

本稿では、筆者が半年近く悩まされてきた仮想化環境の難解な障害を紹介するが、最終的に判明した障害の原因と修復方法もとんでもないものである。このプロセスが複雑だからではなく、失敗に遭遇したときにビジネスとテクノロジーのバランスを取る方法や検索エンジンの正しい使い方を考える心理的なプロセスを共有するためです。
故障現象当社では、社内テスト段階では安定して動作していた高性能のプロキシ クラスタを運用しておりましたが、正式リリースから半月も経たないうちに、プロキシ サービスを提供するホストが次々と突然クラッシュし、クラスタ上のすべてのサービスが停止してしまいました。ホストが中断される。
障害分析障害が発生すると、ホストが直接クラッシュし、リモートからログインできなくなり、コンピュータ室はオンサイトのキーボード入力に応答します。ホストの syslog が ELK に接続されているため、クラッシュの前後でさまざまな syslog を収集しました。
######エラーログ###### クラッシュしたホストの syslog を確認したところ、マシンがクラッシュする前に次のカーネル エラーが報告されていたことがわかりました。 リーリー これは、カーネルの null ポインターにアクセスするとシステム バグが引き起こされ、その後一連のコール スタック エラーが発生し、最終的にはクラッシュすることを示しています。 障害現象をさらに分析するには、まずこの高性能プロキシ クラスターのアーキテクチャを理解する必要があります。
アーキテクチャの紹介
単一ノードは、10G ネットワーク カードを備えたホスト上で Docker コンテナを実行し、コンテナ内で Haproxy インスタンスを実行します。各ノードとインスタンスの構成情報とビジネス情報はスケジューラ上でホストされます。
特別なことは、ホストが Linux ブリッジを使用して Docker コンテナの IP アドレスを直接設定することです。ホスト自身の外部ネットワーク IP を含むすべての外部サービス IP は、Linux ブリッジに関連付けられます。 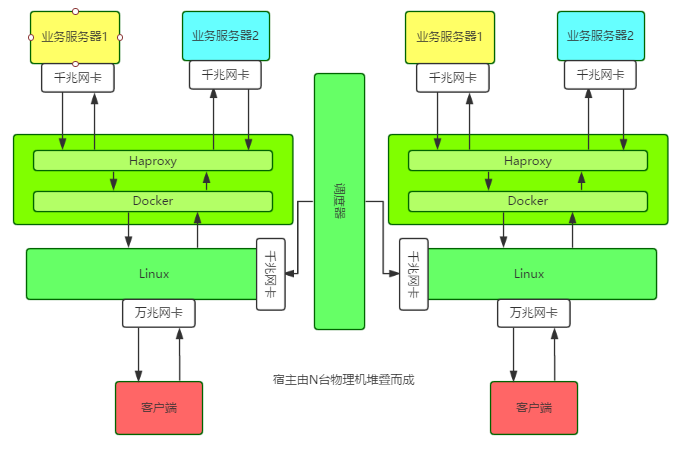
アプリケーションの紹介
各ホストのオペレーティング システム、ハードウェア、および Docker のバージョンはすべて一致しています。オペレーティング システムと Docker のバージョンは次のとおりです: リーリー 初期分析 このクラスターのホスト構成は一貫しており、障害の症状も一貫しています。3 つの疑問があります:
1. Docker のバージョンはホスト カーネルのバージョンと互換性がありません
3 つのホストの環境は元々同じでしたが、1 つのホストはサービスを安定して実行し、2 か月後にクラッシュしました。1 つのホストはサービスを実行しましたが、1 か月後にクラッシュしました。もう 1 つのホストはサービスをオンラインで実行しましたが、1 か月以内にクラッシュしました。週。 クラッシュの異常なログに加えて、各ホストにも同じエラー ログがあることが判明しました: リーリー 上記のヒントによると、オペレーティング システムのカーネル バージョンがこのバージョンの Docker の特定の機能をサポートしていないことが原因であるはずです。ただし、検索エンジンでの検索は Docker の機能には影響せず、システムの安定性にも影響しません。 ###例えば:### リーリー
は Docker 1.9 から存在する問題であり、1.12.3 で修正されました。
リーリー
ただし、ここに記載されているのはバージョン v1.12.2 で修正できる問題のみであり、Docker のバージョンをアップグレードした後もクラッシュが同じであることがわかりました。そこで、様々な Google を通じて私たちと同じ障害現象による問題を多数確認し、障害と Docker の相関関係を最初に確認しました。また、公式の問題に基づいて、Docker のバージョンが互換性がないことも最初に確認しました。システム カーネルのバージョンが異なるため、ダウンタイムが発生する可能性があります。相関関係、その後、公式の変更ログと問題を通じて、ホストで使用されている Docker バージョンがシステム カーネル バージョンと互換性がないことを確認しました。トライアルの精神から、Docker バージョンを次のようにアップグレードしました。 1.12.2でも、事故は発生せずにクラッシュが発生しました。
2. Linux ブリッジを使用してホスト ネットワーク カードを変更すると、バグが発生する可能性があります
一週間サービスを実行するとクラッシュするホストを見つけ、Docker の実行を停止し、ネットワークのみを変更したところ、一週間は安定して動作し、異常は見つかりませんでした。
3. パイプワークを使用して Docker コンテナーの IP を構成すると、バグが発生する可能性があります コンテナに IP を割り当てるときにオープンソースのパイプワーク スクリプトを使用したため、パイプワークの動作原理にバグがあるのではないかと考え、IP アドレスの割り当てにパイプワークを使用しないようにしましたが、ホストが依然として墜落した。
そのため、最初のトラブルシューティングは困難に陥り、少なくとも月に 1 回はホストがクラッシュするのを見て非常にイライラしました。 故障定位
因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
原因:从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri “unable to handle kernel NULL pointer dereference” * arch/tile/mm/fault.c:530: pr_alert(“Unable to handlekernel NULL pointer dereference/n”); arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT “Unable to handle kernel NULL pointerdereference in mna handler”); arch/sparc/mm/fault_32.c:44: “Unable to handle kernel NULL pointer dereference/n”); arch/m68k/mm/fault.c:47: pr_alert(“Unable tohandle kernel NULL pointer dereference”); arch/ia64/mm/fault.c:292: printk(KERN_ALERT “Unable tohandle kernel NULL pointer dereference (address %016lx)/n”, address); debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
故障处理下面是整个故障处理过程中,我们进行的一些操作。
升级操作系统内核对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
/proxy/bin#ls /var/lib/dpkg/info/docker-engine. docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm docker-engine.list docker-engine.postinst docker-engine.preinst #Getthe latest Docker package. $curl -fsSL https://get.docker.com/ | sh #启动 nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
apt-get install docker-engine
然后在早些时候,还有使用下面的安装方式:
apt-get install lxc-docker
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
验证16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15 docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
总结这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质运维要具有预见性、长期规划,而不能仅仅满足于眼前:
この障害に対処する過程で、さまざまな人が Google を使用してさまざまなことを検索していることがわかります。なぜですか?ここが検索エンジンの欠点、あるいは柔軟性の弱点だと思います。この障害に対して、Linux Docker の「カーネル NULL ポインター逆参照を処理できません」を使用して検索しましたが、「カーネル NULL ポインター逆参照を処理できません」を使用した他の結果とは結果が異なりました。理由は、「」を追加すると検索がより正確になるためです。 Googleの正しい開き方について。
以上が半年間悩んでいた問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



