

RoboFusion による SAM を使用した信頼性の高いマルチモーダル 3D 検出

論文リンク: https://arxiv.org/pdf/2401.03907.pdf
マルチモーダル 3D 検出器は、安全で信頼性の高い自動運転認識システムを研究するために設計されています。クリーンなベンチマーク データセットでは最先端のパフォーマンスを実現しますが、現実世界の環境の複雑さと過酷な条件は無視されることがよくあります。同時に、ビジュアルベーシックモデル (VFM) の出現により、マルチモーダル 3D 検出の堅牢性と汎用化機能の向上は、自動運転における機会と課題に直面しています。したがって、著者らは、SAM のような VFM を活用して配布外 (OOD) ノイズ シナリオに対処する RoboFusion フレームワークを提案します。
まず、元の SAM を SAM-AD という名前の自動運転シナリオに適用します。 SAM または SAMAD をマルチモーダル手法と連携させるために、SAM によって抽出された画像特徴をアップサンプリングする AD-FPN を導入します。ノイズと天候による干渉をさらに低減するために、ウェーブレット分解を使用して深度ガイド画像のノイズを除去します。最後に、セルフ アテンション メカニズムを使用して、融合された特徴を適応的に再重み付けし、過剰なノイズを抑制しながら有益な特徴を強化します。 RoboFusion は、VFM の汎用性と堅牢性を活用してノイズを徐々に低減することで、マルチモーダル 3D オブジェクト検出の回復力を強化します。その結果、KITTIC および nuScenes-C ベンチマークの結果によると、RoboFusion はノイズの多いシーンでも最先端のパフォーマンスを実現します。
この論文では、SAM のような VFM を利用して、3D マルチモーダルオブジェクト検出器をクリーンなシーンから OOD ノイズの多いシーンまで適応させる、RoboFusion という名前の堅牢なフレームワークを提案しています。中でも鍵となるのはSAMの適応戦略だ。
1) セグメンテーション結果を推測する代わりに、SAM から抽出された特徴を使用します。
2) SAM-AD が提案されています。これは、AD シナリオ用の事前トレーニングされた SAM です。
