

データ処理ツール: pandas で Excel ファイルを読み取るための効率的なテクニック


データ処理の人気が高まるにつれ、データを効率的に使用し、データを活用する方法に注目する人が増えています。日々のデータ処理において、Excel テーブルは間違いなく最も一般的なデータ形式です。しかし、大量のデータを処理する必要がある場合、Excel を手動で操作するのは明らかに時間と労力がかかります。したがって、この記事では、効率的なデータ処理ツールである pandas と、このツールを使用して Excel ファイルをすばやく読み込んでデータ処理を実行する方法を紹介します。
1. pandas の紹介
pandas は、幅広いデータ読み取り、データ処理、およびデータ分析機能を提供する強力な Python データ分析ツールです。 pandas の主なデータ構造は DataFrame と Series で、Excel や CSV などの一般的な形式のファイルを直接読み取り、さまざまなデータ処理操作を実行できます。そのため、pandas はデータ処理の分野で広く使用されており、Python データ分析の主流ツールの 1 つとして知られています。
2. pandas で Excel ファイルを読み取る基本的な方法
pandas では、Excel ファイルを読み取るための主な関数は read_excel であり、Excel テーブルのデータを読み取り、それをデータに変換できます。データフレームオブジェクト。コードは次のとおりです。
import pandas as pd
data = pd.read_excel('test.xlsx', sheet_name='Sheet1')上記のコードでは、test.xlsx は読み込む Excel ファイルの名前、Sheet1 は読み込むシートの名前です。このように、データは Excel テーブルのデータを含む DataFrame オブジェクトです。
3. pandas で Excel ファイルを効率的に読み取るテクニック
pandas の基本的な読み取り方法は、手動で Excel を操作する場合に比べて大幅に時間を節約できますが、大量のデータを処理する場合は、 Excel ファイルの読み取りプロセスを最適化します。
1. Skiprows および nrows パラメーターを使用する
skiprows および nrows パラメーターを使用して、テーブル内の行をスキップし、指定された数の行を読み取ることができます。たとえば、次のコードは、テーブルの行 2 から行 1001 までのデータを読み取ることができます。
data = pd.read_excel('test.xlsx', sheet_name='Sheet1', skiprows=1, nrows=1000)この方法では、データの一部のみを読み取ることができるため、読み取り時間とメモリ消費量が節約されます。
2. usecols パラメーターを使用する
テーブル内のデータの特定の列のみが必要な場合は、usecols パラメーターを使用して、指定された列のみを読み取ることができます。たとえば、次のコードはテーブルの列 A と B のみを読み取ります。
data = pd.read_excel('test.xlsx', sheet_name='Sheet1', usecols=['A', 'B'])このようにして、処理する必要があるデータ列に焦点を当て、不要なデータの読み取りを回避できます。
3. チャンクサイズとイテレータ パラメータを使用する
読み取られる Excel ファイルが大きい場合は、チャンクサイズとイテレータ パラメータを使用してデータをブロック単位で読み取ることができます。たとえば、次のコードは一度に 1000 行のデータを読み取ることができます。
for i in pd.read_excel('test.xlsx', sheet_name='Sheet1', chunksize=1000):
# 处理代码このようにして、データをブロックごとに読み取り、バッチで処理して、データ処理効率を向上させることができます。
4. 完全な例
次は、パンダが Excel ファイルを読み取るための完全なサンプル コードです。このコードは、test.xlsx の Sheet1 のすべてのデータを読み取り、列 A を計算します。 . と列 B の合計を計算し、結果を出力します:
import pandas as pd
data = pd.read_excel('test.xlsx', sheet_name='Sheet1')
result = pd.DataFrame([{'sum_A': data['A'].sum(), 'sum_B': data['B'].sum()}])
result.to_excel('result.xlsx', index=False)上記のコードでは、最初に test.xlsx ファイル全体の Sheet1 を読み取り、次に sum 関数を使用して列 A の合計を計算します。と B を結合し、その結果を DataFrame オブジェクトに格納します。最後に、結果を新しい Excel ファイル result.xlsx に書き込みます。このファイルには 1 行のデータのみが含まれており、最初の列は列 A の合計、2 列目は列 B の合計です。
概要
上記の紹介を通じて、pandas を使用して Excel ファイルを読み取ると、データ処理の効率が大幅に向上し、さまざまな高度なパラメーターを使用してさらに最適化できることがわかりました。 pandas が提供するメソッド データの読み取りと処理のプロセス。したがって、データ分析と処理の分野では、パンダの使用は非常に効率的で実用的なツールです。
以上がデータ処理ツール: pandas で Excel ファイルを読み取るための効率的なテクニックの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 Excelで印刷時に枠線が消えてしまった場合はどうすればよいですか?
