

UniVision は、新世代の統合フレームワークを導入しています。BEV 検出と占有のデュアル タスクが最も高度なレベルに達しています。

前書き&個人的な理解
近年、自動運転技術における視覚中心の3D認識が急速に発展しています。 3D 認識モデルは構造的および概念的に類似していますが、特徴の表現、データ形式、目的には依然としてギャップがあり、統一された効率的な 3D 認識フレームワークを設計することが課題となっています。したがって、研究者は、より正確で信頼性の高い自動運転システムを実現するために、これらのギャップに対処するために懸命に取り組む必要があります。私たちは、コラボレーションとイノベーションを通じて、自動運転の安全性とパフォーマンスをさらに向上させたいと考えています。
特に、BEV での検出タスクと占有タスクでは、共同トレーニングを実施して良好な結果を達成することは非常に困難です。これは、不安定性や制御が難しい影響により、多くのアプリケーションに大きな問題をもたらします。ただし、UniVision は、視覚中心の 3D 認識の 2 つの主要なタスク、つまり占有予測とオブジェクト検出を統合するシンプルで効率的なフレームワークです。フレームワークの中核は、相補的な 2D-3D フィーチャ変換のための明示的-暗黙的ビュー変換モジュールです。さらに、UniVision は、効率的かつ適応的なボクセルと BEV の特徴抽出、強化、および相互作用のためのローカル グローバル特徴抽出および融合モジュールも提案しています。これらの方法を採用することにより、UniVision は BEV での検出タスクと占有タスクで満足のいく結果を達成することができます。
UniVision は、マルチタスク フレームワーク トレーニングの効率と安定性を向上させるために、共同占有検出データ強化戦略と段階的な減量調整戦略を提案しています。シーンフリー LIDAR セグメンテーション、シーンフリー検出、OpenOccupancy、Occ3D を含む 4 つの公開ベンチマークで広範な実験が行われています。実験結果は、UniVision が各ベンチマークでそれぞれ 1.5 mIoU、1.8 NDS、1.5 mIoU、1.8 mIoU のゲインを達成し、SOTA レベルに達したことを示しています。したがって、UniVision フレームワークは、統合されたビジョン中心の 3D 認識タスクの高性能ベースラインとして機能します。
3D 認識分野の現状
3D 認識は自動運転システムの主なタスクであり、一連のセンサー (LIDAR など) を利用することを目的としています。 、レーダー、カメラ)取得されたデータは、走行シーンを総合的に把握し、その後の計画や意思決定に活用することができます。これまで、3D 認識の分野は、点群データから得られた正確な 3D 情報により、LIDAR ベースのモデルが主流でした。ただし、LIDAR ベースのシステムは高価で、悪天候の影響を受けやすく、導入が不便です。対照的に、ビジョンベースのシステムには、低コスト、簡単な導入、優れた拡張性など、多くの利点があります。したがって、視覚を中心とした三次元認識は研究者の間で広く注目を集めています。
最近、ビジョンベースの 3D 検出は、改善された特徴表現変換、時間融合、および監視信号設計を通じて大幅な進歩を遂げており、LiDAR ベースのモデルとの差は縮小し続けています。さらに、視覚ベースの占有タスクも近年急速に発展しています。 3D ボックスを使用してオブジェクトを表現するのとは異なり、占有率は運転シーンの幾何学的および意味論的な特性をより包括的に記述することができ、オブジェクトの形状やカテゴリによって制限されません。
検出方法と占有方法には構造的および概念的な類似点がありますが、これら 2 つのタスクを同時に処理し、それらの相互関係を調査することに関する研究は不十分です。占有モデルと検出モデルは通常、異なる特徴表現を抽出します。占有予測タスクには徹底的な意味論的および幾何学的な判断が必要なため、きめの細かい 3D 情報を保存するためにボクセル表現が広く使用されています。ただし、検出タスクでは、ほとんどのオブジェクトが同じ水平面上にあり、重なりが小さいため、BEV 表現の方が適しています。
