

AIを活用したイベント知的分析システムの実践的構築と応用

1. 背景
仮想化やクラウド コンピューティングなどの新しいテクノロジーの広範な適用により、企業データ センター内の IT インフラストラクチャの規模は急速に成長しました。その結果、コンピュータのハードウェアとソフトウェアのサイズが増大し、コンピュータの故障も頻繁に発生しました。したがって、最前線の運用および保守担当者は、課題に対処するために、より専門的で強力な運用および保守ツールを緊急に必要としています。
データセンターの日常の運用と保守では、通常、基本的な監視システムとアプリケーション監視システムを使用して、障害検出メカニズムを構築します。事前にしきい値を設定しておくと、ソフトウェアやハードウェアのさまざまな異常が発生したときに、インジケーター項目がしきい値を超えてアラームが発生します。運用専門家は直ちに通知を受け、トラブルシューティングを実行して、データセンターの安定した運用を確保します。このような監視メカニズムにより、潜在的な問題を適時に検出して解決できるため、データセンターの信頼性と可用性が向上します。
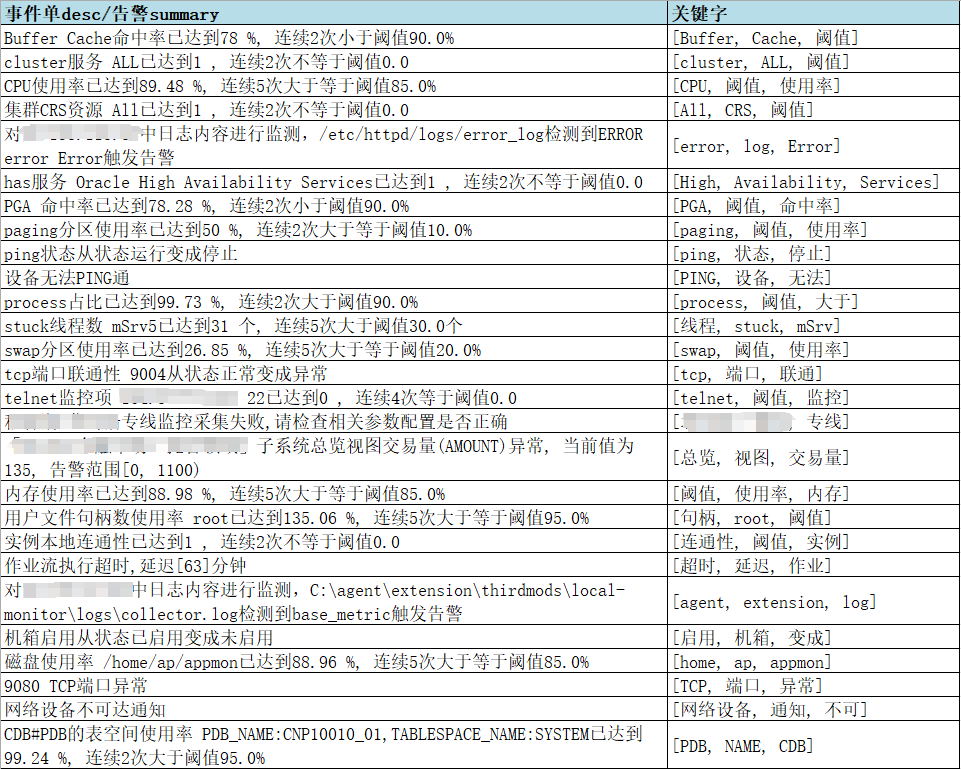
#イベントインテリジェント分析システムは、アラームの遷移を解決し、分析して処理するように設計されたシステムです。 2. 全体的なアーキテクチャ 1. イベントインテリジェント分析システムのアーキテクチャイベントインテリジェント分析システムは、「障害特定-障害分析-障害対応」の全プロセス障害対応システムを構築し、運用保守専門家の経験をデジタルモデルに統合します。 「障害の特定→分析→対処」を行うことで、MTTR(平均修復時間)を短縮します。 イベント インテリジェント分析システムは、システムの各モジュールを強化するために AI テクノロジーを導入しており、運用保守の専門家が手動で障害モデルを確立しない場合、AI が自動的に障害モデルを確立します。アラームを発して自動的に分析し、運用および保守の専門家による障害の分析を支援する分析計画を提供します。 AI の強化により、運用および保守の専門家のモデリング作業負荷のプレッシャーが軽減され、運用および保守の専門家の経験の盲点も補われます。
