

浙江大学が新しいSOTA技術SIFUを提案:たった1枚の写真で高品質の3D人体モデルを再構築可能

AR、VR、3D プリント、シーン構築、映画制作などの多くの分野において、服を着た人体の高品質 3D モデルは非常に重要です。
従来のモデル作成方法では多くの時間がかかり、専門の機器と技術者のみが完成させることができます。

# 逆に、日常生活では携帯電話のカメラをよく使います。またはウェブ上で見つけたポートレート写真。
したがって、単一の画像から 3D 人体モデルを正確に再構築できる方法は、コストを大幅に削減し、独自の作成プロセスを簡素化することができます。
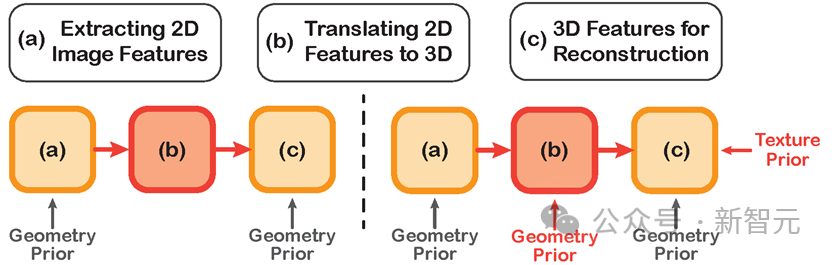 以前の方法 (左) とこの方法 (右) の技術的ルートの比較
以前の方法 (左) とこの方法 (右) の技術的ルートの比較
3D 人体再構成のための以前の深度学習モデルには、多くの場合、画像から 2D 特徴を抽出し、2D 特徴を 3D 空間に転送し、人体再構築に 3D 特徴を使用するという 3 つのステップが必要です。
しかし、これらの方法では、2D 特徴を 3D 空間に変換する段階で人体の事前分布の導入が無視されることが多く、その結果、特徴抽出が不十分になり、最終的な再構成結果にさまざまな欠陥が生じます。
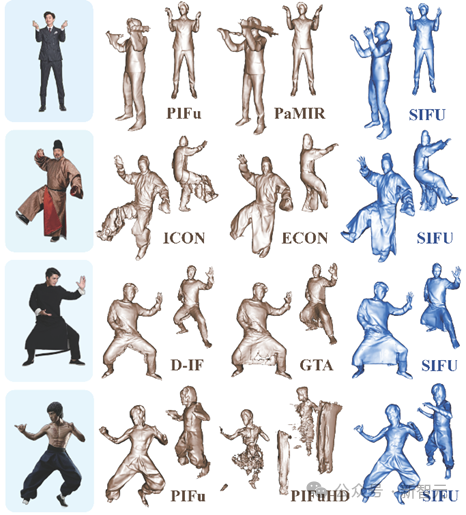 SIFU と他の SOTA モデルの再構築効果の比較
SIFU と他の SOTA モデルの再構築効果の比較
また、ステージでは以前は、モデルはトレーニング セットで学習した知識のみに依存しており、現実世界の事前知識が不足していたため、目に見えない領域でのテクスチャ予測が不十分になることがよくありました。

 写真
写真
#モデル構造
モデル パイプラインは次のとおりです:
写真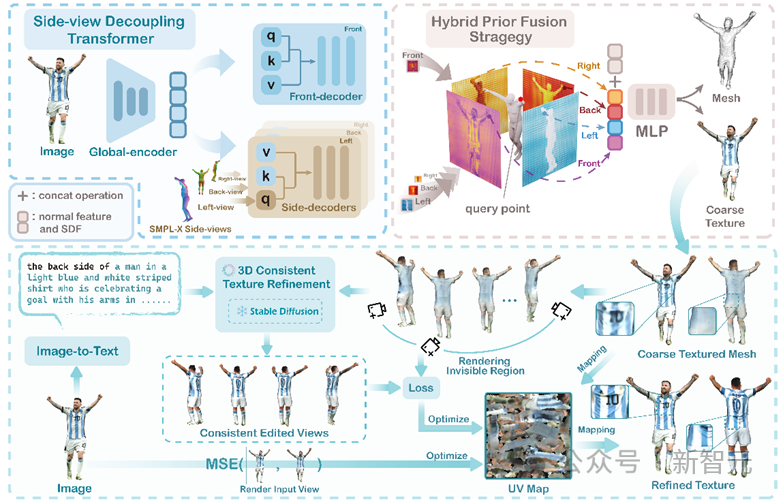
モデルの操作は 2 つの段階に分かれており、第 1 段階ではサイド陰関数を使用して人体の形状 (メッシュ) と粗いテクスチャ (粗いテクスチャ) を再構築します。ステージでは、事前トレーニングされた拡散モデルを使用してテクスチャを調整します。
第一段階では、著者は独自のサイドビュー デカップリング トランスを設計し、グローバル エンコーダを通じて 2D 特徴を抽出した後、人体の事前モデル SMPL- をデコーダに導入しました。側面図
この方法では、2D フィーチャを 3D 空間に変換する際に人体の事前知識をうまく組み合わせることができ、モデルの再構成効果が向上します。
第 2 段階では、著者は 3D 一貫したテクスチャ洗練プロセスを提案します。まず、人体の目に見えない領域 (側面と背中) を、次のような画像のコレクションに区別できます。連続的な視野角を設定し、大量のデータから事前知識を学習する拡散モデルの助けを借りて、粗いテクスチャの画像を一貫して編集して、より洗練された結果を得ることができます。最後に、リファイン前後の画像から損失を計算することで、3D モデルのテクスチャ マップが最適化されます。
