

LeCunの評価:ConvNetとTransformerのメタ評価どっちが強い?

特定のニーズに基づいてビジュアル モデルを選択するにはどうすればよいですか?
ConvNet/ViT モデルと教師あり/CLIP モデルは、ImageNet 以外の指標に関してどのように比較されますか?
MABZUAI と Meta の研究者によって発表された最新の研究では、「非標準」指標に関する一般的な視覚モデルを包括的に比較しています。

論文アドレス: https://arxiv.org/pdf/2311.09215.pdf
LeCunこの研究は高く評価され、優れていると評価されました。この調査では、同様のサイズの ConvNext アーキテクチャと VIT アーキテクチャを比較し、教師ありモードおよび CLIP メソッドを使用してトレーニングした場合のさまざまなプロパティの包括的な比較を提供します。

#ImageNet の精度を超えて
コンピュータ ビジョン モデルの状況はますます多様化し、複雑になってきています。初期の ConvNet から Vision Transformer の進化に至るまで、利用可能なモデルの種類は絶えず拡大しています。
同様に、トレーニング パラダイムは、ImageNet での教師ありトレーニングから、自己教師あり学習および CLIP のような画像とテキストのペアのトレーニングに進化しました。

ImageNet の精度は、常にモデルのパフォーマンスを評価するための主な指標でした。ディープラーニング革命を引き起こして以来、人工知能の分野で大きな進歩をもたらしてきました。