3) 新しい AD-FPN は、VFM をマルチモーダル 3D 検出器と調整するためのフィーチャー アップサンプリングの問題を解決するために導入されました。
ノイズ干渉を軽減し、信号特性を維持するために、高周波ノイズと低周波ノイズを効果的に減衰させるディープ ガイド ウェーブレット アテンション (DGWA) モジュールが導入されています。
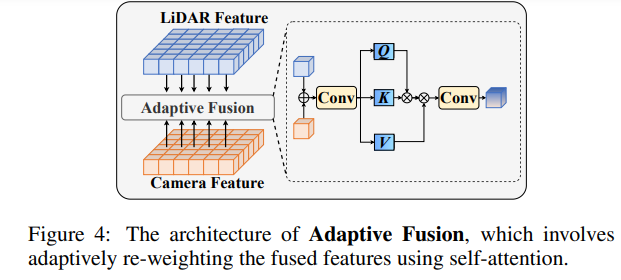
点群特徴と画像特徴を融合した後、適応融合を通じて特徴を再重み付けして、特徴の堅牢性とノイズ耐性を強化します。
RoboFusion ネットワーク構造
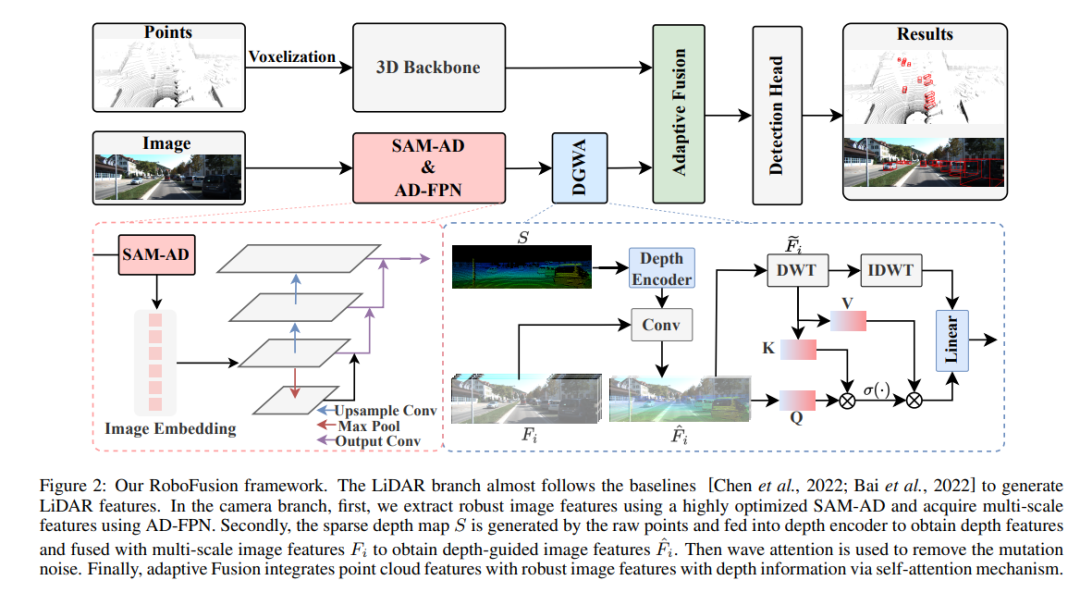
RoboFusion フレームワークを以下に示します。その LIDAR ブランチはベースラインに従っています [Chen et al., 2022; Bai et al., 2022]レーザー光レーダーシグネチャを生成します。カメラ ブランチでは、高度に最適化された SAM-AD アルゴリズムを最初に使用して堅牢な画像特徴を抽出し、AD-FPN と組み合わせてマルチスケール特徴を取得します。次に、元の点を使用して疎な深度マップ S が生成されます。このマップは深度エンコーダに入力されて深度特徴が取得され、マルチスケール画像特徴と融合されて深度ガイド付き画像特徴が取得されます。次に、変動する注意メカニズムを通じて突然変異ノイズが除去されます。最後に、適応型融合は、点群特徴と深度情報を備えた堅牢な画像特徴を組み合わせるセルフ アテンション メカニズムを通じて実現されます。
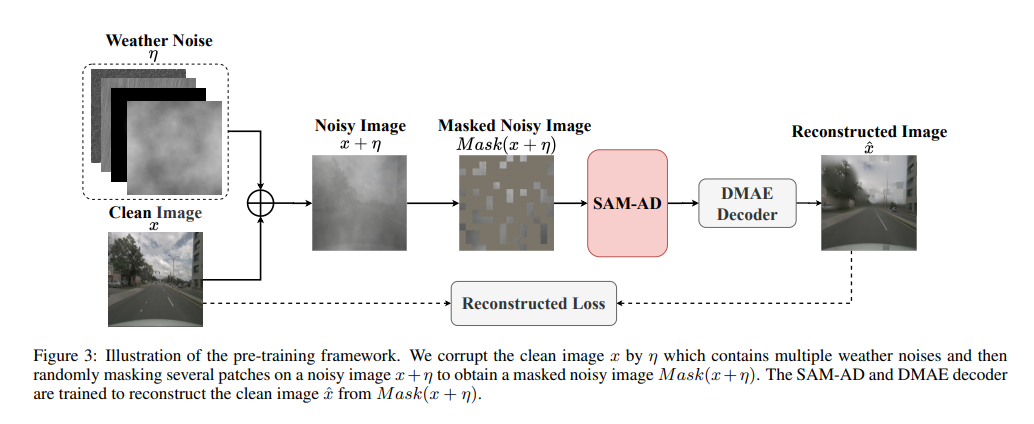
SAM-AD: SAM を AD (自動運転) シナリオにさらに適応させるために、SAM は SAM-AD を取得するように事前トレーニングされています。具体的には、成熟したデータセット (KITTI や nuScenes) から多数の画像サンプルを収集して、基本的な AD データセットを形成します。 DMAE の後、図 3 に示すように、AD シナリオで SAM-AD を取得するために SAM が事前トレーニングされます。 