

AIビデオ生成フレームワークテストコンテスト:Pika、Gen-2、ModelScope、SEINE、誰が優勝できるでしょうか?

AI ビデオ生成は、最近最も注目されている分野の 1 つです。さまざまな大学の研究室、インターネット大手の AI Labs、新興企業が AI ビデオ生成トラックに参加しています。 Pika、Gen-2、Show-1、VideoCrafter、ModelScope、SEINE、LaVie、VideoLDM などのビデオ生成モデルのリリースはさらに目を引きます。 v⁽ⁱ⁾
誰もが次の質問に興味があるはずです:
- どのビデオ生成モデルが最適ですか?
- 各モデルの特徴は何ですか?
- AI動画生成分野で解決すべき注目すべき課題は何でしょうか?
この目的を達成するために、私たちは包括的な「ビデオ生成モデルの評価フレームワーク」である VBench を立ち上げました。これは、さまざまなビデオ生成モデルの長所、短所、特性に関する情報をユーザーに提供するように設計されています。ビデオモデル。 VBench を通じて、ユーザーはさまざまなビデオ モデルの長所と利点を理解できます。

- 論文: https://arxiv.org/abs / 2311.17982
- コード: https://github.com/Vchitect/VBench
- ウェブページ: https://vchitect.github.io /VBench -project/
- 論文タイトル: VBench: ビデオ生成モデルのための包括的なベンチマーク スイート
VBench は、包括的かつ詳細な機能を備えているだけではありません。ビデオ生成効果を正確に評価でき、また人々の感覚体験に沿った評価を提供できるため、時間とエネルギーを節約できます。
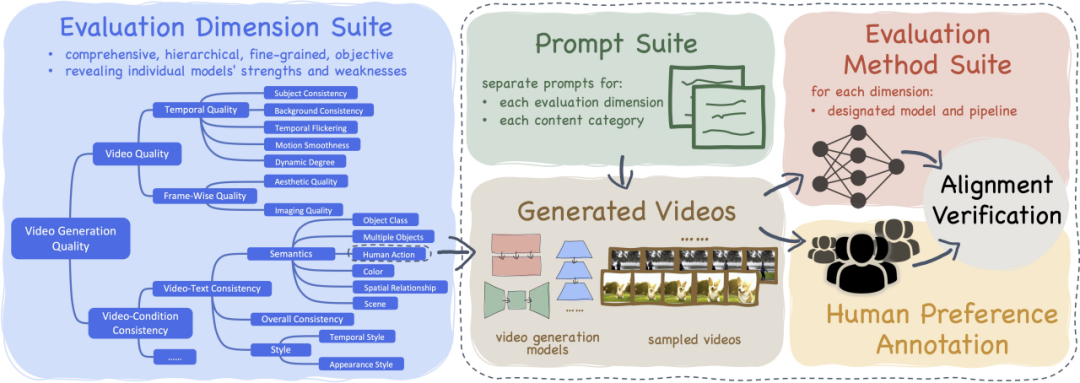
- VBench には 16 の階層化された分離された評価ディメンションが含まれています