ただし、さまざまなアーキテクチャ、トレーニング パラダイム、データから生じるモデルの微妙な違いを測定することはできません。
ImageNet の精度のみで判断すると、プロパティが異なるモデルは似ているように見える可能性があります (図 1)。この制限は、モデルが ImageNet の機能に過剰適合し始め、精度が飽和に達すると、より明らかになります。
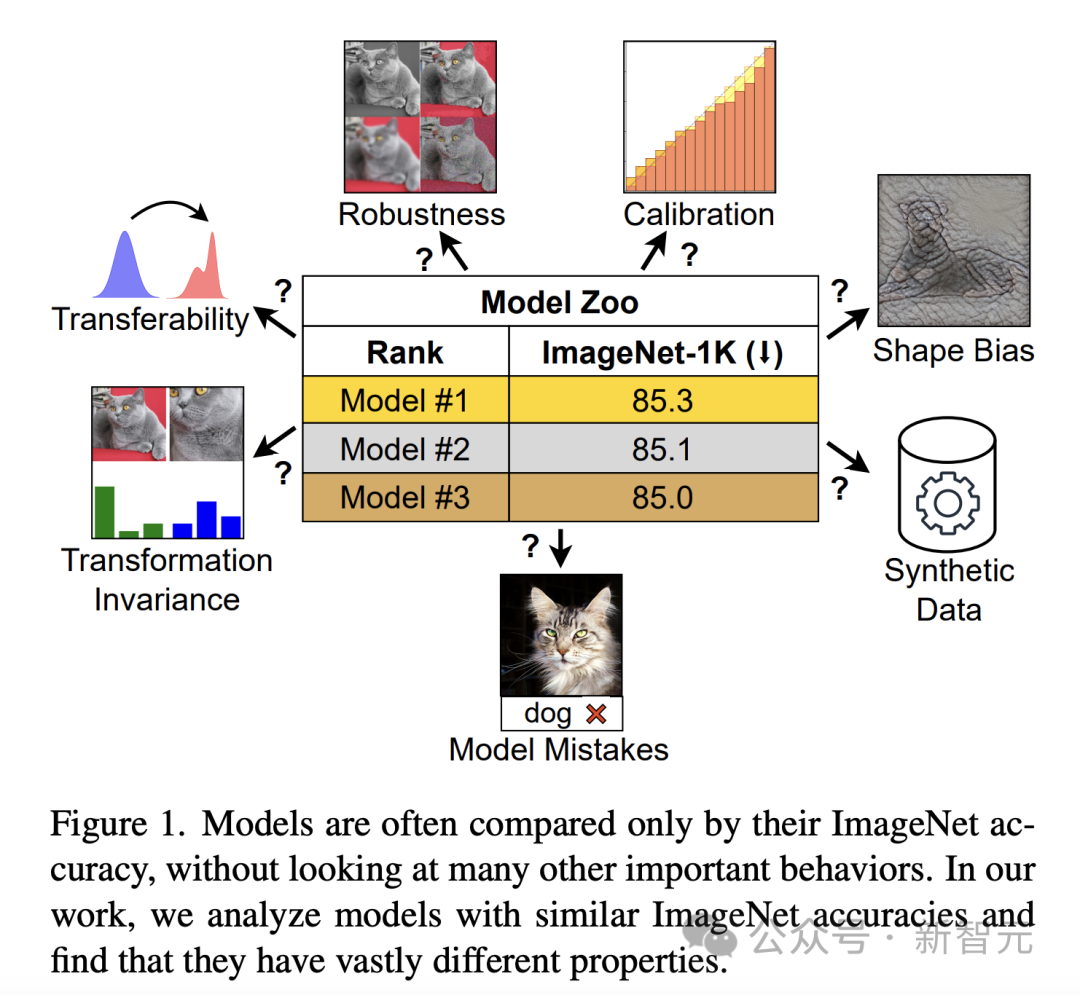
モデルのパフォーマンスに対するアーキテクチャとトレーニング目標の影響を調査するために、Vision Transformer (ViT) と ConvNeXt を具体的に比較しました。これら 2 つの最新アーキテクチャの ImageNet-1K 検証精度と計算要件は同等です。
さらに、この研究では、DeiT3-Base/16 と ConvNeXt-Base で代表される教師ありモデル、および CLIP モデルに基づく OpenCLIP のビジュアル エンコーダを比較しました。

結果の分析
研究者による分析は、さらなるトレーニングや罰金を必要としないことを目的としています。スタディの調整 モデルの動作の評価。このアプローチは、事前トレーニングされたモデルに依存することが多いため、コンピューティング リソースが限られている実務者にとって特に重要です。
具体的な分析では、著者は物体検出などの下流タスクの価値を認識していますが、最小限の計算要件で洞察を提供し、アプリケーションの適用を反映できる機能に焦点を当てています。現実世界のアプリケーション非常に重要な動作特性。
モデル エラー
