

HDFS データ アクセス効率を最適化: データのヒートとコールドを使用して管理します

テーマの紹介:
- HDFS最適化ストレージ機能の説明
- SSM システム アーキテクチャ設計
- SSM システム アプリケーション シナリオ分析
ビッグデータ技術関連技術の開発と普及に伴い、オープンソースの Hadoop をベースとしたプラットフォーム システムを利用する企業が増えていると同時に、従来の技術アーキテクチャから新しい技術アーキテクチャに移行するビジネスやアプリケーションも増えています。データプラットフォーム上のビッグデータテクノロジー。一般的な Hadoop ビッグ データ プラットフォームでは、ストレージ サービスのコアとして HDFS が使用されます。
ビッグ データの開発が始まった当初、主なアプリケーション シナリオはまだオフライン バッチ処理シナリオであり、ストレージの需要はスループットの追求でした。HDFS はそのようなシナリオ向けに設計されており、テクノロジーが進化し続けるにつれて、開発が進むにつれ、ストレージに対する新たな需要が高まるシナリオが増えており、HDFS も新たな課題に直面しています。これには主にいくつかの側面が含まれます:
1. データ量の問題ビジネスの成長と新しいアプリケーションへのアクセスに伴い、より多くのデータが HDFS に持ち込まれる一方で、ディープラーニング、人工知能、その他のテクノロジーの発展により、ユーザーは通常、データを保存したいと考えています。ディープラーニングの効果を高めるための長期間のデータ。データ量の急速な増加により、クラスターは継続的に拡張ニーズに直面することになり、結果としてストレージ コストが増加します。
2. 小さなファイルの問題ご存知のとおり、HDFS は大きなファイルのオフライン バッチ処理用に設計されており、小さなファイルの処理は従来の HDFS が得意とするシナリオではありません。 HDFS の小さいファイルの問題の根本原因は、ファイルのメタデータ情報が単一のネームノードのメモリ内に保持され、単一マシンのメモリ空間が常に制限されていることです。単一のネームノード クラスターが収容できるシステム ファイルの最大数は約 1 億 5,000 万であると推定されています。実際、HDFS プラットフォームは通常、複数の上位層コンピューティング フレームワークと複数のビジネス シナリオに対応するための基盤となるストレージ プラットフォームとして機能するため、ビジネスの観点からはファイルが小さいという問題は避けられません。現在、Namenode のシングルポイント スケーラビリティ問題を解決する HDFS-Federation などのソリューションがありますが、同時に運用保守管理に大きな困難をもたらします。
3. ホット データとコールド データの問題データ量が増加し蓄積し続けると、アクセス人気にも大きな差が見られるようになります。たとえば、プラットフォームは最新のデータを継続的に書き込みますが、通常、最近書き込まれたデータは、ずっと前に書き込まれたデータよりもはるかに頻繁にアクセスされます。データがホットかコールドかに関係なく同じストレージ戦略が使用される場合、クラスター リソースの無駄になります。 データのホットとコールドに基づいて HDFS ストレージ システムを最適化する方法は、解決する必要がある緊急の問題です。
2. 既存の HDFS 最適化テクノロジーHadoop の誕生から 10 年以上が経過し、この間、HDFS テクノロジー自体も最適化と進化を続けてきました。 HDFS には、上記の問題の一部をある程度解決できる既存のテクノロジーがいくつかあります。ここでは、HDFS 異種ストレージと HDFS イレイジャー コーディング テクノロジについて簡単に紹介します。
