

なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?

前書き&筆者の個人的理解
三次元ガウス スプラッティング (3DGS) は、近年陽光照射野やコンピュータ グラフィックスの分野で登場した革新的な技術です。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3D GS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3D GS は、次世代の 3D 再構築と表現における潜在的な変革をもたらすものとして位置付けられます。この目的を達成するために、私たちは 3D GS 分野における最新の開発と主要な貢献についての初めての体系的な概要を提供します。まず、3D GS の出現に関する基本原理と公式を詳細に検討し、その重要性を理解するための基礎を築きます。次に、3D GS の実用性について詳しく説明します。 3D GS は、リアルタイム パフォーマンスを促進することで、仮想現実からインタラクティブ メディアなどに至るまで、さまざまなアプリケーションの可能性を広げます。さらに、主要な 3D GS モデルの比較分析が実行され、さまざまなベンチマーク タスクで評価され、そのパフォーマンスと実用性が強調されます。このレビューは、現在の課題を特定し、この分野における将来の研究の潜在的な道筋を示唆することで締めくくられています。この調査により、私たちは新人と経験豊富な研究者の両方に貴重なリソースを提供し、放射線分野の適用可能かつ明確な表現におけるさらなる探求と進歩を刺激することを目指しています。
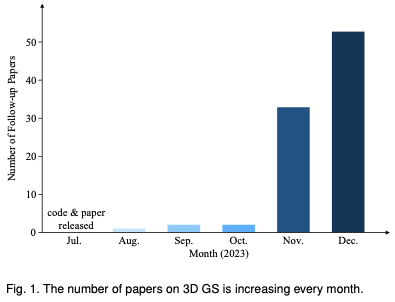
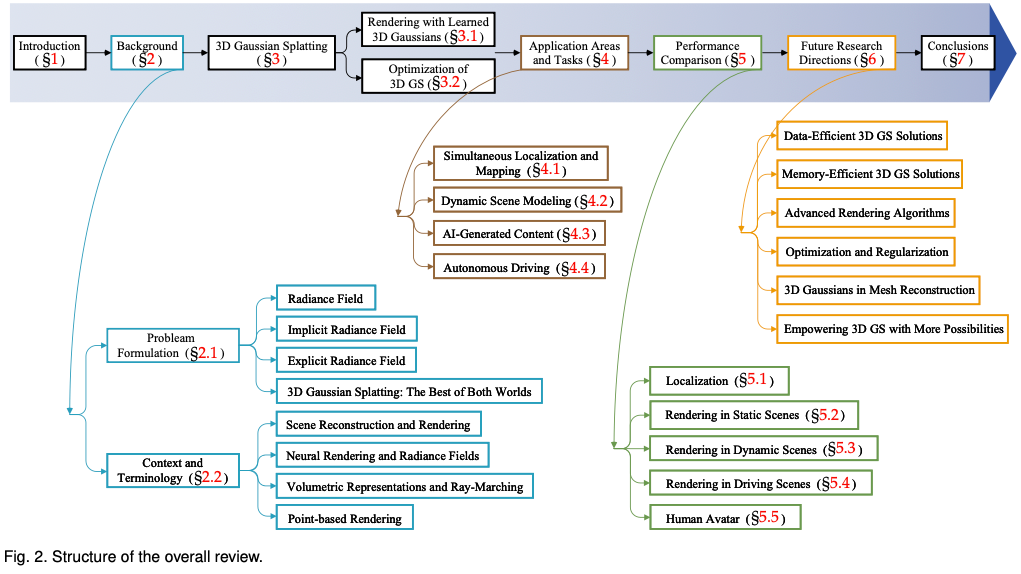
読者が 3D GS の急速な発展についていけるよう、3D GS に関する最初の調査レビューを提供します。私たちは、主に arxiv から、このトピックに関する最も重要な最新の文献を体系的かつタイムリーに収集しました。この記事の目的は、3D GS の初期開発、理論的基礎、および新たなアプリケーションに関する包括的かつ最新の分析を提供し、この分野における革新的な可能性を強調することです。 3D GS は初期ながら急速に進化しているという性質を考慮して、この調査は、この分野における現在の課題と将来の見通しを特定し、議論することも目的としています。現在進行中の研究の方向性と、3D GS が促進する可能性のある進歩についての洞察を提供します。このレビューが学術的知識を提供するだけでなく、この分野のさらなる研究と革新を刺激することが期待されます。 この記事の構成は次のとおりです (図 2)。 すべてのコンテンツは最新の文献や研究結果に基づいており、3D GS に関する包括的かつタイムリーな情報を読者に提供することを目的としていることに注意してください。
#背景の紹介
このセクションでは、シーン レンダリングの重要な概念である放射線場の簡単な式を紹介します。放射線場は 2 つの主なタイプで表すことができます: NeRF などの暗黙的タイプでは、直接的ではあるが計算量の多いレンダリングにニューラル ネットワークを使用します。もう 1 つはメッシュのような明示的タイプで、アクセスは高速ですがメモリの使用量は少なく、離散構造を使用します。次に、シーンの再構成やレンダリングなどの関連領域とのつながりをさらに検討します。問題定義
