

自動運転分野のエンドツーエンド技術は、Apollo や Autoware などのフレームワークに取って代わるのでしょうか?

nuScenes におけるエンドツーエンドの自動運転のオープンループ評価を再考する
- 著者ユニット: Baidu
- 著者: Jiang-Tian Zhai、Ze Feng、Baidu Wang Jingdong Group
- 発行: arXiv
- 論文リンク: https://arxiv.org/abs/2305.10430
- コードリンク: https://github.com/E2E - AD/AD-MLP
キーワード: エンドツーエンドの自動運転、nuScenes オープンループ評価
1. 概要
一部の自動運転システムは、通常、知覚、予測、計画の 3 つの主要なタスクに分かれており、計画タスクでは、内部の意図と外部環境に基づいて車両の軌道を予測し、車両を制御します。既存のソリューションのほとんどは、nuScenes データ セットでメソッドを評価します。評価指標は、L2 エラーと衝突率です。
この記事では、既存の評価指標を再評価して、それらが正確であるかどうかを調査します。さまざまな方法。この記事では、生のセンサー データ (過去の軌跡、速度など) を入力として受け取り、カメラ画像や LiDAR などの認識情報や予測情報を使用せずに、車両の将来の軌跡を直接出力する MLP ベースの方法も設計しました。驚くべきことに、このような単純な方法により、nuScenes データセット上で SOTA プランニングのパフォーマンスが実現され、L2 エラーが 30% 削減されます。さらに詳細な分析により、nuScenes データセットでタスクを計画するために重要な要素について、いくつかの新しい洞察が得られます。私たちの観察は、nuScenes におけるエンドツーエンドの自動運転のための開ループ評価スキームを再考する必要があることも示唆しています。
2. 論文の目的、貢献、結論
この論文は、nuScenes 上のエンドツーエンド自動運転の開ループ評価スキームを評価することを目的としています。 ; ビジョンやライダーを使用せず この場合、車両の状態と高度なコマンド (合計 21 次元のベクトル) のみを入力として使用することで、nuScenes 上で計画の SOTA を実現できます。したがって、著者は nuScenes の開ループ評価の信頼性の低さを指摘し、2 つの分析を提供しました: nuScenes データセット上の車両の軌道は直進するか、曲率が非常に小さい傾向があります; 衝突率の検出はグリッド密度に関連していますデータセットの衝突アノテーションにもノイズが多く、衝突率を評価する現在の方法は堅牢かつ正確ではありません;
3. 論文の方法
##3.1 概要と関連作業の概要
既存の自動運転モデルには、認識、予測、計画などの複数の独立したタスクが含まれます。この設計により、チーム間での書き込みの難しさが簡素化されますが、各タスクの最適化とトレーニングが独立しているため、システム全体での情報の損失とエラーの蓄積にもつながります。自車両と周囲環境の時空間的特徴を学習することから恩恵を受けるエンドツーエンドの方法が提案されています。関連研究: ST-P3[1] は、認識、予測、計画のための特徴学習を統合する、解釈可能なビジョンベースのエンドツーエンド システムを提案しています。 UniAD[2] は計画タスクを体系的に設計し、クエリベースの設計を使用して複数の中間タスクを接続し、複数のタスク間の関係をモデル化およびエンコードできます。VAD[3] は完全にベクトル化された方法でシーンを構築します。モジュールは密な特徴表現を必要としませんそして計算的にはより効率的です。