- #VBench Wensheng ビデオの生成と評価のためのプロンプト リスト システムをオープンソース化しました
- #VBench の各側面の評価計画は人間の認識と評価と一致しています
- VBench は、AI ビデオ生成の将来の探求を容易にする多視点の洞察を提供します
「VBench」 - 「ビデオ生成モデル」包括的なベンチマーク スイート
#AI ビデオ生成モデル - 評価結果
オープンソース AI ビデオ生成モデル
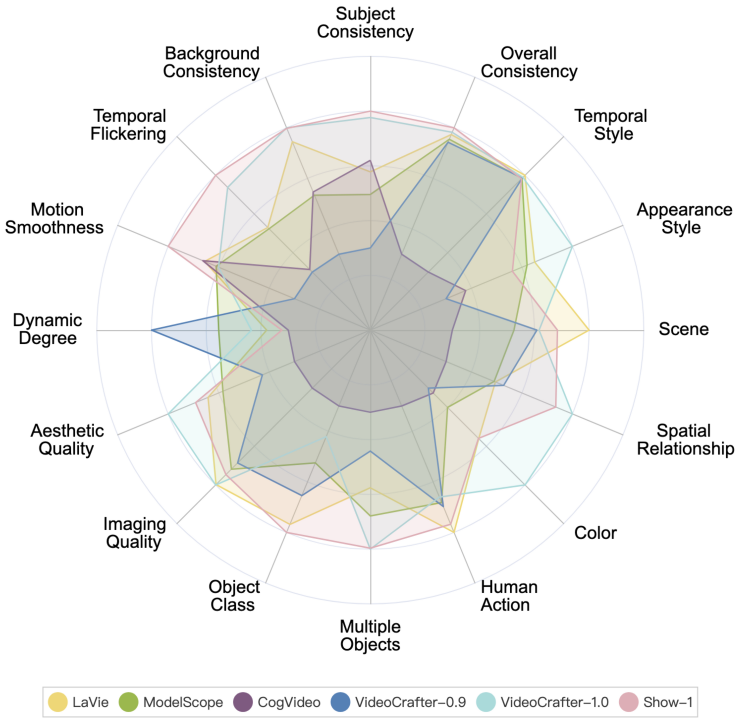
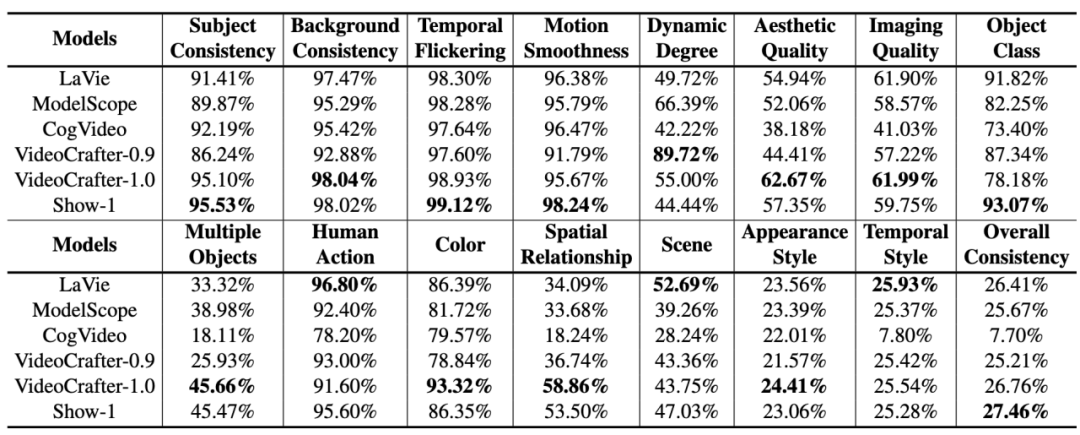
#VBench 上のさまざまなオープンソース AI ビデオ生成モデルのパフォーマンスは次のとおりです。
#VBench 上のさまざまなオープンソース AI ビデオ生成モデルのパフォーマンス。レーダー チャートでは、比較をより明確に視覚化するために、各次元の結果が 0.3 ~ 0.8 になるように正規化しました。
スタートアップのビデオ生成モデル
VBench は現在、Gen-2 と Pika の 2 つのスタートアップを提供しています 企業の評価結果モデル。
VBench での Gen-2 と Pika のパフォーマンス。レーダーチャートでは、比較をより明確に視覚化するために、VideoCrafter-1.0とShow-1をリファレンスとして追加し、各次元の評価結果が0.3~0.8になるように正規化しました。 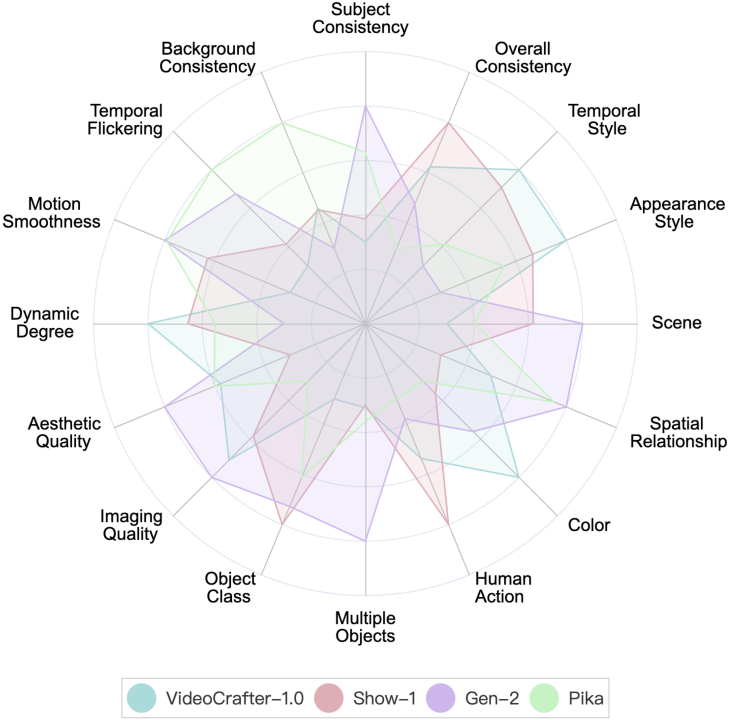
Gen-2 和 Pika 在 VBench 上的表現。我們加入了 VideoCrafter-1.0 和 Show-1 的數值結果作為參考。
可以看到,Gen-2 和Pika 在視訊品質(Video Quality)上有明顯優勢,例如時序一致性(Temporal Consistency)和單幀品質(Aesthetic Quality 和Imaging Quality)相關維度。在與使用者輸入的 prompt 的語意一致性上(例如 Human Action 和 Appearance Style),部分維度開源模型會更勝一籌。