x を AD データセット (つまり、KITTI と nuScenes) からのクリーンな画像として示し、eta を x に基づいて生成されたノイズのある画像として示します。騒音の種類と重大度は、それぞれ 4 つの気象条件 (雨、雪、霧、晴天) と 1 ~ 5 の 5 つの重大度レベルからランダムに選択されました。 MobileSAM の画像エンコーダである SAM をエンコーダとして使用しますが、デコーダと再構成の損失は DMAE と同じです。
AD-FPN。キュー可能なセグメンテーション モデルとして、SAM はイメージ エンコーダ、キュー エンコーダ、マスク デコーダの 3 つの部分で構成されます。一般に、画像エンコーダを一般化して VFM をトレーニングしてからデコーダをトレーニングする必要があります。言い換えれば、画像エンコーダーは下流モデルに高品質で非常に堅牢な画像埋め込みを提供できますが、マスク デコーダーはセマンティック セグメンテーションのデコード サービスのみを提供するように設計されています。さらに、私たちが必要としているのは、キュー エンコーダーによるキュー情報の処理ではなく、堅牢な画像特徴です。したがって、SAM の画像エンコーダを使用して、堅牢な画像特徴を抽出します。ただし、SAMでは画像エンコーダとしてViTシリーズを採用しており、マルチスケール機能を排除し、高次元の低解像度機能のみを提供しています。 [Li et al., 2022a] に触発されて、ターゲット検出に必要なマルチスケール特徴を生成するために、ViT! に基づいたマルチスケール特徴を提供する AD-FPN が設計されています。
SAM-AD または SAM が堅牢な画像特徴を抽出できるにもかかわらず、2D ドメインと 3D ドメインの間にはギャップが依然として存在しており、損傷した環境で幾何学的な情報が不足しているカメラでは、ノイズが増幅され、マイナスの転送問題が発生することがよくあります。この問題を軽減するために、我々はディープ ガイド付きウェーブレット アテンション (DGWA) モジュールを提案します。これは次の 2 つのステップに分割できます。 1) 深度ガイダンス ネットワークは、画像特徴と点群の深度特徴を組み合わせることにより、画像特徴の前にジオメトリを追加するように設計されています。 2) Haar ウェーブレット変換を使用して、画像の特徴を 4 つのサブバンドに分解します。その後、アテンション メカニズムにより、サブバンド内の情報特徴のノイズを除去できます。