HDFS 異種ストレージ:Hadoop は、バージョン 2.6.0 以降、異種ストレージ機能をサポートします。 HDFS のデフォルトのストレージ戦略では、各データ ブロックの 3 つのコピーが使用され、それらが異なるノードのディスクに保存されることがわかっています。異種ストレージの役割は、サーバー上でさまざまなタイプのストレージ メディア (HDD ハードディスク、SSD、メモリなど) を使用して、より多くのストレージ戦略 (たとえば、コピーを 3 つ、1 つは SSD メディアに保存し、残りの 2 つは引き続き HDD ハードディスクに保存されます)。これにより、HDFS ストレージがより柔軟で効率的になり、さまざまなアプリケーション シナリオに対応できるようになります。
HDFS で事前定義されサポートされているさまざまなストレージには次のものがあります。
-
アーカイブ: コールド データの保存には、通常、テープなど、記憶密度が高く消費電力が低い記憶メディアが使用されます。
- DISK: ディスク メディア。これは HDFS でサポートされている最も古いストレージ メディアです。
-
RAM_DISK: データがメモリに書き込まれ、同時に別のコピーがストレージ メディアに (非同期で) 書き込まれます -
HDFS でサポートされるストレージ戦略は次のとおりです: 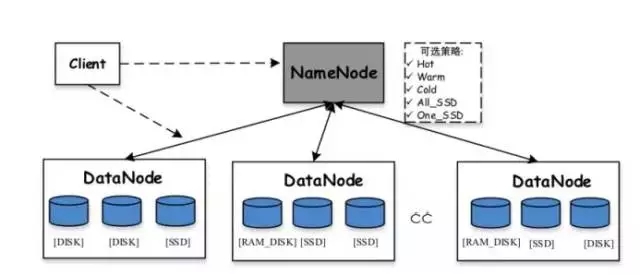
Lazy_persist: 1 つのコピーはメモリ RAM_DISK に保存され、残りのコピーはディスクに保存されます
-
ALL_SSD: すべてのコピーは SSD に保存されます -
One_SSD: 1 つのコピーが SSD に保存され、残りのコピーがディスクに保存されます
-
ホット: すべてのコピーはディスクに保存されます。これはデフォルトのストレージ ポリシーでもあります
-
ウォーム: 1 つのコピーがディスクに保存され、残りのコピーはアーカイブ ストレージに保存されます
-
コールド: すべてのコピーはアーカイブ ストレージに保存されます
一般に、HDFS 異種ストレージの価値は、データの人気に応じてさまざまな戦略を採用し、クラスターの全体的なリソース使用効率を向上させることにあります。頻繁にアクセスされるデータの場合は、アクセス性能の高いストレージ メディア (メモリまたは SSD) にそのすべてまたは一部を保存して読み取りおよび書き込みのパフォーマンスを向上させます。アクセスがほとんどないデータの場合は、アーカイブ ストレージ メディアに保存して読み取りおよび書き込みのパフォーマンスを低下させます。パフォーマンス、ストレージコスト。しかし、HDFS 異種ストレージの構成では、ユーザーがディレクトリに対応するポリシーを指定する必要があり、各ディレクトリ内のファイルのアクセス人気を事前に把握する必要があり、実際のビッグ データ プラットフォーム アプリケーションでは、これはさらに困難です。
HDFS 消去コーディング:従来の HDFS データは、データの信頼性を確保するために 3 コピー メカニズムを使用しています。つまり、保存されるデータ 1 TB ごとに、クラスターの各ノードで占有される実際のデータは 3 TB に達し、追加のオーバーヘッドが 200% になります。これにより、ノードのディスク ストレージとネットワーク伝送に大きな負荷がかかります。
Hadoop 3.0 では、HDFS ファイル ブロック レベルをサポートするために消去コーディングが導入され、基礎となるレイヤーではリードソロモン (k, m) アルゴリズムが使用されます。 RS は一般的に使用される消去符号化アルゴリズムです。行列演算を通じて、k ビットのデータに対して m ビットのチェック ディジットを生成できます。k と m の値に応じて、異なる程度のフォールト トレランスを実現できます。比較的柔軟な方法、イレージコーディングアルゴリズム。
