

RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法

言語モデルが前例のない規模に拡大するにつれて、下流タスクの包括的な微調整には法外なコストがかかります。この問題を解決するために、研究者はPEFT法に注目し、採用し始めました。 PEFT 手法の主なアイデアは、微調整の範囲を少数のパラメーター セットに制限して、自然言語理解タスクで最先端のパフォーマンスを達成しながら計算コストを削減することです。このようにして、研究者は高いパフォーマンスを維持しながらコンピューティング リソースを節約でき、自然言語処理の分野に新たな研究のホットスポットをもたらします。
RoSA は新しい PEFT テクノロジーです。一連のベンチマーク テストの実験を通じて、同じパラメーター バジェットを使用した場合、RoSA がパフォーマンスを向上させることがわかりました。以前の低ランク適応 (LoRA) および純粋なスパース微調整方法よりも優れています。
この記事では、RoSA の原則、手法、結果を詳しく掘り下げ、そのパフォーマンスがどのように有意義な進歩を示すかを説明します。大規模な言語モデルを効果的に微調整したい人のために、RoSA は以前のソリューションよりも優れた新しいソリューションを提供します。
パラメータの効率的な微調整の需要
NLP はトランスフォーマーベースの言語に置き換えられましたGPT-4などのモデルを完全に変更。これらのモデルは、大規模なテキスト コーパスで事前トレーニングすることにより、強力な言語表現を学習します。次に、これらの表現を簡単なプロセスを通じて下流の言語タスクに転送します。
モデルのサイズが数十億から数兆のパラメータに増大するにつれて、微調整には膨大な計算負荷が生じます。たとえば、1 兆 7,600 億個のパラメータを持つ GPT-4 のようなモデルの場合、微調整には数百万ドルの費用がかかる可能性があります。このため、実際のアプリケーションでの展開は非常に非現実的になります。
PEFT メソッドは、微調整のパラメータ範囲を制限することで効率と精度を向上させます。最近、効率と精度をトレードオフするさまざまな PEFT テクノロジーが登場しました。
LoRA
#著名な PEFT 手法の 1 つは、低ランク適応 (LoRA) です。 LoRA は、Meta と MIT の研究者によって 2021 年に開始されました。このアプローチは、トランスがヘッド マトリクス内で低ランク構造を示すという観察によって動機付けられました。 LoRA は、この低ランク構造を利用して計算の複雑さを軽減し、モデルの効率と速度を向上させることが提案されています。
LoRA は最初の k 個の特異ベクトルのみを微調整し、他のパラメーターは変更されません。これには、O(n) ではなく、O(k) 個の追加パラメーターのみを調整する必要があります。
この低ランク構造を活用することで、LoRA は下流のタスクへの一般化に必要な意味のある信号をキャプチャし、微調整をこれらの上位特異ベクトルに制限することで、より効果的な最適化と推論を可能にします。
実験の結果、LoRA は 100 分の 1 以上少ないパラメーターを使用しながら、GLUE ベンチマークで完全に微調整されたパフォーマンスに匹敵することがわかりました。ただし、モデルのサイズが拡大し続けると、LoRA を通じて強力なパフォーマンスを得るにはランク k を増やす必要があり、完全な微調整と比較して計算量の節約が減少します。
RoSA が登場する前は、LoRA は PEFT 手法の最先端を代表しており、異なる行列因数分解や少数の微調整の追加などの手法を使用したわずかな改良のみでした。パラメーター。
ロバスト アダプテーション (RoSA)
ロバスト アダプテーション (RoSA) では、パラメータ効率の高い新しい微調整方法が導入されています。 RoSA は、低ランク構造のみに依存するのではなく、堅牢な主成分分析 (ロバスト PCA) からインスピレーションを得ています。
