###導入###
| アプリケーションの入出力 (I/O) モデルを理解することは、計画された処理負荷と過酷な現実世界の使用シナリオとの違いを意味します。アプリケーションが比較的小さく、高負荷を提供しない場合、影響はほとんどない可能性があります。しかし、アプリケーションの負荷が徐々に増加するため、間違った I/O モデルを採用すると、多くの落とし穴や傷跡が残る可能性があります。
|
複数のソリューションがあるほとんどのシナリオと同様に、どのアプローチがより優れているかではなく、トレードオフを実現する方法を理解することに重点が置かれています。 I/O ランドスケープをツアーして、そこから何が盗めるかを見てみましょう。

この記事では、Node、Java、Go、および PHP をそれぞれ Apache と比較し、これらの異なる言語がどのように I/O をモデル化するか、各モデルの長所と短所について説明し、結論を導き出します。ベンチマーク。次の Web アプリケーションの I/O パフォーマンスが気になる場合は、適切な記事を見つけてください。
I/O の基本: 簡単な復習
I/O に密接に関連する要素を理解するには、まずオペレーティング システムの基礎となる概念を確認する必要があります。これらの概念のほとんどは直接扱うことはありませんが、アプリケーションのランタイム環境を通じて間接的に扱ってきました。そして悪魔は細部に宿ります。
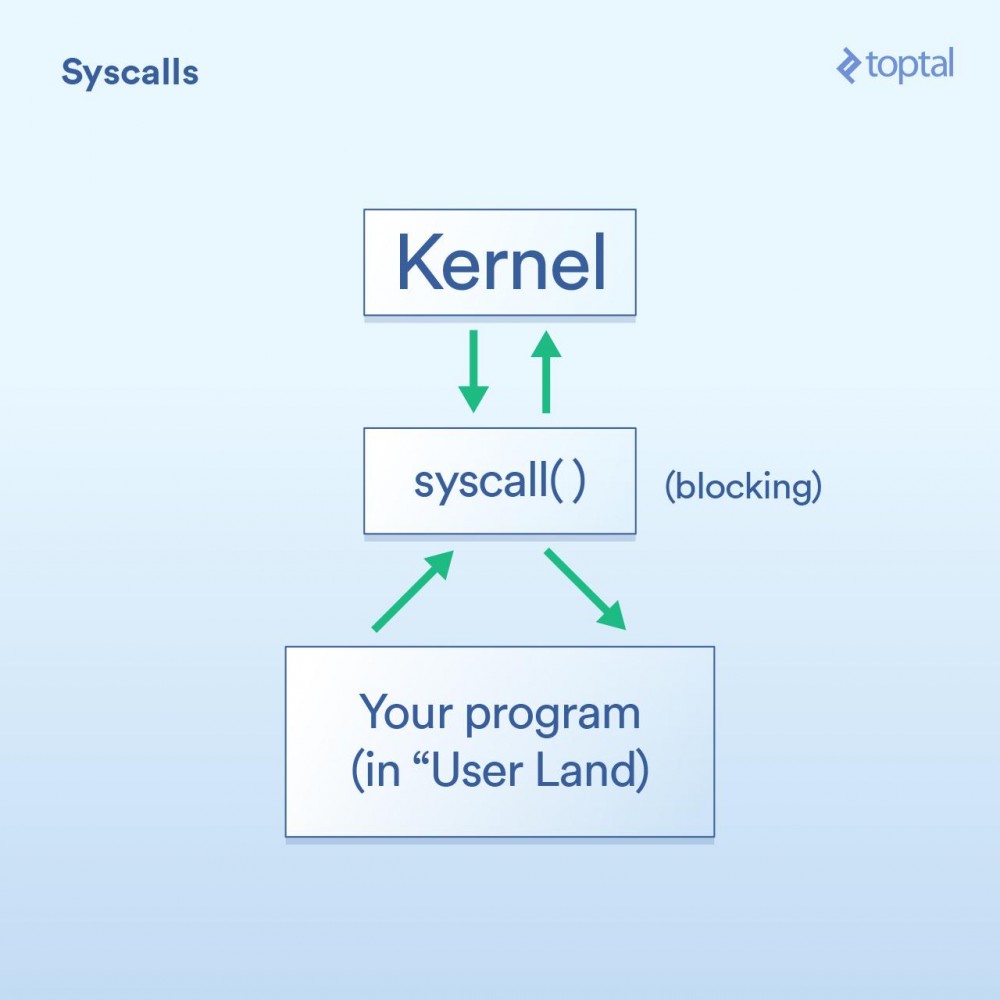
システムコール
まず、システム コールがあります。これは次のように記述できます:
- プログラム (いわゆる「ユーザーランド」内) では、オペレーティング システム カーネルが独自に I/O 操作を実行できるようにする必要があります。
- 「システム コール」(syscall) は、プログラムがカーネルに何かを行うように要求することを意味します。オペレーティング システムが異なれば、システム コールの実装の詳細は異なりますが、基本的な概念は同じです。これには、プログラムからカーネルに制御を移すいくつかの特定の命令が含まれます (関数呼び出しに似ていますが、このシナリオを処理するために設計された特別なソースがいくつかあります)。通常、システム コールはブロックされており、プログラムはカーネルがコードに戻るまで待機する必要があります。
- カーネルは、いわゆる物理デバイス (ハードディスク、ネットワーク カードなど) 上で低レベルの I/O 操作を実行し、システム コールに応答します。現実の世界では、カーネルはリクエストを完了するために、デバイスの準備ができるのを待つ、内部状態を更新するなど、多くのことを行う必要があるかもしれませんが、アプリケーション開発者としては心配する必要はありません。そのことについて。カーネルがどのように動作するかは次のとおりです。
ブロッキング コールと非ブロッキング コール
さて、上でシステム コールがブロックしていると言いましたが、一般的に言えば、これは正しいです。ただし、一部の呼び出しは「ノンブロッキング」として分類されます。これは、カーネルがリクエストを受信し、それをキューまたはバッファーのどこかに置き、実際の I/O 呼び出しを待たずにすぐに戻ることを意味します。したがって、リクエストをキューに入れるのに十分な非常に短い期間だけ「ブロック」されます。