実験部分
より高い再構成精度
実験部分では、著者は包括的な彼らのモデルは、CAPE-NFP、CAPE-FP、THuman2.0 などのさまざまなテスト セットでテストされ、主要な会議で発表された以前の単一画像人体再構成 SOTA モデルと比較されました。定量的テストの後、SIFU モデルは幾何学的再構成とテクスチャ再構成の両方で最良の結果を示しました。
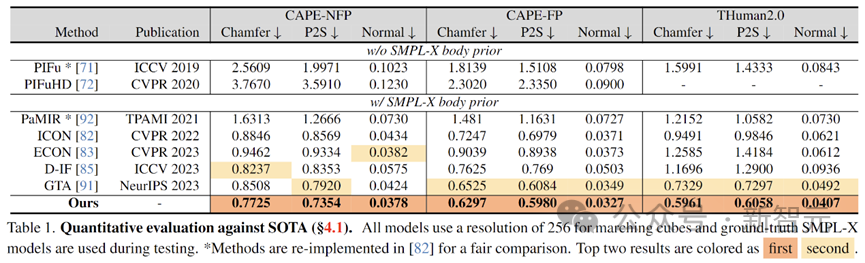 #幾何学再構成精度の定量的評価
#幾何学再構成精度の定量的評価
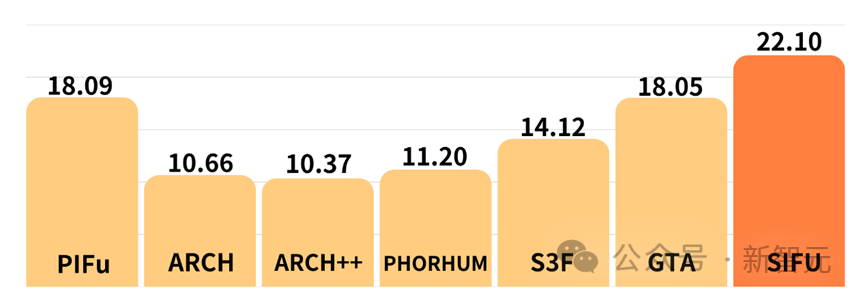 テクスチャ再構築効果の定量的評価
テクスチャ再構築効果の定量的評価
 インターネット上の公開画像を入力として使用して、定性的な効果を実証します
インターネット上の公開画像を入力として使用して、定性的な効果を実証します
##より強力な堅牢性
以前の場合トレーニングセット以外のデータにモデルを適用すると、推定人体事前モデルSMPL/SMPL-Xの精度が十分ではないため、再構成結果が入力画像と大きく異なることが多く、実用化が困難になる。
この点に関して、著者は特にモデルの堅牢性をテストしました。事前のモデル パラメーターのグラウンド トゥルースに摂動を追加することで、実際のシーンをシミュレートするためにポーズがシフトされました。SMPL-X不正確な状況を推定してモデル再構成の精度を評価します。結果は、この場合でも SIFU モデルが依然として最高の再構成精度を持っていることを示しています。
#エラーのある人体の以前のモデルに直面した場合のモデルの堅牢性を評価します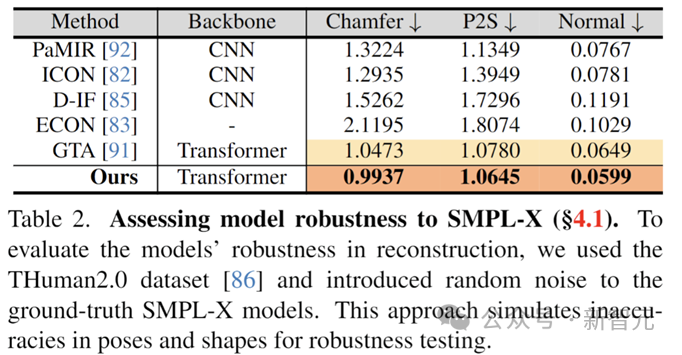
現実世界の画像を使用することで、以前の人体モデルの推定が不正確な場合でも、SIFU はより優れた再構築効果を実現します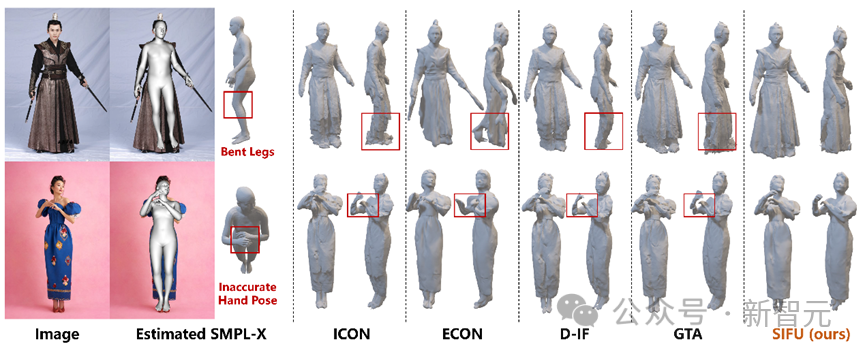
より広範なアプリケーション シナリオ
SIFU モデルの高精度かつ高品質な再構成効果により、3D プリント、シーン構築、テクスチャ編集などのさまざまなアプリケーション シナリオに適しています。
#3D プリント SIFU 再構成人体モデル

##SIFU は 3D シーンの構築に使用されます


 この記事では、サイドビューの条件付き暗黙関数と 3D 一貫性のあるテクスチャ編集を提案します。これは、2D フィーチャを 3D 空間に変換し、テクスチャを予測する際に、以前の研究で導入された事前知識の欠点を克服し、単一の画像内での人体再構成の精度と効果を大幅に向上させ、モデルに実際の大きな利点を与えます。 -世界のアプリケーション、そしてまた、この分野の将来の研究に新しいアイデアを提供します。
この記事では、サイドビューの条件付き暗黙関数と 3D 一貫性のあるテクスチャ編集を提案します。これは、2D フィーチャを 3D 空間に変換し、テクスチャを予測する際に、以前の研究で導入された事前知識の欠点を克服し、単一の画像内での人体再構成の精度と効果を大幅に向上させ、モデルに実際の大きな利点を与えます。 -世界のアプリケーション、そしてまた、この分野の将来の研究に新しいアイデアを提供します。