Mar 21, 2024 am 09:50 AM
Excelで印刷時に枠線が消えてしまった場合はどうすればよいですか?
Mar 21, 2024 am 09:50 AM
印刷が必要なファイルを開いたときに、印刷プレビューで表の枠線が何らかの原因で消えてしまった場合は、早めに対処する必要があります。 file このような質問がある場合は、エディターに参加して次のコースを学習してください: Excel で表を印刷するときに枠線が消えた場合はどうすればよいですか? 1. 次の図に示すように、印刷する必要があるファイルを開きます。 2. 以下の図に示すように、必要なコンテンツ領域をすべて選択します。 3. 以下の図に示すように、マウスを右クリックして「セルの書式設定」オプションを選択します。 4. 以下の図に示すように、ウィンドウの上部にある「境界線」オプションをクリックします。 5. 下図に示すように、左側の線種で細い実線パターンを選択します。 6.「外枠」を選択します
 Excelで3つ以上のキーワードを同時にフィルタリングする方法
Mar 21, 2024 pm 03:16 PM
Excelで3つ以上のキーワードを同時にフィルタリングする方法
Mar 21, 2024 pm 03:16 PM
Excelは日々の事務作業でデータ処理に使用されることが多く、「フィルター」機能を使用することが多いです。 Excel で「フィルタリング」を実行する場合、同じ列に対して最大 2 つの条件しかフィルタリングできません。では、Excel で同時に 3 つ以上のキーワードをフィルタリングする方法をご存知ですか?次に、それをデモンストレーションしてみましょう。 1 つ目の方法は、フィルターに条件を徐々に追加することです。条件を満たす 3 つの詳細を同時にフィルターで除外する場合は、まずそのうちの 1 つを段階的にフィルターで除外する必要があります。最初に、条件に基づいて姓が「Wang」の従業員をフィルタリングできます。 [OK]をクリックし、フィルター結果の[現在の選択をフィルターに追加]にチェックを入れます。手順は以下の通りです。同様に再度個別にフィルタリングを行う
 Excelテーブル互換モードを通常モードに変更する方法
Mar 20, 2024 pm 08:01 PM
Excelテーブル互換モードを通常モードに変更する方法
Mar 20, 2024 pm 08:01 PM
私たちは日々の仕事や勉強で、他人からExcelファイルをコピーし、そのファイルを開いて内容を追加したり、再編集したりして保存することがありますが、互換性チェックのダイアログボックスが表示されることがあり、非常に面倒です。ソフトウェア. 、通常モードに変更できますか?そこで以下では、エディターがこの問題を解決するための詳細な手順を紹介します。一緒に学びましょう。最後に、忘れずに保存してください。 1. 図に示すように、ワークシートを開き、ワークシートの名前に追加の互換モードを表示します。 2. このワークシートでは、内容を変更して保存すると、図のように互換性チェックのダイアログが必ず表示され、非常に面倒です。 3. [Office] ボタンをクリックし、[名前を付けて保存] をクリックして、
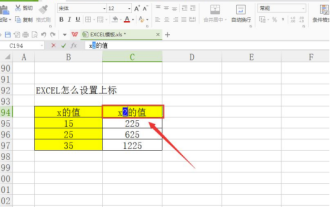 Excelで上付き文字を設定する方法
Mar 20, 2024 pm 04:30 PM
Excelで上付き文字を設定する方法
Mar 20, 2024 pm 04:30 PM