説明に役立つ例 (Linux システム コール) をいくつか示します。 -read() はブロッキング コールです。これにファイル ハンドルとデータを保存するバッファを渡し、 read してからこの呼び出しを行います。データの準備ができたら返されます。このアプローチには優雅さとシンプルさという利点があることに注意してください。 -epoll_create() 、 epoll_ctl() 、および epoll_wait() これらの呼び出しでは、それぞれグループ追加からリスニング用のハンドルのセットを作成できます。 /ハンドルを削除し、アクティビティが存在するまでブロックします。これにより、スレッドを通じて一連の I/O 操作を効率的に制御できます。これらの機能が必要な場合にはこれは最適ですが、ご覧のとおり、使用するのは確かに非常に複雑です。
ここでのタイミングの違いの大きさを理解することが重要です。 CPU コアが最適化なしで 3GHz で実行される場合、1 秒あたり 30 億ループ (またはナノ秒あたり 3 ループ) が実行されます。ノンブロッキング システム コールは、完了するまでに 10 ナノ秒程度、つまり「比較的数ナノ秒」かかる場合があります。ネットワーク経由で情報を受信している呼び出しをブロックするには、さらに時間がかかる場合があります (たとえば、200 ミリ秒 (0.2 秒))。たとえば、ノンブロッキング呼び出しに 20 ナノ秒かかったとすると、ブロッキング呼び出しには 200,000,000 ナノ秒かかります。呼び出しをブロックする場合、プログラムは 1,000 万倍長く待機します。
カーネルは、ブロッキング I/O (「ネットワーク接続から読み取ってデータを提供する」) とノンブロッキング I/O (「これらのネットワーク接続に新しいデータがあるときに通知する」) の 2 つのメソッドを提供します。どのメカニズムが使用されているかに応じて、対応する呼び出しプロセスのブロック時間は明らかに異なります。
スケジュール
次の 3 番目の重要なことは、多数のスレッドまたはプロセスがブロックされ始めた場合にどうするかです。
私たちの目的では、スレッドとプロセスの間に大きな違いはありません。実際、実行関連の最も明らかな違いは、スレッドが同じメモリを共有するのに対し、各プロセスは独自のメモリ空間を持っているため、個別のプロセスが大量のメモリを占有することが多いことです。しかし、スケジューリングについて話すとき、最終的には、各イベントが利用可能な CPU コアで実行時間の一部を取得する必要があるイベント (スレッドとプロセスの両方) のリストに集約されます。 300 のスレッドが実行されていて、8 コアで実行している場合は、各コアを短時間実行してから次のスレッドに切り替えることによって、各スレッドが何かを取得できるように、タイムアウトを分散する必要があります。これは、CPU が実行中の 1 つのスレッド/プロセスから次のスレッド/プロセスに切り替えることを可能にする「コンテキスト スイッチング」によって実現されます。