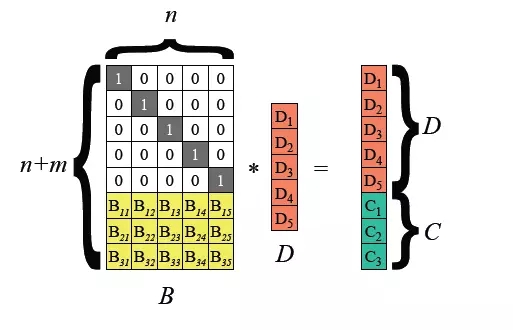
一般的なアルゴリズムは RS(3,2)、RS(6,3)、RS(10,4) で、k ファイル ブロックと m チェック ブロックがグループを形成し、このグループでは任意の m が許容されます データの損失ブロック。
HDFS イレイジャー コーディング テクノロジは、データ ストレージの冗長性を削減できます。RS(3,2) を例にとると、そのデータ冗長性は 67% であり、Hadoop のデフォルトの 200% と比較して大幅に削減されます。ただし、イレイジャー コーディング テクノロジでは、データ ストレージとデータ回復のための計算に CPU を消費する必要があります。これは実際には、時間をスペースと交換する選択です。 そのため、より適切なシナリオは、コールド データのストレージです。コールドデータに保存されたデータは、一度書き込まれた後は長期間アクセスされないことが多く、この場合、消去符号化技術を利用することでコピー数を削減できます。
3. ビッグ データ ストレージの最適化: SSM前に紹介した HDFS 異種ストレージやイレイジャー コーディング テクノロジに関係なく、ユーザーは特定のデータのストレージ動作を指定する必要があるという前提があります。つまり、ユーザーはどのデータがホット データでどのデータがコールド データであるかを知る必要があります。 。では、ストレージを自動的に最適化する方法はあるのでしょうか?
答えは「はい」です。ここで紹介する SSM (Smart Storage Management) システムは、基礎となるストレージ (通常は HDFS) からメタデータ情報を取得し、さまざまな熱レベルを対象としたデータの読み取りおよび書き込みアクセス情報分析を通じてデータの熱ステータスを取得します。一連の事前に確立されたルールに基づいて、対応するストレージ最適化戦略が採用され、ストレージ システム全体の効率が向上します。 SSM は Intel が主導するオープンソース プロジェクトであり、China Mobile もその研究開発に参加しています。 プロジェクトは Github: https://github.com/Intel-bigdata/SSM から入手できます。
SSM ポジショニングは、全体としてサーバー、エージェント、クライアントのアーキテクチャを採用したストレージ周辺機器の最適化システムです。サーバーは SSM の全体的なロジックの実装を担当し、エージェントはストレージ クラスター上でさまざまな操作を実行するために使用されます。データ アクセス インターフェイス (通常はネイティブ HDFS インターフェイスが含まれます)。
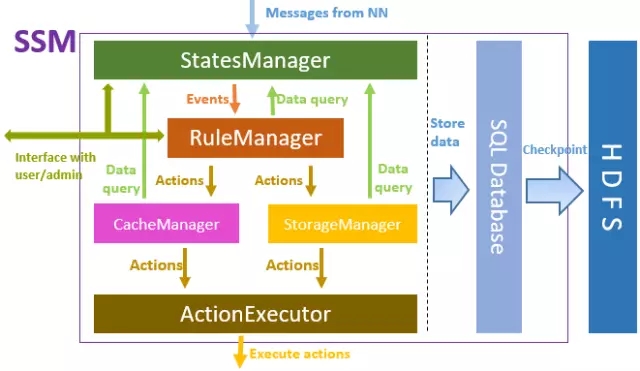
SSM-Server の主要なフレームワークは上の図に示されており、上から下に、StatesManager は HDFS クラスターと対話して、HDFS メタデータ情報を取得し、各ファイルのアクセス人気情報を維持します。 StatesManager 内の情報はリレーショナル データベースに保存されます。 TiDB は、SSM の基盤となるストレージ データベースとして使用されます。 RuleManager はルール関連情報を維持および管理します。ユーザーはフロントエンド インターフェイスを通じて SSM の一連のストレージ ルールを定義し、RuleManager はルールの解析と実行を担当します。 CacheManager/StorageManager は、人気とルールに基づいて特定のアクション タスクを生成します。 ActionExecutor は特定のアクション タスクを担当し、タスクをエージェントに割り当て、エージェント ノード上でタスクを実行します。