この記事では、既存の評価指標がさまざまな方法の長所と短所を正確に測定できるかどうかを調査したいと考えています。この論文では、カメラや LIDAR によって提供される知覚および予測情報を使用するのではなく、運転中の車両の物理的状態 (既存の方法で使用される情報のサブセット) のみを使用して実験を実施します。つまり、この記事のモデルはビジュアル エンコーダや点群特徴エンコーダを使用せず、車両の物理情報を 1 次元ベクトルに直接エンコードし、連結後に MLP に送信します。トレーニングでは、GT 軌道を監視に使用し、モデルは将来の特定の時間内の車両の軌道ポイントを直接予測します。以前の作業に従い、nuScenes データ セットの評価に L2 エラーと衝突率 (衝突率) を使用します。モデル設計はシンプルですが、最良の計画結果が得られます。この記事では、これは現在の不十分な点によるものであると考えています。評価指標の説明。実際、過去の自車の軌跡、速度、加速度、時間連続性を利用することで、将来の自車の動きをある程度反映することができます。3.2 モデル構造
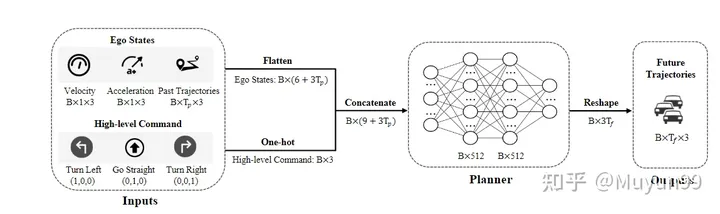
=4フレーム分の自車の運動軌跡、瞬間速度、加速度を収集

高度なコマンド: このモデルでは高精度の地図が使用されていないため、ナビゲーションには高度なコマンドが必要です。一般的な慣例に従い、左折、直進、右折の 3 種類のコマンドが定義されています。具体的には、自車が今後 3 秒以内に左右に 2m 以上移動する場合は、対応するコマンドを左または右に曲がり、それ以外の場合は直進するように設定します。次元 1x3 のワンホット エンコーディングを使用して高レベルのコマンドを表現します
ネットワーク構造: ネットワークは単純な 3 層 MLP (入力から出力までの寸法はそれぞれ 21-512-512-18)、最終出力フレーム数 = 6、各フレーム出力自車両の軌道位置(x,y座標)と進行方向の角度(方位角)
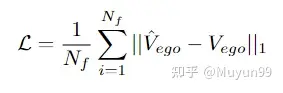
損失関数
損失関数 : ペナルティには L1 損失関数を使用します
4. 論文の実験
4.1 実験設定
データセット : 実験は、主にボストンとシンガポールで収集された 1K のシーンと約 40K のキーフレームで構成される nuScenes データセットに対して、LiDAR と全周カメラを搭載した車両を使用して行われます。各フレームで収集されるデータには、マルチビュー Camear 画像、LiDAR、速度、加速度などが含まれます。
評価メトリクス: ST-P3 論文 (https://github.com/OpenPerceptionX/ST-P3/blob/main/stp3/metrics.py) の評価コードを使用します。 1 秒、2 秒、および 3 秒の時間範囲の出力トレースを評価します。予測された自車軌道の品質を評価するために、一般的に使用される 2 つの指標が計算されます。
L2 誤差: メートル単位で、次の 1 秒、2 秒、および 3 秒における予測軌道と真の自車軌道軌道間の平均 L2 誤差を計算します;
衝突率: パーセントで表します。自車両が他の物体と衝突する頻度を求めるには、予測軌道上の各ウェイポイントに自車両を表すボックスを配置し、車両と歩行者の境界ボックスとの衝突の有無を検出することで衝突を計算します。現在のシーンで評価します。