影片產生模型VS 圖片產生模型
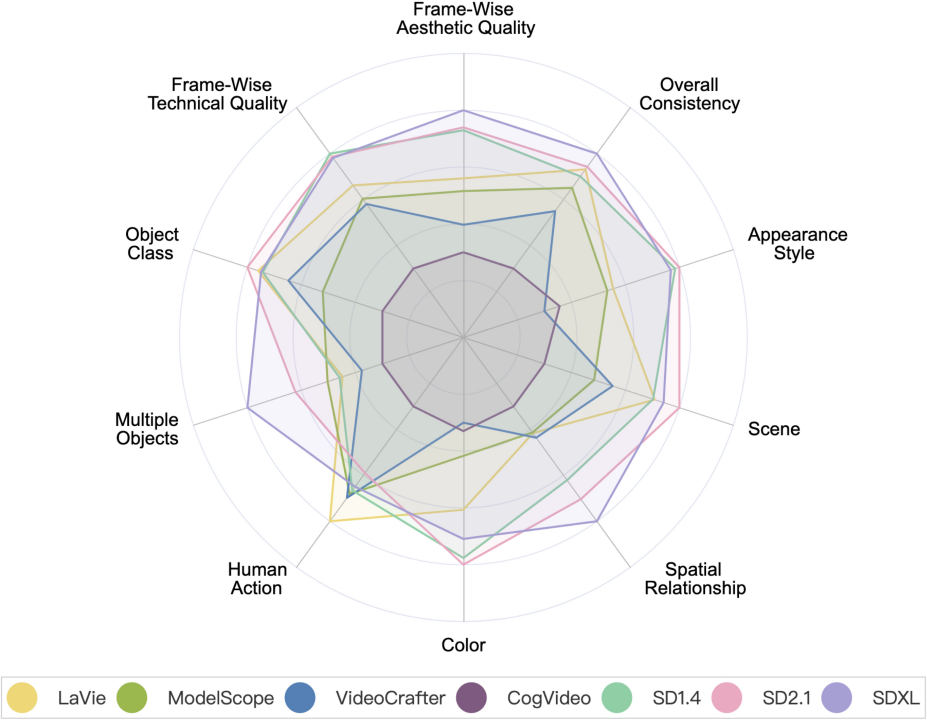
影片產生模型VS圖片生成模型。其中 SD1.4,SD2.1 和 SDXL 是圖片產生模型。
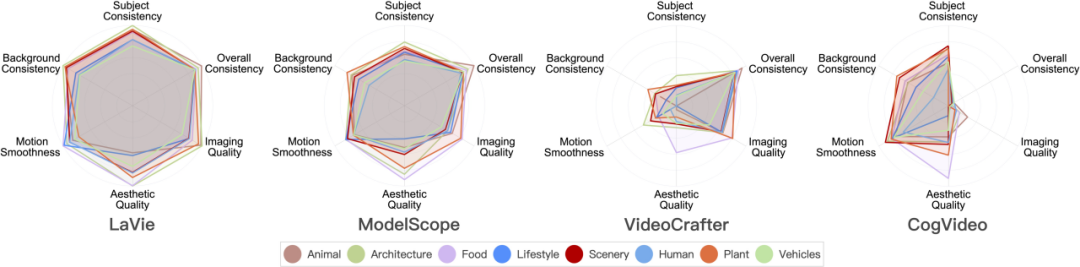
影片產生模型在8 大場景類別上的表現
#下面是不同模型在8 個不同類別上的評測結果。
VBench 現已開源,一鍵即可安裝
目前,VBench 已全面開源,且支援一鍵安裝。歡迎大家來玩,測試一下有興趣的模型,一起推動影片生成社群的發展。



開源位址:https://github.com/Vchitect/VBench
我們也開源了一系列Prompt List :https://github.com/Vchitect/VBench/tree/master/prompts,包含在不同能力維度上用於評測的Benchmark,以及在不同場景內容上的評測Benchmark。
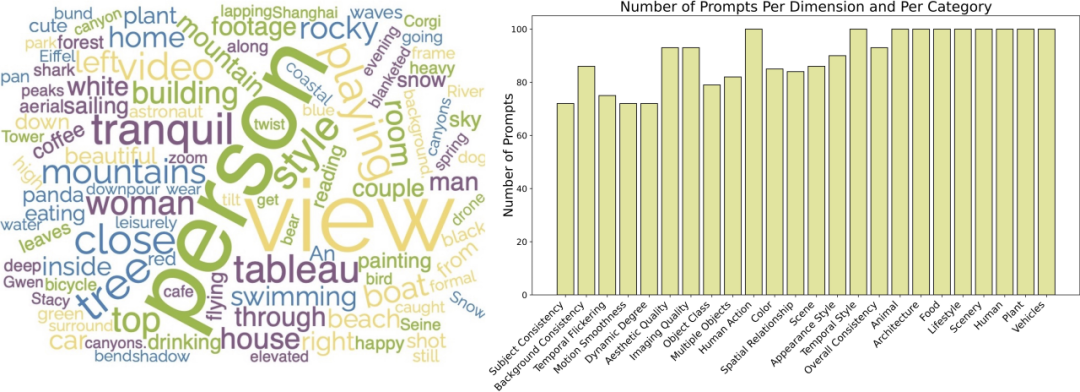
左邊詞雲展示了我們 Prompt Suites 的高頻詞分佈,右圖展示了不同維度和類別的 prompt 數量統計。
VBench 準不準?
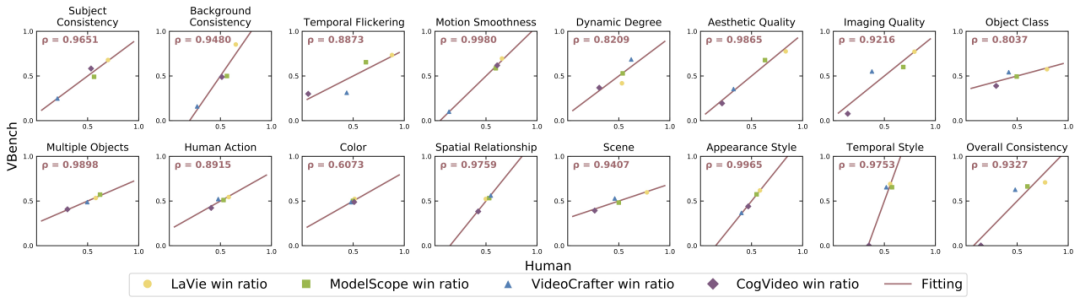
針對每個向度,我們計算了 VBench 評測結果與人工評測結果之間的相關度,進而驗證我們方法與人類觀感的一致性。下圖中,橫軸代表不同維度的人工評測結果,縱軸則展示了 VBench 方法自動評測的結果,可以看到我們方法在各個維度都與人類感知高度對齊。
VBench 帶給AI 影片產生的思考
VBench 不僅可以對現有模型進行評測,更重要的是,還可以發現不同模型中可能存在的各種問題,為未來AI 視訊生成的發展提供有價值的insights。
「時序連貫性」以及「影片的動態程度」:不要二選一,而應同時提升
