

Google、AI によるエラー修正機能の向上を支援する BIG-Bench Mistake データセットを発表

Google Research は最近、独自の BIG-Bench ベンチマークと新しく確立された「BIG-Bench Mistake」データセットを使用して、一般的な言語モデルに関する評価研究を実施しました。彼らは主に、言語モデルのエラー確率とエラー訂正能力に焦点を当てました。この調査は、市場における言語モデルのパフォーマンスをより深く理解するための貴重なデータを提供します。
Googleの研究者らは、大規模な言語モデルの「エラー確率」と「自己修正能力」を評価するために、「BIG-Bench Mistake」と呼ばれる特別なベンチマークデータセットを作成したと発表した。これは、これらの重要な指標を効果的に評価およびテストするための対応するデータセットが過去に欠如していたことが原因です。
研究者らは、PaLM 言語モデルを使用して独自の BIG-Bench ベンチマーク タスクで 5 つのタスクを実行し、生成された「思考連鎖」軌跡を「ロジック エラー」部分に追加しました。モデルの精度を再テストします。
データセットの精度を向上させるために、Google の研究者は上記のプロセスを繰り返し実行し、最終的に「BIG-Bench Mistake」と呼ばれる 255 個の論理エラーを含む評価専用のベンチマーク データセットを作成しました。
研究者らは、「BIG-Bench Mistake」データセットの論理エラーは非常に明白であるため、言語モデルのテストの優れた標準として使用できると指摘しました。このデータセットは、モデルが単純なエラーから学習し、エラーを識別する能力を徐々に向上させるのに役立ちます。
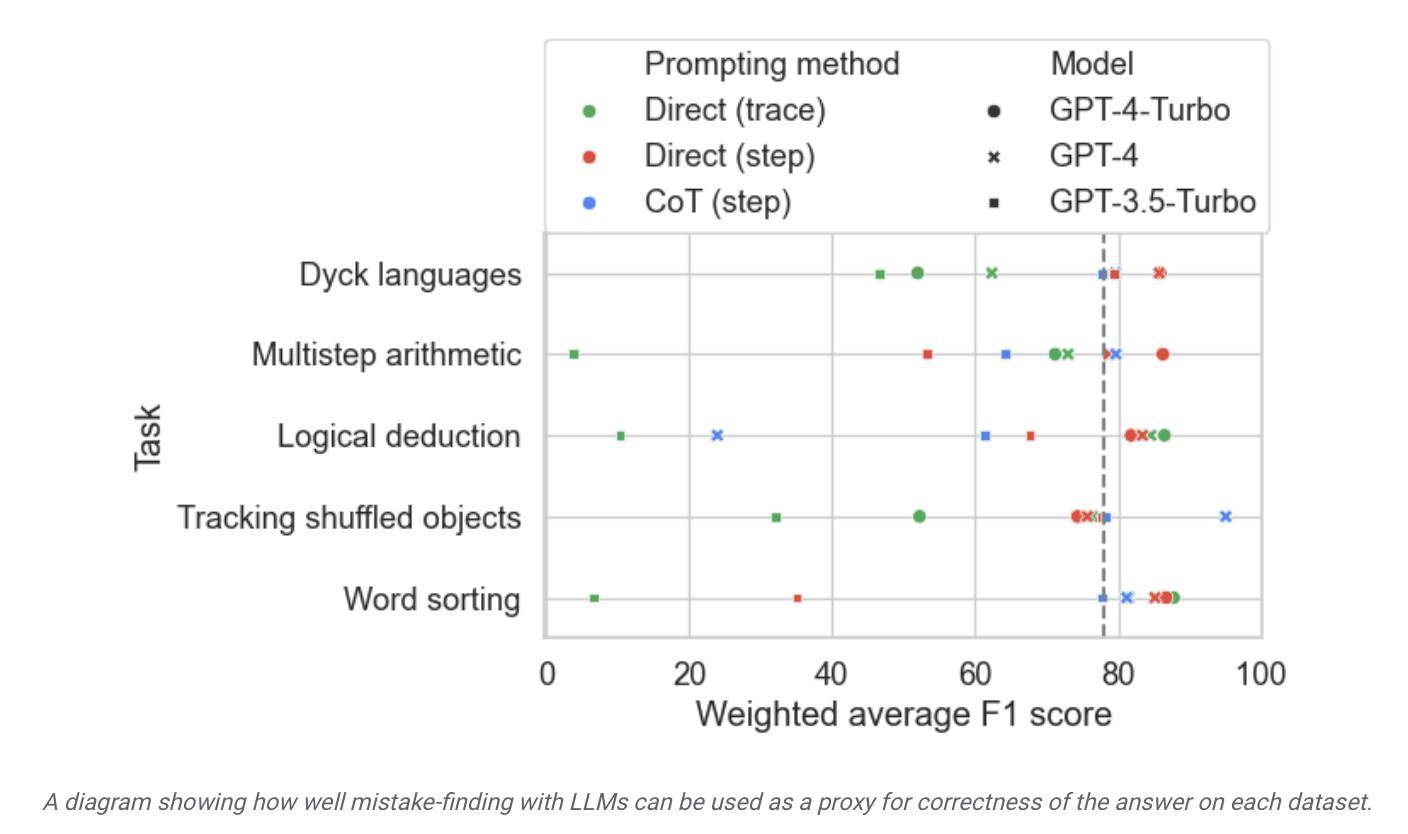
研究者らは、このデータセットを使用して市販のモデルをテストしたところ、ほとんどの言語モデルは推論プロセスの論理エラーを特定して自ら修正できるものの、このプロセスはあまり理想的ではないことがわかりました。多くの場合、モデルの出力を修正するには人間の介入も必要です。
▲ 画像出典 Google Research プレスリリース
レポートによると、Google は、これが現在最も先進的な大規模言語モデルであると考えられているが、その自己修正能力は比較的限られていると主張しています。テストでは、最もパフォーマンスの高いモデルで検出された論理エラーは 52.9% のみでした。

