

HuggingFace: 2 頭のアルパカを頭と尻尾を取り除いてつなぎ合わせたもの

HuggingFace のオープンソースの大規模モデル ランキングが再び削除されました。
最前列は、数週間前のさまざまな Mixtral 8x7B 微調整バージョンを締め出し、SOLAR 10.7B 微調整バージョンによって独占的に占められています。
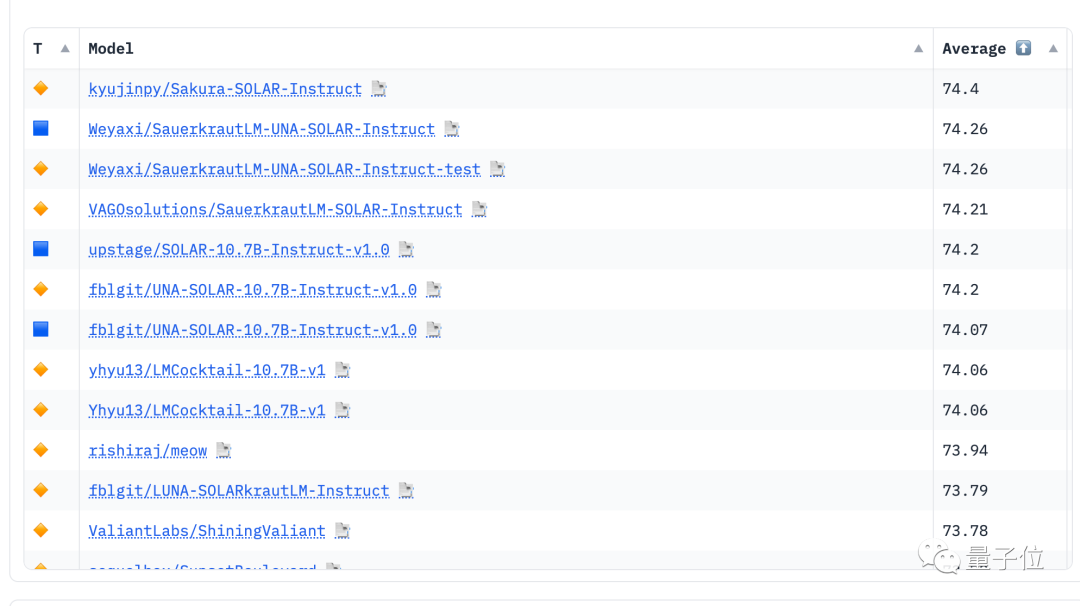
#大型 SOLAR モデルの起源は何ですか?
韓国企業 Upstage AI から、新しい大規模モデル拡張手法 Depth up を使用した関連論文が ArXiv にアップロードされました。 -スケーリング(DUS)。

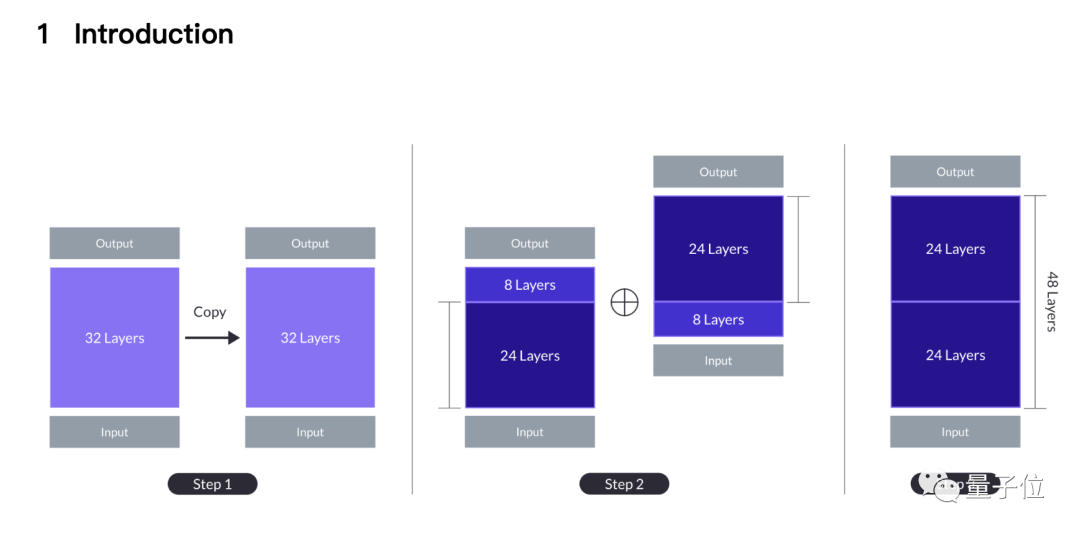
簡単に言うと、2頭の7Bアルパカの頭と尻尾を切り落とし、1頭は最初の8層を切り落とします。 、残りの 8 つのレイヤーのみを切り取ります。
残りの 2 つの 24 レイヤーが縫い合わされます。、最初のモデルの 24 番目のレイヤーが 2 番目のモデルの 9 番目のレイヤーと接合され、最終的に次のようになります。新型48階建て10.7Bの大型モデル。
 論文では、この新しい方法は MoE などの従来の拡張方法を超え、基本的な大規模モデルとまったく同じインフラストラクチャを使用できると主張しています。
論文では、この新しい方法は MoE などの従来の拡張方法を超え、基本的な大規模モデルとまったく同じインフラストラクチャを使用できると主張しています。
ゲート ネットワークなどの追加モジュールは必要なく、トレーニング フレームワークは MoE 用に最適化されており、高速推論のために CUDA カーネルをカスタマイズする必要はなく、効率を維持しながら既存のメソッドにシームレスに統合できます。 。
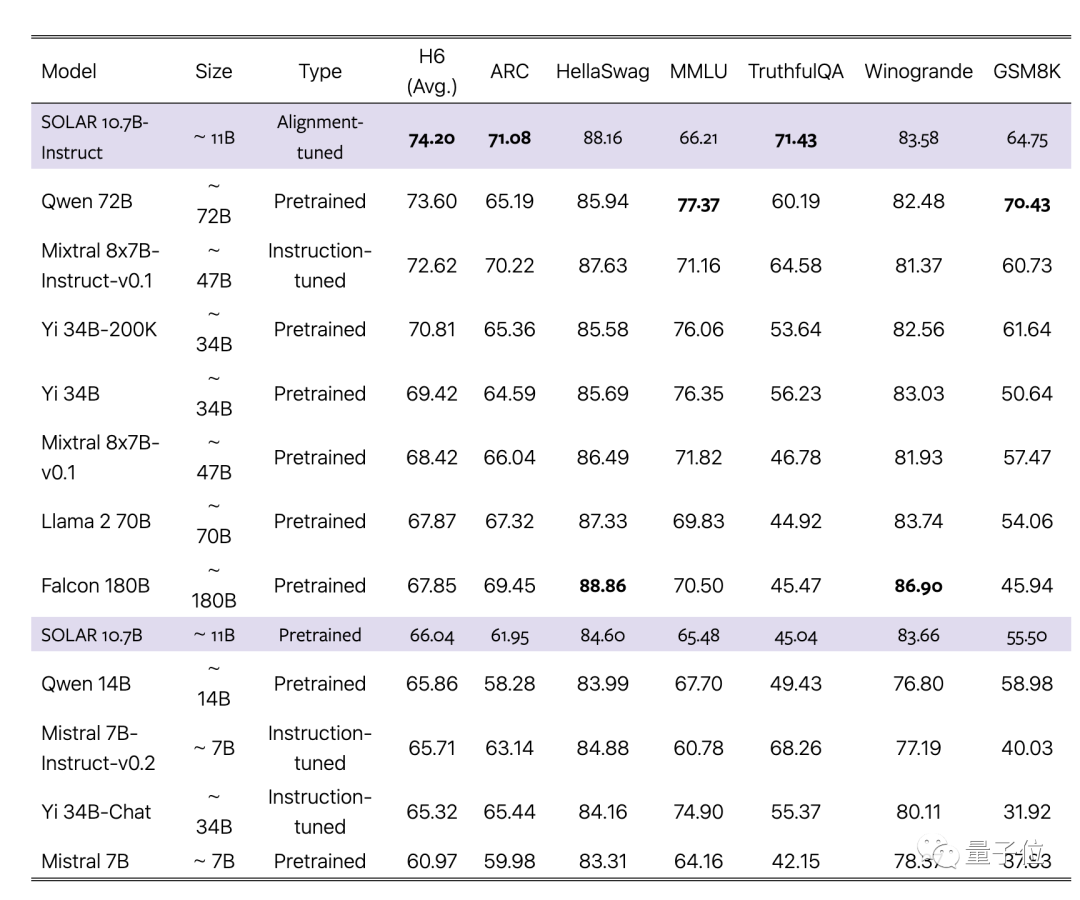
チームは、7B の単一大型モデルの中で最も強力なミストラル 7B をベース素材として選択し、オリジナル バージョンと MoE バージョンを超える新しい方法を使用してそれをつなぎ合わせました。
同時に、調整された命令バージョンも、対応する MoE 命令バージョンを上回ります。
 ステッチを最後まで実行する
ステッチを最後まで実行する
なぜこの継ぎ方なのか? 論文の導入部分は直感から来ています。
