

SD コミュニティの I2V アダプター: 設定不要、プラグアンドプレイ、Tusheng ビデオ プラグインと完全に互換性あり

画像からビデオへの生成 (I2V) タスクは、静止画像を動的なビデオに変換することを目的とした、コンピューター ビジョンの分野における課題です。このタスクの難しさは、画像コンテンツの信頼性と視覚的な一貫性を維持しながら、単一の画像から時間次元で動的な情報を抽出して生成することです。既存の I2V 手法では、多くの場合、この目標を達成するために複雑なモデル アーキテクチャと大量のトレーニング データが必要になります。
最近、Kuaishou が主導した新しい研究成果「I2V アダプター: ビデオ拡散モデルのための汎用画像対ビデオ アダプター」が発表されました。この研究では、革新的な画像からビデオへの変換方法を導入し、軽量のアダプター モジュールである I2V アダプターを提案します。このアダプター モジュールは、既存のテキストからビデオへの生成 (T2V) モデルの元の構造と事前トレーニングされたパラメーターを変更することなく、静止画像を動的なビデオに変換できます。この方法は、画像からビデオへの変換の分野で幅広い応用の可能性があり、ビデオ作成、メディアコミュニケーション、その他の分野にさらなる可能性をもたらす可能性があります。研究成果の公開は、画像・映像技術の発展を促進する上で非常に意義があり、関連分野の研究者にとって有効なツールや手法を提供します。

- #論文アドレス: https://arxiv.org/pdf/2312.16693 .pdf
- プロジェクトのホームページ: https://i2v-adapter.github.io/index.html
- コードアドレス: https://github.com/I2V-Adapter/I2V-Adapter-repo
既存のメソッドとの比較 他つまり、I2V アダプターはトレーニング可能なパラメーターの点で大幅な改善を行い、パラメーターの最小数は 22M に達しましたが、これは主流のソリューションである Stable Video Diffusion のわずか 1% にすぎません。