Google 研究者らはまた、この BIG-Bench Mistake データセットはモデルの自己修正能力の向上に役立つと主張しており、関連するテスト タスクでモデルを微調整した後、「小さなモデルであっても、通常はモデルのパフォーマンスよりも優れています」と述べています。サンプルプロンプトがゼロの大きなモデル。「より良い」。
これによると、Google は、モデルのエラー修正に関して、独自の小さなモデルを大規模なモデルの「監視」に使用できると考えています。大規模な言語モデルに「自己エラーの修正」を学習させる代わりに、専用の小さな専用モデルをデプロイします。大規模なモデルを監視することには、効率が向上し、関連する AI 導入コストが削減され、微調整が容易になるという利点があります。
以上がGoogle、AI によるエラー修正機能の向上を支援する BIG-Bench Mistake データセットを発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7333
7333
 9
1627
14
1351
46
1262
25
1209
29
9
1627
14
1351
46
1262
25
1209
29

 モデルコンテキストプロトコル(MCP)とは何ですか?
Mar 03, 2025 pm 07:09 PM
モデルコンテキストプロトコル(MCP)とは何ですか?
Mar 03, 2025 pm 07:09 PM
モデルコンテキストプロトコル(MCP):AIとデータのユニバーサルコネクタ 私たちは皆、毎日のコーディングにおけるAIの役割に精通しています。 Replit、Github Copilot、Black Box AI、およびCursor IDEは、AIがワークフローを合理化する方法のほんの一部です。 しかし、想像してみてください
 Omniparser V2とOmnitoolを使用して地元のビジョンエージェントを構築する
Mar 03, 2025 pm 07:08 PM
Omniparser V2とOmnitoolを使用して地元のビジョンエージェントを構築する
Mar 03, 2025 pm 07:08 PM
MicrosoftのOmniparser V2とOmnitool:AIでGUIオートメーションに革命をもたらす 味付けされた専門家のように、Windows 11インターフェースと相互作用するだけでなく、熟練したプロのように相互作用するAIを想像してください。 MicrosoftのOmniparser V2とOmnitoolはこれを再生します
 レプリットエージェント:実用的な例を備えたガイド
Mar 04, 2025 am 10:52 AM
レプリットエージェント:実用的な例を備えたガイド
Mar 04, 2025 am 10:52 AM
アプリ開発の革新:レプリットエージェントに深く潜ります 複雑な開発環境と不明瞭な構成ファイルとの格闘にうんざりしていませんか? Replit Agentは、アイデアを機能的なアプリに変換するプロセスを簡素化することを目的としています。 このai-p
 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 Runway Act-One Guide:私はそれをテストするために自分自身を撮影しました
Mar 03, 2025 am 09:42 AM
Runway Act-One Guide:私はそれをテストするために自分自身を撮影しました
Mar 03, 2025 am 09:42 AM
このブログ投稿では、Runway MLの新しいAct-One Animationツールの経験をテストし、WebインターフェイスとPython APIの両方をカバーしています。約束しますが、私の結果は予想よりも印象的ではありませんでした。 生成AIを探索したいですか? PでLLMSを使用することを学びます
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 Elon Musk&Sam Altmanは、5,000億ドルを超えるスターゲートプロジェクトを超えて衝突します
Mar 08, 2025 am 11:15 AM
Elon Musk&Sam Altmanは、5,000億ドルを超えるスターゲートプロジェクトを超えて衝突します
Mar 08, 2025 am 11:15 AM
Openai、Softbank、Oracle、Nvidiaなどのハイテク大手に支援され、米国政府が支援する5,000億ドルのStargate AIプロジェクトは、アメリカのAIリーダーシップを固めることを目指しています。 この野心的な仕事は、AIの進歩によって形作られた未来を約束します