放射場: 放射場は、3 次元空間における光の分布を表現したものです。環境内の表面およびマテリアルの相互作用と相互作用します。数学的には、放射線場は、空間内の点と球面座標で指定された方向を非負の放射線値にマッピングする関数として説明できます。放射線フィールドは、暗黙的表現または明示的表現によってカプセル化でき、それぞれに特定のシーン表現とレンダリング上の利点があります。
暗黙的放射フィールド:暗黙的放射フィールドは、シーンのジオメトリを明示的に定義せずに、シーン内の光の分布を表します。ディープラーニングの時代では、連続的なボリュームシーン表現を学習するためにニューラルネットワークがよく使用されます。最も顕著な例は NeRF です。 NeRF では、MLP ネットワークを使用して、一連の空間座標と視線方向を色と濃度の値にマッピングします。任意の点の放射輝度は明示的に保存されませんが、ニューラル ネットワークにクエリを実行することによってリアルタイムで計算されます。したがって、この関数は次のように記述できます。
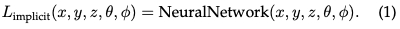
明示的放射フィールド: 対照的に、明示的放射フィールドは、ボクセルのグリッドや点のセットなどの離散空間構造内の光の分布を直接表します。構造内の各要素は、空間内の対応する位置の放射線情報を格納します。このアプローチにより、放射測定データへのより直接的で高速なアクセスが可能になりますが、メモリ使用量が増加し、解像度が低下する可能性があります。明示的な放射線フィールド表現の一般的な形式は次のように記述できます。 DataStructure は、視線方向に基づいて放射を変更する関数であるグリッドまたは点群にすることができます。 両方の長所 3D ガウス スプラッティング : 3D GS は、暗黙的な放射フィールドから明示的な放射フィールドへの移行を表します。柔軟かつ効率的な表現として 3D ガウスを利用することで、両方の方法の利点を活用します。これらのガウス係数は、ニューラル ネットワーク ベースの最適化と明示的な構造化データ ストレージの利点を組み合わせて、シーンを正確に表現できるように最適化されています。このハイブリッド アプローチは、特に複雑なシーンや高解像度の出力において、より高速なトレーニングとリアルタイム パフォーマンスによる高品質のレンダリングを実現することを目的としています。 3D ガウス表現は次のように定式化されます。 シーンの再構成とレンダリング: 大まかに言えば、シーンの再構成には、画像またはその他のデータのコレクションからシーンの 3D モデルを作成することが含まれます。レンダリングは、コンピューター可読情報 (シーン内の 3D オブジェクトなど) をピクセルベースのイメージに変換することに焦点を当てた、より具体的な用語です。初期の技術は、リアルな画像を生成するライト フィールドに基づいていました。 Structure-from-Motion (SfM) およびマルチビュー ステレオ (MVS) アルゴリズムは、画像シーケンスから 3D 構造を推定することでこの分野をさらに進歩させます。これらの歴史的な手法は、より複雑なシーンの再構築およびレンダリング技術の基礎を築きました。 