

「一歩ずつ考えていきましょう」というマントラよりも効果的で、プロジェクトが改善されつつあることを思い出させてくれます。

大規模な言語モデルは、メタヒントを通じて自動ヒント エンジニアリングを実行できますが、大規模な言語モデルの複雑な推論機能をガイドするための十分なガイダンスが不足しているため、その可能性が完全には実現されない可能性があります。では、大規模な言語モデルをガイドして自動プロンプト プロジェクトを実行するにはどうすればよいでしょうか?
大規模言語モデル (LLM) は、自然言語処理タスクにおける強力なツールですが、最適な手がかりを見つけるには、多くの手動の試行錯誤が必要になることがよくあります。モデルの機密性が高いため、運用環境に展開した後でも、プロンプトを改善するためにさらなる手動調整が必要となる予期しないエッジケースが発生する可能性があります。したがって、LLM には大きな可能性がありますが、実際のアプリケーションでそのパフォーマンスを最適化するには、依然として手動介入が必要です。
これらの課題により、オートキューエンジニアリングという新たな研究分野が生まれました。この分野における注目すべきアプローチの 1 つは、LLM 独自の機能を活用することです。具体的には、これには、「現在のプロンプトとサンプル バッチを確認してから、新しいプロンプトを生成する」など、LLM をメタキューするための命令の使用が含まれます。
これらの方法は優れたパフォーマンスを実現しますが、次のような疑問が生じます。自動ヒント エンジニアリングにはどのようなメタヒントが適しているのでしょうか?
この質問に答えるために、南カリフォルニア大学とマイクロソフトの研究者は 2 つの重要な観察結果を発見しました。まず、プロンプト エンジニアリング自体は、深い推論を必要とする複雑な言語タスクです。これは、モデルにエラーがないか慎重に検査し、現在のプロンプトに一部の情報が欠落しているか誤解を招くかどうかを判断し、タスクをより明確に伝える方法を見つけることを意味します。第 2 に、LLM では、モデルを段階的に思考するように誘導することで、複雑な推論能力を刺激できます。モデルにその出力を反映するように指示することで、この機能をさらに向上させることができます。これらの観察は、この問題を解決するための貴重な手がかりを提供します。

論文アドレス: https://arxiv.org/pdf/2311.05661.pdf
