
 テクノロジー周辺機器
AI
Google Mathematical AI が Nature に記事を掲載: ウー・ウェンジュンの 1978 年の法則定理を超え、世界クラスの幾何学的レベルを実証
テクノロジー周辺機器
AI
Google Mathematical AI が Nature に記事を掲載: ウー・ウェンジュンの 1978 年の法則定理を超え、世界クラスの幾何学的レベルを実証
Google Mathematical AI が Nature に記事を掲載: ウー・ウェンジュンの 1978 年の法則定理を超え、世界クラスの幾何学的レベルを実証

Google DeepMind は Nature を再びリリースし、AI の Alpha シリーズが復活し、数学のレベルは飛躍的に向上しました。
AlphaGeometry、IMO 金メダル選手の幾何学的レベルに達するために人間によるデモンストレーションは必要ありません。

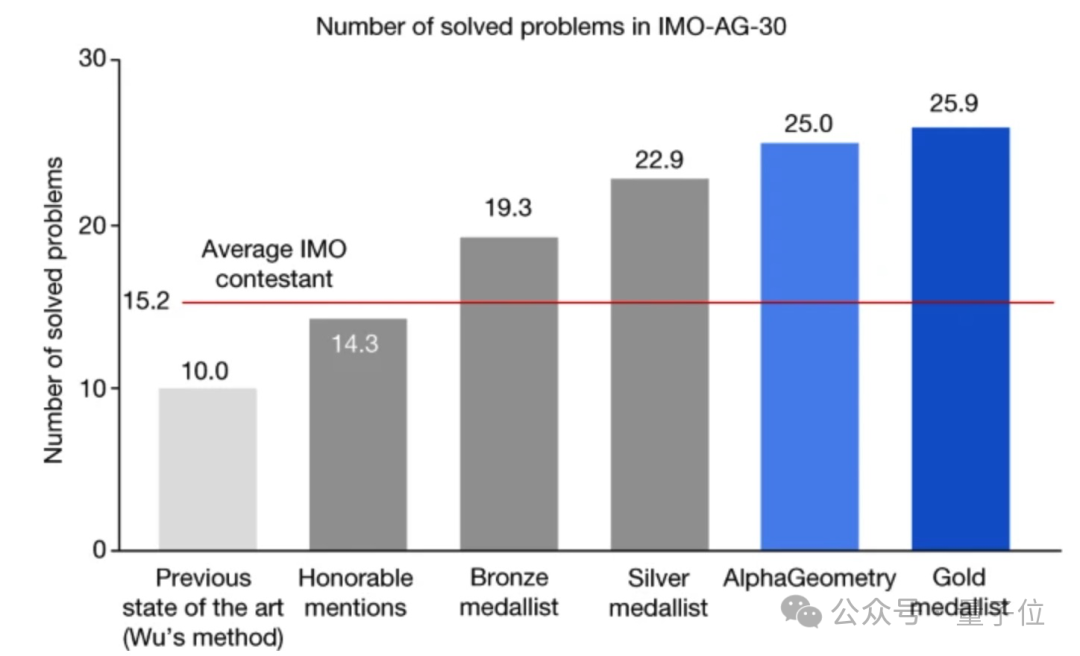
陈伊婷 (Evan Chen) は、AI によって生成された回答を評価する責任を負い、次のようにコメントしました。
##AlphaGeometry の出力は、信頼性が高く、クリーンであり、印象的です。これまでの AI ソリューションは当たり外れが多く、結果として手動でのレビューが必要になる場合もありました。AlphaGeometry のソリューションは、マシンによって検証でき、人間によって理解できる検証可能な構造を備えています。学生と同じように、角度や類似の三角形などの古典的な幾何学ルールを使用します。
優れた結果に加えて、この研究には業界の注目を集めている 3 つの重要なポイントがあります。
- 必要ありません。人間によるデモンストレーション、つまり、AlphaZero の自己学習 Go メソッドを継続して、AI 合成データ トレーニングのみが使用されます。
