

小さくても強力なモデルが増加中: TinyLlama と LiteLlama が人気の選択肢になる

現在、研究者はコンパクトで高性能な小型モデルに焦点を当て始めていますが、誰もがパラメータサイズが数百億、さらには数千億に達する大規模なモデルを研究しています。
小型モデルは、スマートフォン、IoT デバイス、組み込みシステムなどのエッジ デバイスで広く使用されています。これらのデバイスは多くの場合、コンピューティング能力とストレージ容量が限られており、大規模な言語モデルを効率的に実行できません。したがって、小さなモデルを研究することが特に重要になります。
次に紹介する 2 つの研究は、小規模モデルのニーズを満たす可能性があります。
TinyLlama-1.1B
シンガポール工科デザイン大学 (SUTD) の研究者らは最近、11 億パラメータの言語である TinyLlama をリリースしました。モデルは約 3 兆個のトークンで事前トレーニングされています。

- #論文アドレス: https://arxiv.org/pdf/2401.02385.pdf
- プロジェクトアドレス: https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama は Llama 2 アーキテクチャとトークナイザーに基づいており、Llama を使用する多くのオープン ソース プロジェクトと簡単に統合できます。さらに、TinyLlama にはパラメータが 11 億個しかなく、サイズも小さいため、限られた計算量とメモリ フットプリントを必要とするアプリケーションに最適です。