従来の主成分分析では、データ行列 X が行列に分解されます。堅牢な PCA はさらに一歩進んで、X をクリーンな低ランク L と「汚染/破損した」スパース S に分解します。
RoSA はここからインスピレーションを得て、言語モデルの微調整を次のように分解します。
低ランク適応 (L) 行列LoRA に似ており、主要なタスク関連信号を近似するように微調整されています。
非常に少数の、選択的に微調整された大きなパラメーターを含む高度にスパースな微調整 (S) 行列L をエンコードすると残留信号が失われます。
残留スパース成分を明示的にモデル化することで、RoSA は LoRA 単独よりも高い精度を達成できます。
RoSA は、モデルの頭部行列の低ランク分解を実行して L を構築します。これにより、下流のタスクに役立つ基礎となるセマンティック表現がエンコードされます。次に、RoSA は、各レイヤーの上位 m 個の最も重要なパラメーターを選択的に S に微調整しますが、他のすべてのパラメーターは変更されません。このステップでは、低ランクのフィッティングに適さない残差信号をキャプチャします。
微調整パラメータの数 m は、LoRA のみで必要なランク k よりも一桁小さいです。したがって、L の下位ヘッド マトリックスと組み合わせることで、RoSA は非常に高いパラメータ効率を維持します。
RoSA は、他のシンプルだが効果的な最適化も使用します:
残差スパース接続: S 残差は、層の正規化とフィードフォワード サブ層を通過する前に、各トランスフォーマー ブロックの出力に直接追加されます。これにより、L が見逃した信号をシミュレートできます。
独立したスパース マスク: 微調整のために S で選択されたメトリクスは、トランス層ごとに独立して生成されます。
共有低ランク構造: LoRA と同様に、同じ低ランクの基本 U、V 行列が L のすべての層で共有されます。これにより、一貫した部分空間で意味概念が捕捉されます。
これらのアーキテクチャの選択により、最適化と推論のためのパラメーターの効率を維持しながら、完全な微調整に似た柔軟性を RoSA モデリングに提供します。堅牢な低ランク適応と高度にスパースな残差を組み合わせたこの PEFT 手法を利用して、RoSA は精度と効率のトレードオフの新しいテクノロジーを実現します。
実験と結果
研究者らは、テキスト検出、感情分析、自然言語などのタスクをカバーする 12 の NLU データセットの包括的なベンチマークで RoSA を評価しました。言語推論と堅牢性テスト。彼らは、人工知能アシスタント LLM に基づく RoSA を使用し、120 億のパラメーター モデルを使用して実験を実施しました。
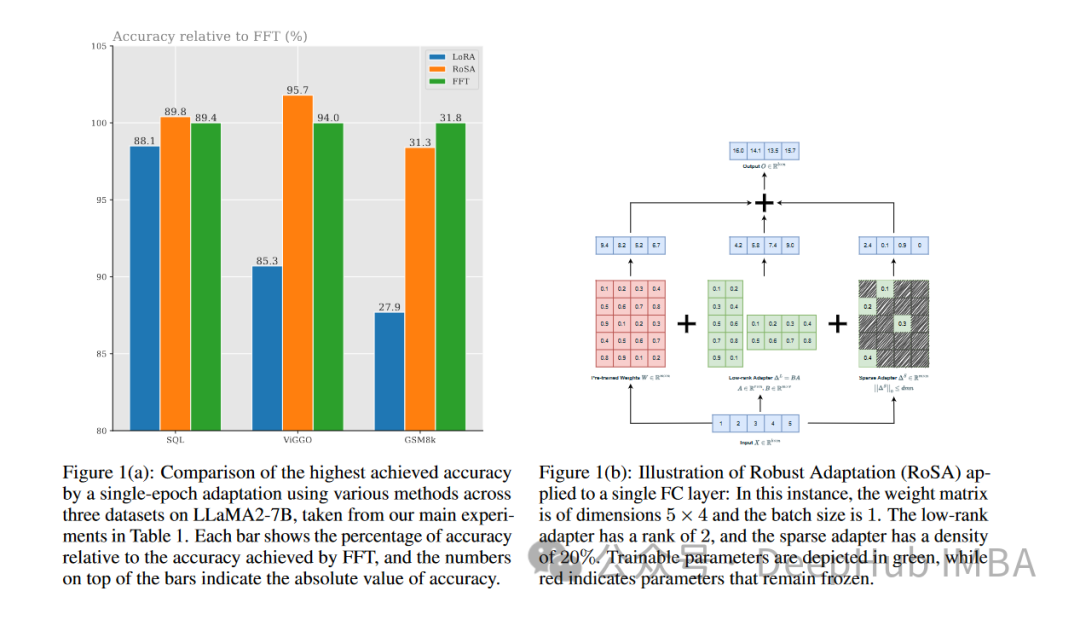
すべてのタスクにおいて、同じパラメータを使用した場合、RoSA は LoRA よりも大幅に優れたパフォーマンスを発揮します。両方の方法のパラメータの合計は、モデル全体の約 0.3% です。これは、LoRA の場合は k = 16、RoSA の場合は m = 5120 の場合、どちらの場合も約 450 万の微調整パラメータがあることを意味します。
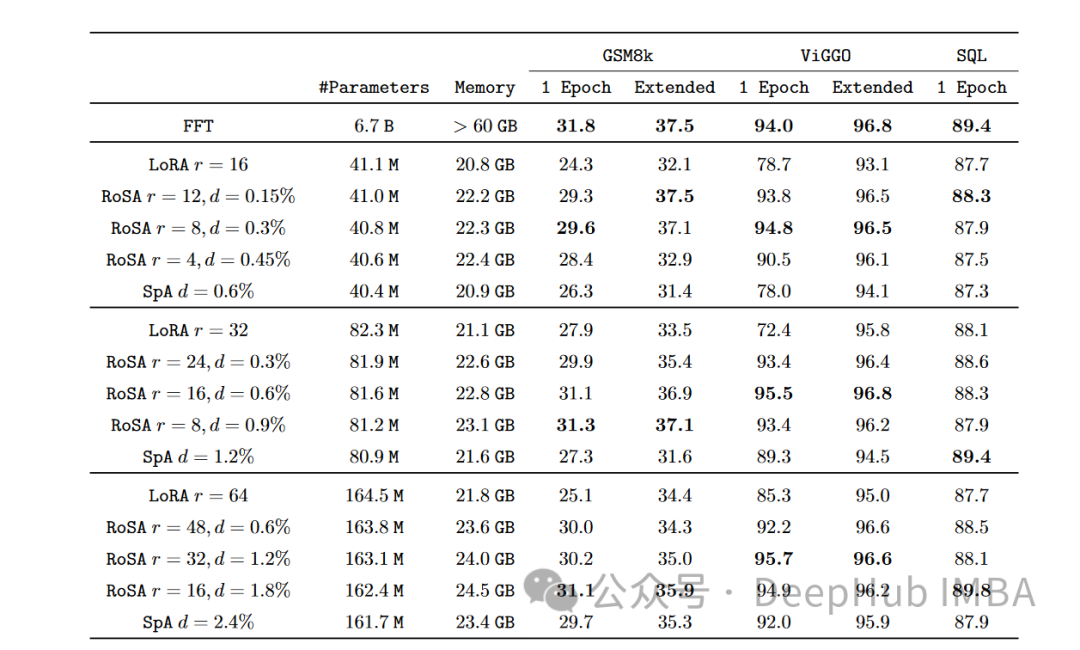
RoSA は、純粋なスパースの微調整されたベースラインのパフォーマンスと同等かそれを上回っています。
敵対的な例に対する堅牢性を評価する ANLI ベンチマークでは、RoSA のスコアが 55.6 であるのに対し、LoRA のスコアは 52.7 です。これは、汎化と調整の改善を示しています。
感情分析タスク SST-2 と IMDB では、RoSA の精度は 91.2% と 96.9% に達し、LoRA の精度は 90.1% と 95.3% に達します。
