

蒸留モデルの基本概念


モデル蒸留は、大規模で複雑なニューラル ネットワーク モデル (教師モデル) から小規模で単純なニューラル ネットワーク モデル (学生モデル) に知識を転送する方法です。このようにして、学生モデルは教師モデルから知識を得ることができ、パフォーマンスと汎化パフォーマンスが向上します。
通常、大規模なニューラル ネットワーク モデル (教師モデル) は、トレーニング中に多くのコンピューティング リソースと時間を消費します。比較すると、小規模なニューラル ネットワーク モデル (スチューデント モデル) は高速に実行され、計算コストが低くなります。モデルのサイズと計算コストを小さく保ちながら学生モデルのパフォーマンスを向上させるには、モデル蒸留手法を使用して教師モデルの知識を学生モデルに転送します。この転送プロセスは、教師モデルの出力確率分布を生徒モデルのターゲットとすることで実現できます。このようにして、学生モデルは教師モデルの知識を学習し、より小さなモデル サイズと計算コストを維持しながら、より優れたパフォーマンスを示すことができます。
モデルの抽出方法は、教師モデルのトレーニングと生徒モデルのトレーニングの 2 つのステップに分けることができます。教師モデルのトレーニング プロセスでは、通常、深層学習の一般的なアルゴリズム (畳み込みニューラル ネットワーク、リカレント ニューラル ネットワークなど) を使用して大規模なニューラル ネットワーク モデルをトレーニングし、より高い精度と汎化パフォーマンスを実現します。スチューデント モデルのトレーニング プロセス中に、より小さなニューラル ネットワーク構造といくつかの特定のトレーニング テクニック (温度スケーリング、知識の蒸留など) がモデル蒸留の効果を達成するために使用され、それによってモデルの精度と一般化が向上します。学生モデルのパフォーマンス。このようにして、学生モデルは教師モデルからより豊富な知識と情報を取得し、低い計算リソース消費量を維持しながらより優れたパフォーマンスを達成できます。
たとえば、複数の畳み込み層と全結合層で構成される画像分類用の大規模なニューラル ネットワーク モデルがあり、トレーニング データ セットには 100,000 個の画像が含まれているとします。ただし、モバイル デバイスや組み込みデバイスのコンピューティング リソースとストレージ スペースには限りがあるため、この大規模なモデルはこれらのデバイスに直接適用できない場合があります。この問題を解決するために、モデル蒸留法を使用できます。 モデルの蒸留は、大きなモデルから小さなモデルに知識を転送する手法です。具体的には、大規模なモデル (教師モデル) を使用してトレーニング データでトレーニングし、教師モデルの出力をラベルとして使用し、次に小規模なニューラル ネットワーク モデル (スチューデント モデル) をトレーニングに使用できます。生徒モデルは教師モデルの出力を学習することで教師モデルの知識を得ることができます。 モデルの蒸留を使用すると、分類精度をあまり犠牲にすることなく、組み込みデバイス上でより小さな学生モデルを実行できます。スチューデント モデルはパラメータが少なく、計算スペースとストレージの要件が低いため、組み込みデバイスのリソース制約を満たすことができます。 要約すると、モデルの蒸留は、モバイルまたは組み込みデバイスの制約に対応するために、大規模なモデルから小規模なモデルに知識を転送する効率的な方法です。このようにして、教師モデルにソフトマックス レイヤーを追加することで、各カテゴリの出力をスケーリング (温度スケーリング) することができ、出力がよりスムーズになります。これにより、モデルの過学習現象が軽減され、モデルの汎化能力が向上します。その後、教師モデルを使用してトレーニング セットでトレーニングし、教師モデルの出力を生徒モデルのターゲット出力として使用することで、知識の蒸留を達成できます。このようにして、学生モデルは教師モデルの知識指導を通じて学習することができ、より高い精度を達成することができます。次に、学生モデルを使用してトレーニング セットでトレーニングし、学生モデルが教師モデルの知識をよりよく学習できるようにします。最終的には、組み込みデバイス上で実行される、より小型でより正確な学生モデルを取得できるようになります。この知識の蒸留方法により、リソースが限られた組み込みデバイス上で効率的なモデルの展開を実現できます。
モデル蒸留法の手順は次のとおりです:
1. 教師ネットワークのトレーニング: まず、大規模で複雑なモデルが必要です。それが教師ネットワークです。このモデルには通常、学生ネットワークよりもはるかに多くのパラメータがあり、より長いトレーニングが必要になる場合があります。教師ネットワークのタスクは、入力データから有用な特徴を抽出し、最良の予測を生成する方法を学習することです。
2. パラメータの定義: モデルの蒸留では、教師ネットワークの出力を確率分布に変換できる「ソフト ターゲット」と呼ばれる概念を使用します。学生ネットワークへ。これを達成するために、出力確率分布がどれだけ滑らかかを制御する「温度」と呼ばれるパラメータを使用します。温度が高いほど確率分布は滑らかになり、温度が低いほど確率分布はシャープになります。