我們發現時序連貫性(例如Subject Consistency、Background Consistency、Motion Smoothness)與影片中運動的幅度(Dynamic Degree)之間有一定的權衡關係。比方說,Show-1 和VideoCrafter-1.0 在背景一致性和動作流暢度方面表現很好,但在動態程度方面得分較低;這可能是因為產生 「沒有動起來」 的畫面更容易顯得「在時序上很連貫」。另一方面,VideoCrafter-0.9 在與時序一致性的維度上弱一些,但在 Dynamic Degree 上得分很高。
這說明,同時做好「時序連貫性」 和「較高的動態程度」 確實挺難的;未來不應只關注其中一方面的提升,而應該同時提升「時序連貫性」以及「影片的動態程度」 這兩方面,這才是有意義的。
分場景內容進行評測,發掘各家模型潛力
有些模型在不同類別上表現出的表現有較大差異,例如在美學品質(Aesthetic Quality)上,CogVideo 在「Food」 類別上表現不錯,而在「LifeStyle」 類別得分較低。如果透過訓練資料的調整,CogVideo 在 “LifeStyle” 這些類別上的美學品質是否可以提升上去,進而提升模型整體的視訊美學品質?
這也告訴我們,在評估影片產生模型時,需要考慮模型在不同類別或主題下的表現,挖掘模型在某個能力維度的上限,進而針對性地提升「拖後腿」 的場景類別。
有複雜運動的類別:時空表現都不佳
#在空間上複雜度高的類別,在美學品質維度得分都比較低。例如,「LifeStyle」 類別對複雜元素在空間中的佈局有比較高的要求,而「Human」 類別則由於鉸鍊式結構的產生帶來了挑戰。
對於時序複雜的類別,例如「Human」 類別通常涉及複雜的動作、「Vehicle」 類別會經常出現較快的移動,它們在所有測試的維度上得分都相對較低。這表明目前模型在處理時序建模方面仍然存在一定的不足,時序上的建模限制可能會導致空間上的模糊與扭曲,從而導致影片在時間和空間上的品質都不理想。
難產生的類別:提升資料量效益不大