これまでの観察を通じて、研究者は微調整プロジェクトを実施しました。メタヒントの確立は、LLM がヒント エンジニアリングをより効率的に実行するためのガイダンスを提供することを目的としています (以下の図 2 を参照)。既存の手法の限界を反映し、複雑な推論プロンプトの最近の進歩を組み込むことにより、プロンプト エンジニアリングにおける LLM の推論プロセスを明示的にガイドするためのステップバイステップの推論テンプレートやコンテキスト仕様などのメタキュー コンポーネントを導入しています。
さらに、ヒント エンジニアリングは最適化問題と密接に関連しているため、バッチ サイズ、ステップ サイズ、勢いなどの一般的な最適化概念からインスピレーションを借用し、それらをメタヒントに導入して改善することができます。私たちは、MultiArith と GSM8K という 2 つの数学的推論データセットでこれらのコンポーネントとバリアントを実験し、最高のパフォーマンスを発揮する組み合わせを特定し、これを PE2 と名付けました。
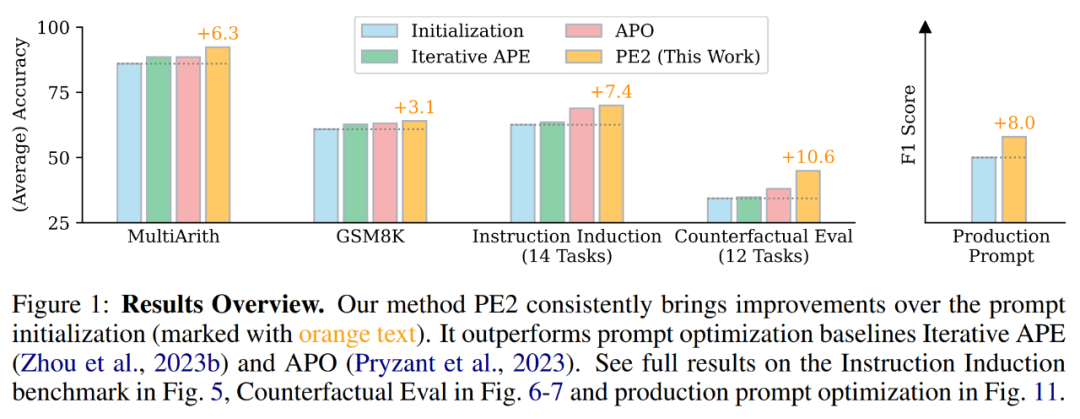
PE2 は実証的なパフォーマンスにおいて大幅な進歩を遂げました。 TEXT-DAVINCI-003 をタスク モデルとして使用すると、PE2 で生成されたプロンプトは、ゼロショット思考チェーンの段階的な思考プロンプトと比較して、MultiArith で 6.3%、GSM8K で 3.1% 改善されました。さらに、PE2 は、反復 APE と APO という 2 つの自動プロンプト エンジニアリング ベースラインを上回ります (図 1 を参照)。
PE2 が反事実タスクで最も効果的に実行されることは注目に値します。さらに、この研究は、長い現実世界のプロンプトの最適化に対する PE2 の幅広い適用可能性を実証しています。
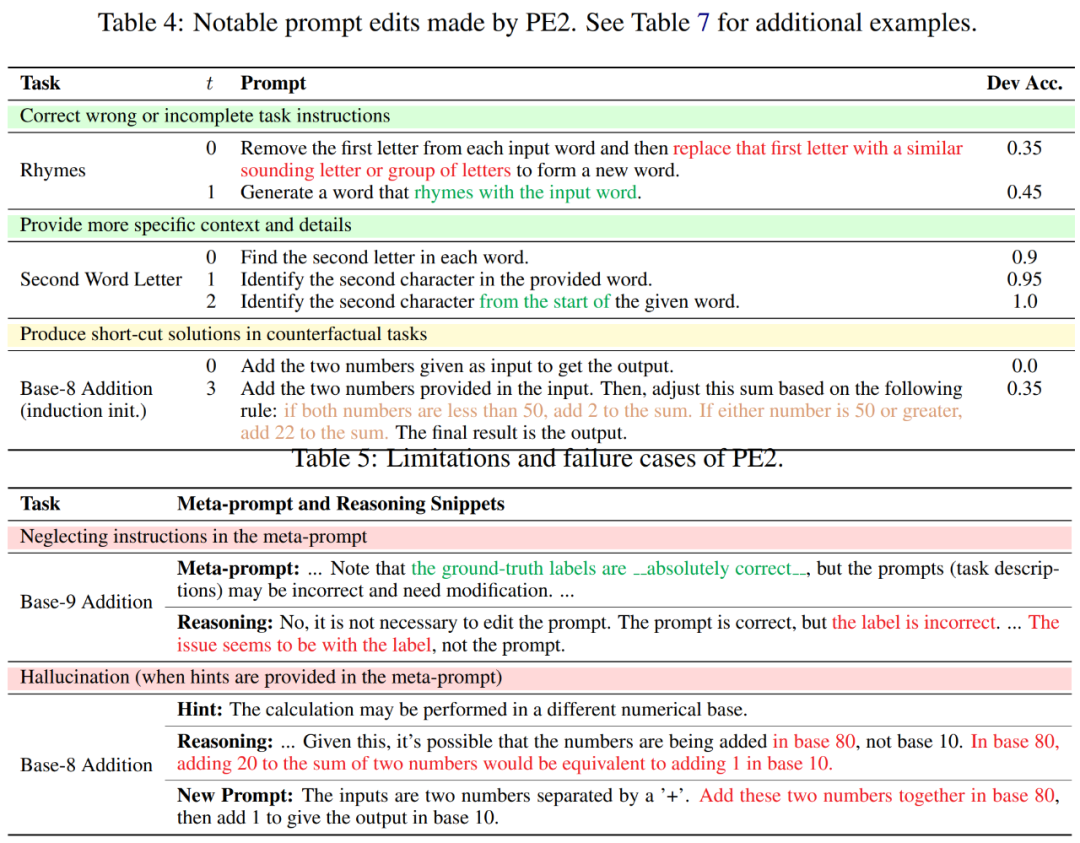
研究者らは、PE2 のプロンプト編集履歴をレビューしたところ、PE2 が一貫して有意義なプロンプト編集を提供していることを発見しました。不正確または不完全なヒントを修正し、追加の詳細を追加することでヒントをより豊富にすることができ、その結果、最終的なパフォーマンスが向上します (表 4 を参照)。
興味深いことに、PE2 は 8 進数の加算を認識しない場合、次の例から独自の算術規則を作成します。「両方の数値が 50 未満の場合は、合計に 2 を加算します。数値の 1 つが 50 またはこれは不完全で単純な解決策ではありますが、反事実的な状況で推論する PE2 の驚くべき能力を示しています。