これらのコンテキストの切り替えにはコストがかかり、ある程度の時間がかかります。高速な場合は、おそらく 100 ナノ秒未満ですが、実装の詳細、プロセッサの速度/アーキテクチャ、CPU キャッシュなどによっては、1000 ナノ秒以上かかることも珍しくありません。
スレッド (またはプロセス) が増えると、コンテキスト スイッチの数も増えます。数千のスレッドについて話していて、各切り替えに数百ナノ秒かかる場合、非常に遅くなります。
ただし、ノンブロッキング呼び出しは基本的にカーネルに「新しいデータがある場合、またはこれらの接続のいずれかでイベントが発生した場合にのみ呼び出してください」と指示します。これらのノンブロッキング呼び出しは、大きな I/O 負荷を効率的に処理し、コンテキストの切り替えを減らすように設計されています。
まだこの記事をここまで読んでいますか?なぜなら、ここからが楽しい部分だからです。いくつかの流暢な言語がこれらのツールをどのように使用しているかを見て、使いやすさとパフォーマンスの間のトレードオフについていくつかの結論を導き出しましょう...および他の興味深いコメント。
この投稿に示されている例は簡単ですが (コードの関連部分のみを示している不完全です)、データベース アクセス、外部キャッシュ システム (memcache などすべて)、O の I/Everything が必要であることに注意してください。最終的にいくつかの基礎となる I/O 操作が実行され、示されている例と同じ影響が生じます。同様に、I/O が「ブロッキング」と記述されている状況 (PHP、Java) では、HTTP リクエストと応答の読み書き自体が呼び出しをブロックしています。繰り返しになりますが、システム O とそれに付随する I/O にはさらに多くの I/O が隠蔽されています。パフォーマンスの問題を考慮する必要があります。
プロジェクトにプログラミング言語を選択する際には、考慮すべき要素が数多くあります。パフォーマンスのみを考慮する場合、考慮すべき要素はさらに多くなります。ただし、プログラムが主に I/O に依存していることが懸念される場合、および I/O パフォーマンスがプロジェクトにとって重要である場合は、これらのことを知っておく必要があります。 「シンプルに保つ」アプローチ: PHP。
1990 年代には、多くの人がコンバースの靴を履いて、Perl で CGI スクリプトを書いていました。その後、PHP が登場し、多くの人が PHP を好んで使用し、動的な Web ページを簡単に作成できるようになりました。
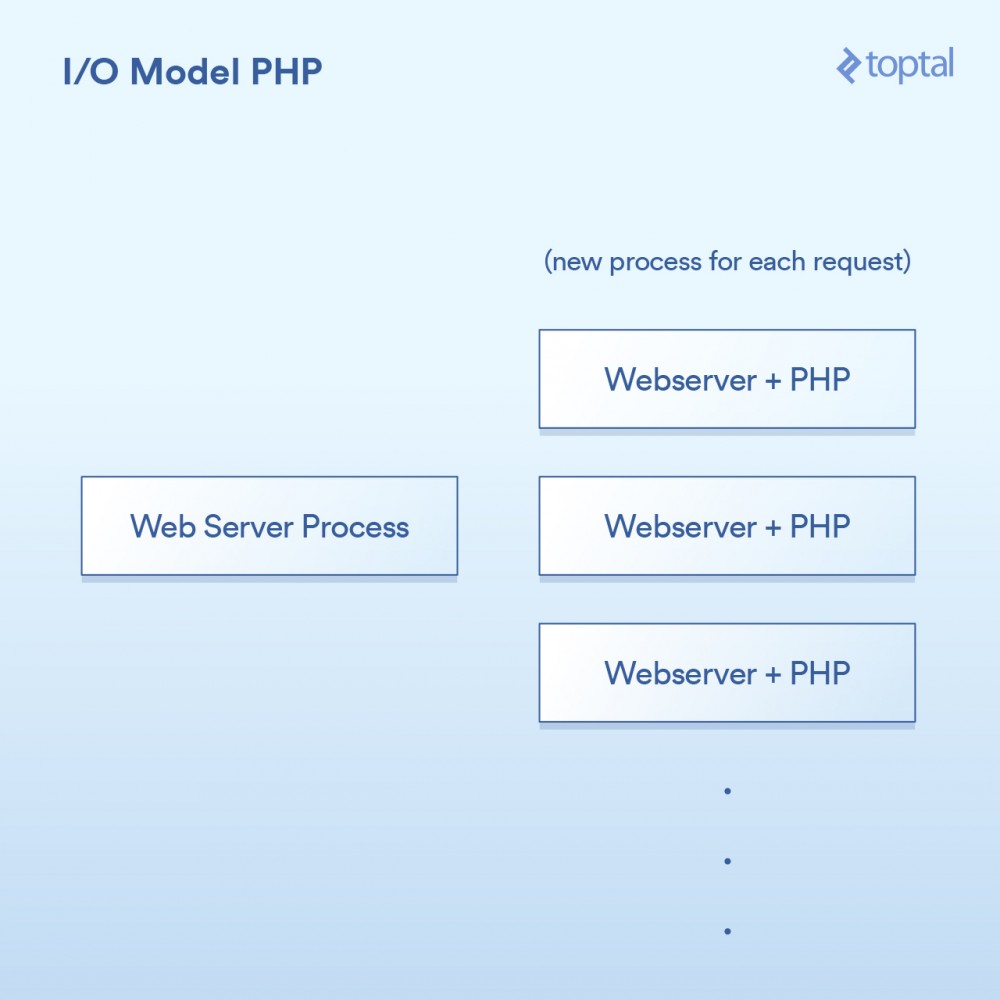
PHP で使用されるモデルは非常に単純です。いくつかのバリエーションがありますが、基本的に PHP サーバーは次のようになります:
HTTP リクエストはユーザーのブラウザから送信され、Apache Web サーバーにアクセスします。 Apache はリクエストごとに個別のプロセスを作成し、実行に必要な回数を最小限に抑えるためにいくつかの最適化を行ってプロセスを再利用します (プロセスの作成には比較的時間がかかります)。 Apache は PHP を呼び出し、ディスク上の対応する .php ファイルを実行するように指示します。 PHP コードが実行され、いくつかのブロッキング I/O 呼び出しが行われます。 PHP で file_get_contents() が呼び出される場合、舞台裏で read() システム コールがトリガーされ、結果が返されるのを待ちます。