同時に、このアダプターは、Stable Diffusion コミュニティによって開発されたカスタマイズされた T2I モデル (DreamBooth、Lora など) および制御ツール (ControlNet など) とも互換性があります。研究者らは実験を通じて、高品質のビデオコンテンツの生成における I2V アダプターの有効性を証明し、I2V 分野でクリエイティブなアプリケーションの新たな可能性を切り開きました。

安定拡散による時間モデリング
画像生成と比較して、ビデオ生成は、ビデオ フレーム間の時間的一貫性をモデル化するという独特の課題に直面しています。現在の手法のほとんどは、ビデオ内のタイミング情報をモデル化するタイミング モジュールを導入することにより、安定拡散や SDXL などの事前トレーニングされた T2I モデルに基づいています。もともとカスタマイズされた T2V タスク用に設計されたモデルである AnimateDiff からインスピレーションを受けており、T2I モデルから分離されたタイミング モジュールを導入することでタイミング情報をモデル化し、スムーズなビデオを生成する元の T2I モデルの機能を保持します。したがって、研究者らは、事前トレーニングされた時間モジュールは普遍的な時間表現と見なすことができ、微調整することなく、I2V 生成などの他のビデオ生成シナリオに適用できると考えています。したがって、研究者らは事前トレーニングされた AnimateDiff タイミング モジュールを直接使用し、そのパラメーターを固定したままにしました。
アテンション レイヤー用アダプター
I2V タスクのもう 1 つの課題は、入力画像の ID 情報を維持することです。 。現在の主な解決策は 2 つあります。1 つは、事前トレーニングされた画像エンコーダーを使用して入力画像をエンコードし、クロスアテンション メカニズムを通じてエンコードされた特徴をモデルに注入してノイズ除去プロセスをガイドするもので、もう 1 つは画像をチャネル次元のノイズを含む入力と連結され、後続のネットワークに一緒に供給されます。ただし、前者の方法では、画像エンコーダーが基礎となる情報をキャプチャすることが難しいため、生成されたビデオ ID が変更される可能性がありますが、後者の方法では、多くの場合、T2I モデルの構造とパラメーターの変更が必要となるため、トレーニング コストが高くなり、パフォーマンスが低下します。