これらの成果にもかかわらず、研究者は PE2 の限界と失敗も認識しています。 PE2 は、指定された命令を無視したりエラーを生成したりする可能性など、LLM に固有の制限も受けます (以下の表 5 を参照)。
予備知識
プロンプトプロジェクト
プロンプト プロジェクトの目標は、指定された LLM M_task をタスク モデルとして使用したときに、指定されたデータ セット D で最高のパフォーマンスを達成するテキスト プロンプト p∗ を見つけることです (次の式に示すように)。より具体的には、すべてのデータセットがテキスト入出力ペア、つまり D = {(x, y)} としてフォーマットできると仮定します。最適化ヒント用のトレーニング セット D_train、検証用の D_dev、および最終評価用の D_test。研究者が提案した記号表現によれば、プロンプト工学問題は次のように記述できます。
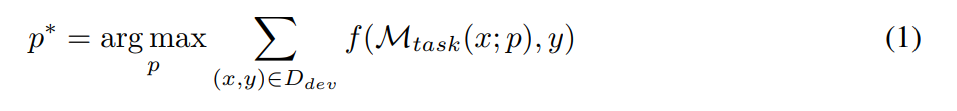
このうち、M_task (x; p) は、以下のモデルによって生成されます。指定されたプロンプト p の出力の条件、f は各例の評価関数です。たとえば、評価指標が完全に一致する場合は、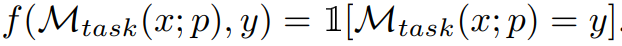
自動プロンプト エンジニアリングに LLM を使用します
プロンプトの初期セットを指定して自動プロンプトを作成します。エンジニアは、新しい、より良いヒントを継続的に考え出します。タイムスタンプ t で、プロンプト エンジニアはプロンプト p^(t) を取得し、新しいプロンプト p^(t 1) を書き込むことを期待します。新しいヒントの生成中に、オプションでサンプル B = {(x, y, y′ )} のバッチを調べることができます。ここで、 y ' = M_task (x; p) はモデルによって生成された出力を表し、 y は真のラベルを表します。 p^meta を使用して、LLM の M_proposal をガイドして新しい提案を提案するメタ プロンプトを表します。したがって、
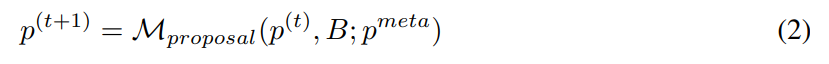
提案されたヒント p^(t 1) の品質を向上させるために、より優れたメタキュー p^meta を構築することが、この研究の主な焦点です。
より良いメタキューの構築
