

Pandas コードの効率を向上させるための 2 つの素晴らしいヒント

表形式データで Pandas を使用したことがある場合は、データをインポートし、クリーンアップして変換し、それをモデルへの入力として使用するプロセスに精通しているかもしれません。ただし、コードをスケールして運用環境に導入する必要がある場合、Pandas パイプラインがクラッシュし始め、動作が遅くなる可能性が高くなります。この記事では、Pandas コードの実行を高速化し、データ処理の効率を向上させ、よくある落とし穴を回避するのに役立つ 2 つのヒントを紹介します。

ヒント 1: ベクトル化操作
Pandas では、ベクトル化操作は、ボックスの列を使用せずに、より簡潔な方法でデータ全体を処理できる効率的なツールです。行ごとにループします。
それはどのように機能しますか?
ブロードキャストはベクトル化操作の重要な要素であり、これによりさまざまな形状のオブジェクトを直感的に操作できるようになります。
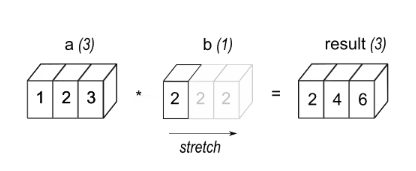
例 1: 3 つの要素を持つ配列 a にスカラー b を乗算すると、ソースと同じ形状の配列が得られます。
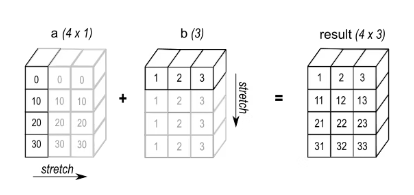
例 2: 加算演算を実行する場合、形状 (4,1) の配列 a と形状 (3,) の配列 b を加算すると、結果は次の配列になります。形状 (4,3)。
これについては、特に大規模な行列の乗算が一般的な深層学習において、多くの記事で議論されています。この記事では 2 つの簡単な例について説明します。
まず、特定の整数が列に出現する回数を数えたいとします。考えられる方法は 2 つあります。
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
次に、日付列を含む DataFrame があり、それを指定された日数だけオフセットしたいとします。ベクトル化された演算を使用した計算は次のとおりです。
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
ヒント 2: 反復
「for ループ」
反復を行う最初の最も直感的な方法は、Python for を使用することです。ループ。
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
「apply」
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
df.apply の各反復で、提供された呼び出し可能関数は、インデックスが df.columns で値が行である Series を取得します。これは、パンダがループごとにシーケンスを生成する必要があり、コストがかかることを意味します。コストを削減するには、次のように、使用することがわかっている df のサブセットに対して apply を呼び出すことをお勧めします。
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
「リストの組み合わせ itertuples」
リストと組み合わせた itertuples を使用した反復は、確実に実行されます。より良く働きます。 itertuples は、行データを含む (名前付き) タプルを生成します。
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
「リストの組み合わせ zip」
zip は反復可能オブジェクトを受け取り、タプルを生成します。i 番目のタプルには、指定された反復可能オブジェクトの i 番目の要素がすべて順番に含まれます。
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
「リストの組み合わせ to_dict」
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
「キャッシュ」
これまでに説明した反復手法に加えて、他の 2 つの方法もコードのパフォーマンスの向上に役立ちます。そして並列化。キャッシュは、同じパラメーターを使用して pandas 関数を複数回呼び出す場合に特に便利です。たとえば、多くの重複値を含むデータセットにremove_wordsが適用された場合、functools.lru_cacheを使用して関数の結果を保存し、毎回再計算する必要がなくなります。 lru_cache を使用するには、remove_words の宣言に @lru_cache デコレーターを追加し、好みの反復方法を使用して関数をデータセットに適用するだけです。これにより、コードの速度と効率が大幅に向上します。次のコードを例に挙げます。
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
このデコレータを追加すると、以前に遭遇した入力の出力を「記憶」する関数が生成され、すべてのコードを再度実行する必要がなくなります。
「並列化」
最後の切り札は、pandarallel を使用して、複数の独立した df ブロックにわたって関数呼び出しを並列化することです。このツールの使い方は簡単です。インポートして初期化し、すべての .applys を .Parallel_applys に変更するだけです。
rree以上がPandas コードの効率を向上させるための 2 つの素晴らしいヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7338
7338
 9
1627
14
1352
46
1265
25
1210
29
9
1627
14
1352
46
1265
25
1210
29

 ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルースクリーンコード0x0000001が発生した場合の対処方法
Feb 23, 2024 am 08:09 AM
ブルー スクリーン コード 0x0000001 の対処法。ブルー スクリーン エラーは、コンピューター システムまたはハードウェアに問題がある場合の警告メカニズムです。コード 0x0000001 は、通常、ハードウェアまたはドライバーの障害を示します。ユーザーは、コンピュータの使用中に突然ブルー スクリーン エラーに遭遇すると、パニックになり途方に暮れるかもしれません。幸いなことに、ほとんどのブルー スクリーン エラーは、いくつかの簡単な手順でトラブルシューティングして対処できます。この記事では、ブルー スクリーン エラー コード 0x0000001 を解決するいくつかの方法を読者に紹介します。まず、ブルー スクリーン エラーが発生した場合は、再起動を試みることができます。
 一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
Pandas インストール チュートリアル: 一般的なインストール エラーとその解決策の分析、特定のコード サンプルが必要です はじめに: Pandas は、データ クリーニング、データ処理、およびデータ視覚化で広く使用されている強力なデータ分析ツールであるため、この分野で高く評価されていますデータサイエンスのただし、環境構成と依存関係の問題により、パンダのインストール時に問題やエラーが発生する可能性があります。この記事では、パンダのインストール チュートリアルを提供し、いくつかの一般的なインストール エラーとその解決策を分析します。 1.パンダをインストールする
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
コード0xc000007bエラーを解決する
Feb 18, 2024 pm 07:34 PM
終了コード 0xc000007b コンピューターを使用しているときに、さまざまな問題やエラー コードが発生することがあります。その中でも最も厄介なのが終了コード、特に終了コード0xc000007bです。このコードは、アプリケーションが正常に起動できず、ユーザーに迷惑がかかっていることを示しています。まずは終了コード0xc000007bの意味を理解しましょう。このコードは、32 ビット アプリケーションを 64 ビット オペレーティング システムで実行しようとしたときに通常発生する Windows オペレーティング システムのエラー コードです。それはそうすべきだという意味です
 ブルー スクリーン コード 0x000000d1 は何を表しますか?
Feb 18, 2024 pm 01:35 PM
ブルー スクリーン コード 0x000000d1 は何を表しますか?
Feb 18, 2024 pm 01:35 PM
0x000000d1 ブルー スクリーン コードは何を意味しますか? 近年、コンピューターの普及とインターネットの急速な発展に伴い、オペレーティング システムの安定性とセキュリティの問題がますます顕著になってきています。よくある問題はブルー スクリーン エラーで、コード 0x000000d1 もその 1 つです。ブルー スクリーン エラー、または「死のブルー スクリーン」は、コンピューターに重大なシステム障害が発生したときに発生する状態です。システムがエラーから回復できない場合、Windows オペレーティング システムは、画面上にエラー コードを含むブルー スクリーンを表示します。これらのエラーコード
 あらゆるデバイス上の GE ユニバーサル リモート コード プログラム
Mar 02, 2024 pm 01:58 PM
あらゆるデバイス上の GE ユニバーサル リモート コード プログラム
Mar 02, 2024 pm 01:58 PM
デバイスをリモートでプログラムする必要がある場合は、この記事が役に立ちます。あらゆるデバイスをプログラミングするためのトップ GE ユニバーサル リモート コードを共有します。 GE リモコンとは何ですか? GEUniversalRemote は、スマート TV、LG、Vizio、Sony、Blu-ray、DVD、DVR、Roku、AppleTV、ストリーミング メディア プレーヤーなどの複数のデバイスを制御するために使用できるリモコンです。 GEUniversal リモコンには、さまざまな機能を備えたさまざまなモデルがあります。 GEUniversalRemote は最大 4 台のデバイスを制御できます。あらゆるデバイスでプログラムできるトップのユニバーサル リモート コード GE リモコンには、さまざまなデバイスで動作できるようにするコードのセットが付属しています。してもいいです
 1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
今日の急速な技術変化の波の中で、人工知能 (AI)、機械学習 (ML)、および深層学習 (DL) は輝かしい星のようなもので、情報技術の新しい波をリードしています。これら 3 つの単語は、さまざまな最先端の議論や実践で頻繁に登場しますが、この分野に慣れていない多くの探検家にとって、その具体的な意味や内部のつながりはまだ謎に包まれているかもしれません。そこで、まずはこの写真を見てみましょう。ディープラーニング、機械学習、人工知能の間には密接な相関関係があり、進歩的な関係があることがわかります。ディープラーニングは機械学習の特定の分野であり、機械学習
 超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
2006 年にディープ ラーニングの概念が提案されてから、ほぼ 20 年が経過しました。ディープ ラーニングは、人工知能分野における革命として、多くの影響力のあるアルゴリズムを生み出してきました。では、ディープラーニングのトップ 10 アルゴリズムは何だと思いますか?私の考えでは、ディープ ラーニングのトップ アルゴリズムは次のとおりで、いずれもイノベーション、アプリケーションの価値、影響力の点で重要な位置を占めています。 1. ディープ ニューラル ネットワーク (DNN) の背景: ディープ ニューラル ネットワーク (DNN) は、多層パーセプトロンとも呼ばれ、最も一般的なディープ ラーニング アルゴリズムです。最初に発明されたときは、コンピューティング能力のボトルネックのため疑問視されていました。最近まで長年にわたる計算能力、データの爆発的な増加によって画期的な進歩がもたらされました。 DNN は、複数の隠れ層を含むニューラル ネットワーク モデルです。このモデルでは、各層が入力を次の層に渡し、