ニューラル レンダリングと放射フィールド: ニューラル レンダリングは、ディープ ラーニングと従来のグラフィックス技術を組み合わせて、フォトリアリスティックな画像を作成します。初期の試みでは、畳み込みニューラル ネットワーク (CNN) を使用して、ハイブリッド ウェイトまたはテクスチャ空間ソリューションを推定しました。放射フィールドは、空間内の各点を通って各方向に進む光の量を記述する関数を表します。 NeRF はニューラル ネットワークを使用して放射線場をモデル化し、詳細で現実的なシーンのレンダリングを可能にします。 ボリューム表現とレイマーチング: ボリューム表現は、ターゲットとシーンをサーフェスとしてだけでなく、マテリアルまたは空のスペースで満たされたボリュームとしてもモデル化します。この方法により、霧、煙、半透明のマテリアルなどの現象をより正確にレンダリングできます。レイ マーチングは、ボリュームを通過する光の経路を段階的に追跡することによってイメージをレンダリングするボリューム表現で使用される手法です。 NeRF は、ボリュメトリック レイ マーチングと同じ精神を共有し、重要なサンプリングと位置エンコーディングを導入して、合成画像の品質を向上させます。高品質の結果が得られる一方で、ボリューム レイの移動には計算コストがかかるため、3D GS などのより効率的な方法の探索が求められています。 ポイントベースのレンダリング: ポイントベースのレンダリングは、従来のポリゴンの代わりにポイントを使用して 3D シーンを視覚化する手法です。このアプローチは、複雑、非構造化、またはまばらな幾何学データをレンダリングする場合に特に効果的です。ポイントは、学習可能なニューラル記述子などの追加プロパティで強化し、効率的にレンダリングできますが、このアプローチでは、レンダリング時のホールやエイリアシング効果などの問題が発生する可能性があります。 3D GS は、異方性ガウスを使用してこの概念を拡張し、シーンのより連続的で一貫した表現を実現します。 三次元ガウスの性質: 三次元ガウスの特徴は、その中心(位置)μ、不透明度α、三次元共分散行列∑、色cです。ビューに依存する外観の場合、c は球面調和関数で表されます。すべての属性はバックプロパゲーションを通じて学習および最適化できます。 錐台カリング: 指定されたカメラ ポーズが与えられた場合、このステップでは、どの 3D ガウスがカメラの錐台の外側にあるかを決定します。こうすることで、特定のビューの外側にある 3D ガウスは後続の計算に関与しなくなり、計算リソースが節約されます。 スプラッティング: **このステップでは、レンダリングのために 3D ガウス (楕円体) が 2D 画像空間 (楕円体) に投影されます。表示変換 W と 3D 共分散行列 Σ が与えられると、投影された 2D 共分散行列 Σ' は次の式を使用して計算されます。 ここで、J は射影変換のアフィン近似のヤコビ行列です。 ピクセルごとのレンダリング: 3D GS の最終バージョンに入る前に、その仕組みをより深く理解するために、まずその単純な形式について詳しく説明します。 3D GS は複数のテクノロジーを利用して並列コンピューティングを促進します。ピクセルの位置が与えられると、次に、アルファ合成を使用して、そのピクセルの最終的な色が計算されます。 ここで、 は学習された色で、最終的な不透明度は学習された不透明度とガウス値の積です。 