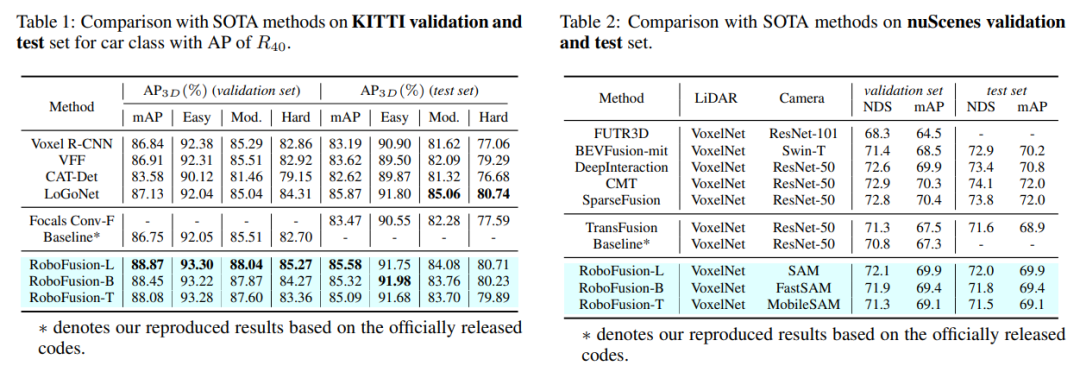
#実験による比較
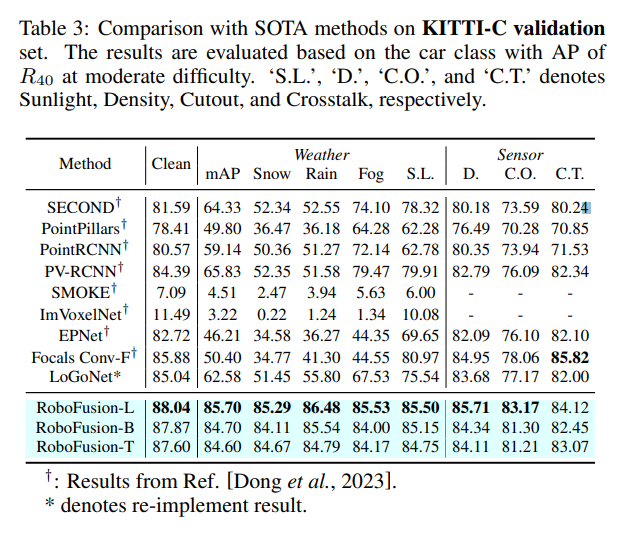
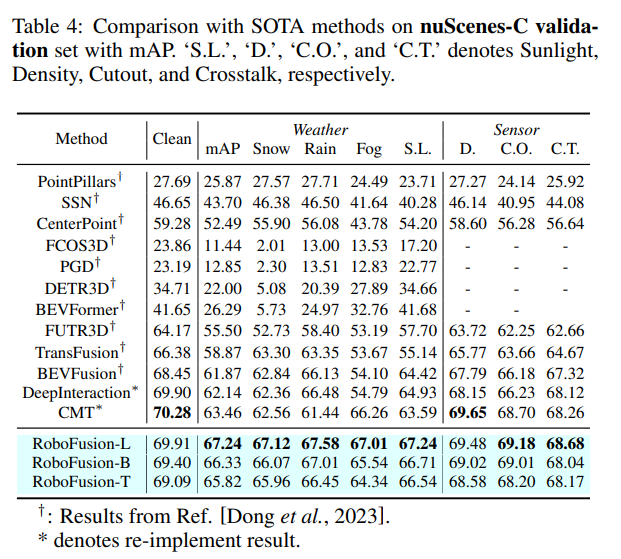
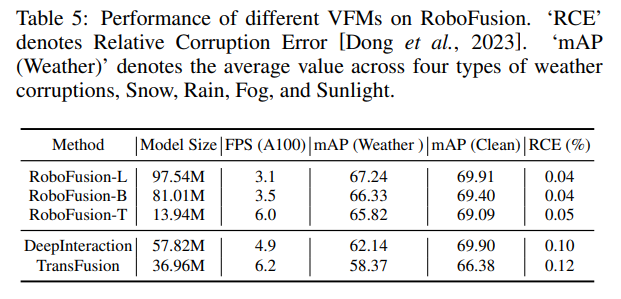

 #元のリンク: https://mp.weixin.qq.com/s/78y1KyipHeUSh5sLQZy-ng
#元のリンク: https://mp.weixin.qq.com/s/78y1KyipHeUSh5sLQZy-ng
以上がRoboFusion による SAM を使用した信頼性の高いマルチモーダル 3D 検出の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートのコスト/パフォーマンスを評価するには、次の手順が必要です。 必要な保証レベルとサービス レベル アグリーメント (SLA) 保証を決定します。研究サポートチームの経験と専門知識。アップグレード、トラブルシューティング、パフォーマンスの最適化などの追加サービスを検討してください。ビジネス サポートのコストと、リスクの軽減と効率の向上を比較検討します。
 PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は、言語熟練度、フレームワークの複雑さ、ドキュメントの品質、コミュニティのサポートによって異なります。 PHP フレームワークの学習曲線は、Python フレームワークと比較すると高く、Ruby フレームワークと比較すると低くなります。 Java フレームワークと比較すると、PHP フレームワークの学習曲線は中程度ですが、開始までの時間は短くなります。
 PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
PHP フレームワークの軽量オプションはアプリケーションのパフォーマンスにどのような影響を与えますか?