もちろん、実際のコードはページに埋め込まれているだけであり、操作はブロックされています:
リーリー
システムとの統合方法については次のようになります:
相当简单:一个请求,一个进程。I/O是阻塞的。优点是什么呢?简单,可行。那缺点是什么呢?同时与20,000个客户端连接,你的服务器就挂了。由于内核提供的用于处理大容量I/O(epoll等)的工具没有被使用,所以这种方法不能很好地扩展。更糟糕的是,为每个请求运行一个单独的过程往往会使用大量的系统资源,尤其是内存,这通常是在这样的场景中遇到的第一件事情。
注意:Ruby使用的方法与PHP非常相似,在广泛而普遍的方式下,我们可以将其视为是相同的。
多线程的方式:Java
所以就在你买了你的第一个域名的时候,Java来了,并且在一个句子之后随便说一句“dot com”是很酷的。而Java具有语言内置的多线程(特别是在创建时),这一点非常棒。
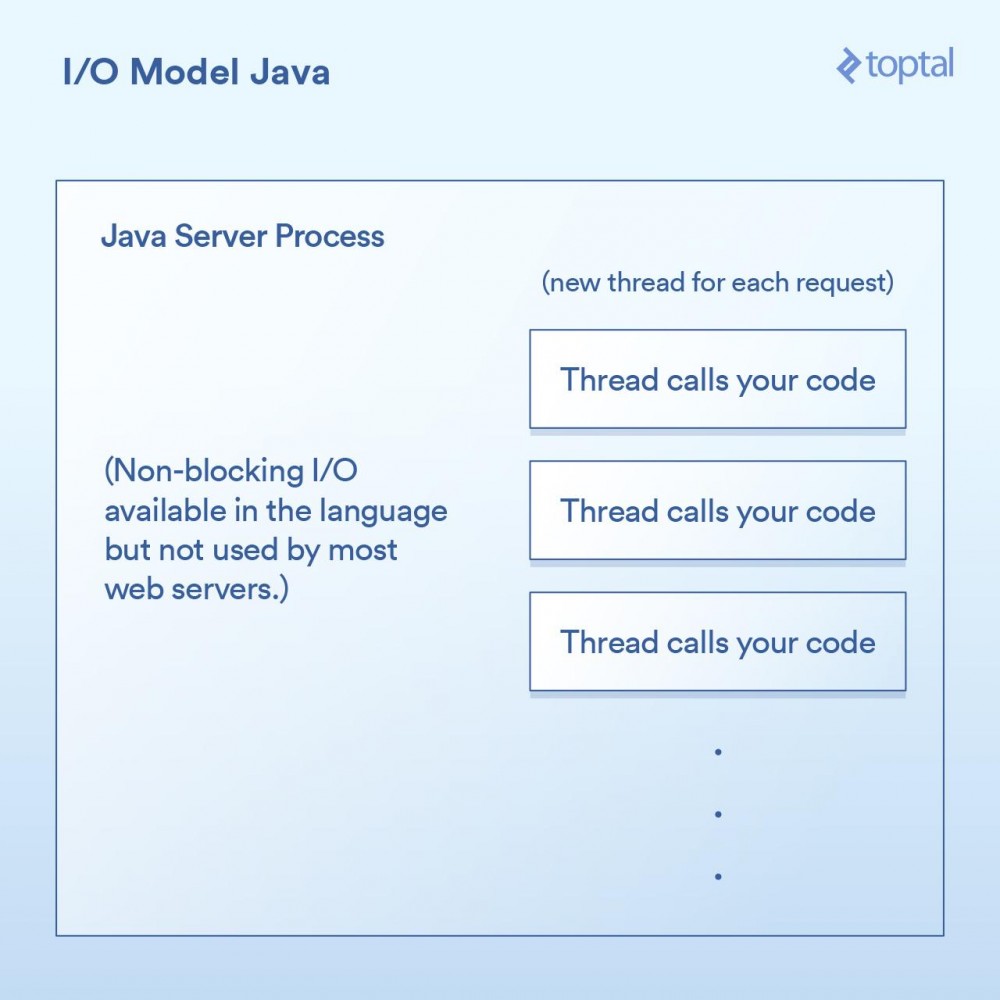
大多数Java网站服务器通过为每个进来的请求启动一个新的执行线程,然后在该线程中最终调用作为应用程序开发人员的你所编写的函数。
在Java的Servlet中执行I/O操作,往往看起来像是这样:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// 阻塞的文件I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// 阻塞的网络I/O
URLConnection urlConnection = (new URL("https://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// 更多阻塞的网络I/O
out.println("...");
}ログイン後にコピー
由于我们上面的doGet 方法对应于一个请求并且在自己的线程中运行,而不是每次请求都对应需要有自己专属内存的单独进程,所以我们会有一个单独的线程。这样会有一些不错的优点,例如可以在线程之间共享状态、共享缓存的数据等,因为它们可以相互访问各自的内存,但是它如何与调度进行交互的影响,仍然与前面PHP例子中所做的内容几乎一模一样。每个请求都会产生一个新的线程,而在这个线程中的各种I/O操作会一直阻塞,直到这个请求被完全处理为止。为了最小化创建和销毁它们的成本,线程会被汇集在一起,但是依然,有成千上万个连接就意味着成千上万个线程,这对于调度器是不利的。
一个重要的里程碑是,在Java 1.4 版本(和再次显著升级的1.7 版本)中,获得了执行非阻塞I/O调用的能力。大多数应用程序,网站和其他程序,并没有使用它,但至少它是可获得的。一些Java网站服务器尝试以各种方式利用这一点; 然而,绝大多数已经部署的Java应用程序仍然如上所述那样工作。
Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
作为一等公民的非阻塞I/O:Node
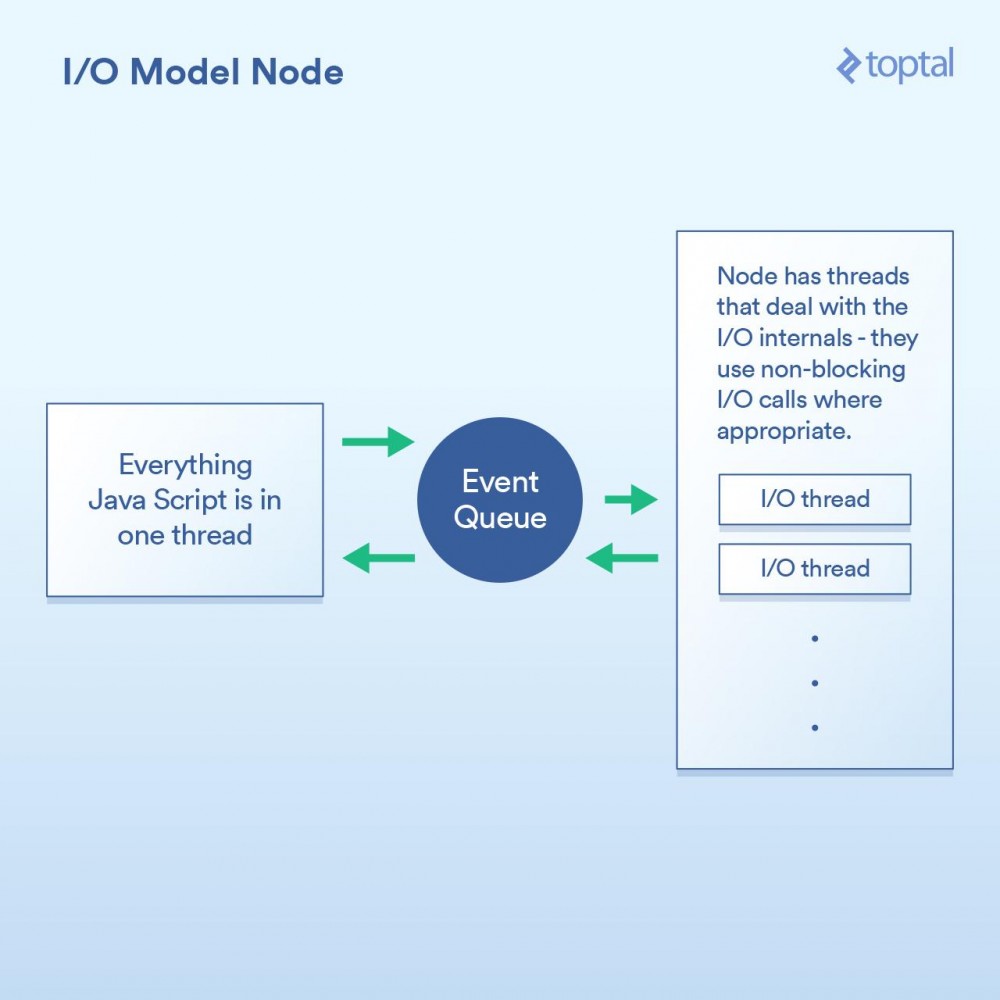
当谈到更好的I/O时,Node.js无疑是新宠。任何曾经对Node有过最简单了解的人都被告知它是“非阻塞”的,并且它能有效地处理I/O。在一般意义上,这是正确的。但魔鬼藏在细节中,当谈及性能时这个巫术的实现方式至关重要。
本质上,Node实现的范式不是基本上说“在这里编写代码来处理请求”,而是转变成“在这里写代码开始处理请求”。每次你都需要做一些涉及I/O的事情,发出请求或者提供一个当完成时Node会调用的回调函数。
在求中进行I/O操作的典型Node代码,如下所示:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});ログイン後にコピー
可以看到,这里有两个回调函数。第一个会在请求开始时被调用,而第二个会在文件数据可用时被调用。
这样做的基本上给了Node一个在这些回调函数之间有效地处理I/O的机会。一个更加相关的场景是在Node中进行数据库调用,但我不想再列出这个烦人的例子,因为它是完全一样的原则:启动数据库调用,并提供一个回调函数给Node,它使用非阻塞调用单独执行I/O操作,然后在你所要求的数据可用时调用回调函数。这种I/O调用队列,让Node来处理,然后获取回调函数的机制称为“事件循环”。它工作得非常好。
然而,这个模型中有一道关卡。在幕后,究其原因,更多是如何实现JavaScript V8 引擎(Chrome的JS引擎,用于Node)1,而不是其他任何事情。你所编写的JS代码全部都运行在一个线程中。思考一下。这意味着当使用有效的非阻塞技术执行I/O时,正在进行CPU绑定操作的JS可以在运行在单线程中,每个代码块阻塞下一个。 一个常见的例子是循环数据库记录,在输出到客户端前以某种方式处理它们。以下是一个例子,演示了它如何工作:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// 对每一行纪录进行处理
}
response.end(...); // 输出结果
})
};ログイン後にコピー
虽然Node确实可以有效地处理I/O,但上面的例子中的for 循环使用的是在你主线程中的CPU周期。这意味着,如果你有10,000个连接,该循环有可能会让你整个应用程序慢如蜗牛,具体取决于每次循环需要多长时间。每个请求必须分享在主线程中的一段时间,一次一个。
这个整体概念的前提是I/O操作是最慢的部分,因此最重要是有效地处理这些操作,即使意味着串行进行其他处理。这在某些情况下是正确的,但不是全都正确。
另一点是,虽然这只是一个意见,但是写一堆嵌套的回调可能会令人相当讨厌,有些人认为它使得代码明显无章可循。在Node代码的深处,看到嵌套四层、嵌套五层、甚至更多层级的嵌套并不罕见。
我们再次回到了权衡。如果你主要的性能问题在于I/O,那么Node模型能很好地工作。然而,它的阿喀琉斯之踵(
真正的非阻塞:Go
在进入Go这一章节之前,我应该披露我是一名Go粉丝。我已经在许多项目中使用Go,是其生产力优势的公开支持者,并且在使用时我在工作中看到了他们。