ここで、x' と μ は投影空間内の座標です。必要なソート済みリストの生成を並列化するのが難しいことを考慮すると、説明されているレンダリング プロセスは NeRF に比べて遅くなる可能性がありますが、これは正当な懸念事項です。実際、この懸念は的中しており、この単純なピクセルごとのアプローチを使用すると、レンダリング速度が大幅に影響を受ける可能性があります。リアルタイム レンダリングを実現するために、3DGS は並列コンピューティングに対応するためにいくつかの譲歩を行いました。 タイル (パッチ): 各ピクセルのガウス係数を導出する計算コストを回避するために、3D GS は精度をピクセル レベルからパッチ レベルの詳細に転送します。具体的には、3D GS は最初に画像を、元の論文では「タイル」と呼ばれる、重複しない複数のブロックに分割します。図 3b はタイルを示しています。各タイルは 16×16 ピクセルで構成されます。 3D GS はさらに、どのタイルがこれらの投影されたガウス マップと交差するかを決定します。投影されたガウスが複数のタイルをカバーすると仮定すると、論理的なアプローチは、ガウスをコピーし、各コピーに関連するタイルの識別子 (つまり、タイル ID) を割り当てることで構成されます。 並列レンダリング: コピー後、3D GS は個々のタイル ID と各ガウスのビュー変換から取得した深度値を組み合わせます。これにより、ソートされていないバイトのリストが生成されます。上位ビットはタイル ID を表し、下位ビットは深さを表します。こうすることで、ソートされたリストをレンダリング (つまり、アルファ合成) に直接使用できます。図 3c と 3d は、これらの概念を視覚的に示しています。各タイルとピクセルのレンダリングが独立して行われるため、このプロセスが並列コンピューティングに最適であることを強調する価値があります。もう 1 つの利点は、各タイルのピクセルが共通の共有メモリにアクセスし、均一な読み取りシーケンスを維持できるため、アルファ合成をより効率的に並行して実行できることです。元の論文の正式な実装では、フレームワークはタイルとピクセルの処理をそれぞれ CUDA プログラミング アーキテクチャのブロックとスレッドと同様に扱います。 つまり、3D GS は、高水準の画像合成品質を維持しながら、計算効率を向上させるために、前方処理段階でいくつかの近似を導入します。 3D GS の中核となるのは、シーンの本質を正確に捉える 3D ガウスの大規模なコレクションを構築するように設計された最適化プロセスです。これにより、自由な視点レンダリングが促進されます。一方で、3D ガウスのプロパティは、特定のシーンのテクスチャに適応するように微分可能なレンダリングを通じて最適化する必要があります。一方、特定のシーンを適切に表現できる 3D ガウスの数は事前にはわかりません。有望なアプローチの 1 つは、ニューラル ネットワークに 3D ガウス密度を自動的に学習させることです。各ガウスのプロパティを最適化する方法と、ガウスの密度を制御する方法について説明します。これら 2 つのプロセスは、最適化ワークフロー内でインターリーブされます。最適化中に手動で設定されるハイパーパラメータが多数あるため、わかりやすくするためにほとんどのハイパーパラメータの記号を省略しています。 