#次は、イベント インテリジェント分析システムの全体的なアーキテクチャ図です。
#写真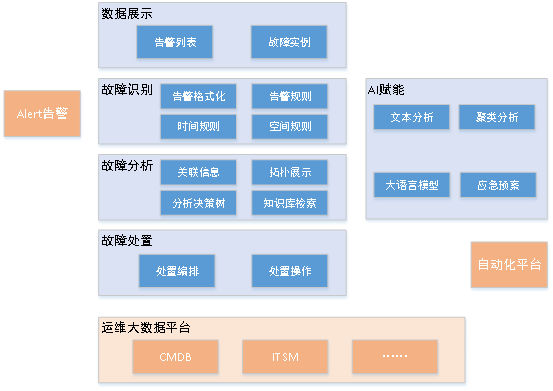
#3. 機能の詳細説明
1. 障害の特定
障害特定の主な機能は、アラームを障害に変換するためのルールを定義できる障害モデルを確立することですが、同時に、障害モデルの定義は、高い CPU 使用率などの障害の単純な分類でもあります障害、メモリ使用量の多い障害など ディスクの使用量が多い障害、ネットワーク遅延の障害など 簡単に言えば、どのアラームが障害になる可能性があるかを意味します。アラームと障害の数の関係は 1:1 または n のいずれかになります。 1; 間の関係のみ 特定の障害を特定することによってのみ、その後の分析と処理が容易になります。
アラームの形式:
統合イベント プラットフォームから受信したアラームは標準化され、イベント インテリジェント処理システムによって処理されます。必要な形式は、一部のフィールドは、構成管理のオブジェクト インスタンス データを検索して補足する必要があります。
障害モデルの定義:
障害シナリオ モデルの定義には、主に基本情報、障害ルール、分析および意思決定機能などが含まれます。
1) 基本情報には、障害名、属するオブジェクト、障害タイプ、障害の説明が含まれます;
2 ) 障害ルールは次のカテゴリに分類できます:
- アラームマッチングのキーワードルールの設定: アラームのjsonフィールドの概要やレベルなどのフィールドを条件として設定でき、複数のルールを論理的に設定できます(ルールのANDまたはNOT計算)。 時間ルール: 即時実行 (アラーム受信直後に障害インスタンスを生成)、固定時間ウィンドウの待機 (最初のアラームの開始後の一定期間内にアラームの障害インスタンスを強制的に集約)、待機を含むスライド時間ウィンドウ(最後のアラームが開始されてから一定期間内のアラーム強制集約障害インスタンス);