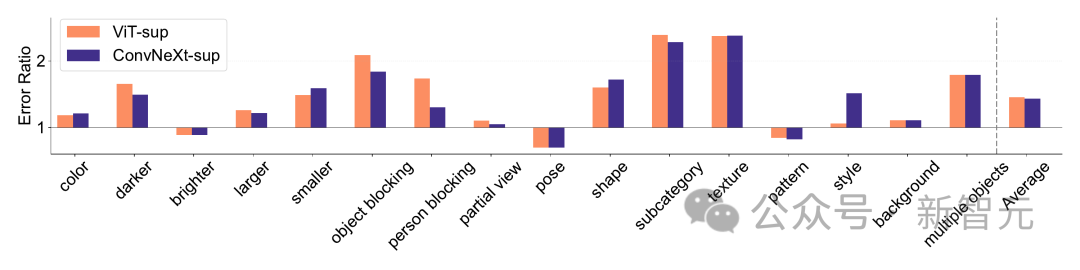
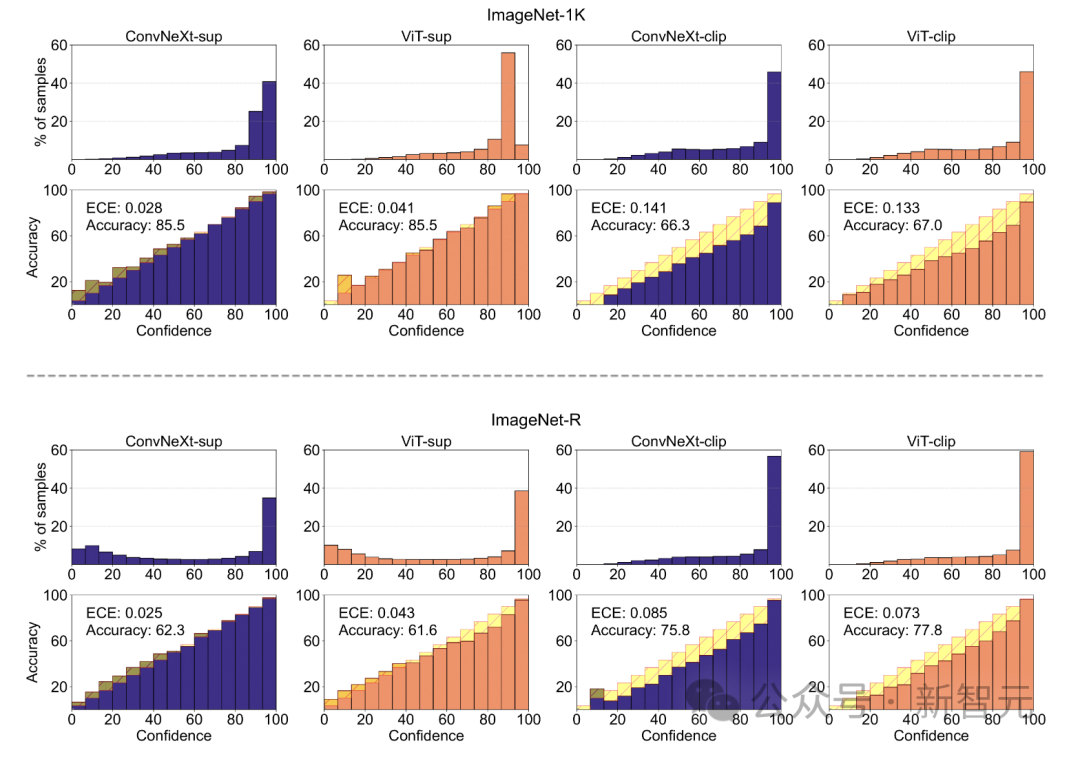
ImageNet-X は ImageNet-1K を拡張するデータセットであり、16 の詳細な手動アノテーションが含まれています変化する要因により、画像分類におけるモデルエラーの詳細な分析が可能になります。エラー率 (低いほど良い) を使用して、全体の精度と比較して特定の要素におけるモデルのパフォーマンスを定量化し、モデル エラーの微妙な分析を可能にします。 ImageNet-X の結果:
1. ImageNet の精度と比較して、CLIP モデルは教師ありモデルよりもエラーが少なくなります。
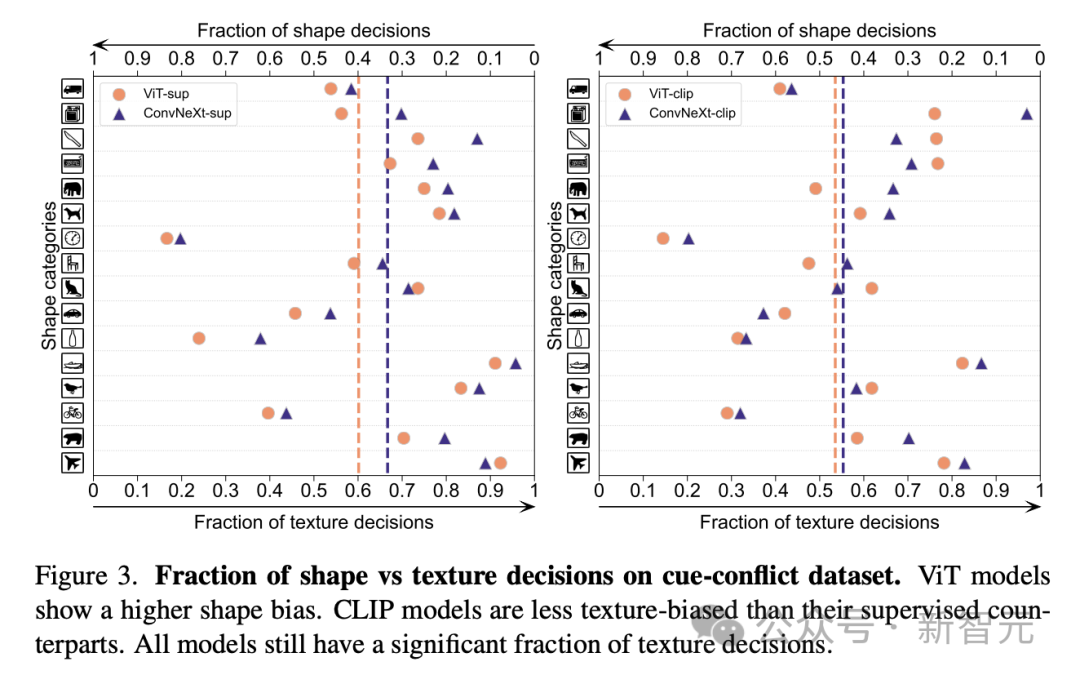
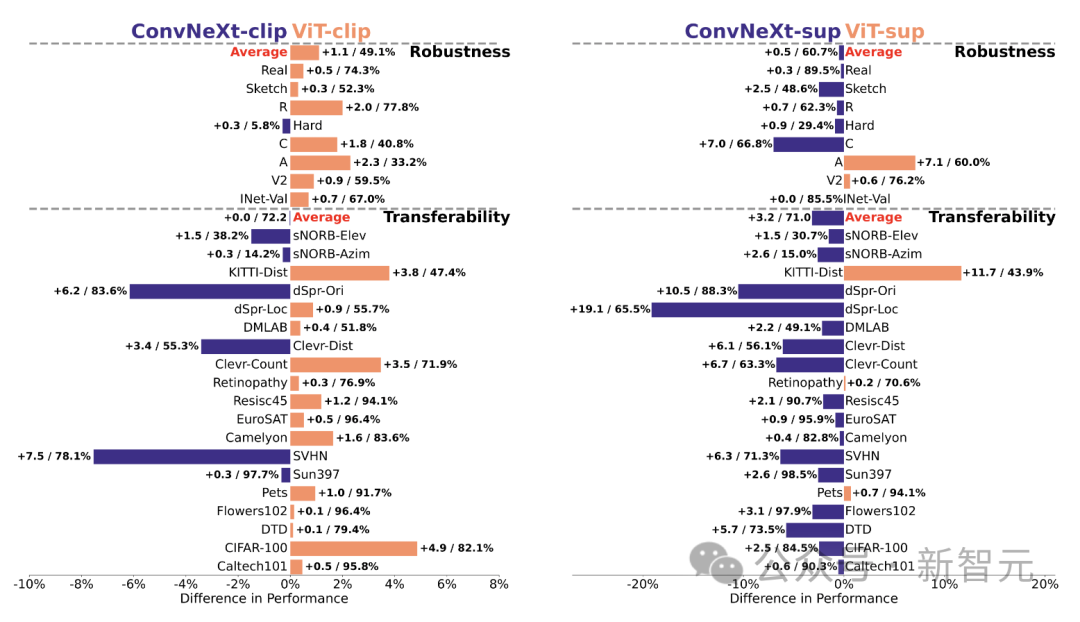
2. すべてのモデルは主にオクルージョンなどの複雑な要因の影響を受けます。 3. テクスチャはすべてのモデルの中で最も難しい要素です。 #形状/質感の偏差 Shape/Texture Deviation は、モデルが高度なシェイプ ヒントではなくテクスチャ ショートカットに依存しているかどうかをチェックします。 このバイアスは、形状とテクスチャのさまざまなカテゴリの手がかりが矛盾する画像を組み合わせることで研究できます。 このアプローチは、モデルの決定がテクスチャと比較して形状にどの程度基づいているかを理解するのに役立ちます。 研究者らは、キュー競合データセットの形状とテクスチャのバイアスを評価し、CLIP モデルのテクスチャ バイアスが教師ありモデルのテクスチャ バイアスよりも小さいことを発見しました。 