SSM サーバーの内部ロジックの実装はルールの定義に依存しているため、管理者はフロントエンド Web ページを通じて SSM システムの一連のルールを策定する必要があります。ルールはいくつかの部分で構成されます:
- 操作オブジェクトは通常、特定の条件を満たすファイルを指します。
- トリガーは、毎日スケジュールされたトリガーなど、ルールがトリガーされる時点を指します。
- 実行条件。一定期間内のファイル アクセス数要件など、人気に基づいて一連の条件を定義します。
- 操作を実行し、実行条件を満たすデータに対して関連する操作を実行します。通常はストレージ ポリシーなどを指定します。
実際のルールの例:
file.path は「/foo/*」と一致します: accessCount(10min) >= 3 | one-ssd
このルールは、/foo ディレクトリ内のファイルが 10 分以内に 3 回以上アクセスされた場合、One-SSD ストレージ戦略が採用されることを意味します。つまり、データのコピーが 1 つ保存されます。 SSD に保存され、残りの 2 A コピーは通常のディスクに保存されます。
4. SSM アプリケーションのシナリオSSM は、さまざまなストレージ戦略を使用して、データのホットとコールドを最適化できます。次に、典型的なアプリケーション シナリオをいくつか示します:
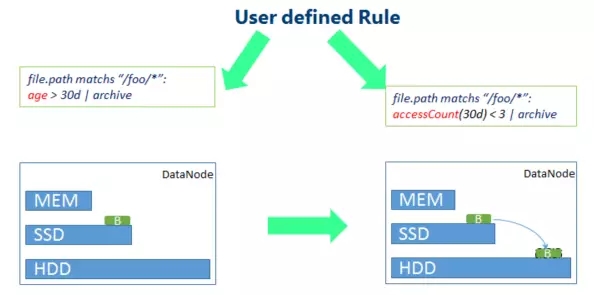
最も一般的なシナリオはコールド データの場合で、上の図に示すように、関連するルールを定義し、長期間アクセスされていないデータに対して低コストのストレージを使用します。たとえば、元のデータ ブロックは SSD ストレージから HDD ストレージに劣化します。
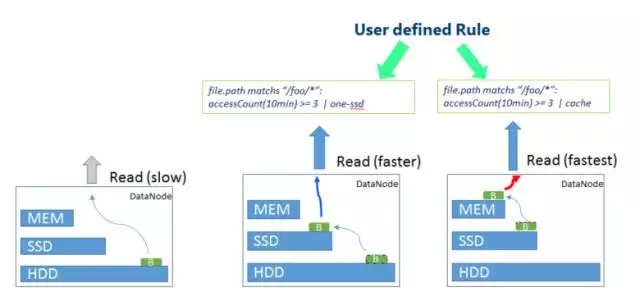
同様に、ホットスポット データの場合も、さまざまなルールに従って高速ストレージ戦略を採用できます。上の図に示すように、短時間でより多くのホットスポット データにアクセスすると、HDD からのストレージ コストが増加します。SSD ストレージの場合、より多くのホットデータはメモリストレージ戦略を使用します。
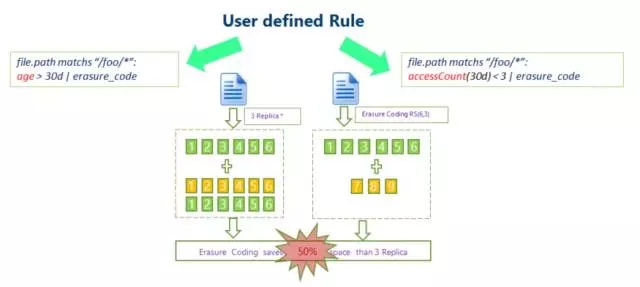
コールド データ シナリオの場合、SSM はイレイジャー コーディングの最適化も使用できます。対応するルールを定義することで、アクセス数の少ないコールド データに対してイレイジャー コード操作が実行され、データ コピーの冗長性が削減されます。

また、SSM には小さなファイルに対応する最適化メソッドがあることにも言及する価値がありますが、この機能はまだ開発段階にあります。一般的なロジックは、SSM が HDFS 上の一連の小さなファイルを大きなファイルにマージするというもので、同時に、元の小さなファイルとマージされた大きなファイルの間のマッピング関係、および大きなファイル内の各小さなファイルの場所は次のようになります。 SSM のメタデータに記録されるオフセット。ユーザが小さいファイルにアクセスする必要がある場合、SSM メタデータ内の小さいファイル マッピング情報に基づいて、SSM 固有のクライアント (SmartClient) を通じてマージされたファイルから元の小さいファイルが取得されます。
最後に、SSM はオープン ソース プロジェクトであり、現在も非常に急速な反復進化の過程にあります。興味のある友人はプロジェクトの開発に貢献することを歓迎します。
Q&AQ1: HDFS を自分で構築するにはどの規模から始めるべきですか?