調査では、90 日間で TinyLlama のトレーニングを完了できるのは 16 個の A100-40G GPU のみであることが示されています。

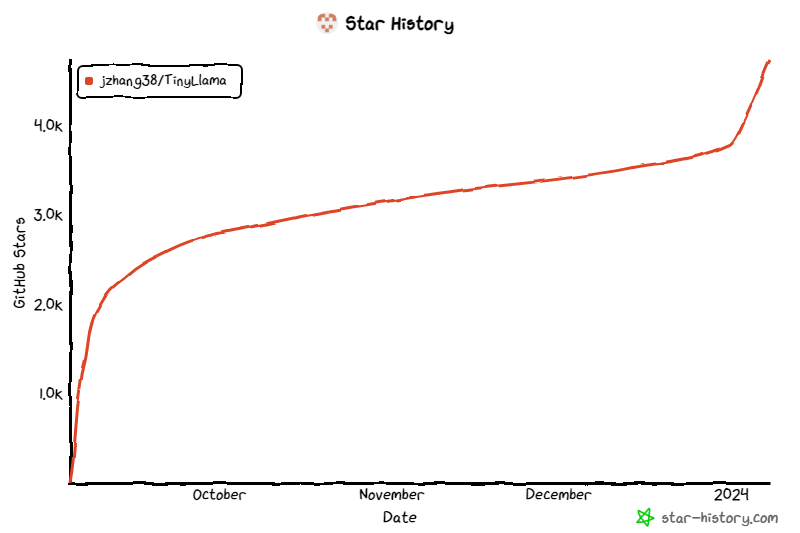
このプロジェクトは開始以来注目を集め続けており、現在の星の数は 4.7,000 に達しています。
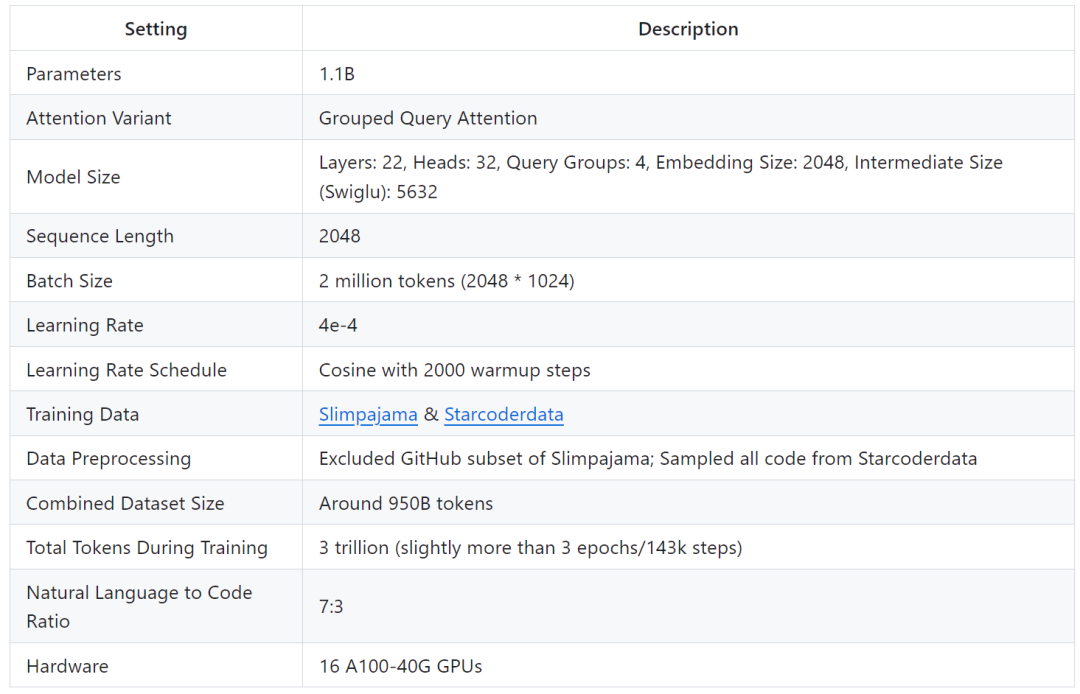
TinyLlama モデル アーキテクチャの詳細は次のとおりです:

トレーニングの詳細は次のとおりです:
研究者は、この研究はトレーニングに大規模なデータセットを使用してマイニングすることを目的としていると述べました。より小さなモデルの可能性。彼らは、スケーリング則で推奨されているよりもはるかに多くのトークンを使用してトレーニングしたときの、より小さなモデルの動作を調査することに重点を置きました。
具体的には、この研究では、1.1B パラメーターを使用して Transformer (デコーダーのみ) モデルをトレーニングするために約 3 兆のトークンを使用しました。私たちの知る限り、このような大量のデータを使用して 1B パラメーターでモデルをトレーニングする試みはこれが初めてです。
TinyLlama は、サイズが比較的小さいにもかかわらず、さまざまなダウンストリーム タスクで非常に優れたパフォーマンスを発揮し、同様のサイズの既存のオープンソース言語モデルを大幅に上回ります。具体的には、TinyLlama は、さまざまなダウンストリーム タスクにおいて OPT-1.3B および Pythia1.4B よりも優れたパフォーマンスを発揮します。