- 他の AI 手法と組み合わせた大規模モデル、AlphaGo や OpenAI Q* の噂に似ています。 これまでの多くの方法とは異なり、AlphaGeometry は人間が読める証明を生成でき、モデルとコードは両方ともオープンソースです。
 #チームは、AlphaGeometry が高度な推論能力を実現し、新しい知識を発見するための潜在的なフレームワークを提供すると信じています。
#チームは、AlphaGeometry が高度な推論能力を実現し、新しい知識を発見するための潜在的なフレームワークを提供すると信じています。
 さらに、著者のチームとのコミュニケーションプロセス中に、Qubits は、AlphaGo チャレンジと同様に、AlphaGeometry が本当に IMO 競技会に参加することを許可されるかどうかを尋ねました。人間の囲碁チャンピオンのように。
さらに、著者のチームとのコミュニケーションプロセス中に、Qubits は、AlphaGo チャレンジと同様に、AlphaGeometry が本当に IMO 競技会に参加することを許可されるかどうかを尋ねました。人間の囲碁チャンピオンのように。
彼らは、システムの機能を向上させるために熱心に取り組んでおり、AI が幾何学を超えた幅広い数学的問題を解決できるようにする必要があると述べました。
AI は幾何学も補助線を引くことを証明しました
以前、AI システムは幾何学的な問題をうまく解決できず、高品質のトレーニング データが不足していたため行き詰まっていました。
幾何学を学習している人間は、紙とペンを使って画像に関する既存の知識を利用して、新しくより複雑な幾何学的特性と関係を発見できます。
Google チームは、この目的のために 10 億のランダムな幾何学的オブジェクト グラフと、それらの点と線の間のすべての関係を生成し、最終的に 1 億の固有の定理とさまざまな困難の証明を選別しました。これらのデータを最初からトレーニングします。