ViT モデルは ConvNets のモデルよりも高かった。 モデルのキャリブレーション 定量化可能なモデルの予測信頼度をキャリブレーションし、実際の精度は一貫していますか? これは、予想される校正誤差 (ECE) などのメトリクスや、信頼性プロットや信頼度ヒストグラムなどの視覚化ツールを通じて評価できます。 研究者らは、ImageNet-1K と ImageNet-R のキャリブレーションを評価し、予測を 15 レベルに分類しました。実験では、次の点が観察されました: -CLIP モデルの信頼度は高いですが、教師ありモデルの信頼度はわずかに低くなります。 - 教師あり ConvNeXt は教師あり ViT よりも適切に調整されています。 #堅牢性と移植性 研究者らは、さまざまな ImageNet バリアントを使用して堅牢性を評価し、ViT モデルと ConvNeXt モデルは、ImageNet-R と ImageNet-Sketch を除いて同様の平均パフォーマンスを示しているが、監視モデルは一般に CLIP よりも優れていることを発見しました。堅牢性の点で。 移植性の点では、VTAB ベンチマークを使用して 19 のデータセットで評価したところ、教師あり ConvNeXt は ViT を上回り、CLIP モデルのパフォーマンスとほぼ同等でした。
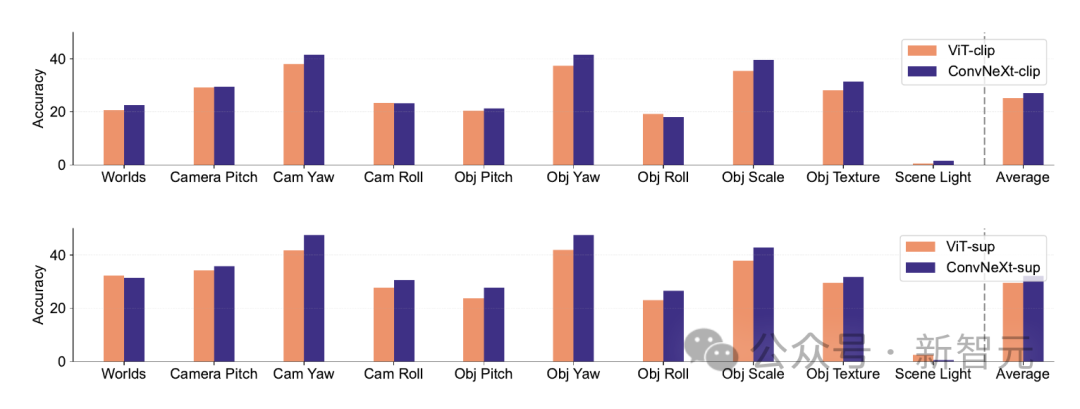