データを処理していると、倍数や温度などのさまざまな記号が含まれるデータに遭遇することがあります。 Excel で上付き文字を設定する方法をご存知ですか? Excel を使用してデータを処理する場合、上付き文字を設定しないと、大量のデータを入力するのがさらに面倒になります。今回はエクセルの上付き文字の具体的な設定方法をエディターがお届けします。 1. まず、図に示すように、デスクトップで Microsoft Office Excel ドキュメントを開き、上付き文字に変更する必要があるテキストを選択します。 2. 次に、図に示すように、右クリックして、クリック後に表示されるメニューで「セルの書式設定」オプションを選択します。 3. 次に、自動的に表示される「セルの書式設定」ダイアログボックスで
 エクセルでiif関数を使う方法
Mar 20, 2024 pm 06:10 PM
エクセルでiif関数を使う方法
Mar 20, 2024 pm 06:10 PM
ほとんどのユーザーは Excel を使用してテーブル データを処理します。実は Excel にも VBA プログラムがあります。専門家を除けば、この関数を使用したユーザーはあまり多くありません。VBA で記述するときによく使用されるのが iif 関数です。実際には、次の場合と同じです。関数の機能は似ていますが、iif関数の使い方を紹介します。 SQL ステートメントには iif 関数があり、Excel には VBA コードがあります。 iif 関数は Excel ワークシートの IF 関数と似ており、論理的に計算された真値と偽値に基づいて真偽値を判定し、異なる結果を返します。 IF 関数の使用法は (条件、はい、いいえ) です。 VBAのIF文とIIF関数、前者のIF文は条件に応じて異なる文を実行できる制御文であり、後者は条件に応じて異なる文を実行できる制御文です。
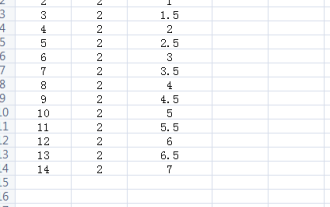 Excelの読み取りモードを設定する場所
Mar 21, 2024 am 08:40 AM
Excelの読み取りモードを設定する場所
Mar 21, 2024 am 08:40 AM
ソフトウェアの学習では、Excel が便利なだけでなく、実際の作業で必要なさまざまな形式に対応できるため、Excel の使用に慣れています。Excel は非常に柔軟に使用でき、今日は「みんなのために:Excelの読み取りモードを設定する場所」を持ってきました。 1. コンピュータの電源を入れ、Excel アプリケーションを開き、目的のデータを見つけます。 2. Excel で読み取りモードを設定するには 2 つの方法があります。 1 つ目: Excel には、Excel レイアウトで多数の便利な処理メソッドが配布されています。 Excelの右下に読み取りモードを設定するショートカットがあります。バツマークのパターンを見つけてクリックすると、読み取りモードに入ります。バツマークの右側に小さな立体マークがあります。 。
 ExcelアイコンをPPTスライドに挿入する方法
Mar 26, 2024 pm 05:40 PM
ExcelアイコンをPPTスライドに挿入する方法
Mar 26, 2024 pm 05:40 PM
1. PPT を開き、Excel アイコンを挿入する必要があるページに移動します。 「挿入」タブをクリックします。 2. [オブジェクト]をクリックします。 3. 次のダイアログボックスが表示されます。 4. [ファイルから作成]をクリックし、[参照]をクリックします。 5. 挿入する Excel テーブルを選択します。 6. [OK] をクリックすると、次のページが表示されます。 7. [アイコンで表示]にチェックを入れます。 8. 「OK」をクリックします。
 ExcelデータをHTMLで読み込む方法
Mar 27, 2024 pm 05:11 PM
ExcelデータをHTMLで読み込む方法
Mar 27, 2024 pm 05:11 PM
Excel データを HTML で読み取る方法: 1. JavaScript ライブラリを使用して Excel データを読み取ります; 2. サーバーサイド プログラミング言語を使用して Excel データを読み取ります。