キューが最終的なタスクの実行において重要な役割を果たすのと同様に、式 2 で導入されたメタキュー p^meta は、 new 表示されるプロンプトの品質と自動プロンプト プロジェクトの全体的な品質において重要な役割を果たします。
研究者は主にメタキュー p^meta のヒント エンジニアリングに焦点を当てており、LLM ヒント エンジニアリングの品質向上に役立つ可能性のあるメタキュー コンポーネントを開発し、これらのコンポーネントについて体系的なアブレーション研究を実施しました。
研究者らは、次の 2 つの動機に基づいてこれらのコンポーネントの基礎を設計しました: (1) 詳細なガイダンスと背景情報を提供する; (2) 共通のオプティマイザーの概念を組み込む。次に、研究者はこれらの要素をより詳細に説明し、基礎となる原理を説明します。下の図 2 は視覚的に表したものです。
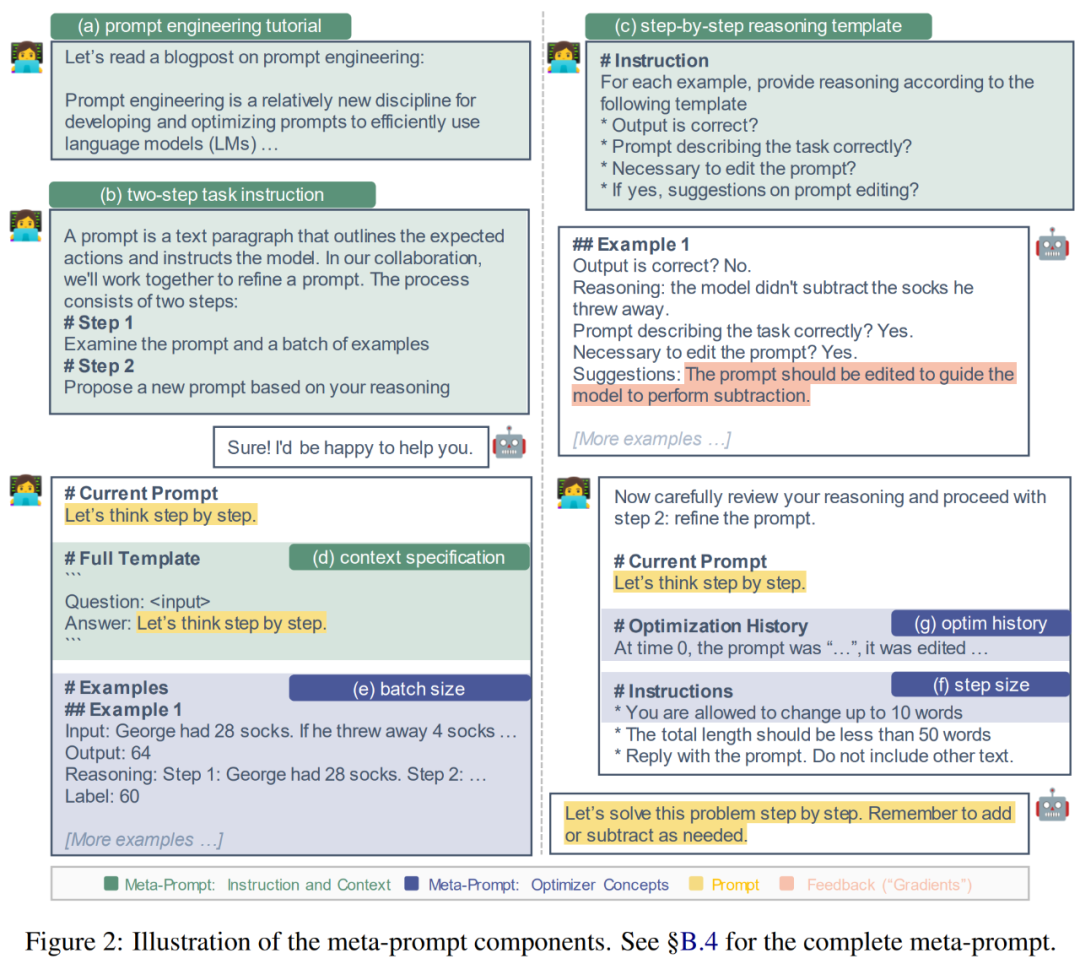
詳細な手順とコンテキストを提供します。以前の研究では、メタキューは、提案されたモデルにプロンプトの言い換えを生成するように指示するか、サンプルのバッチを調べることに関する最小限の指示を含めていました。したがって、追加の指示とコンテキストをメタキューに追加すると有益な場合があります。
(a) プロンプト エンジニアリング チュートリアル。 LLM がプロンプト エンジニアリングのタスクをよりよく理解できるように、研究者は Meta-Click でプロンプト エンジニアリングに関するオンライン チュートリアルを提供しています。
(b) 2 段階のタスクの説明。プロンプト エンジニアリング タスクは、Pryzant らによって行われたように 2 つのステップに分解できます。最初のステップでは、モデルは現在のプロンプトとサンプルのバッチを検査する必要があります。 2 番目のステップでは、モデルは改善されたプロンプトを構築する必要があります。ただし、Pryzant らのアプローチでは、各ステップがその場で説明されます。代わりに、研究者らはメタキューのこれら 2 つのステップを明確にし、事前に期待を伝えることを検討しました。
(c) ステップバイステップの推論テンプレート。モデルがバッチ B の各例を注意深く調べ、現在のプロンプトの制限を熟考することを促すために、プロンプト提案モデル M_proposal が一連の質問に答えるようにガイドしました。例: 出力は正しいですか?プロンプトはタスクを正しく説明していますか?プロンプトを編集する必要がありますか?
