

次元削減アルゴリズムを使用してターゲット検出を実現する: ヒントと手順


オブジェクト検出はコンピューター ビジョンにおける重要なタスクであり、その目標は画像またはビデオ内の対象オブジェクトを識別して位置を特定することです。次元削減アルゴリズムは、高次元の画像データを低次元の特徴表現に変換することにより、ターゲット検出に一般的に使用される方法です。これらの機能により、ターゲットの重要な情報を効果的に表現することができ、ターゲット検出の精度と効率をサポートします。
ステップ 1: データ セットの準備
まず、元の画像と対応する関心領域を含むラベル付きデータ セットを準備します。これらの領域は、手動で注釈を付けることも、既存の物体検出アルゴリズムを使用して生成することもできます。各領域には、境界ボックスとカテゴリ情報で注釈を付ける必要があります。
#ステップ 2: モデルを構築する #ターゲット検出タスクを達成するには、通常、深層学習モデルを構築する必要があります。元の画像を入力として受け取り、対象領域の境界ボックス座標を出力できます。一般的なアプローチは、畳み込みニューラル ネットワーク (CNN) に基づく回帰モデルを使用することです。このモデルをトレーニングすることにより、画像から境界ボックス座標へのマッピングを学習して、関心領域を検出できます。この次元削減アルゴリズムにより、入力データの次元を効果的に削減し、ターゲットの検出に関連する特徴情報を抽出できるため、検出パフォーマンスが向上します。 ステップ 3: モデルのトレーニング データ セットとモデルを準備したら、モデルのトレーニングを開始できます。トレーニングの目標は、モデルが関心領域の境界ボックス座標をできるだけ正確に予測できるようにすることです。一般的な損失関数は平均二乗誤差 (MSE) で、予測された境界ボックスの座標と実際の座標の差を測定します。勾配降下法などの最適化アルゴリズムを使用して損失関数を最小化し、それによってモデルの重みパラメーターを更新できます。 ステップ 4: モデルをテストする トレーニングが完了したら、テスト データ セットを使用してモデルのパフォーマンスを評価できます。 。テスト時に、モデルはテスト データセット内の画像に適用され、予測された境界ボックスの座標が出力されます。次に、予測された境界ボックスとグラウンド トゥルースの注釈が付けられた境界ボックスを比較することによって、モデルの精度が評価されます。一般的に使用される評価指標には、精度、再現率、mAP などが含まれます。#ステップ 5: モデルを適用する
テストに合格したら、トレーニングされたモデルを実際のターゲット検出タスクに適用できます。入力画像ごとに、モデルは対象領域の境界ボックス座標を出力して、ターゲット オブジェクトを検出します。必要に応じて、出力境界ボックスを非最大値抑制 (NMS) などの後処理して、検出結果の精度を向上させることができます。
このうち、モデルを構築するステップ 2 は重要なステップであり、畳み込みニューラル ネットワークなどの深層学習テクノロジを使用して実現できます。トレーニングとテストのプロセス中に、適切な損失関数と評価メトリクスを使用してモデルのパフォーマンスを測定する必要があります。最終的には、実用化することで、対象物の正確な検出が可能になります。
次元削減アルゴリズムを使用してターゲット検出を実現する例
具体的な方法と手順を紹介した後、実装例を見てみましょう。以下は、次元削減アルゴリズムを使用してオブジェクト検出を実装する方法を示す、Python で記述された簡単な例です。
import numpy as np
import cv2
# 准备数据集
image_path = 'example.jpg'
annotation_path = 'example.json'
image = cv2.imread(image_path)
with open(annotation_path, 'r') as f:
annotations = np.array(json.load(f))
# 构建模型
model = cv2.dnn.readNetFromCaffe('deploy.prototxt', 'res101_iter_70000.caffemodel')
blob = cv2.dnn.blobFromImage(image, scalefactor=0.007843, size=(224, 224), mean=(104.0, 117.0, 123.0), swapRB=False, crop=False)
model.setInput(blob)
# 训练模型
output = model.forward()
indices = cv2.dnn.NMSBoxes(output, score_threshold=0.5, nms_threshold=0.4)
# 应用模型
for i in indices[0]:
box = output[i, :4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
cv2.imshow('Output', image)