さらに、TinyLlama は、フラッシュ アテンション 2、FSDP (Fully Sharded Data Parallel)、xFormers など、さまざまな最適化手法も使用します。
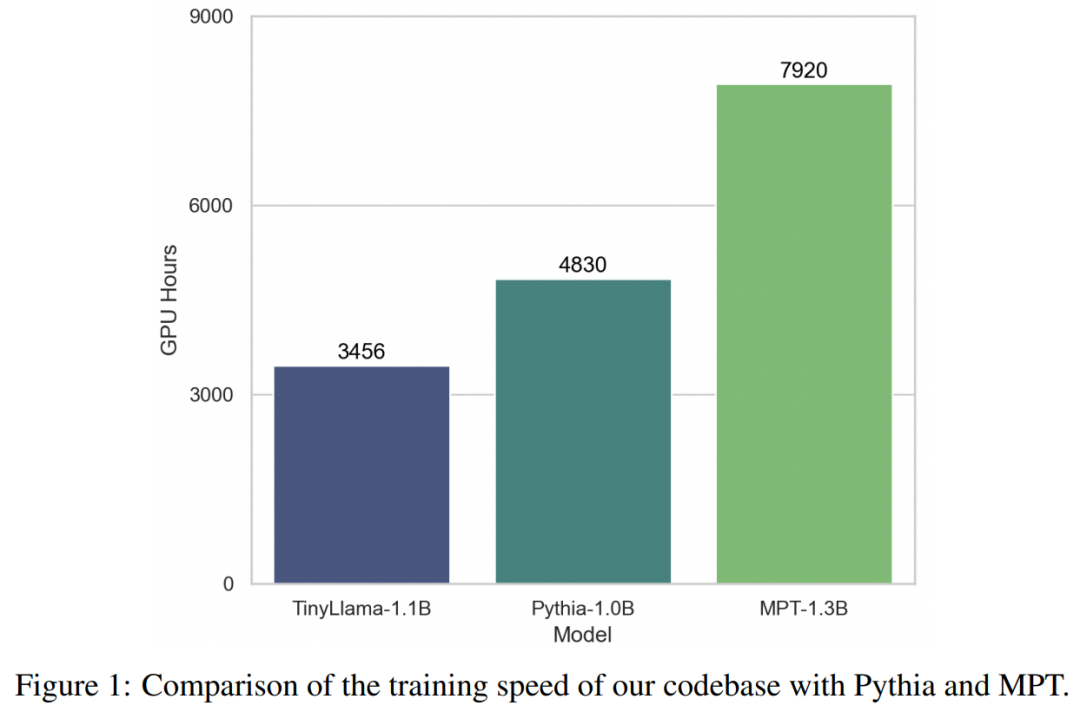
これらのテクノロジーのサポートにより、TinyLlama のトレーニング スループットは、A100-40G GPU あたり 1 秒あたり 24,000 トークンに達します。たとえば、TinyLlama-1.1B モデルでは、300B トークンに必要な A100 GPU 時間はわずか 3,456 時間ですが、Pythia では 4,830 時間、MPT では 7,920 時間かかります。これは、この研究の最適化の有効性と、大規模なモデルのトレーニングで大幅な時間とリソースを節約できる可能性を示しています。
TinyLlama は、24,000 トークン/秒/A100 のトレーニング速度を達成します。この速度は、ユーザーが 8 台の A100 で 11 億のパラメーターと 220 億のトークンを使用してチンチラを 32 時間でトレーニングできるのと同じです。 -最適なモデル。同時に、これらの最適化によりメモリ使用量も大幅に削減され、GPU あたりのバッチ サイズ 16,000 トークンを維持しながら、11 億のパラメーター モデルを 40 GB GPU に詰め込むことができます。バッチ サイズを少し小さく変更するだけで、RTX 3090/4090 で TinyLlama をトレーニングできます。

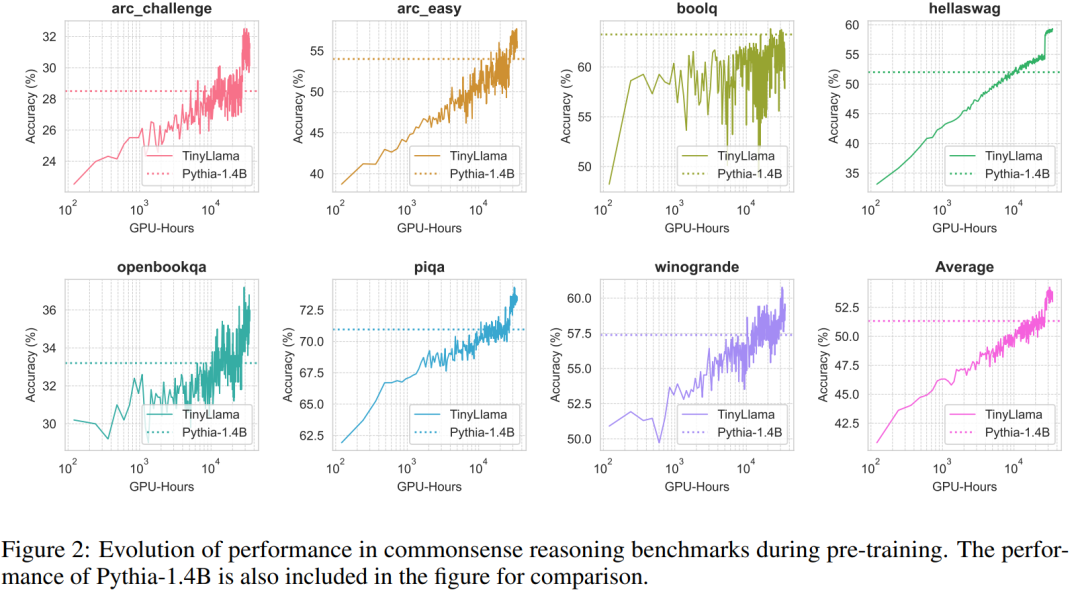