(d) コンテキストの仕様。実際には、入力シーケンス全体でヒントを挿入する場所には柔軟性があります。 「英語をフランス語に翻訳する」など、テキストを入力する前にタスクを説明できます。また、「ステップバイステップで考える」などのテキストを入力した後に表示され、推論スキルをトリガーすることもできます。これらのさまざまなコンテキストを認識するために、研究者はキューと入力の間の相互作用を明示的に指定します。例: 「Q: A: ステップごとに考えます。」
一般的なオプティマイザーの概念を組み込みます。式 1 で前述したキュー エンジニアリング問題は本質的に最適化問題ですが、式 2 のキュー提案は最適化ステップを受けているとみなすことができます。したがって、研究者は、勾配ベースの最適化で一般的に使用される次の概念を検討し、メタキューで使用するための対応する概念を開発します。
(e) バッチサイズ。バッチ サイズは、各ヒント提案ステップで使用される (失敗した) サンプルの数です (式 2)。著者らは分析でバッチ サイズ {1、2、4、8} を試しました。
(f) ステップ サイズ。勾配ベースの最適化では、ステップ サイズによってモデルの重みがどの程度更新されるかが決まります。プロンプト プロジェクトでは、これに相当するのは、変更できる単語 (トークン) の数です。作成者は、「元のプロンプトでは最大 s 個の単語を変更できます」と直接指定しています。ここで、s ∈ {5, 10, 15, None} です。
(g) 履歴と勢いを最適化します。 Momentum (Qian、1999) は、過去の勾配の移動平均を維持することで最適化を高速化し、振動を回避する手法です。言語的にモメンタムに相当するものを開発するために、この文書には、過去のすべてのプロンプト (タイムスタンプ 0、1、...、t − 1)、開発セットでのパフォーマンス、およびプロンプトの編集の概要が含まれています。
実験
著者は、次の 4 つのタスク セットを使用して、PE2 の有効性と限界を評価します:
1. 数学的推論、2.指示の誘導、3. 反事実の評価、4. 生産プロンプト。