損失関数: 画像の合成が完了すると、損失はレンダリングされた画像とレンダリングされた画像の差として計算されます。 GT: 3D-GS の損失関数は NeRF の損失関数とは若干異なります。レイマーチングに時間がかかるため、NeRF は通常、画像レベルではなくピクセル レベルで計算されます。 パラメータ更新: 3D ガウスのほとんどの特性は、バックプロパゲーションを通じて直接最適化できます。共分散行列 Σ を直接最適化すると、非正の半定値行列が生成され、共分散行列に通常関連付けられている物理的解釈に準拠しないことに注意してください。この問題を回避するために、3D GS は四元数 q と 3D ベクトル s を最適化することを選択します。 q と s はそれぞれ回転とスケーリングを表します。このアプローチにより、共分散行列 Σ を次のように再構築できます。 初期化: 3D GS は、SfM またはランダムに初期化されたスパース ポイントの初期セットから始まります。次に、ポイント高密度化と枝刈りを使用して、3 次元ガウス分布の密度を制御します。 ポイント高密度化: ポイント高密度化ステージでは、3D GS はガウス密度を適応的に増加させて、シーンの詳細をより適切にキャプチャします。このプロセスでは、幾何学的特徴が欠落している領域、またはガウス分布が散在しすぎる領域に特に注意を払います。高密度化は、大きなビュー空間位置勾配 (つまり、特定のしきい値を超える) を示すガウスをターゲットとして、一定回数の反復後に実行されます。これには、再構築が不十分な領域で小さなガウスをクローン化するか、再構築が過剰な領域で大きなガウスを分割することが含まれます。クローン作成の場合、ガウスのコピーが作成され、位置勾配に向かって移動されます。分割の場合、2 つの小さなガウスが 1 つの大きなガウスを置き換え、特定の係数でサイズが縮小されます。このステップでは、3D 空間でのガウス分布の最適な分布と表現を追求し、それによって再構成の全体的な品質が向上します。 点枝刈り: 点枝刈り段階では、冗長なガウス分布や影響力の低いガウス分布の除去が含まれます。これは、ある程度正則化プロセスとみなすことができます。このステップは、ほぼ透明なガウス (α が指定されたしきい値を下回る) およびワールド空間またはビュー空間で大きすぎるガウスを除去することによって実行されます。さらに、入力カメラ付近のガウス密度の不当な増加を防ぐために、一定回数の反復後にガウスのアルファ値がゼロに近く設定されます。これにより、余分なガウスを除去しながら、必要なガウス密度の増加を制御することができます。このプロセスは、計算リソースの節約に役立つだけでなく、モデル内のガウス分布によるシーンの表現が正確かつ効率的に維持されることを保証します。 3D GS の変革の可能性は、理論的および計算上の進歩をはるかに超えています。このセクションでは、ロボット工学、シーンの再構成と表現、AI 生成コンテンツ、自動運転、さらにはその他の科学分野など、3D GS が大きな影響を与えているさまざまな先駆的な応用分野を詳しく掘り下げます。 3D GS の応用は、その多用途性と革新的な可能性を実証します。ここでは、最も注目すべきアプリケーション分野のいくつかを概説し、3D GS が各分野でどのように新たなフロンティアを形成しているかについての洞察を提供します。 SLAM は、ロボット工学および自律システムにおける中心的な計算問題です。