参考:
https://arxiv.org/abs/2312.06704
以上が浙江大学が新しいSOTA技術SIFUを提案:たった1枚の写真で高品質の3D人体モデルを再構築可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 WeChat で削除された連絡先を回復する方法 (簡単なチュートリアルでは、削除された連絡先を回復する方法について説明します)
May 01, 2024 pm 12:01 PM
WeChat で削除された連絡先を回復する方法 (簡単なチュートリアルでは、削除された連絡先を回復する方法について説明します)
May 01, 2024 pm 12:01 PM
残念ながら、WeChat は広く使用されているソーシャル ソフトウェアであり、何らかの理由で特定の連絡先を誤って削除してしまうことがよくあります。ユーザーがこの問題を解決できるように、この記事では、削除された連絡先を簡単な方法で取得する方法を紹介します。 1. WeChat の連絡先削除メカニズムを理解します。これにより、削除された連絡先を取得できるようになります。WeChat の連絡先削除メカニズムでは、連絡先がアドレス帳から削除されますが、完全には削除されません。 2. WeChat の組み込みの「連絡先帳復元」機能を使用します。WeChat には、この機能を通じて以前に削除した連絡先をすばやく復元できる「連絡先帳復元」機能が用意されています。 3. WeChat 設定ページに入り、右下隅をクリックし、WeChat アプリケーション「Me」を開き、右上隅にある設定アイコンをクリックして設定ページに入ります。
 Colorful マザーボードに BIOS を入力するにはどうすればよいですか? 2つの方法を教えます
Mar 13, 2024 pm 06:01 PM
Colorful マザーボードに BIOS を入力するにはどうすればよいですか? 2つの方法を教えます
Mar 13, 2024 pm 06:01 PM
Colorful マザーボードは中国国内市場で高い人気と市場シェアを誇っていますが、Colorful マザーボードのユーザーの中には、設定のために BIOS を入力する方法がまだ分からない人もいます。この状況に対応して、編集者はカラフルなマザーボード BIOS に入る 2 つの方法を特別に提供しました。ぜひ試してみてください。方法 1: U ディスク起動ショートカット キーを使用して、U ディスク インストール システムに直接入ります。ワンクリックで U ディスクを起動する Colorful マザーボードのショートカット キーは ESC または F11 です。まず、Black Shark インストール マスターを使用して、Black Shark インストール マスターを作成します。 Shark U ディスク起動ディスクを選択し、コンピュータの電源を入れます。起動画面が表示されたら、キーボードの ESC キーまたは F11 キーを押し続けて、起動項目を順次選択するウィンドウに入ります。「USB」の場所にカーソルを移動します。 」と表示され、その後