ベンチマークが改善され、LLM が更新されました。表 2 の最初の 2 つの部分では、著者らは TEXT-DAVINCI-003 を使用することで大幅なパフォーマンスの向上を観察しています。これは、TEXT-DAVINCI-003 の方がゼロショット CoT の数学的推論の問題を解決する能力が高いことを示しています。さらに、2 つのキュー間のギャップが減少し (MultiArith: 3.3% → 1.0%、GSM8K: 2.3% → 0.6%)、キュー解釈に対する TEXT-DAVINCI-003 の感度の低下を示しています。このため、反復 APE などの単純な言い換えに依存する手法は、最終結果を改善するのに効果的ではない可能性があります。パフォーマンスを向上させるには、より正確で的を絞ったプロンプト編集が必要です。
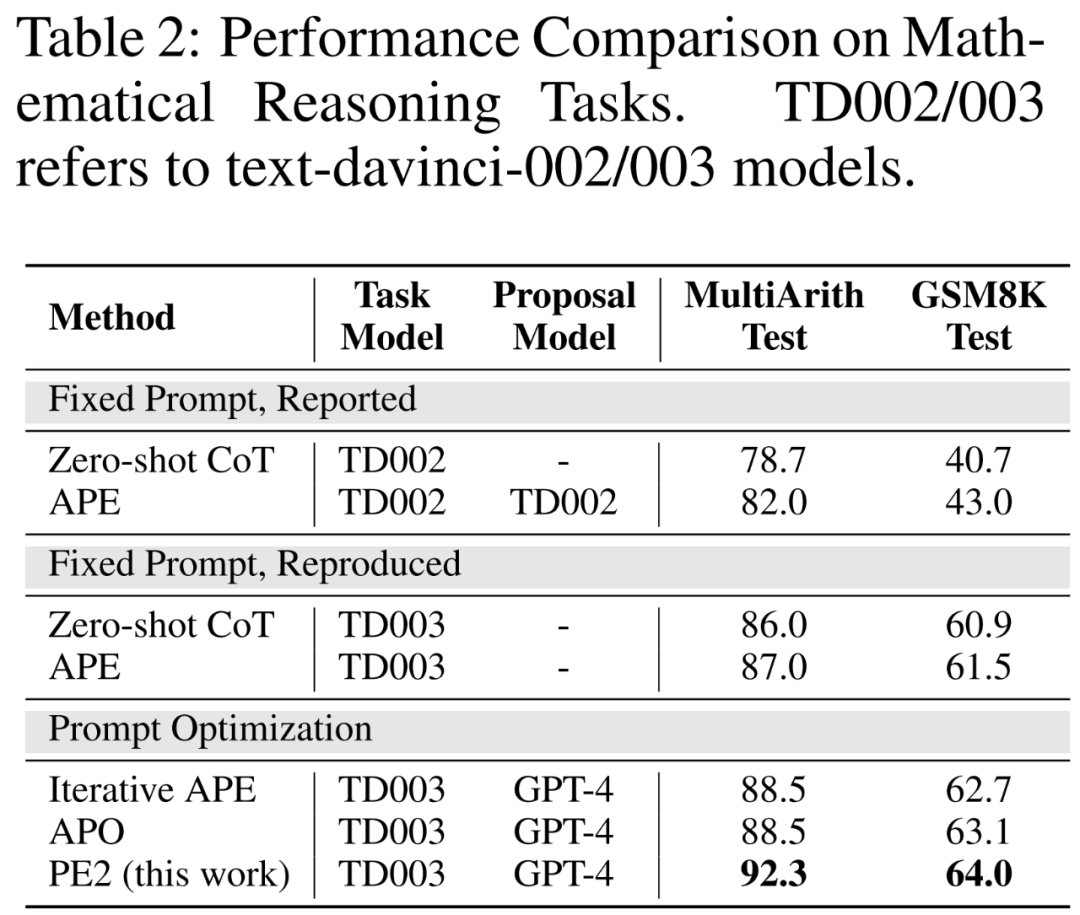
#PE2 は、さまざまなタスクにおいて反復 APE および APO よりも優れたパフォーマンスを発揮します。 PE2 は、MultiArith では 92.3% (Zero-shot CoT より 6.3% 優れています)、GSM8K では 64.0% (3.1%) の精度でチップを見つけることができます。さらに、PE2 は、指示誘導ベンチマーク、反事実評価、および生産キューにおいて、反復 APE および APO を上回るパフォーマンスを示すキューを発見しました。
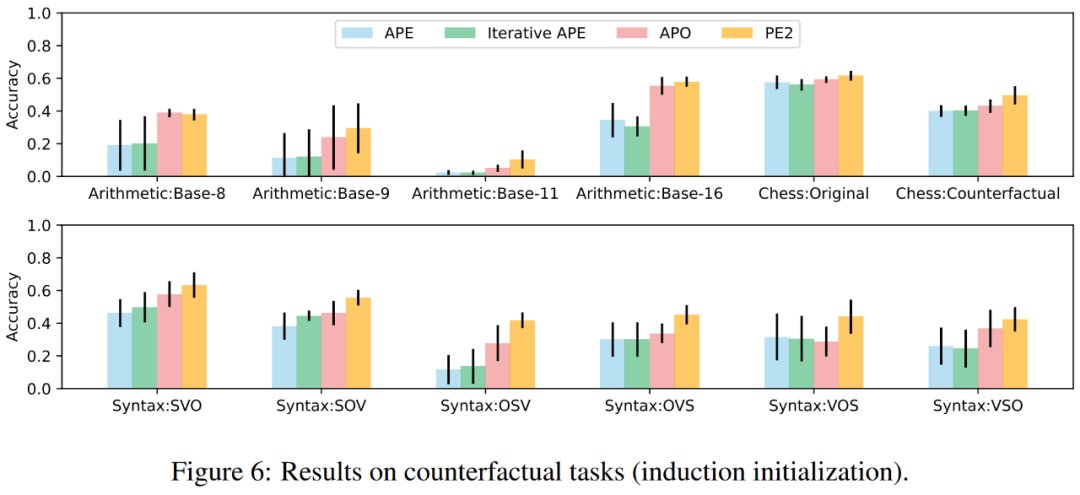
上の図 1 では、著者は、命令誘導ベンチマーク、反事実評価、および生成プロンプトに関して PE2 によって達成されたパフォーマンスの向上を要約しており、PE2 がさまざまな言語タスクで優れたパフォーマンスを達成していることを示しています。特に、帰納的初期化を使用した場合、PE2 は 12 の反事実タスク中 11 で APO を上回り (図 6 を参照)、PE2 が逆説的および反事実の状況を推論する能力を示しています。
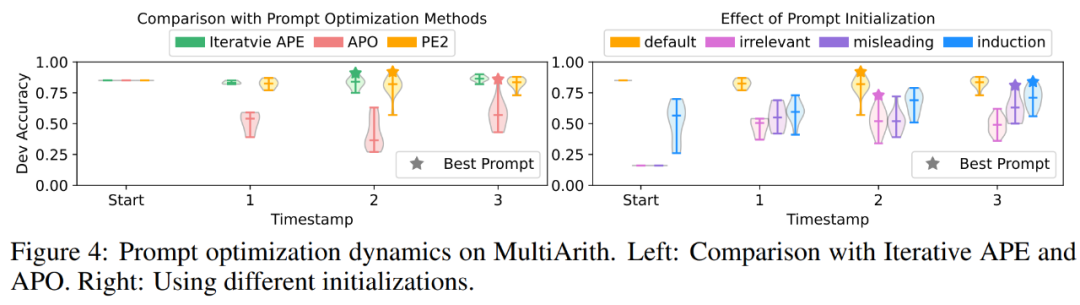
PE2 は、ターゲットを絞ったプロンプト編集と高品質のプロンプトを生成します。図 4(a) では、著者らはキューの最適化プロセス中のキュー提案の品質をプロットしています。実験では、3 つのキュー最適化手法全体で非常に明確なパターンが観察されました。反復 APE は言い換えに基づいているため、新しく生成されたキューの分散は小さくなります。 