互換性。上記の問題を解決するために、研究者たちは I2V アダプターを提案しました。具体的には、研究者は入力画像とノイズを含む入力を並行してネットワークに入力します。モデルの空間ブロックでは、すべてのフレームが最初のフレーム情報をさらにクエリします。つまり、キーと値の特徴はノイズのない最初のフレームから取得されます。 、そして出力結果は元のモデルのセルフアテンションに追加されます。このモジュールの出力マッピング行列はゼロで初期化され、出力マッピング行列とクエリ マッピング行列のみがトレーニングされます。入力画像の意味論的情報に対するモデルの理解をさらに強化するために、研究者らは、画像の意味論的特徴を注入するための事前トレーニング済みコンテンツ アダプター (この記事では IP アダプター [8] を使用します) を導入しました。
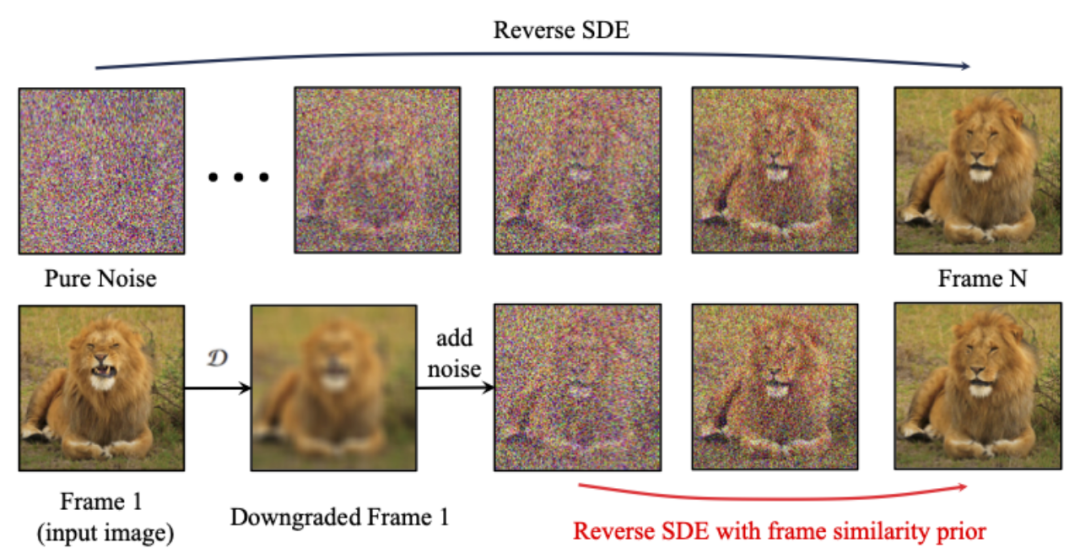
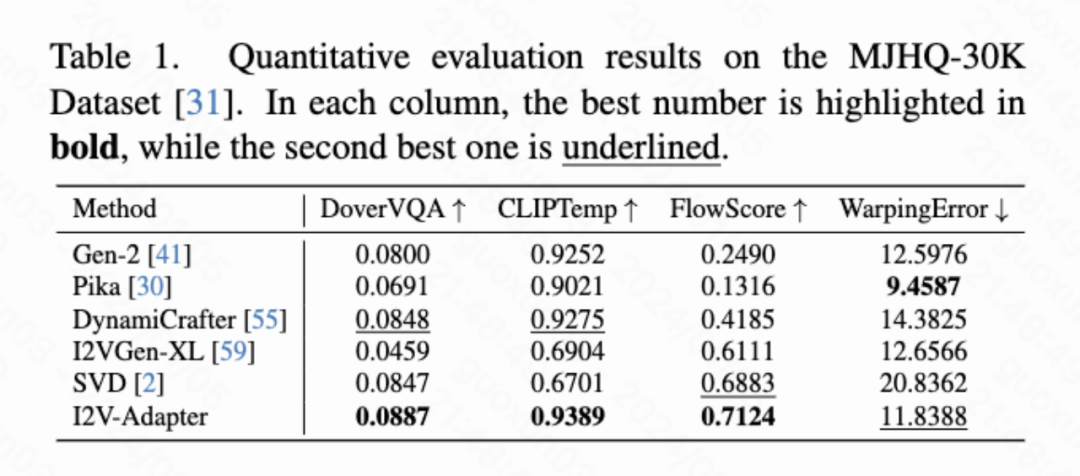
フレーム類似度優先順位 生成された結果の安定性をさらに高めるために、研究者は、は、フレーム間の事前類似性を使用して、生成されたビデオの安定性と動きの強さのバランスを取ることを提案しました。重要な前提は、次の図に示すように、比較的低いガウス ノイズ レベルでは、ノイズのある最初のフレームとノイズのある後続のフレームが十分に近いということです。 したがって、研究者は、すべてのフレームが同様の構造を持ち、一定量のガウス ノイズを追加すると区別できなくなると想定し、したがって、ノイズを加えた入力画像を後続のフレームのアプリオリ入力として使用できると考えています。高周波情報による誤解を避けるために、研究者らはガウスぼかし演算子とランダムマスク混合も使用しました。具体的には、操作は次のようになります。 #実験結果 この記事では、DoverVQA (美的スコア)、CLIPTemp (最初のフレームの一貫性)、FlowScore (動作範囲)、および WarppingError (動作エラー) の 4 つの定量的指標を計算しました。生成されたビデオ。表 1 は、I2V アダプターが最高の美的スコアを獲得し、最初のフレームの一貫性の点ですべての比較スキームを上回っていることを示しています。さらに、I2V アダプターによって生成されたビデオは、最大の動き振幅と比較的低い動き誤差を持ち、このモデルが時間的な動きの精度を維持しながら、よりダイナミックなビデオを生成できることを示しています。 #定性的結果