A1: HDFS は擬似分散モードをサポートしており、ノードが 1 つしかない場合でも HDFS システムを構築できます。 HDFS の分散アーキテクチャをよりよく体験して理解したい場合は、3 ~ 5 ノードの環境を構築することをお勧めします。
Q2: Su Yan さんは各省の実際のビッグデータ プラットフォームで SSM を使用したことがありますか?
A2: まだです。このプロジェクトはまだ急速に開発中です。テストが安定したら、徐々に本番環境で使用される予定です。
Q3: HDFS と Spark の違いは何ですか?長所と短所は何ですか?
A3: HDFS と Spark は同じレベルのテクノロジーではありません。HDFS はストレージ システムであるのに対し、Spark はコンピューティング エンジンです。私たちがよく Spark と比較するのは、HDFS ストレージ システムではなく、Hadoop の Mapreduce コンピューティング フレームワークです。実際のプロジェクト構築では、HDFS と Spark は連携関係にあり、HDFS は基盤となるストレージに使用され、Spark は上位レベルのコンピューティングに使用されます。
以上がHDFS データ アクセス効率を最適化: データのヒートとコールドを使用して管理しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
エラーの原因とソリューションPECLを使用してDocker環境に拡張機能をインストールする場合、Docker環境を使用するときに、いくつかの頭痛に遭遇します...
 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...

 APSChedulerタイミングタスクをMACOSのサービスとして構成する方法は?
Apr 01, 2025 pm 06:09 PM
APSChedulerタイミングタスクをMACOSのサービスとして構成する方法は?
Apr 01, 2025 pm 06:09 PM
nginと同様に、APSChedulerタイミングタスクをサービスとして構成する場合、APSChedulerタイミングタスクをMACOSプラットフォームでサービスとして構成します...
 マルチスレッドをC言語で実装する4つの方法
Apr 03, 2025 pm 03:00 PM
マルチスレッドをC言語で実装する4つの方法
Apr 03, 2025 pm 03:00 PM
言語のマルチスレッドは、プログラムの効率を大幅に改善できます。 C言語でマルチスレッドを実装する4つの主な方法があります。独立したプロセスを作成します。独立して実行される複数のプロセスを作成します。各プロセスには独自のメモリスペースがあります。擬似マルチスレッド:同じメモリ空間を共有して交互に実行するプロセスで複数の実行ストリームを作成します。マルチスレッドライブラリ:pthreadsなどのマルチスレッドライブラリを使用して、スレッドを作成および管理し、リッチスレッド操作機能を提供します。 Coroutine:タスクを小さなサブタスクに分割し、順番に実行する軽量のマルチスレッド実装。
 PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
PythonインタープリターはLinuxシステムで削除できますか?
Apr 02, 2025 am 07:00 AM
Linux Systemsに付属するPythonインタープリターを削除する問題に関して、多くのLinuxディストリビューションは、インストール時にPythonインタープリターをプリインストールし、パッケージマネージャーを使用しません...
 web.xmlを開く方法
Apr 03, 2025 am 06:51 AM
web.xmlを開く方法
Apr 03, 2025 am 06:51 AM
web.xmlファイルを開くには、次の方法を使用できます。テキストエディター(メモ帳やテキストエディットなど)を使用して、統合開発環境(EclipseやNetBeansなど)を使用してコマンドを編集できます(Windows:Notepad web.xml; Mac/Linux:Open -A Textedit Web.xml)