cv2.waitKey(0)このコード例では、OpenCV ライブラリを使用してオブジェクト検出を実装します。まず、元の画像とそれに対応する関心領域を含むラベル付きデータ セットを準備する必要があります。この例では、アノテーション情報を含む JSON ファイルがすでにあることを前提としています。次に、ここでは事前トレーニングされた ResNet101 モデルを使用して、深層学習モデルを構築します。次に、モデルが入力画像に適用されて、予測された境界ボックスの座標が取得されます。最後に、予測された境界ボックスが画像に適用され、出力が表示されます。
以上が次元削減アルゴリズムを使用してターゲット検出を実現する: ヒントと手順の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7445
7445
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 Gray Wolf 最適化アルゴリズム (GWO) とその長所と短所の詳細な分析
Jan 19, 2024 pm 07:48 PM
Gray Wolf 最適化アルゴリズム (GWO) とその長所と短所の詳細な分析
Jan 19, 2024 pm 07:48 PM
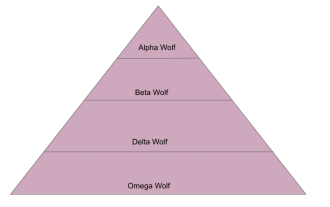
ハイイロオオカミ最適化アルゴリズム (GWO) は、自然界のハイイロオオカミのリーダーシップ階層と狩猟メカニズムをシミュレートする個体群ベースのメタヒューリスティック アルゴリズムです。ハイイロオオカミ アルゴリズムのインスピレーション 1. ハイイロオオカミは頂点捕食者であると考えられており、食物連鎖の頂点に位置します。 2. ハイイロオオカミは集団で生活すること(集団生活)を好み、各群れには平均 5 ~ 12 頭のオオカミがいます。 3. ハイイロオオカミには、以下に示すように、非常に厳格な社会的支配階層があります。 アルファオオカミ: アルファオオカミは、ハイイロオオカミのグループ全体で支配的な地位を占め、ハイイロオオカミのグループ全体を指揮する権利を持っています。アルゴリズムの適用において、Alpha Wolf は最良のソリューションの 1 つであり、最適化アルゴリズムによって生成される最適なソリューションです。ベータ オオカミ: ベータ オオカミはアルファ オオカミに定期的に報告し、アルファ オオカミが最善の決定を下せるように支援します。アルゴリズム アプリケーションでは、Beta Wolf は次のことができます。
 シングルステージターゲット検出アルゴリズムとデュアルステージターゲット検出アルゴリズムの違い
Jan 23, 2024 pm 01:48 PM
シングルステージターゲット検出アルゴリズムとデュアルステージターゲット検出アルゴリズムの違い
Jan 23, 2024 pm 01:48 PM
物体検出はコンピュータ ビジョンの分野で重要なタスクであり、画像やビデオ内の物体を識別し、その位置を特定するために使用されます。このタスクは通常、精度と堅牢性の点で異なる 2 つのカテゴリのアルゴリズム (1 段階と 2 段階) に分類されます。 1 段階ターゲット検出アルゴリズム 1 段階ターゲット検出アルゴリズムは、ターゲットの検出を分類問題に変換するアルゴリズムであり、高速で、わずか 1 ステップで検出を完了できるという利点があります。ただし、単純化しすぎたため、精度は通常、2 段階の物体検出アルゴリズムほど良くありません。一般的な 1 段階ターゲット検出アルゴリズムには、YOLO、SSD、FasterR-CNN などがあります。これらのアルゴリズムは通常、画像全体を入力として受け取り、分類器を実行してターゲット オブジェクトを識別します。従来の 2 段階のターゲット検出アルゴリズムとは異なり、事前にエリアを定義する必要はなく、直接予測します。
 ネストされたサンプリング アルゴリズムの基本原理と実装プロセスを調べる
Jan 22, 2024 pm 09:51 PM
ネストされたサンプリング アルゴリズムの基本原理と実装プロセスを調べる
Jan 22, 2024 pm 09:51 PM
ネストされたサンプリング アルゴリズムは、複雑な確率分布の下で積分または合計を計算するために使用される効率的なベイズ統計推論アルゴリズムです。これは、パラメーター空間を等しい体積の複数のハイパーキューブに分解し、最小体積のハイパーキューブの 1 つを徐々に反復的に「押し出し」、そのハイパーキューブをランダムなサンプルで満たして、確率分布の整数値をより適切に推定することによって機能します。ネストされたサンプリング アルゴリズムは、継続的な反復を通じて、高精度の整数値とパラメーター空間の境界を取得でき、モデルの比較、パラメーターの推定、モデルの選択などの統計的問題に適用できます。このアルゴリズムの中心的な考え方は、複雑な積分問題を一連の単純な積分問題に変換し、パラメーター空間の体積を徐々に減らすことで実際の積分値に近づくことです。各反復ステップはパラメータ空間からランダムにサンプリングします。
 AI テクノロジーを使用して古い写真を復元する方法 (例とコード分析付き)
Jan 24, 2024 pm 09:57 PM
AI テクノロジーを使用して古い写真を復元する方法 (例とコード分析付き)
Jan 24, 2024 pm 09:57 PM