##ControlNet あり (左が入力、右が出力): ## この文書では、画像からビデオへの生成タスク用のプラグアンドプレイの軽量モジュールである I2V アダプターを提案します。この方法では、元の T2V モデルの空間ブロックとモーション ブロックの構造とパラメーターを固定し、ノイズのない最初のフレームとノイズのある後続のフレームを並列に入力し、アテンション メカニズムを通じてすべてのフレームがノイズのない最初のフレームと相互作用できるようにします。したがって、時間的に一貫性があり、最初のフレームと一貫性のあるビデオが生成されます。研究者は、定量的および定性的な実験を通じて、I2V タスクにおけるこの方法の有効性を実証しました。さらに、その分離設計により、ソリューションを DreamBooth、Lora、ControlNet などのモジュールと直接組み合わせることができ、ソリューションの互換性を証明し、カスタマイズされた制御可能な画像からビデオの生成に関する研究を促進します。 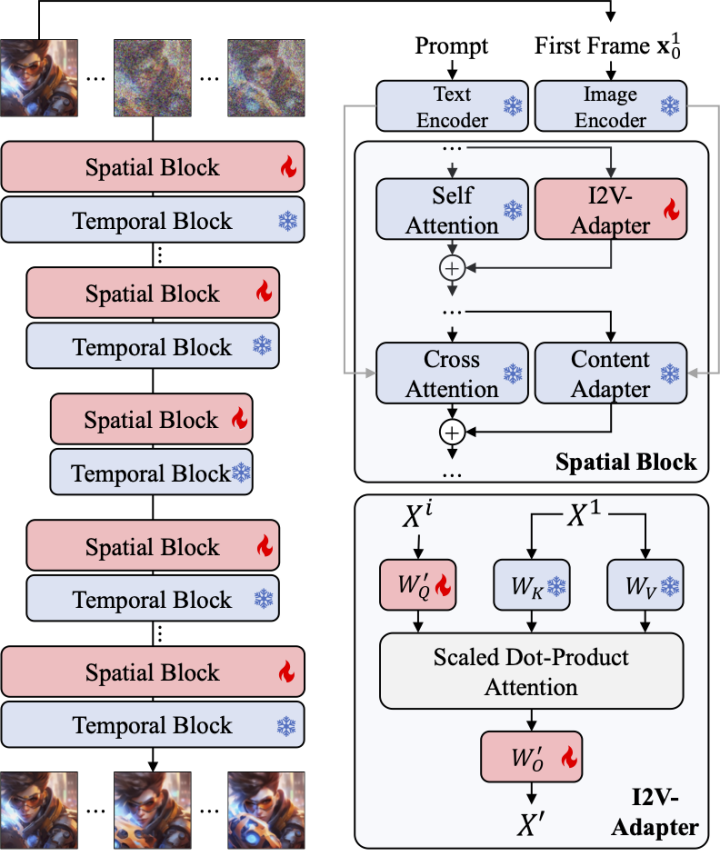


 # #パーソナライズされた T2I あり (左が入力、右が出力):
# #パーソナライズされた T2I あり (左が入力、右が出力): 
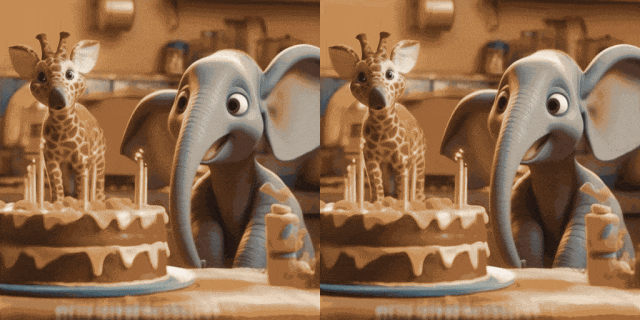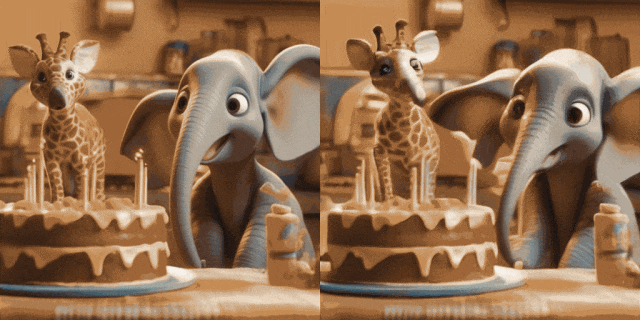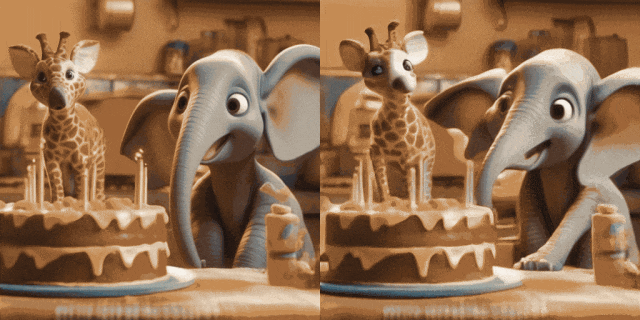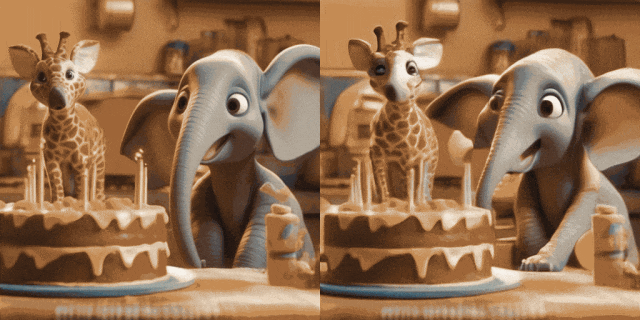




概要
以上がSD コミュニティの I2V アダプター: 設定不要、プラグアンドプレイ、Tusheng ビデオ プラグインと完全に互換性ありの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
動画ファイルはブラウザのキャッシュのどこに保存されますか?