 トマト無料小説アプリで小説を書く方法. トマトノベルで小説を書く方法に関するチュートリアルを共有します。
Mar 28, 2024 pm 12:50 PM
トマト無料小説アプリで小説を書く方法. トマトノベルで小説を書く方法に関するチュートリアルを共有します。
Mar 28, 2024 pm 12:50 PM
トマト ノベルは非常に人気のある小説閲覧ソフトウェアです。トマト ノベルでは、新しい小説や漫画を読むことができます。どの小説も漫画もとても面白いです。小説を書きたい友達もたくさんいます。お小遣いを稼いで、小説の内容を編集することもできます。 「テキストに文章を書きたいです。それで、小説はどうやって書くのですか?友達は知らないので、一緒にこのサイトに行きましょう。小説の書き方の入門を少し見てみましょう。」 Tomato Novels を使用して小説を書く方法に関するチュートリアルを共有します。 1. まず、携帯電話で Tomato Free Novels アプリを開き、パーソナル センター - ライター センターをクリックします。 2. Tomato Writer Assistant ページに移動し、次の場所で [新しい本の作成] をクリックします。小説の終わり
 モバイルドラゴンの卵を孵化させる秘密が明らかに(モバイルドラゴンの卵をうまく孵化させる方法を段階的に教えます)
May 04, 2024 pm 06:01 PM
モバイルドラゴンの卵を孵化させる秘密が明らかに(モバイルドラゴンの卵をうまく孵化させる方法を段階的に教えます)
May 04, 2024 pm 06:01 PM
テクノロジーの発展に伴い、モバイルゲームは人々の生活に欠かせないものになりました。かわいいドラゴンエッグの画像と面白い孵化過程で多くのプレイヤーの注目を集めており、その中でも注目を集めているゲームの一つがモバイル版ドラゴンエッグです。プレイヤーがゲーム内で自分のドラゴンをより適切に育成し成長させることができるように、この記事ではモバイル版でドラゴンの卵を孵化させる方法を紹介します。 1. 適切な種類のドラゴン エッグを選択する プレイヤーは、ゲーム内で提供されるさまざまな種類のドラゴン エッグの属性と能力に基づいて、自分に適したドラゴン エッグの種類を慎重に選択する必要があります。 2. 孵化機のレベルをアップグレードします。プレイヤーはタスクを完了し、小道具を収集することで孵化機のレベルを向上させる必要があります。孵化機のレベルは孵化速度と孵化成功率を決定します。 3. プレイヤーはゲームに参加する必要がある孵化に必要なリソースを収集します。
 Win11で管理者権限を取得する方法まとめ
Mar 09, 2024 am 08:45 AM
Win11で管理者権限を取得する方法まとめ
Mar 09, 2024 am 08:45 AM