これには、環境のレイアウトをマッピングしながら、未知の環境におけるロボットまたはデバイスの位置を理解するという課題が含まれます。 SLAM は、自動運転車、拡張現実、ロボット ナビゲーションなどのさまざまなアプリケーションで重要です。 SLAM の核心は、未知の環境のマップを作成し、マップ上のデバイスの位置をリアルタイムで特定することです。したがって、SLAM は、計算集約的なシーン表現テクノロジに大きな課題をもたらし、3D GS の優れたテストベッドでもあります。 3D GS は、革新的なシーン表現手法として SLAM 分野に参入します。従来の SLAM システムは通常、環境を表すために点/面クラウドまたはボクセル メッシュを使用します。対照的に、3D GS は異方性ガウスを利用して環境をより適切に表現します。この表現にはいくつかの利点があります。 1) 効率: 3D ガウス分布の密度を適応的に制御して、空間データをコンパクトに表現し、計算負荷を軽減します。 2) 精度: 異方性ガウスにより、より詳細で正確な環境モデリングが可能になり、特に複雑なシーンや動的に変化するシーンに適しています。 3) 適応性: 3D GS はさまざまな規模や複雑な環境に適応できるため、さまざまな SLAM アプリケーションに適しています。いくつかの革新的な研究では、SLAM で 3D ガウス スプラッシュを使用し、このパラダイムの可能性と多用途性を実証しています。 ダイナミック シーン モデリングとは、時間の経過とともに変化するシーンの 3 次元構造と外観をキャプチャして表現するプロセスを指します。これには、シーン内のオブジェクトの形状、動き、視覚的側面を正確に反映するデジタル モデルの作成が含まれます。ダイナミック シーン モデリングは、仮想現実や拡張現実、3D アニメーション、コンピュータ ビジョンなどのさまざまなアプリケーションで重要です。 4D ガウス散乱 (4D GS) は、3D GS の概念を動的なシーンに拡張します。時間的な次元が組み込まれており、時間の経過とともに変化するシーンの表現とレンダリングが可能になります。このパラダイムにより、高品質のビジュアル出力を維持しながら、リアルタイムでの動的シーンのレンダリングが大幅に向上します。 AIGC とは、特にコンピューター ビジョン、自然言語処理、機械学習の分野で、人工知能システムによって自律的に作成または大幅に変更されるデジタル コンテンツを指します。 AIGC は、人工的に生成されたコンテンツをシミュレート、拡張、強化する機能を特徴としており、フォトリアリスティックな画像合成から動的な物語の作成に至るまでのアプリケーションを可能にします。 AIGC の重要性は、エンターテインメント、教育、技術開発など、さまざまな分野での変革の可能性にあります。これは、進化するデジタル コンテンツ作成環境における重要な要素であり、従来の方法に代わる、スケーラブルでカスタマイズ可能で、多くの場合より効率的な代替手段を提供します。 3D GS のこの明確な機能により、リアルタイム レンダリング機能と前例のないレベルの制御と編集が容易になり、AIGC アプリケーションとの関連性が高まります。 3D GS の明示的なシーン表現と微分可能なレンダリング アルゴリズムは、仮想現実、インタラクティブ メディア、その他の分野のアプリケーションにとって重要な、忠実度の高いリアルタイムの編集可能なコンテンツを生成するための AIGC の要件を完全に満たしています。 