ハイパーパラメータ設定とハードウェア: PaddlePaddle および PyTorch フレームワーク、AdamW オプティマイザー (4e-6 lr および 1e-2 重み減衰)、コサイン スケジューラ、6 エポック用にトレーニング、バッチ サイズ For 4、 V100 を使用しました
4.2 実験結果
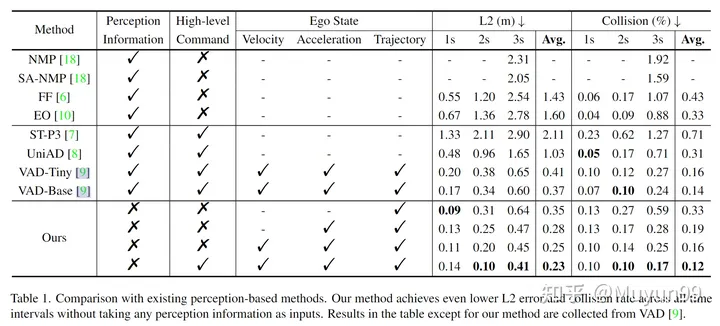
表 1 既存の知覚ベースの方法との比較
Someアブレーション実験は表 1 で実行されました。この記事のモデルのパフォーマンスに対する速度、加速度、軌道、および高レベルのコマンドの影響を分析するため。驚くべきことに、入力として軌跡のみを使用し、知覚情報を使用しないベースライン モデルは、既存のすべての方法よりも低い平均 L2 エラーをすでに達成しています。
加速度、速度、高レベル コマンドを入力に徐々に追加すると、平均 L2 エラーと衝突率は 0.35m から 0.23m に、0.33% から 0.12% に減少します。最後の行に示すように、エゴ状態と高レベル コマンドの両方を入力として受け取るモデルは、L2 エラーと衝突率が最も低くなり、これまでのすべての最先端の知覚ベースの手法を上回っています。
4.3 実験分析
この記事では、nuScenes トレーニング セット上の自車ステータスの分布を、次の 3 秒間の軌跡点、方位角 (ヘディング/ヨー角) と曲率角 (曲率角)
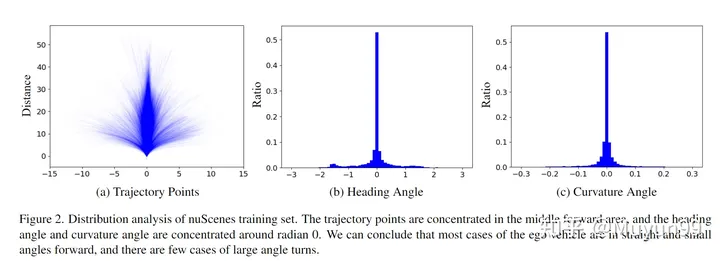
nuScenes トレーニング セットの分布分析。
トレーニング セット内のすべての将来の 3 秒軌道ポイントが図 2(a) にプロットされています。図からわかるように、弾道は主に中央部(直線)に集中しており、主に直線、あるいは曲率が非常に小さい曲線となっている。
ヘディング角度は現在時刻を基準とした将来の進行方向を表し、曲率角度は車両の回転速度を反映します。図 2 (b) と (c) に示すように、方位角と曲率角の約 70% は、それぞれ -0.2 ~ 0.2 ラジアンと -0.02 ~ 0.02 ラジアンの範囲内にあります。この発見は、軌道点の分布から導かれた結論と一致しています。
軌道点、方位角、曲率角の分布に関する上記の分析に基づいて、この記事では、nuScenes トレーニング セットでは、自車は直線かつ小さな角度で前方に移動する傾向があると考えています。短い時間範囲内で移動する場合の角度。
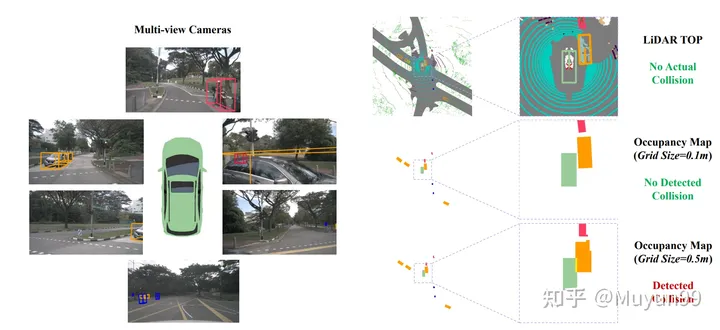
占有マップのグリッド サイズが異なると、GT 軌道で衝突が発生します。
衝突率を計算する場合、既存の方法では次のことが一般的です。車両と歩行者などの物体を組み合わせてBEV(Bird's Eye View)空間に投影し、占有面積に換算してグラフ化します。そして、ここで精度が失われます。GT 軌跡サンプルのごく一部 (約 2%) が占有グリッド内の障害物とも重なっていることがわかりましたが、データを収集するときに自車は実際には他のオブジェクトと重なりません A衝突が発生すると、衝突が誤って検出されます。 自車両が特定のオブジェクト (占有マップの単一のピクセルのサイズより小さいなど) に近づくと、誤った衝突が発生します。
図 3 は、この現象の例と、2 つの異なるグリッド サイズによるグラウンド トゥルース軌道の衝突検出結果を示しています。オレンジ色は、衝突として誤って検出される可能性のある車両です。右下隅に示されている小さいグリッド サイズ (0.1 m) では、評価システムは GT 軌道を非衝突として正しく識別しますが、右下の大きいグリッド サイズでは、評価システムは GT 軌道を非衝突として識別します。コーナー(0.5m)の場合、誤った衝突検出が発生します。