- ロケーション ルール: 同じマシン、同じデプロイメント ユニット、同じ物理サブシステム、および範囲内の条件を満たすアラームが含まれます。指定された範囲が 1 つの障害インスタンスに集約されます。
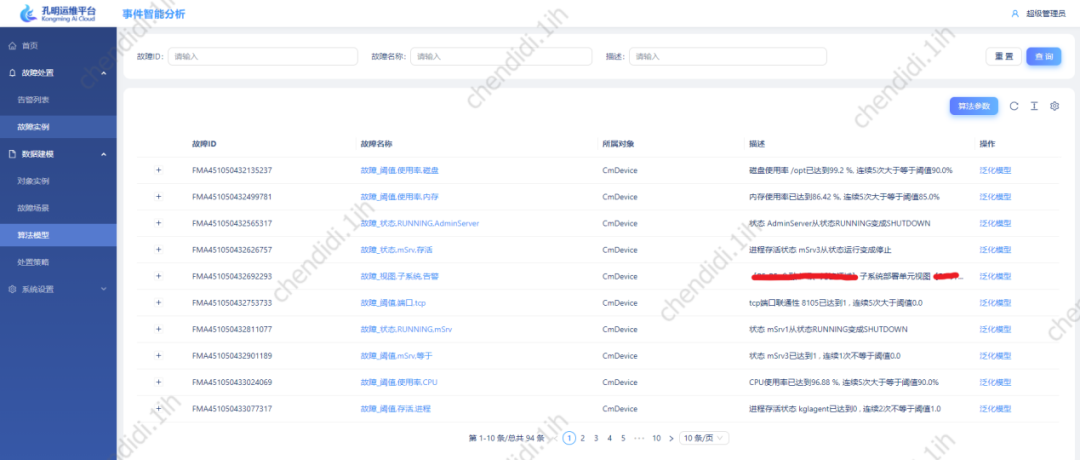
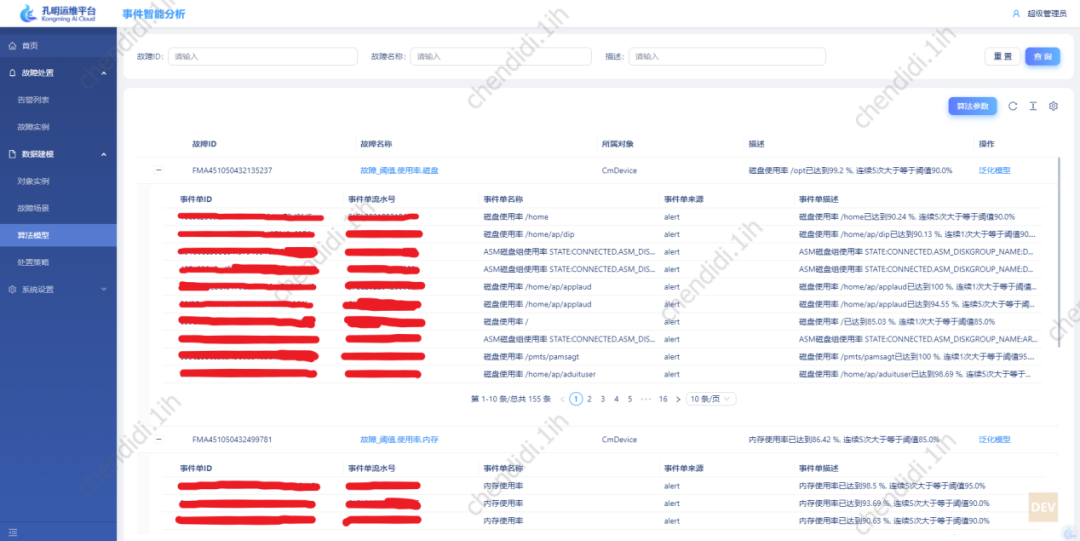
3) 変更分析: 過去 48 時間のアラームオブジェクトに対応するシステムの作業指示記録を変更し、変更分析を実施します; 4) ログ分析: 指定されたパスの適用アラームオブジェクトとその周囲のオブジェクトのログやシステムログを解析して表示します。5) リンク解析:トランザクションコードを核として、アラームオブジェクトに関わるトランザクションコードの上流と下流のリンクデータを解析します。 トポロジ構造の表示: # 物理サブシステムを次元として、システム全体に関わる運用および保守の対象を考慮します。ツリー トポロジ構造で整理されて表示されると同時に、アラームが発生したノードは赤色でマークされ、運用および保守の専門家に警告します。 # 具体的な例は次のとおりです。
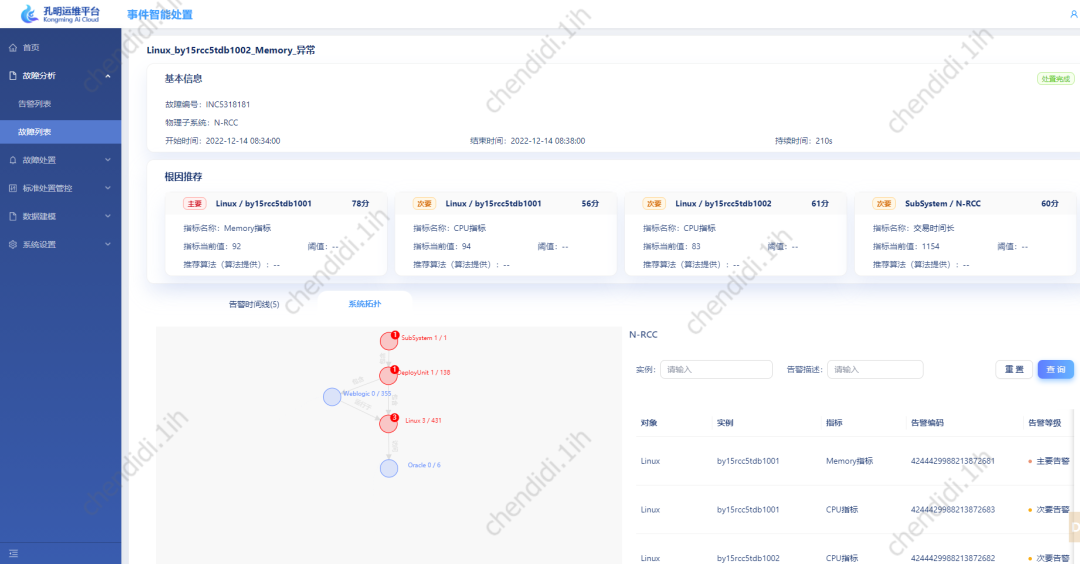 写真
写真
#具体的な例は次のとおりです。
#画像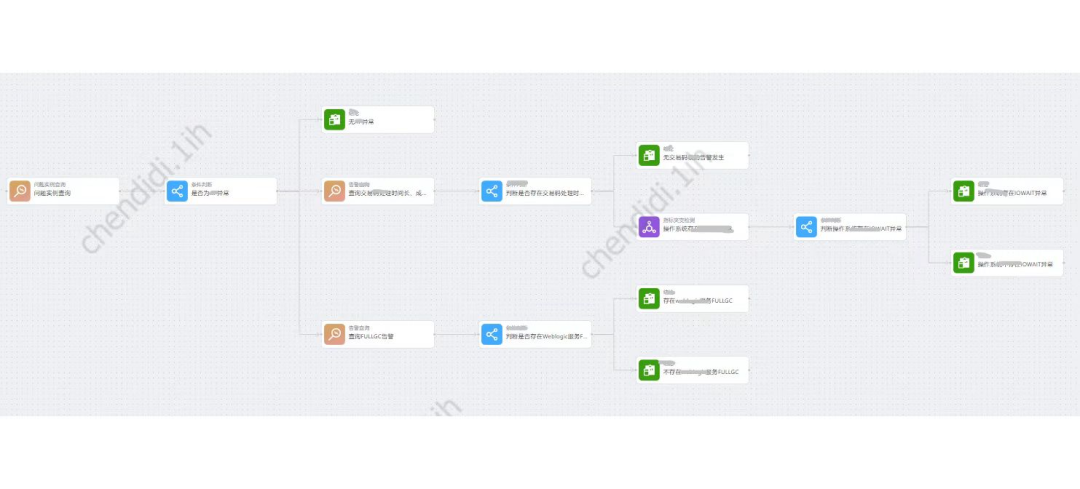 #ナレッジ ベース検索:
#ナレッジ ベース検索:
AIエンパワーメントは、障害の「特定・分析・対処」の全プロセスにおいて、手動設定作業の負荷を最小限に抑え、運用・保守専門家の負担を軽減するものであり、AIでカバーできない部分も補うことができます。運用および保守の専門家の経験があり、初期化段階で過去に発生したアラームの種類を 100% カバーできます。全体的な原則は、AI 計算を使用して障害の特定と分析の分野で障害モデルと分析を構築することです。この計画は、運用および保守の専門家に参考となるものを提供しますが、最終的な判断と制御は運用および保守の専門家によって行われ、アルゴリズムが作業の 99% を実行することを保証します。手動レビューにより、作業の最後の 1% が確実に行われます。