PUG-ImageNet のような合成データセット。カメラアングルやテクスチャなどの要素を正確に制御することは有望な研究手段となっているため、研究者は合成データに基づいてモデルのパフォーマンスを分析しました。 PUG-ImageNet には、照明やその他の要素が体系的に変化するフォトリアリスティックな ImageNet 画像が含まれており、パフォーマンスは絶対的に最高の精度として測定されます。 研究者らは、PUG-ImageNet のさまざまな要素の結果を提供し、ConvNeXt がほぼすべての要素で ViT より優れていることを発見しました。 これは、合成データでは ConvNeXt が ViT よりも優れていることを示していますが、CLIP モデルの精度は教師ありモデルよりも低いため、その差は小さくなりますが、これは異なる可能性があります。元の ImageNet の精度よりも低い関連性があります。
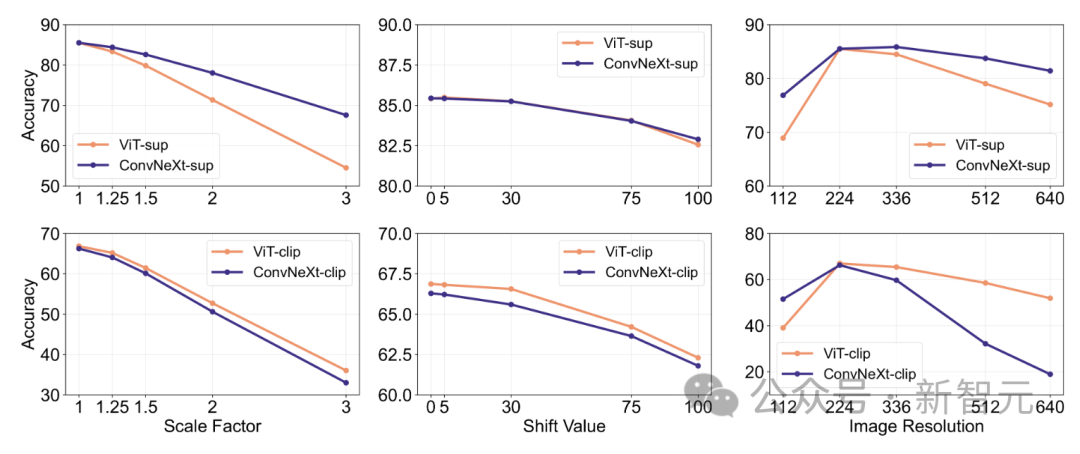
特徴の不変性とは、モデルの能力を指します。入力変換の影響を受けない一貫した表現を生成し、スケーリングや移動などのセマンティクスを維持します。 この機能により、異なるが意味的に類似した入力に対してモデルを適切に一般化できます。 研究人員的方法包括,調整影像大小以實現比例不變性,移動裁剪以實現位置不變性,以及使用內插位置嵌入調整ViT模型的解析度。 在有監督的訓練中,ConvNeXt的表現優於ViT。 整體而言,模式對尺度/解析度變換的穩健性高於對移動的穩健性。對於需要對縮放、位移和解析度具有較高穩健性的應用,研究結果表明有監督的ConvNeXt可能是最佳選擇。 研究人員發現,每種模型都有自己獨特的優點。 