自動運転は、人間の介入なしに車両がナビゲーションおよび操作できるように設計されています。これらの車両には、カメラ、LiDAR、レーダーなどの一連のセンサーが装備されており、高度なアルゴリズム、機械学習モデル、強力なコンピューティング能力と組み合わされています。中心的な目標は、環境を感知し、情報に基づいた意思決定を行い、安全かつ効率的に作戦を実行することです。自動運転には交通手段を変革する可能性があり、人的ミスの削減による交通安全の向上、運転できない人の移動性の向上、交通の流れの最適化による渋滞や環境への影響の軽減など、重要な利点がもたらされます。 自動運転車は安全に運転するために周囲の環境を感知して解釈する必要があります。これには、リアルタイムでの運転シーンの再構築、静的および動的オブジェクトの正確な識別、それらの空間的関係と動きの理解が含まれます。動的な運転シナリオでは、他の車両、歩行者、動物などの移動物体によって環境が常に変化します。これらのシーンをリアルタイムで正確に再構成することは、安全なナビゲーションにとって重要ですが、関係する要素の複雑さと多様性により困難です。自動運転では、3D GS を使用して、LiDAR などのセンサーから取得したデータ ポイントを結合した連続的な表現にブレンドすることでシーンを再構築できます。これは、さまざまな密度のデータ ポイントを処理し、シーン内の静的な背景と動的なオブジェクトをスムーズかつ正確に再構築する場合に特に役立ちます。これまでのところ、3D ガウスを使用してダイナミックな運転/街路シーンをモデル化し、既存の手法と比較してシーンの再構築において優れたパフォーマンスを示している作品はほとんどありません。 このセクションでは、以前に説明したいくつかの 3D GS アルゴリズムのパフォーマンスを示すことで、より経験的な証拠を提供します。多くのタスクにおける 3D GS の多様なアプリケーションと、タスクごとにカスタマイズされたアルゴリズム設計が相まって、単一のタスクまたはデータセット内ですべての 3D GS アルゴリズムを一律に比較することは非現実的です。したがって、詳細なパフォーマンス評価のために、3D GS 分野の 3 つの代表的なタスクを選択します。特に明記されていない限り、パフォーマンスは主にオリジナルの論文に基づいています。 3D とはいえその後の取り組みon GS は大きく進歩しましたが、まだ克服すべき課題がいくつかあると考えています。 私たちの知る限り、このレビューは、革新的な明示的放射線場およびコンピュータ グラフィックス テクノロジである 3D GS の最初の包括的な概要を提供します。これは、従来の NeRF 手法からのパラダイム シフトを示しており、リアルタイム レンダリングと強化された制御性における 3D GS の利点を強調しています。当社の詳細な分析により、実世界のアプリケーション、特にリアルタイム パフォーマンスが必要なアプリケーションにおける 3D GS の利点が実証されています。私たちは、将来の研究の方向性とこの分野の未解決の課題についての洞察を提供します。全体として、3D GS は、3D 再構成と表現の将来の開発に大きな影響を与えることが期待される革新的なテクノロジーです。この調査は、この急速に発展している分野でのさらなる探求と進歩を推進するための基礎的なリソースとして機能することを目的としています。 元のリンク: https://mp.weixin.qq.com/s/jH4g4Cx87nPUYN8iKaKcBA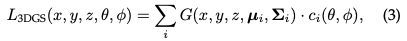
