

Transformer での位置エンコーディングの適用: 長さの外挿の無限の可能性を探る

自然言語処理の分野では、その優れたシーケンスモデリング性能により、Transformer モデルが注目を集めています。ただし、トレーニング中のコンテキストの長さには制限があるため、この長さの制限を超えるシーケンスを効果的に処理することはできません。これは、「有効長の外挿」機能の欠如と呼ばれます。その結果、長いテキストを処理するときに大規模な言語モデルのパフォーマンスが低下したり、処理できなくなったりすることがあります。この問題を解決するために、研究者はトランケーション法、セグメント化法、階層化法などの一連の方法を提案しています。これらの方法は、いくつかのトリックを通じてモデルの実効長の外挿機能を向上させ、非常に長いシーケンスをより適切に処理できるようにすることを目的としています。これらの方法はこの問題をある程度軽減しますが、実際のアプリケーション シナリオのニーズによりよく適応するために、モデルの有効長の外挿能力をさらに向上させるには、さらなる研究がまだ必要です。
テキストの継続と言語の拡張は、人間の言語能力の重要な側面の 1 つです。大規模モデルの時代では、モデルの機能を長いシーケンス データに効果的に適用するために、長さの外挿が重要な方法になりました。この問題に関する研究には理論的かつ実践的な価値があるため、関連する研究が次々と生まれています。同時に、この分野の概要を提供し、言語モデルの境界を継続的に拡大するために、体系的なレビューも必要です。
ハルビン工業大学の研究者は、位置エンコーディングの観点から長さの外挿における変圧器モデルの研究の進捗状況を体系的にレビューしました。研究者は主に、Transformer モデルの長さの外挿機能を強化するために、外挿可能な位置コードとこれらのコードに基づく拡張方法に焦点を当てています。