最も単純な拡張方法から始めます。これは、32 層の基本的な大規模モデルを 2 回繰り返して 64 層にすることです。
この利点は、異質性がないことです。すべてのレイヤーは基本的な大きなモデルからのものですが、レイヤー 32 とレイヤー 33 の継ぎ目は
(レイヤー 1 と同じ)「レイヤー距離」(レイヤー距離) を大きくします。 以前の研究では、Transformer の層が異なると実行する処理が異なることが示されています。たとえば、より深い層ほど、より抽象的な概念の処理に優れています。
チームは、レイヤーの距離が長すぎると、事前トレーニングされた重みを効果的に利用するモデルの能力が妨げられる可能性があると考えています。
考えられる解決策の 1 つは、中間層を犠牲にして縫い目での段差を減らすことであり、ここで DUS 工法が誕生しました。
パフォーマンスとモデル サイズの間のトレードオフに基づいて、チームは各モデルから 8 つのレイヤーを削除することを選択し、継ぎ目は 32 レイヤーからレイヤー 1、24 レイヤーからレイヤー 9 に変更されました。
単純にスプライスされたモデルのパフォーマンスは、最初はまだ元のベース モデルよりも低いですが、事前トレーニングを続けるとすぐに回復できます。
命令の微調整フェーズでは、オープンソース データ セットの使用に加えて、数学的に強化されたデータ セットも作成され、調整フェーズでは DPO が使用されました。
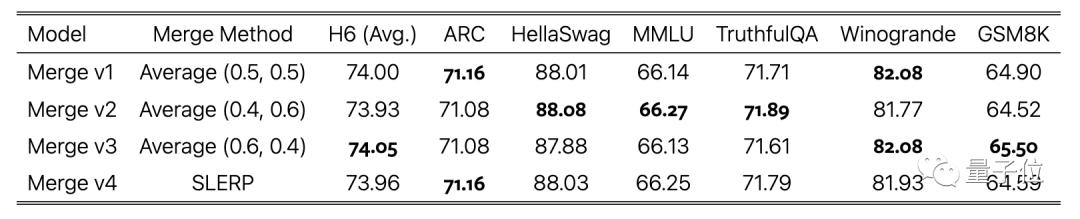
最後のステップは、さまざまなデータ セットを使用してトレーニングされたモデル バージョンの平均に重みを付けることであり、これによりステッチングも完了します。
 一部のネチズンはテストデータ漏洩の可能性を疑問視しました。
一部のネチズンはテストデータ漏洩の可能性を疑問視しました。
 チームはこれも考慮し、論文の付録でデータ汚染テストの結果を具体的に報告しましたが、その結果は低いレベルでした。
チームはこれも考慮し、論文の付録でデータ汚染テストの結果を具体的に報告しましたが、その結果は低いレベルでした。
 最後に、SOLAR 10.7B 基本モデルと微調整モデルは両方とも、Apache 2.0 ライセンスの下でオープンソースです。
最後に、SOLAR 10.7B 基本モデルと微調整モデルは両方とも、Apache 2.0 ライセンスの下でオープンソースです。