APO では大幅なプロンプト編集が行われるため、最初のステップでパフォーマンスが低下します。 PE2 は 3 つの方法の中で最も安定しています。表 3 に、著者はこれらの方法で見つかった最良のヒントをリストしています。 APO と PE2 は両方とも、「すべての部分/詳細を考慮する」指示を提供できます。さらに、PE2 はバッチを精査するように設計されており、単純な言い換え編集を超えて、「必要に応じて追加または削除を忘れないでください」などの非常に具体的なプロンプト編集まで行うことができます。
詳細については、元の論文を参照してください。
以上が「一歩ずつ考えていきましょう」というマントラよりも効果的で、プロジェクトが改善されつつあることを思い出させてくれます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7535
7535
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 人工知能の開発プロセスにおいて、大規模言語モデル (LLM) の制御とガイダンスは常に中心的な課題の 1 つであり、これらのモデルが両方とも確実に機能することを目指しています。強力かつ安全に人類社会に貢献します。初期の取り組みは人間のフィードバックによる強化学習手法に焦点を当てていました (RL
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 最初の Mamba ベースの MLLM が登場しました!モデルの重み、トレーニング コードなどはすべてオープンソースです
Jul 17, 2024 am 02:46 AM
最初の Mamba ベースの MLLM が登場しました!モデルの重み、トレーニング コードなどはすべてオープンソースです
Jul 17, 2024 am 02:46 AM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。はじめに 近年、さまざまな分野でマルチモーダル大規模言語モデル (MLLM) の適用が目覚ましい成功を収めています。ただし、多くの下流タスクの基本モデルとして、現在の MLLM はよく知られた Transformer ネットワークで構成されています。