BEV 表現と比較すると、ボクセル表現は精細度が高くなりますが、効率は低くなります。さらに、多くの高度なオペレータは主に 2D フィーチャ向けに設計および最適化されているため、3D ボクセル表現との統合はそれほど単純ではありません。 BEV 表現は時間効率とメモリ効率の点でより有利ですが、高さの次元で構造情報が失われるため、密な空間予測には次善です。特徴の表現に加えて、認識タスクが異なれば、データ形式と目標も異なります。したがって、マルチタスク 3D 認識フレームワークのトレーニングの均一性と効率を確保することは、大きな課題です。
UniVision ネットワーク構造
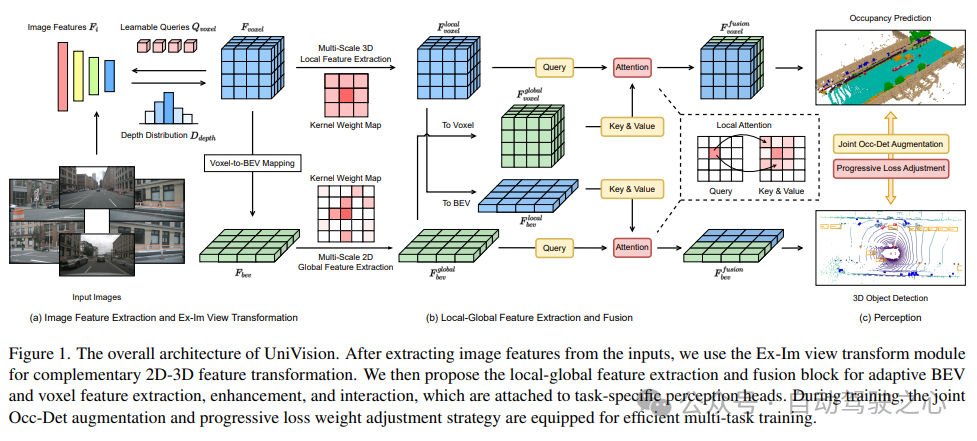
UniVision フレームワークの全体的なアーキテクチャを図 1 に示します。このフレームワークは、周囲の N 台のカメラからの多視点画像を入力として受け取り、画像特徴抽出ネットワークを通じて画像特徴を抽出します。次に、Ex-Im ビュー変換モジュールを使用して、2D 画像特徴を 3D ボクセル特徴に変換します。このモジュールは、深度ガイドによる明示的な特徴ブースティングとクエリによる暗黙的な特徴サンプリングを組み合わせたものです。 ビュー変換後、ボクセル特徴はローカル グローバル特徴抽出および融合ブロックに供給され、ローカル コンテキスト認識ボクセル特徴とグローバル コンテキスト認識 BEV 特徴がそれぞれ抽出されます。次に、相互表現特徴相互作用モジュールを通じて、さまざまな下流の知覚タスクのボクセル特徴と BEV 特徴に関する情報が交換されます。 トレーニング プロセス中、UniVision フレームワークは、効果的なトレーニングのために、Occ-Det データ強化と段階的な減量調整戦略を組み合わせて使用します。これらの戦略により、トレーニング効果とフレームワークの汎化能力を向上させることができます。 つまり、UniVision フレームワークは、マルチビュー画像と 3D ボクセル特徴の処理、および特徴相互作用モジュールのアプリケーションを通じて、周囲の環境をセンシングするタスクを実現します。同時に、データ強化と減量調整戦略の適用を通じて、フレームワークのトレーニング効果が効果的に向上します。
1) Ex-Im View Transform
深度指向の明示的な機能強化。ここでは LSS アプローチに従います:
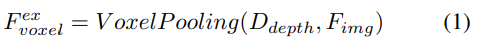
#2) クエリガイドによる暗黙的な特徴サンプリング。ただし、3D 情報の表現にはいくつかの欠点があります。の精度は、推定された深度分布の精度と高い相関があります。さらに、LSS によって生成されるポイントは均一に分配されません。ポイントはカメラの近くでは密集しており、遠くでは疎になります。したがって、クエリガイドによる特徴サンプリングをさらに使用して、上記の欠点を補います。
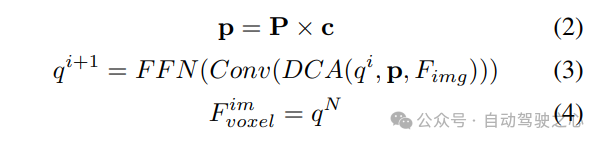
LSS から生成されたポイントと比較して、ボクセル クエリは 3D 空間に均一に分散されており、すべてのトレーニング サンプルの統計的特性から学習されます。これは深度に一致します。 LSS で使用される事前情報は無関係です。したがって、相互に補完し、ビュー変換モジュールの出力特徴としてそれらを接続します。
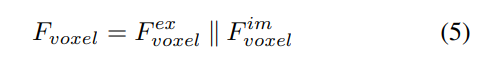
#2) ローカルおよびグローバル特徴の抽出と融合
与えられた入力ボクセル特徴を、最初に Z 軸上に特徴をオーバーレイし、畳み込み層を使用してチャネルを削減し、BEV 特徴を取得します。
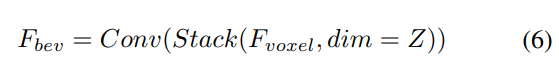
次に、モデル特徴抽出と拡張のために 2 つの並列ブランチに分割されます。ローカル特徴抽出、グローバル特徴抽出、そして最後の相互表現特徴相互作用!図 1(b) に示すように。
#3) 損失関数と検出ヘッド
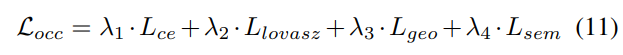
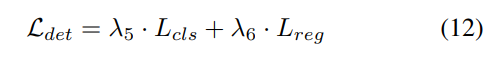