Win11 管理者権限の取得方法のまとめ. Windows 11 オペレーティング システムでは、管理者権限は、ユーザーがシステム上でさまざまな操作を実行できるようにする非常に重要な権限の 1 つです。ソフトウェアのインストールやシステム設定の変更など、一部の操作を完了するために管理者権限の取得が必要になる場合があります。以下にWin11の管理者権限を取得する方法をまとめましたので、お役に立てれば幸いです。 1. ショートカット キーを使用する Windows 11 システムでは、ショートカット キーを使用してコマンド プロンプトをすばやく開くことができます。
 Oracleバージョンの問い合わせ方法の詳細説明
Mar 07, 2024 pm 09:21 PM
Oracleバージョンの問い合わせ方法の詳細説明
Mar 07, 2024 pm 09:21 PM
Oracleバージョンのクエリ方法を詳しく解説 Oracleは、世界で最も人気のあるリレーショナルデータベース管理システムの1つで、豊富な機能と強力なパフォーマンスを提供し、企業で広く使用されています。データベースの管理と開発のプロセスでは、Oracle データベースのバージョンを理解することが非常に重要です。この記事では、Oracle データベースのバージョン情報をクエリする方法と具体的なコード例を詳しく紹介します。単純な SQL ステートメントを実行して、Oracle データベース内の SQL ステートメントのデータベース バージョンをクエリします。
 携帯電話の文字サイズの設定方法(携帯電話の文字サイズを簡単に調整できます)
May 07, 2024 pm 03:34 PM
携帯電話の文字サイズの設定方法(携帯電話の文字サイズを簡単に調整できます)
May 07, 2024 pm 03:34 PM
携帯電話が人々の日常生活において重要なツールになるにつれて、フォント サイズの設定は重要なパーソナライゼーション要件になりました。さまざまなユーザーのニーズを満たすために、この記事では、簡単な操作で携帯電話の使用体験を向上させ、携帯電話のフォントサイズを調整する方法を紹介します。携帯電話のフォント サイズを調整する必要があるのはなぜですか - フォント サイズを調整すると、テキストがより鮮明で読みやすくなります - さまざまな年齢のユーザーの読書ニーズに適しています - フォント サイズを使用すると、視力の悪いユーザーにとって便利です携帯電話システムの設定機能 - システム設定インターフェイスに入る方法 - 設定インターフェイスで「表示」オプションを見つけて入力します。 - 「フォント サイズ」オプションを見つけて、サードパーティでフォント サイズを調整します。アプリケーション - フォント サイズの調整をサポートするアプリケーションをダウンロードしてインストールします - アプリケーションを開いて、関連する設定インターフェイスに入ります - 個人に応じて
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