這表示模型的選擇應該取決於目標案例,因為標準的效能指標可能會忽略關鍵任務特定的細微差別。 此外,許多現有的基準是從ImageNet派生出來的,這對評估有偏見。開發具有不同數據分佈的新基準,對於在更具現實代表性的背景下評估模型至關重要。 ConvNet vs Transformer #- 在許多基準測試中,有監督的ConvNeXt比有監督的VIT具有更好的性能:它更好地校準,對數據轉換不變,表現出更好的可轉移性和健壯性。 - 在合成資料上,ConvNeXt的表現優於ViT。 - ViT有較高的形狀偏向。 Supervised vs CLIP #- 儘管CLIP模型在可轉移性方面更好,但監督的ConvNeXt在這項任務上展現了競爭力。這展示了有監督的模型的潛力。 - 監督模型更擅長穩健性基準,這可能是因為這些模型是ImageNet的變體。 - CLIP模型具有較高的形狀偏差,與其ImageNet精度相比,分類錯誤較少。 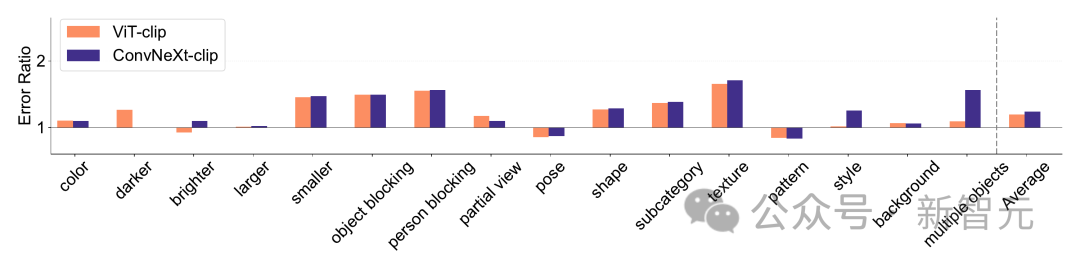
以上がLeCunの評価:ConvNetとTransformerのメタ評価どっちが強い?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7369
7369
 15
1628
14
1354
52
1266
25
1214
29
15
1628
14
1354
52
1266
25
1214
29

 C言語関数の返品値の種類は何ですか? C言語関数の返品値のタイプの概要?
Apr 03, 2025 pm 11:18 PM
C言語関数の返品値の種類は何ですか? C言語関数の返品値のタイプの概要?