#1. 自動モデリング 第 3-1 章の障害モデルの定義を確認すると、次のことがわかりました。アラーム ルール、時間ルール、スペース ルールを決定する限り、分析デシジョン ツリーを同時に決定して障害モデルを構築できます。時間ルールとスペース ルールは、最も一般的な即時実行と同じマシンをデフォルトにすることができます。また、分析デシジョン ツリーでは最も従来のヘルス チェックを使用できます。 したがって、障害モデルを確立し、同じ種類の障害のモデルを構築する場合、中心的な問題はアラームの内容によって障害を分類することであり、次のキーワードを使用します。アラームの内容に基づいて分類を決定し、特定のタイプの障害モデルを確立します。次に、自動モデリングの問題は、アラームのキーワードを見つけて、それらに基づいて障害モデルを確立することに退化します。 全体的なロジック図は次のとおりです: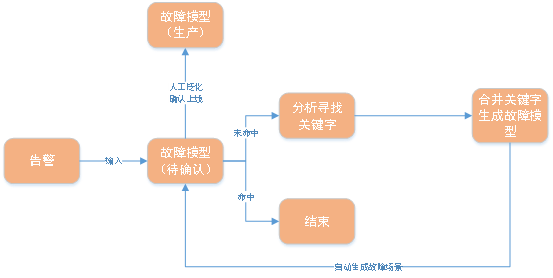 図
図
 #Google が BERT (Bidirectional Encoder Representations from Transformers) をリリースして以来、さまざまなテキスト タスクでランキングのトップに立っており、非常に良い結果が得られているため、主にテキストの類似性を計算するために使用されています。アラームの内容と障害の説明の間の類似性を計算します。
#Google が BERT (Bidirectional Encoder Representations from Transformers) をリリースして以来、さまざまなテキスト タスクでランキングのトップに立っており、非常に良い結果が得られているため、主にテキストの類似性を計算するために使用されています。アラームの内容と障害の説明の間の類似性を計算します。
# 次に、クラスタリング アルゴリズムを構築します。具体的なプロセス図は次のとおりです。
#図具体的な手順は次のとおりです:
1) 必要に応じて、障害クラスタリングのアンカー方向として障害の説明を手動で設定できます。この手順は必要ありません。そうでない場合は、直接スキップしてください。