実験では、この研究は主に純粋な言語を対象としています。約 10 億のパラメータを含むデコーダ アーキテクチャ モデル。具体的には、この研究では TinyLlama を OPT-1.3B、Pythia-1.0B、および Pythia-1.4B と比較しました。
常識推論タスクにおける TinyLlama のパフォーマンスを以下に示しますが、TinyLlama は多くのタスクでベースラインを上回り、最高の平均スコアを達成していることがわかります。

さらに、研究者らは、図 2 に示すように、事前トレーニング中に常識推論ベンチマークで TinyLlama の精度を追跡しました。 TinyLlama の精度はコンピューティング リソースの増加とともに向上し、ほとんどのベンチマークで Pythia-1.4B の精度を上回ります。
#表 3 は、TinyLlama が既存のモデルと比較して優れた問題解決能力を示していることを示しています。
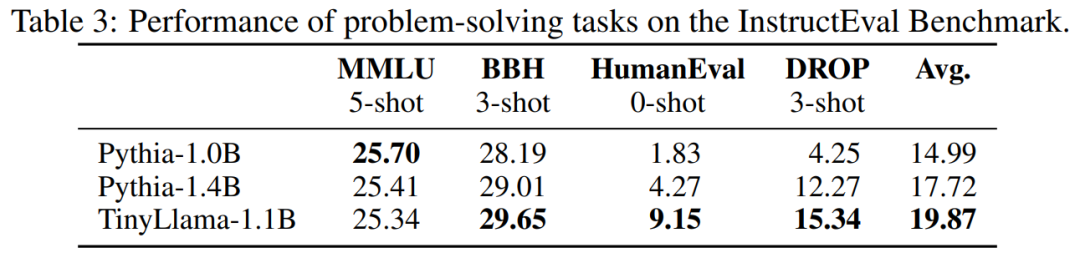
手の早いネチズンはすでに使い始めています。ランニング効果は驚くほど良好で、GTX3060 で実行すると、次の速度で実行できます。 136 トーク/秒。
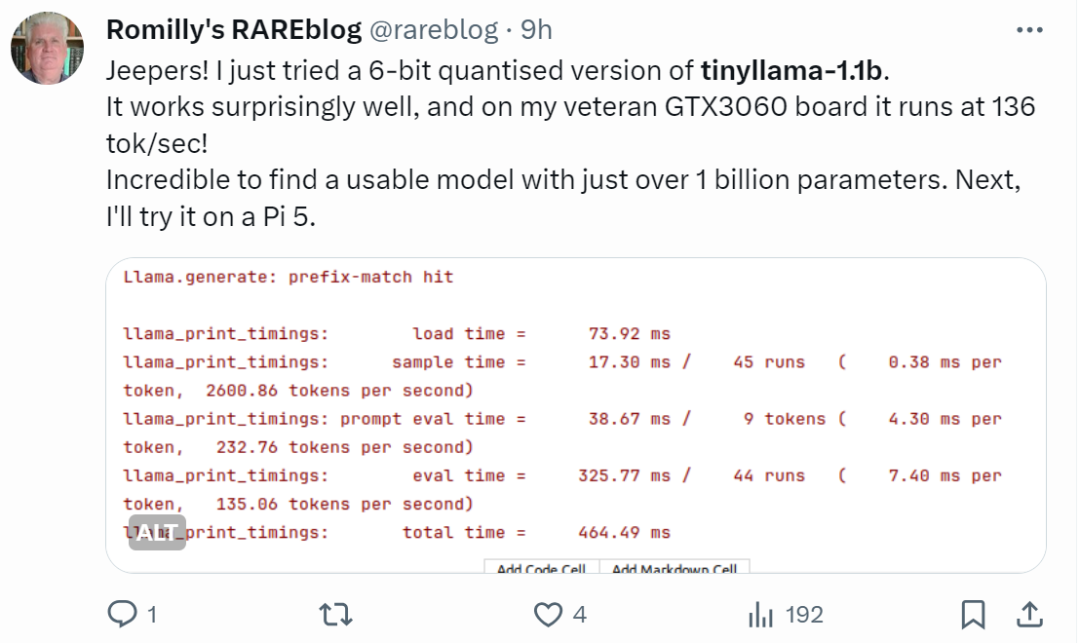
「本当に早いですね!」
TinyLlama のリリースにより、SLM (Small Language Model) が広く注目を集め始めました。テキサス工科大学と A&M 大学の Xiaotian Han 氏は、SLM-LiteLlama をリリースしました。 4 億 6,000 万個のパラメータがあり、1T トークンでトレーニングされています。これは Meta AI の LLaMa 2 のオープンソース フォークですが、モデル サイズが大幅に小さくなっています。