Feb 19, 2024 pm 05:09 PM
ブラウザはビデオをどのフォルダにキャッシュしますか? 私たちは毎日インターネット ブラウザを使用するときに、YouTube でミュージック ビデオを視聴したり、Netflix で映画を視聴したりするなど、さまざまなオンライン ビデオを視聴することがよくあります。これらのビデオは読み込みプロセス中にブラウザによってキャッシュされるため、将来再び再生するときにすぐに読み込むことができます。そこで問題は、これらのキャッシュされたビデオが実際にどのフォルダーに保存されるのかということです。ブラウザーが異なれば、キャッシュされたビデオ フォルダーは異なる場所に保存されます。以下に、いくつかの一般的なブラウザとそのブラウザを紹介します。
 他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
他人の動画をDouyinに投稿することは侵害になりますか?侵害せずにビデオを編集するにはどうすればよいですか?
Mar 21, 2024 pm 05:57 PM
ショートビデオプラットフォームの台頭により、Douyinはみんなの日常生活に欠かせないものになりました。 TikTokでは世界中の面白い動画を見ることができます。他人のビデオを投稿することを好む人もいますが、「Douyin は他人のビデオを投稿することを侵害しているのでしょうか?」という疑問が生じます。この記事では、この問題について説明し、著作権を侵害せずに動画を編集する方法と、著作権侵害の問題を回避する方法について説明します。 1.Douyin による他人の動画の投稿は侵害ですか?私の国の著作権法の規定によれば、著作権者の著作物を著作権者の許可なく無断で使用することは侵害となります。したがって、オリジナルの作者または著作権所有者の許可なしに他人のビデオをDouyinに投稿することは侵害となります。 2. 著作権を侵害せずにビデオを編集するにはどうすればよいですか? 1. パブリックドメインまたはライセンスされたコンテンツの使用: パブリック
 Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオの透かしを削除する方法
Feb 23, 2024 pm 07:22 PM
Wink でビデオからウォーターマークを削除するにはどうすればよいですか? winkAPP にはビデオからウォーターマークを削除するツールがありますが、ほとんどの友達は wink でビデオからウォーターマークを削除する方法を知りません。次は Wink でビデオからウォーターマークを削除する方法の画像です。編集者が持参したテキストチュートリアルですので、興味のある方はぜひ見に来てください! Wink でビデオ透かしを削除する方法 1. まず、Wink APP を開き、ホームページ領域で [透かしを削除] 機能を選択します; 2. 次に、アルバムで透かしを削除したいビデオを選択します; 3. 次に、ビデオを選択してクリックしますビデオ編集後、右上隅にある [√]; 4. 最後に、下図のように [ワンクリック印刷] をクリックし、[処理] をクリックします。
 Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
Douyin に動画を投稿して収益を得るにはどうすればよいですか?初心者はどうやってDouyinでお金を稼ぐことができますか?
Mar 21, 2024 pm 08:17 PM
全国的なショートビデオプラットフォームであるDouyinは、自由な時間にさまざまな興味深く斬新なショートビデオを楽しむことができるだけでなく、自分自身を示し、自分の価値観を実現するステージも提供します。では、Douyin に動画を投稿してお金を稼ぐにはどうすればよいでしょうか?この記事ではこの質問に詳しく答え、TikTokでより多くのお金を稼ぐのに役立ちます。 1.Douyin に動画を投稿してお金を稼ぐにはどうすればよいですか?動画を投稿し、Douyin で一定の再生回数を獲得すると、広告共有プランに参加できるようになります。この収入方法はDouyinユーザーにとって最も馴染みのある方法の1つであり、多くのクリエイターにとって主な収入源でもあります。 Douyin は、アカウントの重み、動画コンテンツ、視聴者のフィードバックなどのさまざまな要素に基づいて、広告共有の機会を提供するかどうかを決定します。 TikTok プラットフォームでは、視聴者がギフトを送ったり、
 iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iPhoneのビデオからスローモーションを削除する2つの方法
Mar 04, 2024 am 10:46 AM
iOS デバイスでは、カメラ アプリを使用してスローモーション ビデオを撮影できます。最新の iPhone を使用している場合は、1 秒あたり 240 フレームのビデオを撮影することもできます。この機能により、高速アクションを詳細にキャプチャできます。ただし、ビデオの詳細やアクションをよりよく理解するために、スローモーション ビデオを通常の速度で再生したい場合もあります。この記事では、iPhone上の既存のビデオからスローモーションを削除するすべての方法を説明します。 iPhoneでビデオからスローモーションを削除する方法[2つの方法] 写真アプリまたはiMovieアプリを使用して、デバイス上のビデオからスローモーションを削除できます。方法 1: 写真アプリを使用して iPhone で開く
 小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
小紅書ビデオ作品を公開するにはどうすればよいですか?動画を投稿する際に注意すべきことは何ですか?