難しい語感曖昧さ回避テストである WIC では、RoSA の F1 スコアは 93.5 ですが、LoRA の F1 スコアは 91.7 です。
12 のデータセットすべてにわたって、一致するパラメータ予算の下では、RoSA は一般に LoRA よりも優れたパフォーマンスを示します。
注目すべきことに、RoSA はタスク固有の調整や特殊化を必要とせずにこれらの利点を達成できます。これにより、RoSA はユニバーサル PEFT ソリューションとしての使用に適しています。
要約
言語モデルのサイズが急速に増大し続ける中、言語モデルを微調整するための計算要件を削減することが緊急の課題となっています。解決する必要があります。 LoRA のようなパラメータ効率の高い適応トレーニング技術は、初期の成功を示していますが、低ランク近似に固有の制限に直面しています。
RoSA は、堅牢な低ランク分解と高度にスパースな残差微調整を有機的に組み合わせて、説得力のある新しいソリューションを提供します。選択的なスパース残差を通じて低ランクのフィッティングを回避する信号を考慮することにより、PEFT のパフォーマンスが大幅に向上します。経験的評価では、さまざまな NLU タスク セットで LoRA および制御されていないスパース ベースラインと比較して大幅な改善が示されています。
RoSA は概念的にはシンプルですが高性能であり、パラメータ効率、適応表現、および言語インテリジェンスを拡張するための継続的学習に関する相互研究をさらに進めることができます。
以上がRoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルのアーキテクチャに注目している場合は、最新のモデルや研究論文で「SwiGLU」という用語を見たことがあるかもしれません。 SwiGLUは大規模言語モデルで最もよく使われるアクティベーション関数と言えますので、この記事で詳しく紹介します。実はSwiGLUとは、2020年にGoogleが提案したSWISHとGLUの特徴を組み合わせたアクティベーション関数です。 SwiGLU の正式な中国語名は「双方向ゲート線形ユニット」で、SWISH と GLU の 2 つの活性化関数を最適化して組み合わせ、モデルの非線形表現能力を向上させます。 SWISH は大規模な言語モデルで広く使用されている非常に一般的なアクティベーション関数ですが、GLU は自然言語処理タスクで優れたパフォーマンスを示しています。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
言語モデルは、通常は文字列の形式であるテキストについて推論しますが、モデルへの入力は数値のみであるため、テキストを数値形式に変換する必要があります。トークン化は自然言語処理の基本タスクであり、特定のニーズに応じて、連続するテキスト シーケンス (文、段落など) を文字シーケンス (単語、フレーズ、文字、句読点など) に分割できます。その中の単位はトークンまたはワードと呼ばれます。以下の図に示す具体的なプロセスに従って、まずテキスト文がユニットに分割され、次に単一の要素がデジタル化され (ベクトルにマッピングされ)、次にこれらのベクトルがエンコード用のモデルに入力され、最後に下流のタスクに出力され、さらに最終結果を取得します。テキストセグメンテーションは、テキストセグメンテーションの粒度に応じて Toke に分割できます。
 FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