3. 損失関数の定義: 次に、生徒ネットワークの出力と教師ネットワークの出力の差を定量化する損失関数を定義する必要があります。クロスエントロピーは損失関数として一般的に使用されますが、ソフト ターゲットで使用できるように変更する必要があります。
4. 学生ネットワークのトレーニング: ここで、学生ネットワークのトレーニングを開始できます。トレーニング プロセス中に、学生ネットワークは、より良く学習するための追加情報として教師ネットワークのソフト ターゲットを受け取ります。同時に、いくつかの追加の正則化手法を使用して、結果として得られるモデルをよりシンプルでトレーニングしやすくすることもできます。
5. 微調整と評価: 学生ネットワークがトレーニングされたら、それを微調整して評価できます。微調整プロセスの目的は、モデルのパフォーマンスをさらに向上させ、新しいデータ セットに確実に適用できるようにすることです。通常、評価プロセスには、学生ネットワークと教師ネットワークのパフォーマンスを比較して、学生ネットワークが高いパフォーマンスを維持しながら、モデル サイズが小さくなり、推論速度が向上していることを確認することが含まれます。
全体として、モデル蒸留は、良好なパフォーマンスを維持しながら、より軽量で効率的なディープ ニューラル ネットワーク モデルを生成するのに役立つ非常に便利な手法です。画像分類、自然言語処理、音声認識などの分野を含む、さまざまなタスクやアプリケーションに適用できます。
以上が蒸留モデルの基本概念の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7725
7725
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 RNN、LSTM、GRU の概念、違い、長所と短所を調べる
Jan 22, 2024 pm 07:51 PM
RNN、LSTM、GRU の概念、違い、長所と短所を調べる
Jan 22, 2024 pm 07:51 PM
時系列データでは、観測間に依存関係があるため、相互に独立していません。ただし、従来のニューラル ネットワークは各観測値を独立したものとして扱うため、時系列データをモデル化するモデルの能力が制限されます。この問題を解決するために、リカレント ニューラル ネットワーク (RNN) が導入されました。これは、ネットワーク内のデータ ポイント間の依存関係を確立することにより、時系列データの動的特性をキャプチャするためのメモリの概念を導入しました。反復接続を通じて、RNN は以前の情報を現在の観測値に渡して、将来の値をより適切に予測できます。このため、RNN は時系列データを含むタスクにとって強力なツールになります。しかし、RNN はどのようにしてこの種の記憶を実現するのでしょうか? RNN は、ニューラル ネットワーク内のフィードバック ループを通じて記憶を実現します。これが RNN と従来のニューラル ネットワークの違いです。
 テキスト分類に双方向 LSTM モデルを使用するケーススタディ
Jan 24, 2024 am 10:36 AM
テキスト分類に双方向 LSTM モデルを使用するケーススタディ
Jan 24, 2024 am 10:36 AM
双方向 LSTM モデルは、テキスト分類に使用されるニューラル ネットワークです。以下は、テキスト分類タスクに双方向 LSTM を使用する方法を示す簡単な例です。まず、必要なライブラリとモジュールをインポートする必要があります: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 ニューラル ネットワークの浮動小数点オペランド (FLOPS) の計算
Jan 22, 2024 pm 07:21 PM
ニューラル ネットワークの浮動小数点オペランド (FLOPS) の計算
Jan 22, 2024 pm 07:21 PM
FLOPS はコンピュータの性能評価の規格の 1 つで、1 秒あたりの浮動小数点演算の回数を測定するために使用されます。ニューラル ネットワークでは、モデルの計算の複雑さとコンピューティング リソースの使用率を評価するために FLOPS がよく使用されます。これは、コンピューターの計算能力と効率を測定するために使用される重要な指標です。ニューラル ネットワークは、データ分類、回帰、クラスタリングなどのタスクを実行するために使用される、複数のニューロン層で構成される複雑なモデルです。ニューラル ネットワークのトレーニングと推論には、多数の行列の乗算、畳み込み、その他の計算操作が必要となるため、計算の複雑さは非常に高くなります。 FLOPS (FloatingPointOperationsperSecond) を使用すると、ニューラル ネットワークの計算の複雑さを測定し、モデルの計算リソースの使用効率を評価できます。フロップ
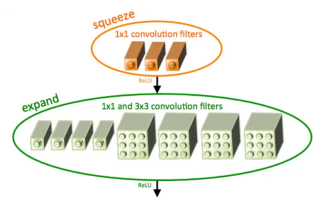 SqueezeNet の概要とその特徴
Jan 22, 2024 pm 07:15 PM
SqueezeNet の概要とその特徴
Jan 22, 2024 pm 07:15 PM