也就是说,我们来看看它是如何处理I/O的。Go语言的一个关键特性是它包含自己的调度器。并不是每个线程的执行对应于一个单一的OS线程,Go采用的是“goroutines”这一概念。Go运行时可以将一个goroutine分配给一个OS线程并使其执行,或者把它挂起而不与OS线程关联,这取决于goroutine做的是什么。来自Go的HTTP服务器的每个请求都在单独的Goroutine中处理。
此调度器工作的示意图,如下所示:
这是通过在Go运行时的各个点来实现的,通过将请求写入/读取/连接/等实现I/O调用,让当前的goroutine进入睡眠状态,当可采取进一步行动时用信息把goroutine重新唤醒。
实际上,除了回调机制内置到I/O调用的实现中并自动与调度器交互外,Go运行时做的事情与Node做的事情并没有太多不同。它也不受必须把所有的处理程序代码都运行在同一个线程中这一限制,Go将会根据其调度器的逻辑自动将Goroutine映射到其认为合适的OS线程上。最后代码类似这样:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 这里底层的网络调用是非阻塞的
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// 处理rows
// 每个请求在它自己的goroutine中
}
w.Write(...) // 输出响应结果,也是非阻塞的
}ログイン後にコピー
正如你在上面见到的,我们的基本代码结构像是更简单的方式,并且在背后实现了非阻塞I/O。
在大多数情况下,这最终是“两个世界中最好的”。非阻塞I/O用于全部重要的事情,但是你的代码看起来像是阻塞,因此往往更容易理解和维护。Go调度器和OS调度器之间的交互处理了剩下的部分。这不是完整的魔法,如果你建立的是一个大型的系统,那么花更多的时间去理解它工作原理的更多细节是值得的; 但与此同时,“开箱即用”的环境可以很好地工作和很好地进行扩展。
Go可能有它的缺点,但一般来说,它处理I/O的方式不在其中。
谎言,诅咒的谎言和基准
对这些各种模式的上下文切换进行准确的定时是很困难的。也可以说这对你来没有太大作用。所以取而代之,我会给出一些比较这些服务器环境的HTTP服务器性能的基准。请记住,整个端对端的HTTP请求/响应路径的性能与很多因素有关,而这里我放在一起所提供的数据只是一些样本,以便可以进行基本的比较。
对于这些环境中的每一个,我编写了适当的代码以随机字节读取一个64k大小的文件,运行一个SHA-256哈希N次(N在URL的查询字符串中指定,例如.../test.php?n=100 ),并以十六进制形式打印生成的散列。我选择了这个示例,是因为使用一些一致的I/O和一个受控的方式增加CPU使用率来运行相同的基准测试是一个非常简单的方式。
環境の使用状況については、これらのベンチマーク ポイントを参照してください。
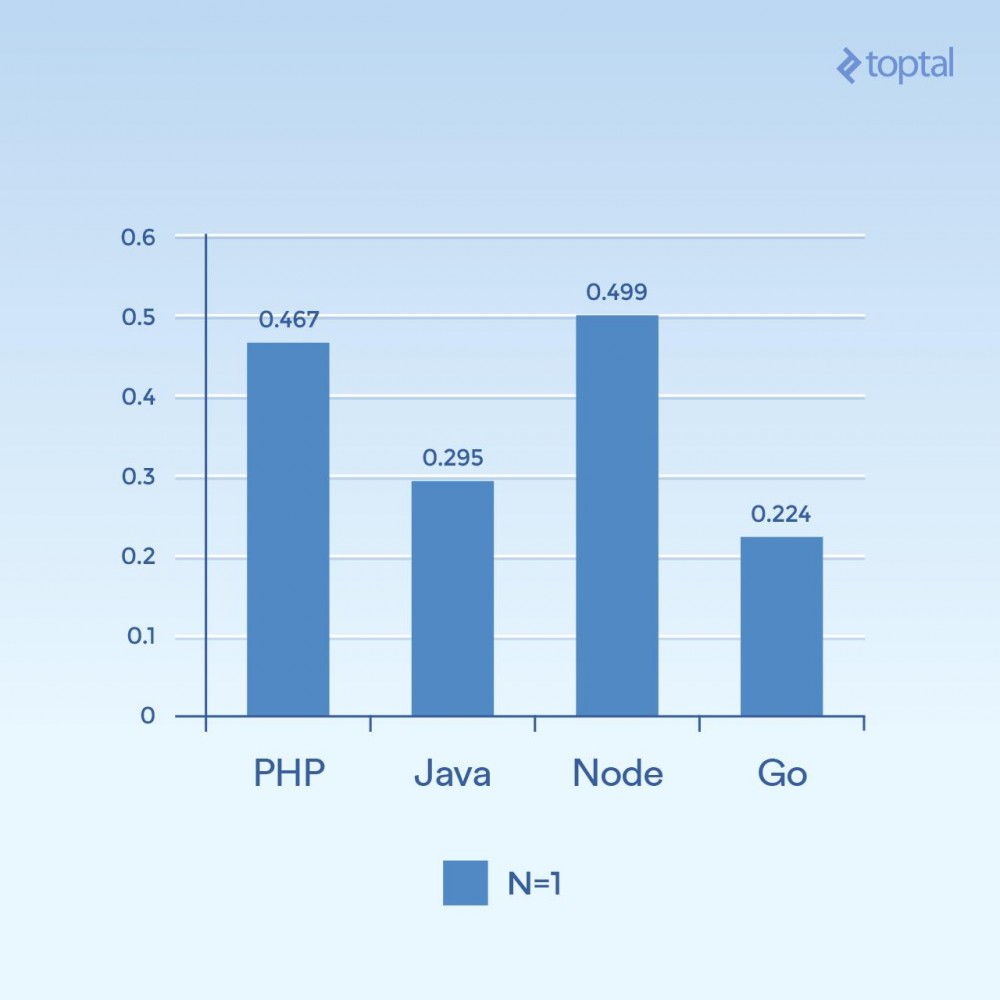
まず、同時実行性の低い例をいくつか見てみましょう。 2000 回の反復、300 の同時リクエストを実行し、リクエストごとに 1 回だけハッシュする (N = 1) と、次の結果が得られます:
Time は、すべての同時リクエストのうち、リクエストが完了するまでにかかる平均ミリ秒数です。低いほど良いです。
たった 1 つのグラフから結論を引き出すのは難しいですが、接続性や計算量などの側面に関連して、時間は言語自体の一般的な実行により関係していることがわかります。 I/O。 「スクリプト言語」とみなされる言語 (任意の入力、動的に解釈される言語) のパフォーマンスが最も遅いことに注意してください。
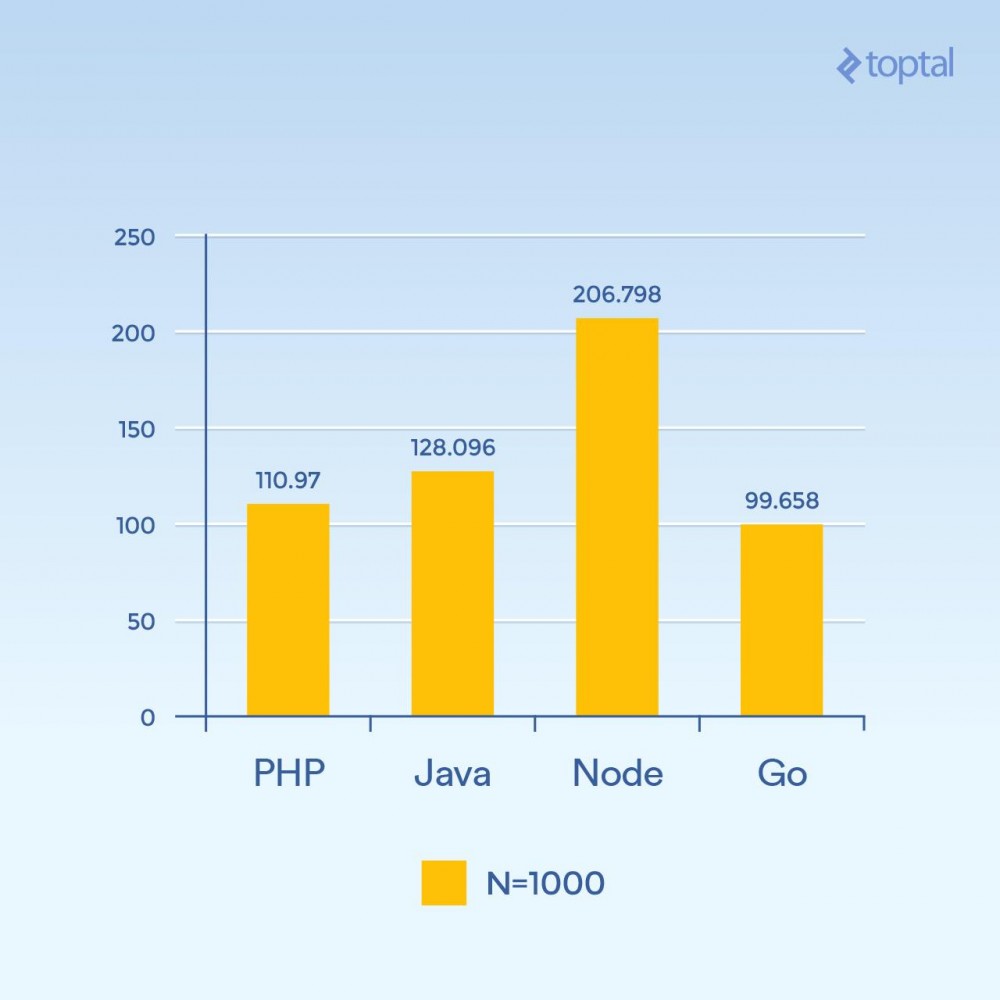
しかし、N を 1000 に増やしても、同時に 300 のリクエストがある場合はどうなるでしょうか。負荷は同じですが、ハッシュの反復が以前より 100 倍高くなります (CPU 負荷が大幅に増加します)。
Time は、すべての同時リクエストのうち、リクエストが完了するまでにかかる平均ミリ秒数です。低いほど良いです。
各リクエスト内の CPU を集中的に使用する操作が相互にブロックされたため、突然、ノードのパフォーマンスが大幅に低下しました。興味深いことに、このテストでは、PHP のパフォーマンスが (他の言語と比較して) はるかに優れており、Java を上回りました。 (SHA-256 実装が C で記述されている PHP では、今回は 1000 回のハッシュ反復を行うため、このループでの実行パスにより多くの時間がかかることに注意してください)。
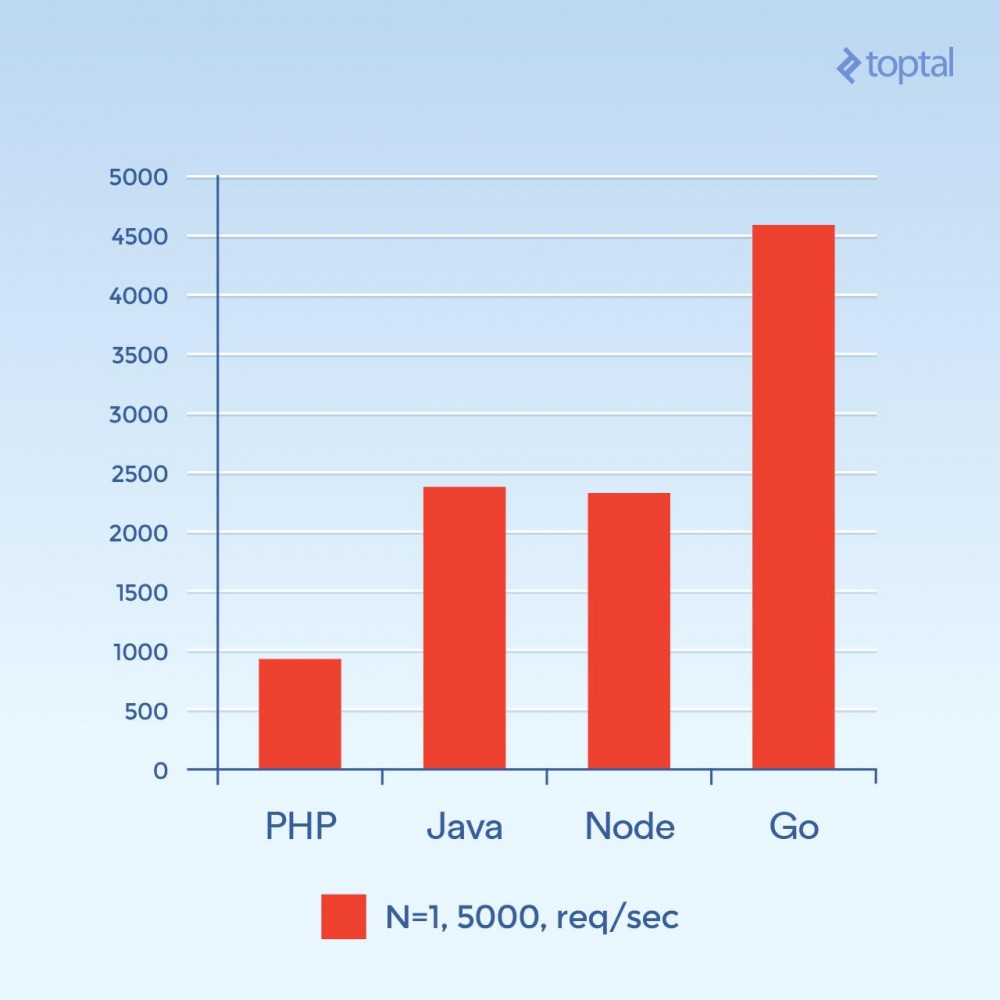
次に、5000 の同時接続 (N = 1)、またはそれに近い同時接続を試してみましょう。残念ながら、これらの環境のほとんどでは、障害率はそれほど大きくありません。このグラフでは、1 秒あたりのリクエストの合計数に焦点を当てます。 高ければ高いほど良い:
1 秒あたりのリクエストの合計数。高いほど良いです。
この写真は全く違って見えます。これは推測ですが、接続量が多い場合、接続ごとに新しいプロセスを生成することに関連するオーバーヘッドと、PHP Apache に関連する追加メモリが主な要因となり、PHP のパフォーマンスを制限しているようです。ここでは明らかに Go が勝者であり、次に Java と Node、最後に PHP が続きます。
###結論は###
要約すると、言語が進化するにつれて、大量の I/O を処理する大規模アプリケーションのソリューションも進化することは明らかです。
公平性を保つために、この記事の説明はしばらく脇に置きますが、PHP と Java には、Web アプリケーションに使用できるノンブロッキング I/O の実装があります。ただし、これらの方法は上記の方法ほど一般的ではないため、この方法を使用したサーバーの保守に伴う運用上のオーバーヘッドを考慮する必要があります。コードがこれらの環境に適した方法で構造化されている必要があることは言うまでもなく、「通常の」PHP または Java Web アプリケーションは通常、そのような環境では大幅な変更を受けません。
比較のために、パフォーマンスと使いやすさに影響を与えるいくつかの重要な要素だけを考慮すると、次のようになります。
###言語###
スレッドまたはプロセス
ノンブロッキングI/O|
###使いやすさ###
|
|
| PHP