オープンソースの大規模言語モデルのパフォーマンスが向上し続けるにつれて、コードの作成と分析、推奨事項、テキストの要約、および質問と回答 (QA) ペアのパフォーマンスがすべて向上しました。しかし、QA に関しては、LLM はトレーニングされていないデータに関連する問題に対応していないことが多く、多くの内部文書はコンプライアンス、企業秘密、またはプライバシーを確保するために社内に保管されています。これらの文書がクエリされると、LLM は幻覚を起こし、無関係なコンテンツ、捏造されたコンテンツ、または矛盾したコンテンツを生成する可能性があります。この課題に対処するために考えられる手法の 1 つは、検索拡張生成 (RAG) です。これには、生成の品質と精度を向上させるために、トレーニング データ ソースを超えた信頼できるナレッジ ベースを参照して応答を強化するプロセスが含まれます。 RAG システムには、コーパスから関連する文書断片を取得するための検索システムが含まれています。
 セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
2024 年は、大規模言語モデル (LLM) が急速に開発される年です。 LLM のトレーニングでは、教師あり微調整 (SFT) や人間の好みに依存する人間のフィードバックによる強化学習 (RLHF) などのアライメント手法が重要な技術手段です。これらの方法は LLM の開発において重要な役割を果たしてきましたが、位置合わせ方法には手動で注釈を付けた大量のデータが必要です。この課題に直面して、微調整は活発な研究分野となっており、研究者は人間のデータを効果的に活用できる方法の開発に積極的に取り組んでいます。したがって、位置合わせ方法の開発は、LLM 技術のさらなる進歩を促進するでしょう。カリフォルニア大学は最近、SPIN (SelfPlayfInetuNing) と呼ばれる新しいテクノロジーを導入する研究を実施しました。 S
 ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
幻覚は、大規模言語モデル (LLM) を扱う場合によくある問題です。 LLM は滑らかで一貫性のあるテキストを生成できますが、生成される情報は不正確または一貫性がないことがよくあります。 LLM の幻覚を防ぐために、データベースやナレッジ グラフなどの外部知識ソースを使用して事実情報を提供できます。このようにして、LLM はこれらの信頼できるデータ ソースに依存できるため、より正確で信頼性の高いテキスト コンテンツが得られます。ベクトル データベースとナレッジ グラフ ベクトル データベース ベクトル データベースは、エンティティまたは概念を表す高次元ベクトルのセットです。これらは、ベクトル表現を通じて計算された、異なるエンティティまたは概念間の類似性または相関関係を測定するために使用できます。ベクトル データベースは、ベクトル距離に基づいて、「パリ」と「フランス」の方が「パリ」よりも近いことを示します。
 大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
2018 年に Google が BERT をリリースしました。リリースされると、11 個の NLP タスクの最先端 (Sota) 結果を一気に打ち破り、NLP 界の新たなマイルストーンとなりました。BERT の構造は次のとおりです。下の図では、左側は BERT モデルのプリセット、右側はトレーニング プロセス、右側は特定のタスクの微調整プロセスです。このうち、微調整ステージは、テキスト分類、品詞のタグ付け、質問と回答システムなど、その後のいくつかの下流タスクで使用されるときに微調整するためのものです。BERT はさまざまな上で微調整できます。構造を調整せずにタスクを実行できます。 「事前トレーニング済み言語モデル + 下流タスク微調整」のタスク設計により、強力なモデル効果をもたらします。以来、「言語モデルの事前トレーニング + 下流タスクの微調整」が NLP 分野のトレーニングの主流になりました。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