Apr 03, 2025 pm 11:18 PM
c言語関数の返品値タイプには、int、float、double、char、void、およびポインタータイプが含まれます。 intは整数を返すために使用され、フロートとダブルはフロートを返すために使用され、charは文字を返します。 voidとは、関数が値を返さないことを意味します。ポインタータイプはメモリアドレスを返し、メモリの漏れを避けるように注意してください。構造またはコンソーシアムは、複数の関連データを返すことができます。
 C言語関数の概念
Apr 03, 2025 pm 10:09 PM
C言語関数の概念
Apr 03, 2025 pm 10:09 PM
C言語関数は再利用可能なコードブロックです。彼らは入力を受け取り、操作を実行し、結果を返すことができます。これにより、再利用性が改善され、複雑さが軽減されます。関数の内部メカニズムには、パラメーターの渡し、関数の実行、および戻り値が含まれます。プロセス全体には、関数インラインなどの最適化が含まれます。単一の責任、少数のパラメーター、命名仕様、エラー処理の原則に従って、優れた関数が書かれています。関数と組み合わせたポインターは、外部変数値の変更など、より強力な関数を実現できます。関数ポインターは機能をパラメーターまたはストアアドレスとして渡し、機能への動的呼び出しを実装するために使用されます。機能機能とテクニックを理解することは、効率的で保守可能で、理解しやすいCプログラムを書くための鍵です。
 c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
C35の計算は、本質的に組み合わせ数学であり、5つの要素のうち3つから選択された組み合わせの数を表します。計算式はC53 = 5です! /(3! * 2!)。これは、ループで直接計算して効率を向上させ、オーバーフローを避けることができます。さらに、組み合わせの性質を理解し、効率的な計算方法をマスターすることは、確率統計、暗号化、アルゴリズム設計などの分野で多くの問題を解決するために重要です。
 個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
std :: uniqueは、コンテナ内の隣接する複製要素を削除し、最後まで動かし、最初の複製要素を指すイテレーターを返します。 STD ::距離は、2つの反復器間の距離、つまり、指す要素の数を計算します。これらの2つの機能は、コードを最適化して効率を改善するのに役立ちますが、隣接する複製要素をstd ::のみ取引するというような、注意すべき落とし穴もあります。 STD ::非ランダムアクセスイテレーターを扱う場合、距離は効率が低くなります。これらの機能とベストプラクティスを習得することにより、これら2つの機能の力を完全に活用できます。
 CとC#の違いと接続は何ですか?
Apr 03, 2025 pm 10:36 PM
CとC#の違いと接続は何ですか?
Apr 03, 2025 pm 10:36 PM
CとC#には類似点がありますが、それらは完全に異なります。Cはプロセス指向の手動メモリ管理、およびシステムプログラミングに使用されるプラットフォーム依存言語です。 C#は、デスクトップ、Webアプリケーション、ゲーム開発に使用されるオブジェクト指向のガベージコレクション、およびプラットフォーム非依存言語です。
 C言語関数はポインター出力をどのように返しますか?
Apr 03, 2025 pm 11:36 PM
C言語関数はポインター出力をどのように返しますか?
Apr 03, 2025 pm 11:36 PM
C言語関数はポインターを返してメモリアドレスを出力します。ポインティングコンテンツは、関数内の操作に依存します。これは、ローカル変数(関数が終了した後にメモリがリリースされた)、動的に割り当てられたメモリ(mallocおよびfreeで割り当てる必要がある)、またはグローバル変数を指す場合があります。
 C言語関数の括弧内のポインターパラメーターは何ですか?
Apr 03, 2025 pm 11:48 PM
C言語関数の括弧内のポインターパラメーターは何ですか?
Apr 03, 2025 pm 11:48 PM
C言語関数のポインターパラメーターは、整数、文字列、または構造へのポインターを含む、発信者が通過するメモリ領域を直接操作します。ポインターパラメーターを使用する場合、エラーやメモリの問題を回避するために、ポインターによって指されたメモリを変更するように注意する必要があります。文字列への二重のポインターの場合、ポインター自体を変更すると、新しい文字列を指すことができ、メモリ管理に注意を払う必要があります。構造または配列にポインターパラメーターを処理する場合、外れのアクセスを避けるために、ポインターの種類と境界を慎重に確認する必要があります。
 C言語の関数定義の形式は何ですか?
Apr 03, 2025 pm 11:51 PM
C言語の関数定義の形式は何ですか?
Apr 03, 2025 pm 11:51 PM
C関数定義の重要な要素には、リターンタイプ(関数によって返される値の定義)、関数名(命名仕様に続き、スコープの決定)、パラメーターリスト(関数で受け入れられたパラメータータイプ、数量、順序の定義)、および関数本文(関数のロジックの実装)が含まれます。これらの要素の意味と微妙な関係を明確にすることが重要であり、開発者が「ピット」を回避し、より効率的でエレガントなコードを書くのに役立ちます。