###プロセス###
###いいえ###
|
|
| Java
###糸###
###利用可能###
|
| コールバックが必要です
|
| Node.js
###糸###
###はい###
|
| コールバックが必要です
|
###行く###
| スレッド (Goroutine)
###はい###
|
| コールバックは必要ありません
|
|
スレッドは同じメモリ空間を共有するのに対し、プロセスは共有しないため、一般にプロセスよりもメモリ効率が高くなります。ノンブロッキング I/O に関連する要因と組み合わせると、I/O の改善に関連する一般的なスタートアップにリストを移動すると、少なくとも上で検討した要因と同じ要因が確認できます。上記のゲームの中で勝者を選ばなければならないとしたら、それは間違いなく囲碁でしょう。 |
それでも、実際には、アプリケーションを構築するために選択する環境は、チームがその環境に精通していることと、達成できる全体的な生産性と密接に関係しています。したがって、すべてのチームにとって、Node または Go で Web アプリケーションやサービスの開発をいきなり始めるのは意味がありません。実際、開発者や社内チームに精通していることが、別の言語や別の環境を使用しない主な理由としてよく挙げられます。つまり、この15年で時代は大きく変わったのです。 |
上記の内容が、舞台裏で何が起こっているのかをより明確に理解し、アプリケーションの実際のスケーラビリティに対処する方法についてのアイデアを得るのに役立つことを願っています。楽しいインプット、楽しいアウトプット! |


















 7529
7529
 15
15

 CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
CentosとUbuntuの違い
Apr 14, 2025 pm 09:09 PM
 Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
Centosはメンテナンスを停止します2024
Apr 14, 2025 pm 08:39 PM
 Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
Centosをインストールする方法
Apr 14, 2025 pm 09:03 PM
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
 Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
Dockerデスクトップの使用方法
Apr 15, 2025 am 11:45 AM
 セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
セントスにハードディスクをマウントする方法
Apr 14, 2025 pm 08:15 PM
 Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
Centosがメンテナンスを停止した後の対処方法
Apr 14, 2025 pm 08:48 PM