SqueezeNet は、高精度と低複雑性のバランスが取れた小型で正確なアルゴリズムであり、リソースが限られているモバイル システムや組み込みシステムに最適です。 2016 年、DeepScale、カリフォルニア大学バークレー校、スタンフォード大学の研究者は、コンパクトで効率的な畳み込みニューラル ネットワーク (CNN) である SqueezeNet を提案しました。近年、研究者は SqueezeNetv1.1 や SqueezeNetv2.0 など、SqueezeNet にいくつかの改良を加えました。両方のバージョンの改良により、精度が向上するだけでなく、計算コストも削減されます。 ImageNet データセット上の SqueezeNetv1.1 の精度
 ファジーニューラルネットワークの定義と構造解析
Jan 22, 2024 pm 09:09 PM
ファジーニューラルネットワークの定義と構造解析
Jan 22, 2024 pm 09:09 PM
ファジー ニューラル ネットワークは、ファジー ロジックとニューラル ネットワークを組み合わせたハイブリッド モデルで、従来のニューラル ネットワークでは処理が困難なファジーまたは不確実な問題を解決します。その設計は人間の認知における曖昧さと不確実性にインスピレーションを得ているため、制御システム、パターン認識、データマイニングなどの分野で広く使用されています。ファジー ニューラル ネットワークの基本アーキテクチャは、ファジー サブシステムとニューラル サブシステムで構成されます。ファジー サブシステムは、ファジー ロジックを使用して入力データを処理し、それをファジー セットに変換して、入力データの曖昧さと不確実性を表現します。ニューラル サブシステムは、ニューラル ネットワークを使用して、分類、回帰、クラスタリングなどのタスクのファジー セットを処理します。ファジー サブシステムとニューラル サブシステム間の相互作用により、ファジー ニューラル ネットワークはより強力な処理能力を持ち、
 畳み込みニューラル ネットワークを使用した画像のノイズ除去
Jan 23, 2024 pm 11:48 PM
畳み込みニューラル ネットワークを使用した画像のノイズ除去
Jan 23, 2024 pm 11:48 PM
畳み込みニューラル ネットワークは、画像のノイズ除去タスクで優れたパフォーマンスを発揮します。学習したフィルターを利用してノイズを除去し、元の画像を復元します。この記事では、畳み込みニューラル ネットワークに基づく画像ノイズ除去方法を詳しく紹介します。 1. 畳み込みニューラル ネットワークの概要 畳み込みニューラル ネットワークは、複数の畳み込み層、プーリング層、全結合層の組み合わせを使用して画像の特徴を学習および分類する深層学習アルゴリズムです。畳み込み層では、畳み込み演算を通じて画像の局所的な特徴が抽出され、それによって画像内の空間相関が捕捉されます。プーリング層は、特徴の次元を削減することで計算量を削減し、主要な特徴を保持します。完全に接続された層は、学習した特徴とラベルをマッピングして画像分類やその他のタスクを実装する役割を果たします。このネットワーク構造の設計により、畳み込みニューラル ネットワークは画像処理と認識に役立ちます。
 因果畳み込みニューラル ネットワーク
Jan 24, 2024 pm 12:42 PM
因果畳み込みニューラル ネットワーク
Jan 24, 2024 pm 12:42 PM
因果畳み込みニューラル ネットワークは、時系列データの因果関係の問題のために設計された特別な畳み込みニューラル ネットワークです。従来の畳み込みニューラル ネットワークと比較して、因果畳み込みニューラル ネットワークは、時系列の因果関係を保持するという独特の利点があり、時系列データの予測と分析に広く使用されています。因果畳み込みニューラル ネットワークの中心的なアイデアは、畳み込み演算に因果関係を導入することです。従来の畳み込みニューラルネットワークは、現時点の前後のデータを同時に認識できますが、時系列予測では情報漏洩の問題が発生する可能性があります。現時点での予測結果は、将来の時点のデータに影響を受けるからです。この問題を解決するのが因果畳み込みニューラル ネットワークであり、現時点と過去のデータのみを認識することができ、将来のデータを認識することはできません。
 拡張コンボリューションとアトラスコンボリューションの類似点、相違点、および関係を比較します。
Jan 22, 2024 pm 10:27 PM
拡張コンボリューションとアトラスコンボリューションの類似点、相違点、および関係を比較します。
Jan 22, 2024 pm 10:27 PM
拡張畳み込みと拡張畳み込みは、畳み込みニューラル ネットワークでよく使用される演算です。この記事では、それらの違いと関係について詳しく紹介します。 1. 拡張畳み込み 拡張畳み込みは、拡張畳み込みまたは拡張畳み込みとも呼ばれる、畳み込みニューラル ネットワークの演算です。これは、従来の畳み込み演算に基づいた拡張であり、畳み込みカーネルに穴を挿入することで畳み込みカーネルの受容野を増加させます。これにより、ネットワークはより広範囲の機能をより適切に捕捉できるようになります。拡張コンボリューションは画像処理の分野で広く使用されており、パラメータの数や計算量を増やすことなくネットワークのパフォーマンスを向上させることができます。コンボリューション カーネルの受容野を拡張することにより、拡張コンボリューションは画像内のグローバル情報をより適切に処理できるようになり、それによって特徴抽出の効果が向上します。拡張畳み込みの主なアイデアは、いくつかの要素を導入することです。
