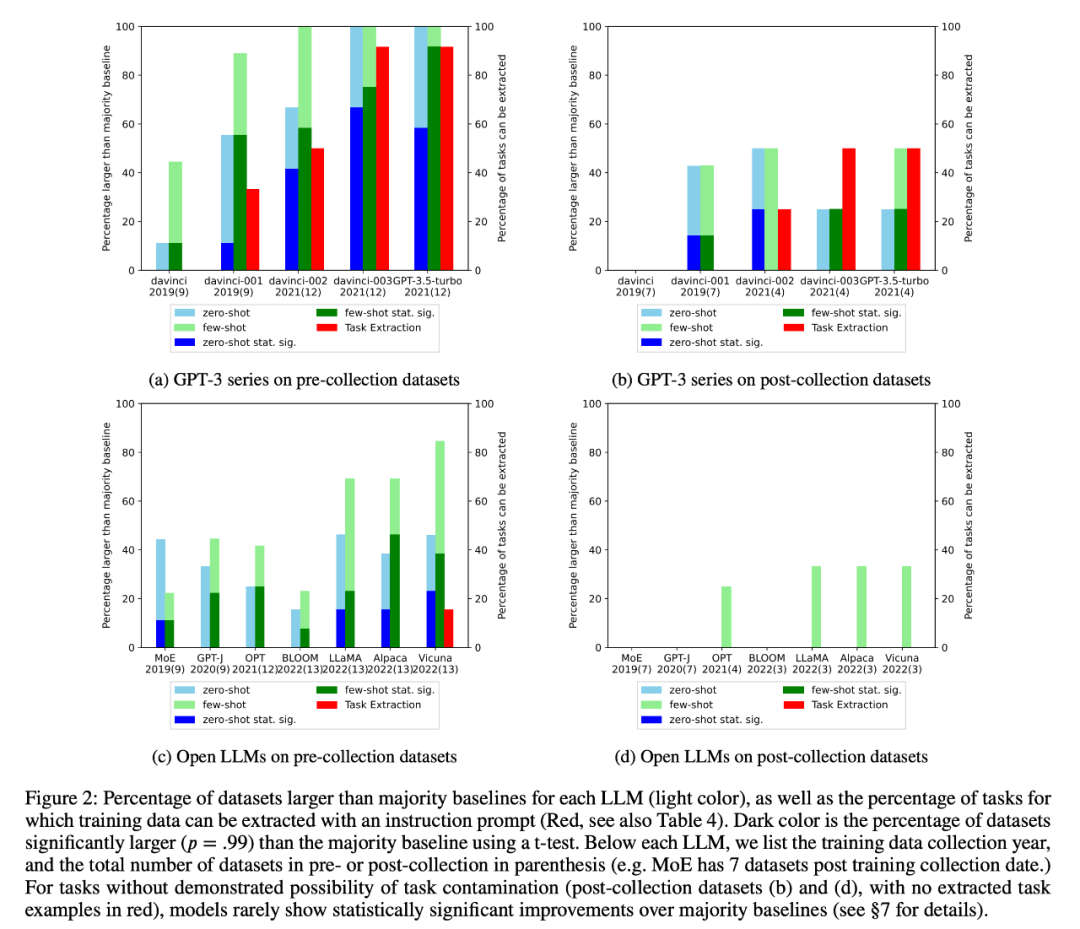
研究者らは、GPT-3 シリーズとオープン LLM の平均パフォーマンスの時間の経過に伴う変化も調べました。図 3 :
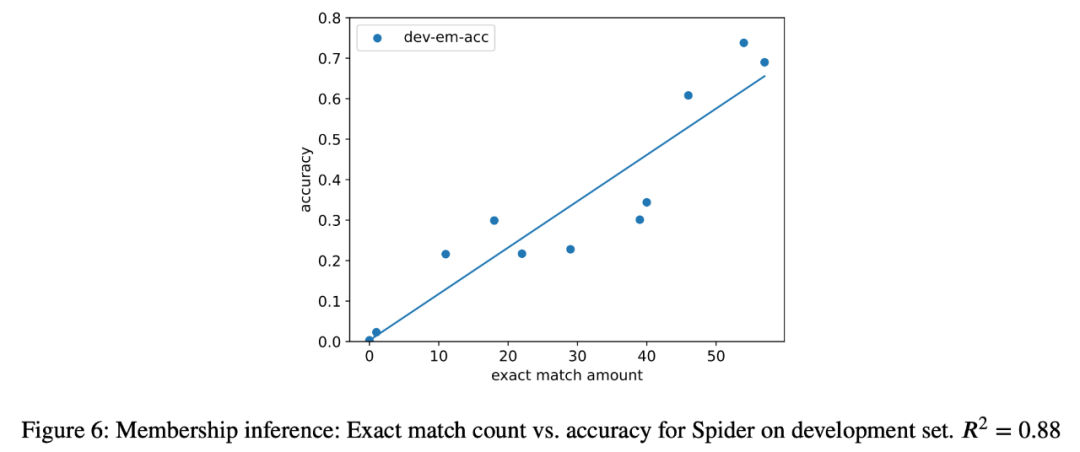
3. ケーススタディとして、研究者はまた、すべてのオブジェクトに対してセマンティック解析タスクを実行しようとしました。推論攻撃では、抽出されたインスタンスの数と最終タスクのモデルの精度の間に強い相関関係 (R=.88) が見つかりました (図 6)。これは、このタスクのゼロショット パフォーマンスの向上がタスクの汚染によるものであることを強く証明しています。
4. 研究者らはまた、GPT-3 シリーズ モデルを注意深く研究し、GPT-3 モデルからトレーニング サンプルを抽出でき、davinci から GPT-3.5-turbo までの各バージョンでトレーニング サンプルを抽出できることを発見しました。抽出された数は増加しています。これは、このタスクにおける GPT-3 モデルのゼロサンプル パフォーマンスの向上と密接に関係しています (図 2)。これは、これらのタスクにおける davinci から GPT-3.5-turbo への GPT-3 モデルのパフォーマンス向上がタスクの汚染によるものであることを強く証明しています。
以上がGPT-4の知能レベルの低下に関する新たな解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7741
7741
 15
1643
14
1397
52
1291
25
1233
29
15
1643
14
1397
52
1291
25
1233
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
2023年、AI技術が注目を集め、プログラミング分野を中心にさまざまな業界に大きな影響を与えています。 AI テクノロジーの重要性に対する人々の認識はますます高まっており、Spring コミュニティも例外ではありません。 GenAI (汎用人工知能) テクノロジーの継続的な進歩に伴い、AI 機能を備えたアプリケーションの作成を簡素化することが重要かつ緊急になっています。このような背景から、AI 機能アプリケーションの開発プロセスを簡素化し、シンプルかつ直観的にし、不必要な複雑さを回避することを目的とした「SpringAI」が登場しました。 「SpringAI」により、開発者はAI機能を搭載したアプリケーションをより簡単に構築でき、使いやすく、操作しやすくなります。
 データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
OpenAI は最近、最新世代の埋め込みモデル embeddingv3 のリリースを発表しました。これは、より高い多言語パフォーマンスを備えた最もパフォーマンスの高い埋め込みモデルであると主張しています。このモデルのバッチは、小さい text-embeddings-3-small と、より強力で大きい text-embeddings-3-large の 2 つのタイプに分類されます。これらのモデルがどのように設計され、トレーニングされるかについてはほとんど情報が開示されておらず、モデルには有料 API を介してのみアクセスできます。オープンソースの組み込みモデルは数多くありますが、これらのオープンソース モデルは OpenAI のクローズド ソース モデルとどう違うのでしょうか?この記事では、これらの新しいモデルのパフォーマンスをオープンソース モデルと実証的に比較します。データを作成する予定です
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
著者丨コンパイル: TimAnderson丨プロデュース: Noah|51CTO Technology Stack (WeChat ID: blog51cto) Zed エディター プロジェクトはまだプレリリース段階にあり、AGPL、GPL、および Apache ライセンスの下でオープンソース化されています。このエディターは高性能と複数の AI 支援オプションを備えていますが、現在は Mac プラットフォームでのみ利用可能です。 Nathan Sobo 氏は投稿の中で、GitHub 上の Zed プロジェクトのコード ベースでは、エディター部分は GPL に基づいてライセンスされ、サーバー側コンポーネントは AGPL に基づいてライセンスされ、GPUI (GPU Accelerated User) インターフェイス部分はApache2.0ライセンス。 GPUI は Zed チームによって開発された製品です
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