 システムは、複雑な幾何学的証明を見つけるために相互に連携する 2 つのモジュールで構成されています。
システムは、複雑な幾何学的証明を見つけるために相互に連携する 2 つのモジュールで構成されています。
- 言語モデル、問題を解決するために使用できる幾何学的構造 を予測します (つまり、補助線を追加します) 。
- 記号推論エンジン、論理ルールを使用して結論を導き出します。
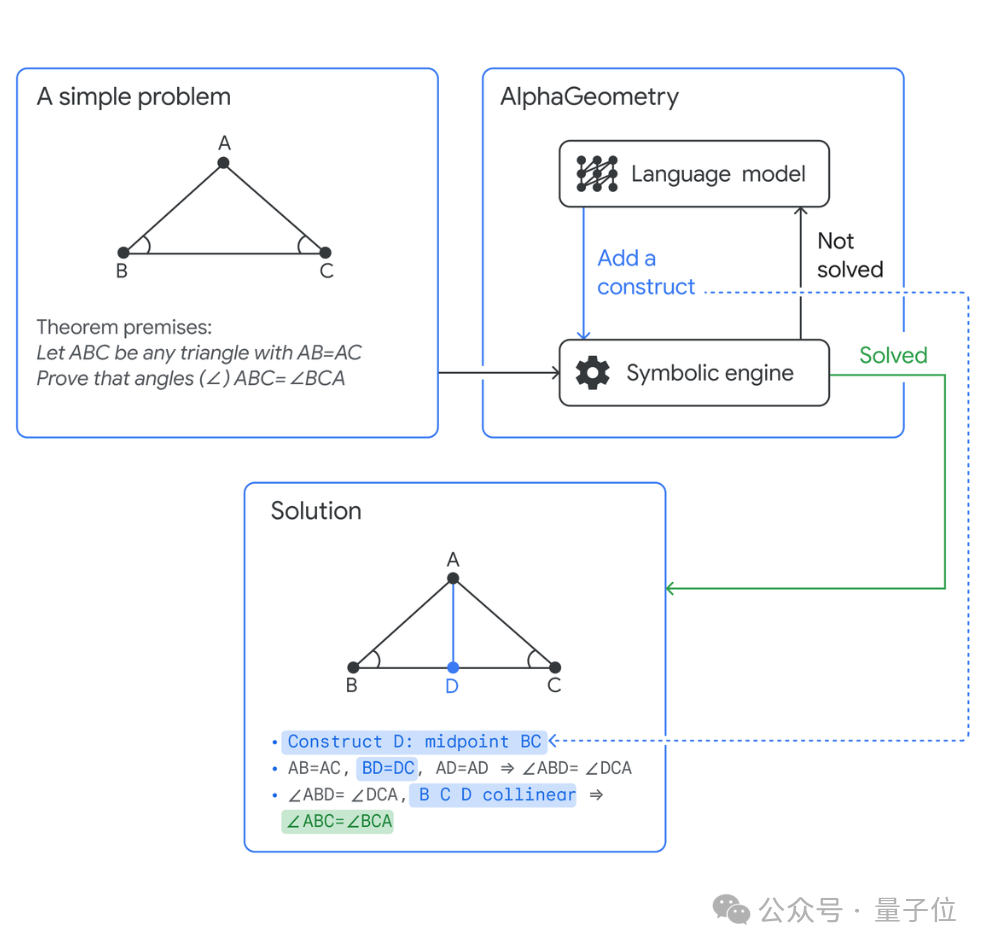 筆頭著者 Trieu Trinh は、AlphaGeometry の演算プロセスは人間の脳が速いタイプと遅いタイプに分けられるのと似ていると紹介しました。
筆頭著者 Trieu Trinh は、AlphaGeometry の演算プロセスは人間の脳が速いタイプと遅いタイプに分けられるのと似ていると紹介しました。
これは、ノーベル賞受賞者ダニエル・カーネマンのベストセラー本「Thinking Fast and Slow」で広められた「システム 1、システム 2」の概念です。
システム 1 は迅速で直感的なアイデアを提供し、システム 2 はより思慮深く合理的な決定を提供します。
一方で、言語モデルはデータ内のパターンと関係を識別するのが得意で、潜在的に有用な補助構造を迅速に予測できますが、多くの場合、その決定を厳密に推論したり説明したりする能力が欠けています。
一方、記号推論エンジンは形式論理に基づいており、明示的なルールを使用して結論を導き出します。これらは合理的で説明可能ですが、特に大規模で複雑な問題を単独で処理する場合、時間がかかり、柔軟性に欠けます。