古い写真の修復は、人工知能テクノロジーを使用して古い写真を修復、強化、改善する方法です。このテクノロジーは、コンピューター ビジョンと機械学習アルゴリズムを使用して、古い写真の損傷や欠陥を自動的に特定して修復し、写真をより鮮明に、より自然に、より現実的に見せることができます。古い写真の復元の技術原則には、主に次の側面が含まれます: 1. 画像のノイズ除去と強化 古い写真を復元する場合、最初にノイズ除去と強化を行う必要があります。平均値フィルタリング、ガウス フィルタリング、バイラテラル フィルタリングなどの画像処理アルゴリズムとフィルタを使用して、ノイズやカラー スポットの問題を解決し、写真の品質を向上させることができます。 2. 画像の修復と修復 古い写真には、傷、ひび割れ、色あせなどの欠陥や損傷がある場合があります。これらの問題は、画像の復元および修復アルゴリズムによって解決できます。
 画像超解像再構成におけるAI技術の応用
Jan 23, 2024 am 08:06 AM
画像超解像再構成におけるAI技術の応用
Jan 23, 2024 am 08:06 AM
超解像度画像再構成は、畳み込みニューラル ネットワーク (CNN) や敵対的生成ネットワーク (GAN) などの深層学習技術を使用して、低解像度画像から高解像度画像を生成するプロセスです。この方法の目的は、低解像度の画像を高解像度の画像に変換することで、画像の品質と詳細を向上させることです。この技術は、医療画像、監視カメラ、衛星画像など、さまざまな分野で幅広く応用されています。超解像度画像再構成により、より鮮明で詳細な画像を取得できるため、画像内のターゲットや特徴をより正確に分析および識別することができます。再構成方法 超解像度画像の再構成方法は、一般に、補間ベースの方法と深層学習ベースの方法の 2 つのカテゴリに分類できます。 1) 補間による手法 補間による超解像画像再構成
 Sparrow Search Algorithm (SSA) の原理、モデル、構成を分析する
Jan 19, 2024 pm 10:27 PM
Sparrow Search Algorithm (SSA) の原理、モデル、構成を分析する
Jan 19, 2024 pm 10:27 PM
スズメ検索アルゴリズム (SSA) は、スズメの対捕食行動と採餌行動に基づいたメタヒューリスティック最適化アルゴリズムです。スズメの採餌行動は、生産者とスカベンジャーの 2 つの主なタイプに分類できます。生産者は積極的に食料を探しますが、スカベンジャーは生産者からの食料を奪い合います。スズメ検索アルゴリズム (SSA) の原理 スズメ検索アルゴリズム (SSA) では、各スズメは隣のスズメの行動に細心の注意を払います。さまざまな採餌戦略を採用することで、個体は蓄えられたエネルギーを効率的に利用して、より多くの食物を追求することができます。さらに、鳥は探索空間では捕食者に対してより脆弱であるため、より安全な場所を見つける必要があります。コロニーの中心にいる鳥は、隣の鳥の近くにいることで、自分自身の危険範囲を最小限に抑えることができます。鳥は捕食者を見つけると、警報を発します。
 id3 アルゴリズムにおける情報獲得の役割は何ですか?
Jan 23, 2024 pm 11:27 PM
id3 アルゴリズムにおける情報獲得の役割は何ですか?
Jan 23, 2024 pm 11:27 PM
ID3 アルゴリズムは、決定木学習の基本アルゴリズムの 1 つです。各特徴の情報ゲインを計算して決定木を生成することにより、最適な分割点を選択します。情報ゲインは ID3 アルゴリズムの重要な概念であり、分類タスクに対する特徴の寄与を測定するために使用されます。この記事では、ID3 アルゴリズムにおける情報ゲインの概念、計算方法、応用について詳しく紹介します。 1. 情報エントロピーの概念 情報エントロピーは情報理論の概念であり、確率変数の不確実性を測定します。離散乱数の場合、p(x_i) は乱数 X が値 x_i をとる確率を表します。手紙
 Wu-Manber アルゴリズムと Python 実装手順の概要
Jan 23, 2024 pm 07:03 PM
Wu-Manber アルゴリズムと Python 実装手順の概要
Jan 23, 2024 pm 07:03 PM
Wu-Manber アルゴリズムは、文字列を効率的に検索するために使用される文字列一致アルゴリズムです。これは、Boyer-Moore アルゴリズムと Knuth-Morris-Pratt アルゴリズムの利点を組み合わせたハイブリッド アルゴリズムで、高速かつ正確なパターン マッチングを提供します。 Wu-Manber アルゴリズムのステップ 1. パターンの考えられる各部分文字列を、その部分文字列が出現するパターン位置にマップするハッシュ テーブルを作成します。 2. このハッシュ テーブルは、テキスト内のパターンの潜在的な開始位置を迅速に特定するために使用されます。 3. テキストを繰り返し処理し、各文字をパターン内の対応する文字と比較します。 4. 文字が一致する場合は、次の文字に移動して比較を続行できます。 5. 文字が一致しない場合は、ハッシュ テーブルを使用して、パターン内の次の文字候補を決定できます。