我們對常用的影片資料集WebVid- 10M 進行了統計,發現其中約有26% 的數據與「Human」 有關,在我們統計的八個類別中佔比最高。然而,在評估結果中,「Human」 類別卻是八個類別中表現最差的之一。
這說明對於「Human」 這樣複雜的類別,僅增加資料量可能不會對效能帶來顯著的改善。一個潛在的方法是透過引入 「Human」 相關的先驗知識或控制,例如 Skeletons 等,來指導模型的學習。
百萬量級的資料集:提升資料品質優先於資料量
「Food」 類別雖然在WebVid-10M 中僅佔11%,但在評測中幾乎總是擁有最高的美學品質分數。於是我們進一步分析了 WebVid-10M 資料集不同類別內容的美學品質表現,發現 「Food」 類別在 WebVid-10M 中也有最高的美學評分。
這意味著,在百萬量級資料的基礎上,篩選 / 提升資料品質比增加資料量更有幫助。
待提升的能力:準確生成生成多物體,以及物體間的關係
##目前的影片生成模型在「多物件生成」(Multiple Objects)和「空間關係」(Spatial Relationship)方面還是追不上圖片產生模型(尤其是SDXL),凸顯了提升組合能力的重要性。所謂組合能力指的是模型在影片生成中是否能準確展示多個對象,及它們之間的空間及互動關係。
解決此問題的潛在方法可能包括:
- #資料打標:建立影片資料集,提供對影片中多個物體的明確描述,以及物體間空間位置關係以及互動關係的描述。
- 在影片產生過程中加入中間模態 / 模組來輔助控制物件的組合和空間位置關係。
- 使用更好的文字編碼器(Text Encoder)也會對模型的組合產生能力有比較大的影響。
- 曲線救國:將 T2V 做不好的 「物體組合」 問題交給 T2I,透過 T2I I2V 的方式來產生影片。這做法針對其他很多影片生成的問題或許也有效。 #
以上がAIビデオ生成フレームワークテストコンテスト:Pika、Gen-2、ModelScope、SEINE、誰が優勝できるでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