 # プロジェクトアドレス: https://huggingface.co/ahxt/LiteLlama-460M-1T
# プロジェクトアドレス: https://huggingface.co/ahxt/LiteLlama-460M-1T
#LiteLlama-460M-1T は RedPajama データセットでトレーニングされ、GPT2Tokenizer を使用してテキストをトークン化します。著者は MMLU タスクでモデルを評価し、その結果を次の図に示します。パラメータの数を大幅に減らしても、LiteLlama-460M-1T は他のモデルと同等以上の結果を達成できます。
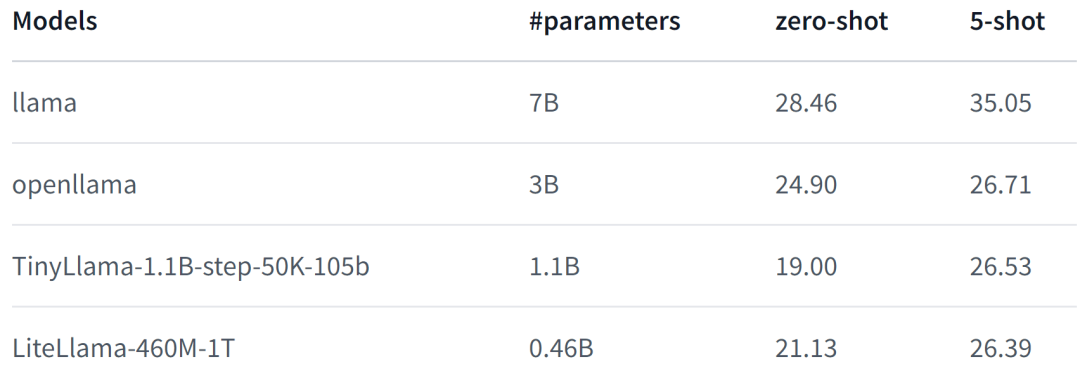 モデルの性能は次のとおりです。詳細については、
モデルの性能は次のとおりです。詳細については、
を参照してください。
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6 LiteLlama の規模が大幅に縮小されたことに直面して、一部のネチズンは4GB のメモリで動作しますか?あなたも知りたいと思ったら、ぜひ試してみてはいかがでしょうか。 

以上が小さくても強力なモデルが増加中: TinyLlama と LiteLlama が人気の選択肢になるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