これを試したネチズンは、JSON 形式のデータからデータを抽出する際に優れたパフォーマンスを発揮すると報告しています。

以上がHuggingFace: 2 頭のアルパカを頭と尻尾を取り除いてつなぎ合わせたものの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7502
7502
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
この記事では、Debian SystemsでiPtablesまたはUFWを使用してファイアウォールルールを構成し、Syslogを使用してファイアウォールアクティビティを記録する方法について説明します。方法1:Iptablesiptablesの使用は、Debian Systemの強力なコマンドラインファイアウォールツールです。既存のルールを表示する:次のコマンドを使用して現在のiPtablesルールを表示します。Sudoiptables-L-N-vでは特定のIPアクセスを許可します。たとえば、IPアドレス192.168.1.100がポート80にアクセスできるようにします:sudoiptables-input-ptcp - dport80-s192.166
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Nginxログパスはどこですか
Apr 12, 2025 pm 11:33 PM
Debian Nginxログパスはどこですか
Apr 12, 2025 pm 11:33 PM
Debianシステムでは、nginxのアクセスログとエラーログのデフォルトのストレージ場所は次のとおりです。アクセスログ(アクセスログ):/var/log/nginx/access.logエラーログ(errorlog):/var/log/nginx/error.log上記のパスは、標準のdebiannginxインストールのデフォルト構成です。インストールプロセス中にログファイルストレージの場所を変更した場合は、nginx構成ファイル(通常は/etc/nginx/nginx.confまたは/etc/etc/nginx/sites-abailable/directoryにあります)を確認してください。構成ファイル
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