論文リンク: https://arxiv.org/abs/2312.17044
推定可能位置エンコーディング
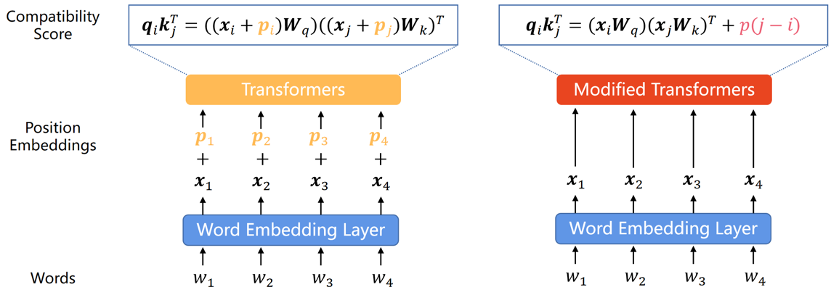
Transformer モデル自体はシーケンス内の各単語の位置情報を取得できないため、位置エンコーディングがそれを追加する一般的な方法となっています。位置エンコードは、絶対位置エンコードと相対位置エンコードの 2 種類に分類できます。絶対位置エンコーディングでは、入力シーケンス内の各単語に位置ベクトルを追加して、シーケンス内の単語の絶対位置情報を表します。相対位置エンコーディングは、異なる位置にある単語の各ペア間の相対距離をエンコードします。どちらのエンコード方法でも、シーケンス内の要素の順序情報を Transformer モデルに統合して、モデルのパフォーマンスを向上させることができます。
既存の研究では、この分類がモデルの外挿能力にとって重要であることが示されているため、この分類に従ってこのセクションを分割します。
絶対位置エンコーディング
元の Transformer 論文では、位置エンコーディングはサイン関数とコサイン関数によって生成されます。この方法は、Transformer の最初の PE として十分に外挿できないことが証明されていますが、sine APE は後続の PE に大きな影響を与えます。
Transformer モデルの外挿機能を強化するために、研究者は、ランダムな変位を通じて正弦波 APE に変位の不変性を組み込むか、位置に応じて滑らかに変化する位置の埋め込みを生成し、モデルが推論を学習することを期待します。この変更機能。これらのアイデアに基づく方法は、正弦波 APE よりも強力な外挿機能を示しますが、それでも RPE のレベルには到達できません。理由の 1 つは、APE がさまざまな位置をさまざまな位置エンベディングにマッピングするためであり、外挿とは、モデルが目に見えない位置エンベディングを推論する必要があることを意味します。ただし、モデルにとってこれは困難な作業です。特に LLM の場合、大規模な事前トレーニング中に繰り返される位置埋め込みの数が限られているため、モデルはこれらの位置エンコーディングに対する過剰適合の影響を非常に受けやすくなります。
相対位置エンコーディング
長さの外挿における APE のパフォーマンスは満足のいくものではありませんが、RPE は当然、Ground の方が優れた外挿機能を備えているためです。変位不変性のため、一般的には文脈内での単語の相対的な順序の方が重要であると考えられています。近年、位置情報を符号化する方式としてはRPEが主流となっている。
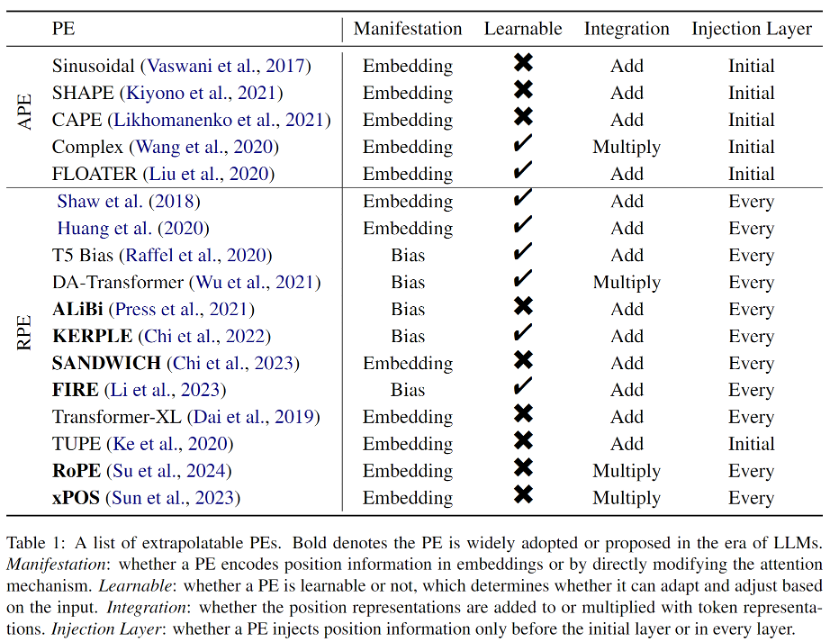
初期の RPE は、正弦波位置エンコーディングへの単純な変更から生まれました。多くの場合、分布外の位置の埋め込みを回避するための枝刈りまたはビニング戦略と組み合わせられ、外挿が容易になると考えられていました。さらに、RPE は位置と位置表現の間の 1 対 1 の対応を切り離すため、バイアス項をアテンション式に直接追加することは、位置情報を Transformer に統合するための実現可能な、またはさらに優れた方法になります。このアプローチははるかに単純で、値ベクトルと位置情報のもつれが自然に解消されます。ただし、これらのバイアス方法には強力な外挿特性がありますが、RoPE (Rotary Position Embedding) のような複雑な距離関数を表すことはできません。したがって、RoPE は外挿には劣りますが、その優れた総合性能により、最近では LLM の最も主流の位置符号化となっています。この論文で紹介されているすべての外挿可能な PE を表 1 に示します。
大型モデル時代の外挿法
モデルの長さの外挿能力を高めるために、 LLM、研究 研究者は、既存の位置エンコーディングに基づいて、主に位置補間 (Position Interpolation) とランダム化位置エンコーディング (Randomized Position Encoding) の 2 つのカテゴリに分類されるさまざまな方法を提案してきました。
#位置補間メソッド
位置補間メソッドは、推論中に位置エンコーディングをスケーリングするため、そうでない場合は、モデル トレーニング長の位置エンコーディングは、トレーニングされた位置間隔に収まるように補間されます。位置補間法は、その優れた外挿パフォーマンスと極めて低いオーバーヘッドにより、研究コミュニティから幅広い関心を集めています。さらに、他の外挿方法とは異なり、位置補間方法は、Code Llama、Qwen-7B、Llama2 などのオープン ソース モデルで広く使用されています。ただし、現在の補間方法は RoPE のみに焦点を当てており、他の PE を使用する LLM に補間によるより優れた外挿機能を持たせる方法はまだ検討する必要があります。
ランダム化位置エンコーディング
# 簡単に言うと、PE のランダム化は、トレーニング中にランダムな位置を導入するだけです。 - より長い推論長からトレーニングされたコンテキスト ウィンドウにより、より長いコンテキスト ウィンドウでのすべての位置の露出が向上します。ランダム化 PE の考え方は位置補間法とは大きく異なることに注意してください。前者はトレーニング中にモデルにすべての可能な位置を観察させることを目的としていますが、後者は推論中に位置を補間して、次の位置に該当するようにしようとします。あらかじめ決められた場所。同じ理由で、位置補間方法はほとんどがプラグ アンド プレイですが、ランダム化 PE ではさらに微調整が必要になることが多く、これにより位置補間がより魅力的になります。ただし、これら 2 つのカテゴリの方法は相互に排他的ではないため、これらを組み合わせてモデルの外挿機能をさらに強化することができます。
課題と今後の方向性
評価およびベンチマーク データセット: 初期の研究では、 Transformer の外挿能力の評価は、機械翻訳の BLEU など、さまざまな下流タスクのパフォーマンス評価指標から得られますが、T5 や GPT2 などの言語モデルが徐々に自然言語処理タスクを統合するにつれて、言語モデリングで使用される複雑さが外挿の基礎になります。評価指標。しかし、最新の研究では、複雑さによって下流のタスクのパフォーマンスを明らかにできないことが示されているため、長さの外挿の分野でさらなる開発を促進するには、専用のベンチマーク データ セットと評価メトリクスが緊急に必要とされています。
理論的説明: 長さの外挿に関連する現在の研究はほとんどが経験に基づくものですが、説明モデルによる外挿に成功した予備的な例がいくつかあります。さまざまな試みが行われていますが、確固たる理論的基盤はまだ確立されておらず、正確にどのような要因が長さの外挿パフォーマンスにどのように影響するかは未解決の問題のままです。
その他の方法: この記事で説明したように、既存の長さの外挿作業のほとんどは位置エンコーディングの観点に焦点を当てていますが、長さの外挿には体系的な設計が必要であることを理解するのは難しくありません。位置エンコーディングは重要なコンポーネントですが、決して唯一のものではなく、より広い視野で見ると問題がさらに深刻になります。
以上がTransformer での位置エンコーディングの適用: 長さの外挿の無限の可能性を探るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7540
7540
 15
1381
52
83
11
21
86
15
1381
52
83
11
21
86

 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debianシステムでのデジタル署名検証にOpenSSLを使用すると、次の手順に従うことができます。OpenSSL:Debianシステムがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoaptupdatesudoaptinInstallopensslslに公開キーを取得できます。デジタル署名検証には、署名者の公開キーが必要です。通常、公開キーは、public_key.peなどのファイルの形で提供されます
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