占有グリッド サイズが軌道衝突検出に及ぼす影響を観察した後、グリッド サイズを 0.6m としてテストしました。 nuScenes トレーニング セットには 4.8% の衝突サンプルがあり、検証セットには 3.0% があります。以前に 0.5m のグリッド サイズを使用したとき、検証セット内のサンプルの 2.0% のみが衝突として誤分類されたことは言及する価値があります。これは、衝突率を推定する現在の方法が十分に堅牢ではなく、正確ではないことを再度示しています。
著者の要約: この論文の主な目的は、新しいモデルを提案することではなく、私たちの観察を提示することです。私たちのモデルは nuScenes データセット上では良好に機能しますが、現実の世界で使用できない非実用的なおもちゃであることは認識しています。自車ステータスを持たずに運転することは、克服できない課題です。それにもかかわらず、私たちは、私たちの洞察がこの分野のさらなる研究を刺激し、エンドツーエンドの自動運転の進歩の再評価を可能にすることを願っています。
5. 記事の評価
この記事は、nuScenes データセットに対する最近のエンドツーエンドの自動運転評価を徹底的にレビューしたものです。計画シグナルの暗黙的なエンドツーエンドの直接出力であっても、中間リンクを使用した明示的なエンドツーエンド出力であっても、それらの多くは nuScenes データセットで評価された計画指標であり、Baidu の記事では、この種の評価は次のように指摘されています。信頼性がありません。この種の記事は、実際には非常に興味深いものです。実際、公開されると多くの同僚の顔を平手打ちしますが、同時に業界の前進を積極的に促進します。おそらく、エンドツーエンドの計画を行う必要はありません (認識予測はパフォーマンスを評価する際に閉ループ テスト (CARLA シミュレーターなど) をさらに行うことで、自動運転コミュニティの進歩をより促進し、論文を実際の車両に実装できる可能性があります。自動運転への道はまだ遠い~
参考
- ^ST-P3: エンドツーエンドのビジョンベースの自動運転時空間特徴学習経由 #^計画指向の自動運転
- ^VAD: 効率的な自動運転のためのベクトル化されたシーン表現
 ##元のリンク: https://mp.weixin.qq.com/s/skNDMk4B1rtvJ_o2CM9f8w
##元のリンク: https://mp.weixin.qq.com/s/skNDMk4B1rtvJ_o2CM9f8w
以上が自動運転分野のエンドツーエンド技術は、Apollo や Autoware などのフレームワークに取って代わるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7444
7444
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 SORA vs VEO 2:よりリアルなビデオを作成するのはどれですか?
Mar 10, 2025 pm 12:22 PM
SORA vs VEO 2:よりリアルなビデオを作成するのはどれですか?
Mar 10, 2025 pm 12:22 PM
GoogleのVEO 2とOpenaiのSORA:どのAIビデオジェネレーターが最高でしたか? どちらのプラットフォームも印象的なAIビデオを生成しますが、その強みはさまざまな領域にあります。 この比較は、さまざまなプロンプトを使用して、どのツールがニーズに最適かを明らかにします。 t
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