Jun 06, 2024 am 10:53 AM
軽量の PHP フレームワークは、サイズが小さくリソース消費が少ないため、アプリケーションのパフォーマンスが向上します。その特徴には、小型、高速起動、低メモリ使用量、改善された応答速度とスループット、および削減されたリソース消費が含まれます。 実際のケース: SlimFramework は、わずか 500 KB、高い応答性と高スループットの REST API を作成します。
 RedMagic Tablet 3D Explorer Edition はメガネ不要の 3D ディスプレイを備えています
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition はメガネ不要の 3D ディスプレイを備えています
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition は、Gaming Tablet Pro と同時に発売されました。ただし、後者はゲーマー向けであるのに対し、前者はエンターテイメント向けです。新しい Android タブレットには、同社が「裸眼 3D&qu」と呼ぶ機能が搭載されています。
 Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
Golang フレームワークのドキュメントのベスト プラクティス
Jun 04, 2024 pm 05:00 PM
明確で包括的なドキュメントを作成することは、Golang フレームワークにとって非常に重要です。ベスト プラクティスには、Google の Go コーディング スタイル ガイドなど、確立されたドキュメント スタイルに従うことが含まれます。見出し、小見出し、リストなどの明確な組織構造を使用し、ナビゲーションを提供します。スタート ガイド、API リファレンス、概念など、包括的で正確な情報を提供します。コード例を使用して、概念と使用法を説明します。ドキュメントを常に最新の状態に保ち、変更を追跡し、新機能を文書化します。 GitHub の問題やフォーラムなどのサポートとコミュニティ リソースを提供します。 API ドキュメントなどの実践的なサンプルを作成します。
 さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
さまざまなアプリケーションシナリオに最適な Golang フレームワークを選択する方法
Jun 05, 2024 pm 04:05 PM
アプリケーションのシナリオに基づいて最適な Go フレームワークを選択します。アプリケーションの種類、言語機能、パフォーマンス要件、エコシステムを考慮します。一般的な Go フレームワーク: Jin (Web アプリケーション)、Echo (Web サービス)、Fiber (高スループット)、gorm (ORM)、fasthttp (速度)。実際のケース: REST API (Fiber) の構築とデータベース (gorm) との対話。フレームワークを選択します。主要なパフォーマンスには fasthttp、柔軟な Web アプリケーションには Jin/Echo、データベース インタラクションには gorm を選択してください。
 golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
golang フレームワーク開発の実践的な詳細な説明: 質疑応答
Jun 06, 2024 am 10:57 AM
Go フレームワーク開発における一般的な課題とその解決策は次のとおりです。 エラー処理: 管理にはエラー パッケージを使用し、エラーを一元的に処理するにはミドルウェアを使用します。認証と認可: サードパーティのライブラリを統合し、資格情報を確認するためのカスタム ミドルウェアを作成します。同時処理: ゴルーチン、ミューテックス、チャネルを使用してリソース アクセスを制御します。単体テスト: 分離のために getest パッケージ、モック、スタブを使用し、十分性を確保するためにコード カバレッジ ツールを使用します。デプロイメントとモニタリング: Docker コンテナを使用してデプロイメントをパッケージ化し、データのバックアップをセットアップし、ログ記録およびモニタリング ツールでパフォーマンスとエラーを追跡します。
 Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Golang フレームワークの学習プロセスでよくある誤解は何ですか?
Jun 05, 2024 pm 09:59 PM
Go フレームワークの学習には、フレームワークへの過度の依存と柔軟性の制限という 5 つの誤解があります。フレームワークの規則に従わない場合、コードの保守が困難になります。古いライブラリを使用すると、セキュリティと互換性の問題が発生する可能性があります。パッケージを過度に使用すると、コード構造が難読化されます。エラー処理を無視すると、予期しない動作やクラッシュが発生します。