2) アラーム情報を削除し、不要な文字を削除します。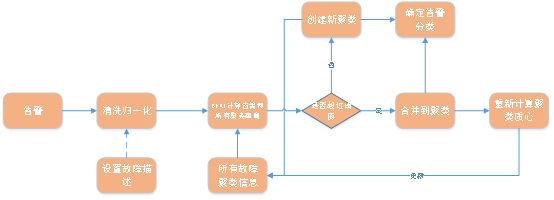 3) BERT モデルを使用して、アラームのテキスト コンテンツを分析します。サマリーと全障害 クラスタリングした情報をテキスト類似度計算し、同様の結果を得る(閾値を超えているか否かで類似判定);
3) BERT モデルを使用して、アラームのテキスト コンテンツを分析します。サマリーと全障害 クラスタリングした情報をテキスト類似度計算し、同様の結果を得る(閾値を超えているか否かで類似判定);
このアルゴリズムの利点は次のとおりです。
1) 履歴およびリアルタイムのアラーム データを通じて、監視なしで障害分類が自動的に実行されるため、障害分類を確立する必要がありません。障害モデル、人的資源の節約;
2) リアルタイム アラームの場合、障害クラスタリング プロセスにより、定期的な計算やモデルの更新を必要とせずにリアルタイムのオンライン更新が保証されます。
##3) アラームは自動的に生成されるか、障害に関連付けられます。これらは、対応する緊急計画とさらに関連付けられ、障害分析計画と治療方法を取得できます。#3. 分析計画を自動的に生成する
第 3-2 章の障害分析、障害の分析を確認してください。主に、障害ノードとその周囲のノードの情報を表示することに重点が置かれており、分析デシジョン ツリーの設定では、より手動での設定も必要になります。
AI エンパワーメント後は、緊急計画、アラームの詳細、障害分析の表示情報をプロンプト (プロンプト) として使用することを検討し、優れた結果が得られた既存の大規模言語モデルを使用して障害分析を自動的に提供します。ソリューション。
民営化された展開の問題を考慮すると、大規模言語モデルとして ChatGLM2、llama2 などを検討できます。特定の実装段階では、ニーズとハードウェア レベルに応じてさまざまな大規模言語モデルを選択できます。この記事の計画説明では、大規模な言語モデルを表すために一律に LLM を使用します。その違いに注意してください。
主なプロセス図は次のとおりです:
写真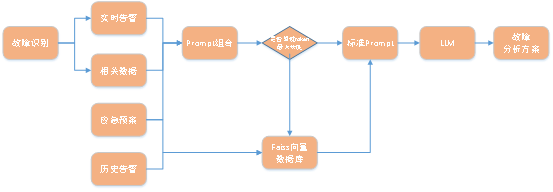
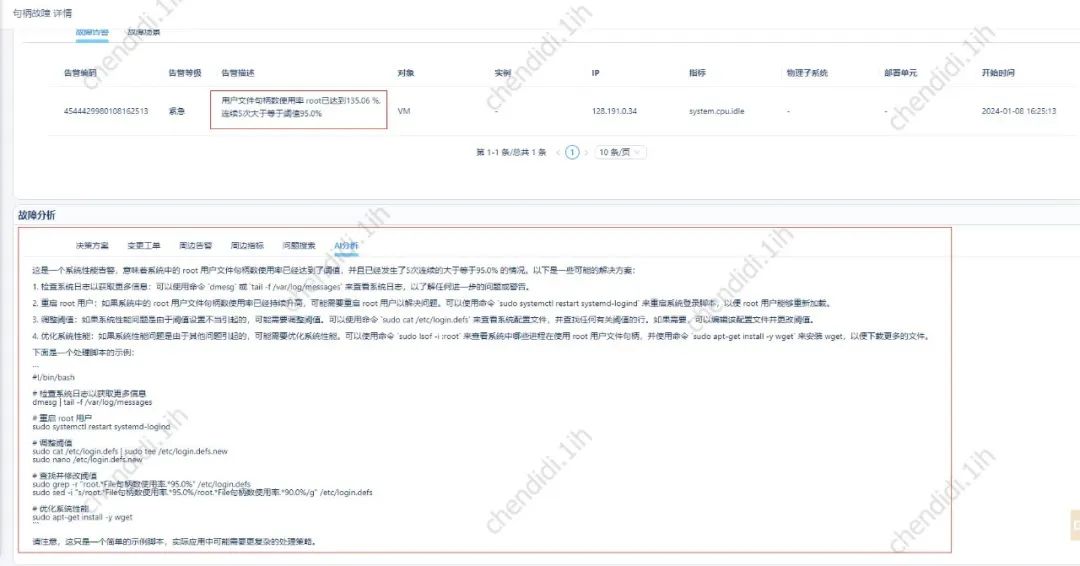
#具体的な効果については、以下の写真を参照してください:
写真
4. 緊急時計画の検索
業界で必要なマニュアルとして、緊急時計画は、すべての障害の該当する分析を包括的に記録します。システム、すべての運用および保守対象、および廃棄手順は非常に優れたテキスト データであり、緊急時計画の内容はこのシステムのさまざまな場所で使用されます。したがって、緊急計画の検索機能を提供する必要があり、ナレッジベースシステムは緊急計画の検索基盤として利用することができる。
文字列マッチングによるテキスト検索、テキスト解析後のキーワード検索、意味レベルのベクトル類似性検索が可能で、システムが必要とする対応する緊急計画テキストを取得します。
上記の検索方法はすべて、上記の技術的手段を使用して処理できるため、ここでは再度説明しません。
5. 結論
イベントインテリジェント分析システムは、運用保守の専門家による各システムの運用保守を支援するためのシリーズを提供しています。モデリング手法により、運用保守の専門家は運用保守の経験をデジタルモデルに集約でき、データ量(障害サンプルデータや運用保守関連データ)が増大する場合、一部のAIアルゴリズムを使用することで作業負荷を軽減できます。運用・保守専門家の作業負荷を軽減し、運用・保守専門家の分析的意思決定を支援し、最終的には運用・保守専門家の介入なしに運用・保守を自動化できる状態、すなわち「自己発見・自動化」を実現したいと考えています。故障に対しては「メンテナンスフリー」。
以上がAIを活用したイベント知的分析システムの実践的構築と応用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7742
7742
 15
1643
14
1397
52
1291
25
1234
29
15
1643
14
1397
52
1291
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