#コンテキストと用語
多くのテクノロジーと研究分野は 3D GS と密接に関連しています。以下に簡単に説明します。
明示的放射線場用の 3D ガウス
3D GS は、ニューラル コンポーネントに依存しない、リアルタイムの高解像度画像レンダリングにおける画期的な技術です。
新しい遠近合成のための 3D ガウスを学習しました
(数百万の) 最適化された 3D ガウスで表されるシーンを考えてみましょう。目標は、指定されたカメラのポーズに基づいて画像を生成することです。 NeRF は、計算を必要とする体積光線の移動、各ピクセルの 3D 空間点のサンプリングによってこのタスクを実行していることを思い出してください。このモードでは、高解像度の画像合成を実現することが難しく、リアルタイムのレンダリング速度を実現できません。まったく対照的に、3D GS は最初にこれらの 3D ガウスをピクセルベースの画像平面に投影します。これは「スプラッティング」と呼ばれるプロセスです (図 3a)。次に、3D GS はこれらのガウス分布を並べ替えて、各ピクセルの値を計算します。図に示すように、NeRF と 3D GS のレンダリングは、相互の逆プロセスとみなすことができます。以下では、3D GS におけるシーン表現の最小要素である 3D ガウスの定義から始めます。次に、これらの 3D ガウスを微分可能なレンダリングに使用する方法について説明します。最後に、高速レンダリングの鍵となる3D GSで使用されるアクセラレーション技術を紹介します。
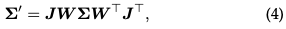
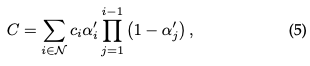
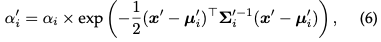
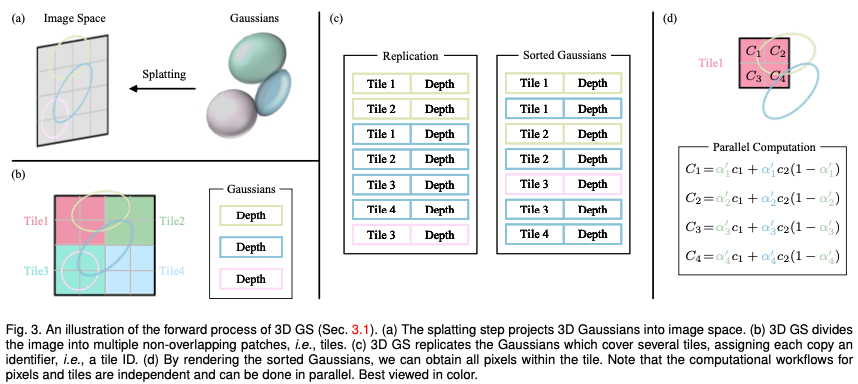
3D ガウス スプラッティングの最適化
パラメータの最適化
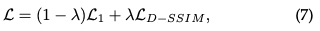

密度制御
アプリケーション分野とタスク
SLAM
ダイナミック シーン モデリング
AIGC
自動運転
パフォーマンスの比較
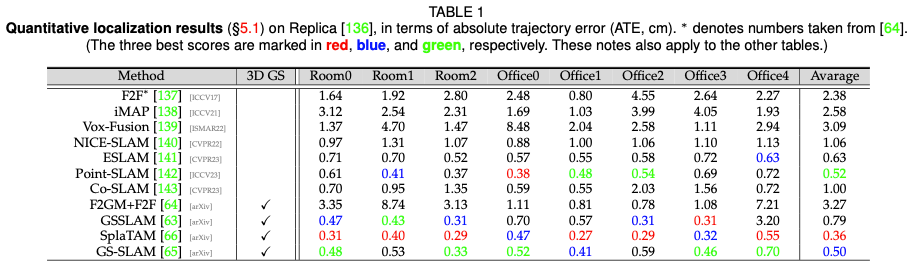
位置決めパフォーマンス
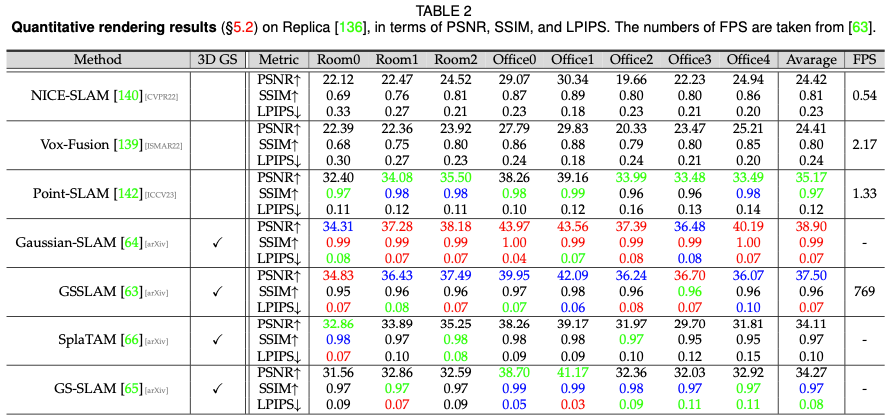
静的シーンのレンダリング パフォーマンス
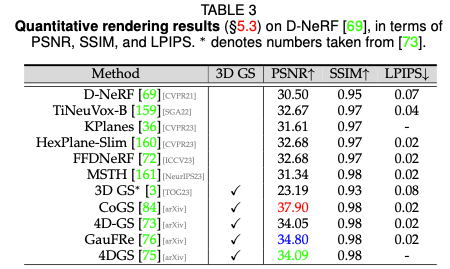
ダイナミック シーンのレンダリング パフォーマンス
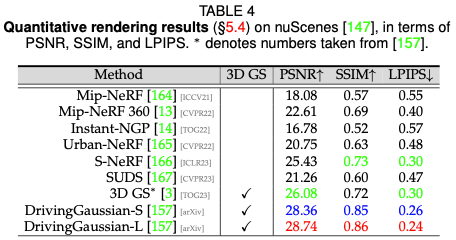
ドライビング シーンのレンダリング パフォーマンス
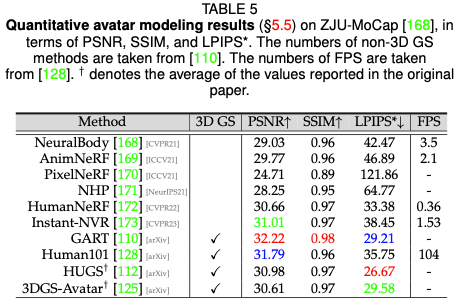
#デジタル ヒューマン パフォーマンス
今後の研究の方向性
結論

以上がなぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