Mar 23, 2024 pm 08:50 PM
短編ビデオ プラットフォームの台頭により、Xiaohongshu は多くの人々が自分の生活を共有し、自分自身を表現し、トラフィックを獲得するためのプラットフォームになりました。このプラットフォームでは、ビデオ作品の公開が非常に人気のある交流方法です。では、小紅書ビデオ作品を公開するにはどうすればよいでしょうか? 1.小紅書ビデオ作品を公開するにはどうすればよいですか?まず、共有できるビデオ コンテンツがあることを確認します。携帯電話やその他のカメラ機器を使用して撮影することもできますが、画質と音声の明瞭さには注意する必要があります。 2.ビデオを編集する:作品をより魅力的にするために、ビデオを編集できます。 Douyin、Kuaishou などのプロ仕様のビデオ編集ソフトウェアを使用して、フィルター、音楽、字幕、その他の要素を追加できます。 3. 表紙を選択する: 表紙はユーザーのクリックを誘致するための鍵です。ユーザーのクリックを誘致するために、表紙には鮮明で興味深い写真を選択してください。
 UC ブラウザでダウンロードしたビデオをローカルビデオに変換する方法
Feb 29, 2024 pm 10:19 PM
UC ブラウザでダウンロードしたビデオをローカルビデオに変換する方法
Feb 29, 2024 pm 10:19 PM
UC ブラウザでダウンロードしたビデオをローカルビデオに変換するにはどうすればよいですか?多くの携帯電話ユーザーは UC Browser を好んで使用しており、Web を閲覧するだけでなく、オンラインでさまざまなビデオやテレビ番組を視聴したり、お気に入りのビデオを携帯電話にダウンロードしたりすることもできます。実は、ダウンロードした動画をローカル動画に変換することもできますが、その方法がわからない人も多いでしょう。したがって、エディターは、UC ブラウザーによってキャッシュされたビデオをローカルビデオに変換する方法を特別に提供します。 uc ブラウザーのキャッシュされたビデオをローカルビデオに変換する方法 1. uc ブラウザーを開き、「メニュー」オプションをクリックします。 2.「ダウンロード/ビデオ」をクリックします。 3. 「キャッシュされたビデオ」をクリックします。 4. 任意のビデオを長押しし、オプションがポップアップ表示されたら、「ディレクトリを開く」をクリックします。 5. ダウンロードしたいものにチェックを入れます
 画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
画質を圧縮せずにWeiboに動画を投稿する方法_画質を圧縮せずにWeiboに動画を投稿する方法
Mar 30, 2024 pm 12:26 PM
1. まず携帯電話で Weibo を開き、右下隅の [Me] をクリックします (図を参照)。 2. 次に、右上隅の [歯車] をクリックして設定を開きます (図を参照)。 3. 次に、[一般設定] を見つけて開きます (図を参照)。 4. 次に、[Video Follow] オプションを入力します (図を参照)。 5. 次に、[ビデオアップロード解像度]設定を開きます(図を参照)。 6. 最後に、圧縮を避けるために [オリジナルの画質] を選択します (図を参照)。