たとえば、IMO 2015 のコンテストの問題を解く場合、青い部分は AlphaGeometry の言語モデルによって追加された補助構造、緑色の部分は最終証明の簡易バージョンで、合計 109 のステップがあります。
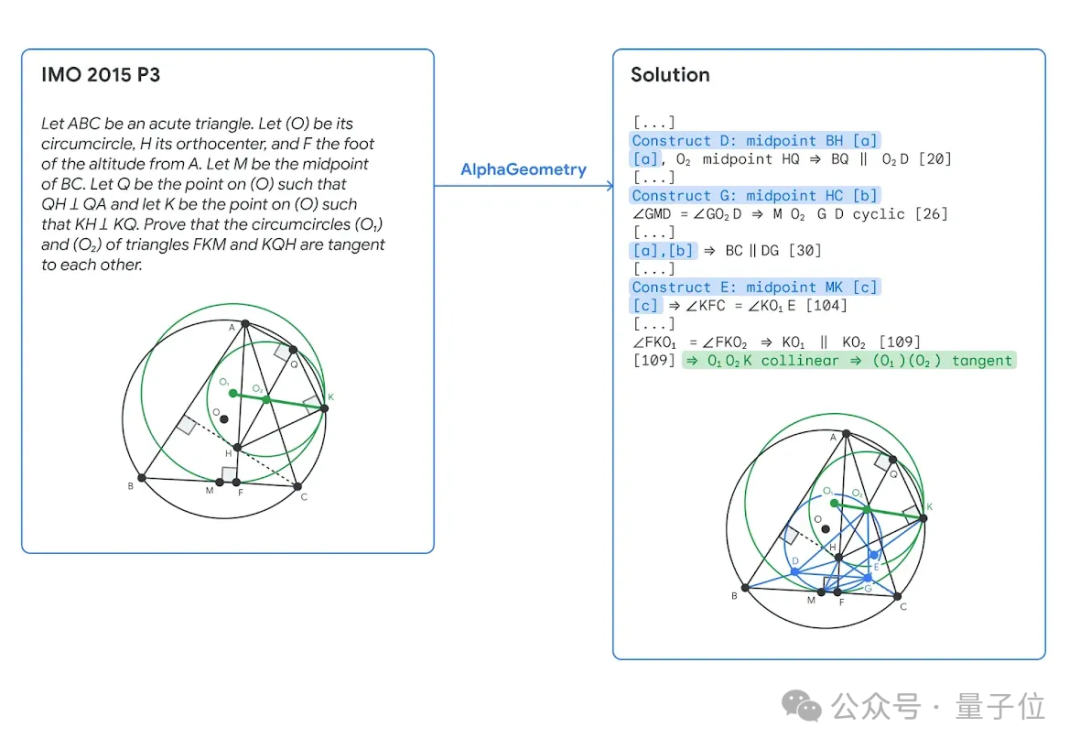
この問題を解決する過程で、AlphaGeometry は 2004 年の IMO コンテストの問題で未使用の前提条件も発見し、定理のより広範なバージョンを発見しました。
O が BC の中点であるという条件なしで、P、B、および C が同一線上にあることを証明できます。
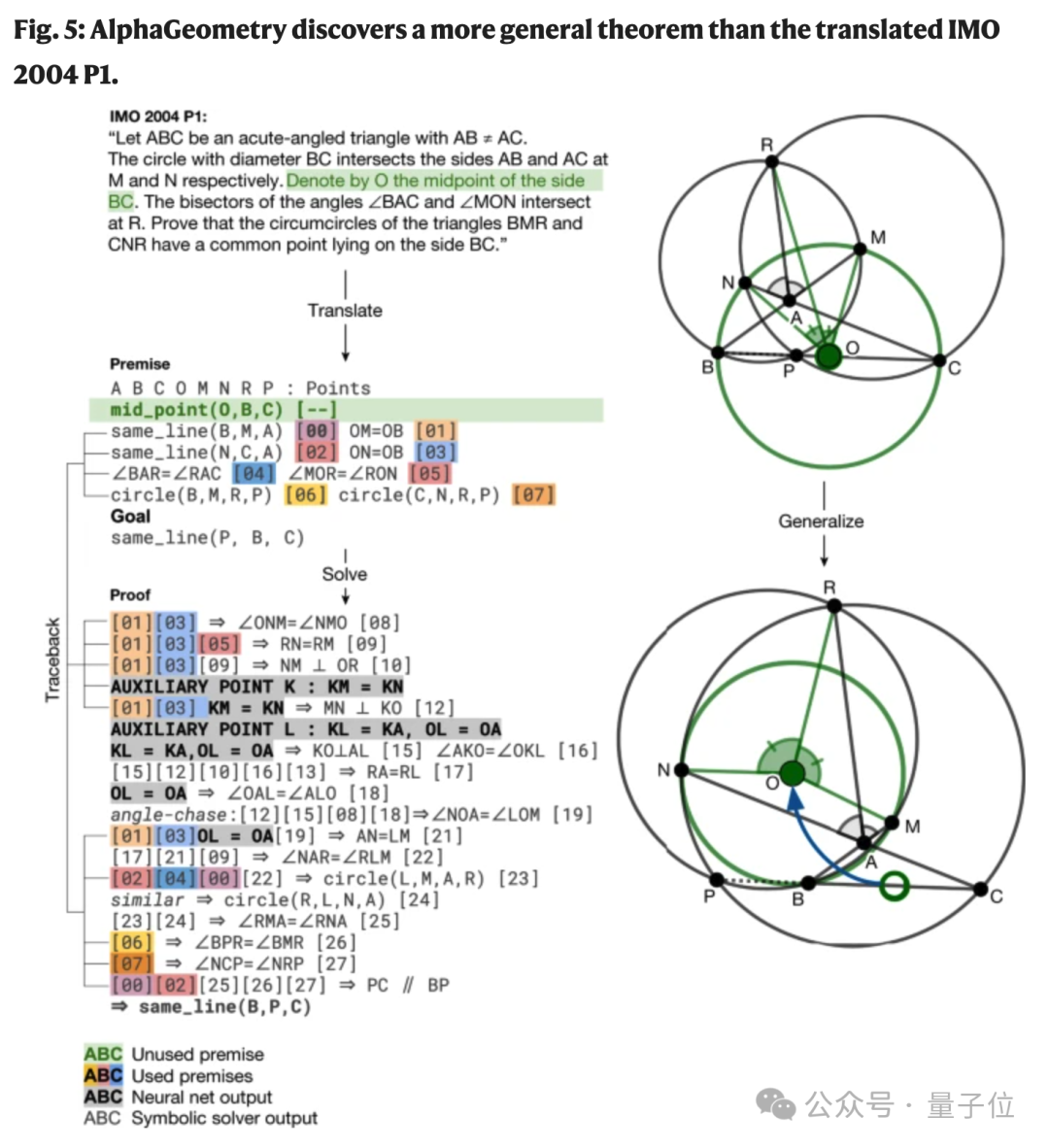
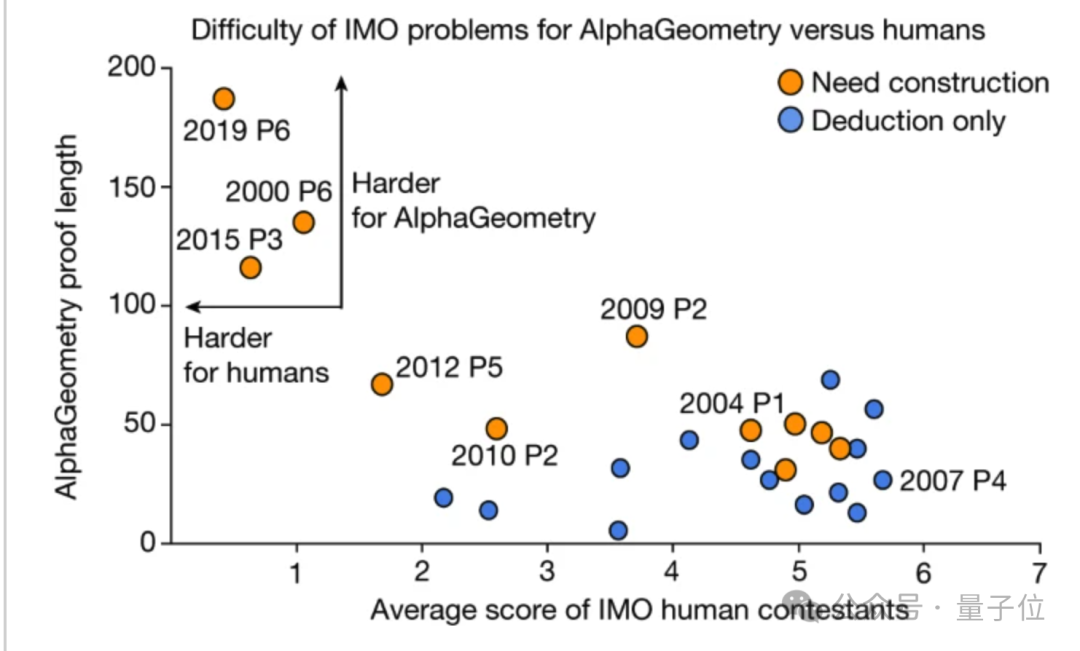
さらに、この研究では、人間のスコアが最も低い 3 つの問題についても、AlphaGeometry では非常に長い証明プロセスと多くの追加が必要であることも判明しました。解決する補助構造の。
しかし、比較的簡単な問題では、人間の平均スコアと AI によって生成された証明の長さとの間に有意な相関はありませんでした (p = −0.06)。
もう 1 つ
AlphaGeometry と AlphaGo の関係と違いについて、チームとのコミュニケーションの過程で、Google の科学者が Quoc Le はじめに:
これらはすべて非常に複雑な意思決定空間で検索しますが、AlphaGo の方法はより伝統的です(注: ニューラル ネットワークはパターン認識を担当します), AlphaGeometry のニューラル ネットワークは、次にとるべきアクションを提案し、決定空間内で正しい方向に進むように検索アルゴリズムを誘導する責任があります。
この結果は Alpha シリーズにちなんで名付けられており、最初のユニットも Google DeepMind ですが、著者は実際には元 Google Brain メンバーです。
Quoc Le マスターについては説明の必要はありません。筆頭著者の Trieu Trinh 氏と責任著者の Thang Luong 氏は、どちらも Google で 6 ~ 7 年間働いています。Thang Luong 氏自身も高校時代は IMO プレーヤーでした。
二人の中国人作家のうち、何何さんはニューヨーク大学の助教授です。 Wu Yuhuai 氏は以前、Google の大規模数学モデル Minerva の研究に参加していましたが、現在は Google を辞めてマスク氏のチームに加わり、xAI の共同創設者の 1 人になっています。
論文アドレス: https://www.nature.com/articles/s41586-023-06747-5。
参考リンク:
[1]https://www.nature.com/articles/d4186-024-00141 -5.
[2]https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry。
以上がGoogle Mathematical AI が Nature に記事を掲載: ウー・ウェンジュンの 1978 年の法則定理を超え、世界クラスの幾何学的レベルを実証の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
 ビットゲット取引プラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 25, 2025 pm 02:42 PM
ビットゲット取引プラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 25, 2025 pm 02:42 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