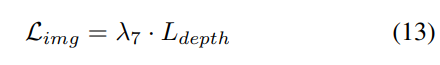
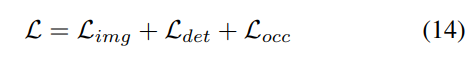
4) Occ-Det 空間データ強化との組み合わせ
3D 検出タスクでは、一般的な画像レベルのデータ強化に加えて、空間レベルのデータ強化も改善に効果的です。モデルのパフォーマンス、効果的。ただし、占有タスクに空間レベルの強化を適用するのは簡単ではありません。データ拡張 (ランダムなスケーリングや回転など) を個別の占有ラベルに適用する場合、結果として得られるボクセルのセマンティクスを判断するのは困難です。したがって、既存の方法では、占有タスクにおけるランダムな反転などの単純な空間拡張のみが適用されます。
この問題を解決するために、UniVision は、フレームワーク内の 3D 検出タスクと占有タスクの同時強化を可能にする共同 Occ-Det 空間データ強化を提案しています。 3D ボックスのラベルは連続値であり、強化された 3D ボックスはトレーニング用に直接計算できるため、検出には BEVDet の強化方法に従います。占有ラベルは離散的で操作が困難ですが、ボクセル フィーチャは連続的なものとして扱うことができ、サンプリングや補間などの操作を通じて処理できます。したがって、データ拡張のために占有ラベルを直接操作するのではなく、ボクセル フィーチャを変換することをお勧めします。
具体的には、まず空間データ拡張がサンプリングされ、対応する 3D 変換行列が計算されます。占有ラベルとそのボクセル インデックス について、その 3 次元座標を計算します。次に、それを適用して正規化して、拡張ボクセル機能のボクセル インデックスを取得します :
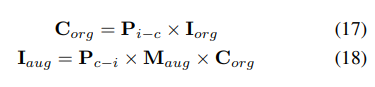
#実験結果の比較
検証には、NuScenes LiDAR セグメンテーション、NuScenes 3D オブジェクト検出、OpenOccupancy、Occ3D の複数のデータ セットを使用しました。 NuScenes LiDAR セグメンテーション: 最近の OccFormer および TPVFormer によると、カメラ画像は LIDAR セグメンテーション タスクの入力として使用され、LIDAR データは出力フィーチャをクエリするための 3D 位置を提供するためにのみ使用されます。評価指標として mIoU を使用します。 NuScenes 3D オブジェクト検出: 検出タスクには、nuScenes の公式メトリックである nuScene 検出スコア (NDS) を使用します。これは、平均 mAP と、平均変換誤差 (ATE) を含むいくつかのメトリックの加重合計です。平均スケール誤差 (ASE)、平均配向誤差 (AOE)、平均速度誤差 (AVE)、および平均属性誤差 (AAE)。 OpenOccupancy: OpenOccupancy ベンチマークは nuScenes データセットに基づいており、512×512×40 の解像度でセマンティック占有ラベルを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。 Occ3D: Occ3D ベンチマークは nuScenes データセットに基づいており、200×200×16 解像度でセマンティック占有ラベルを提供します。 Occ3D はさらに、トレーニングと評価用の可視マスクを提供します。ラベル付けされたクラスは、評価指標として mIoU を使用する LIDAR セグメンテーション タスクのクラスと同じです。1) Nuscenes LiDAR セグメンテーション
表 1 は、nuScenes LiDAR セグメンテーション ベンチマークの結果を示しています。 UniVision は、最先端のビジョンベース手法である OccFormer を 1.5% mIoU 上回り、リーダーボードにおけるビジョンベースのモデルの新記録を樹立しました。特に、UniVision は、PolarNe や DB-UNet などの一部の LIDAR ベースのモデルよりも優れたパフォーマンスを発揮します。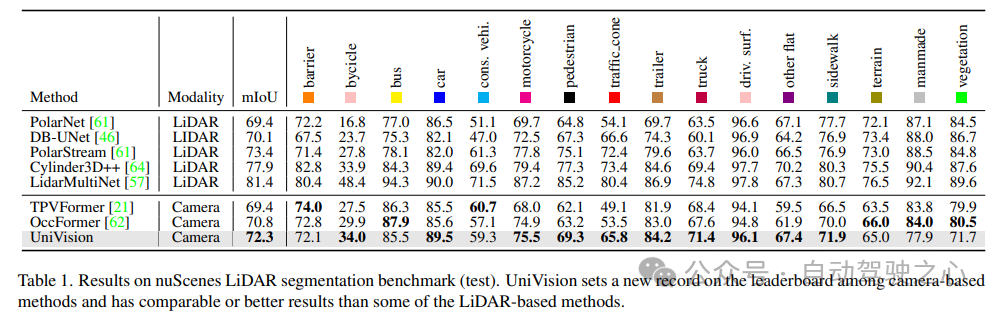
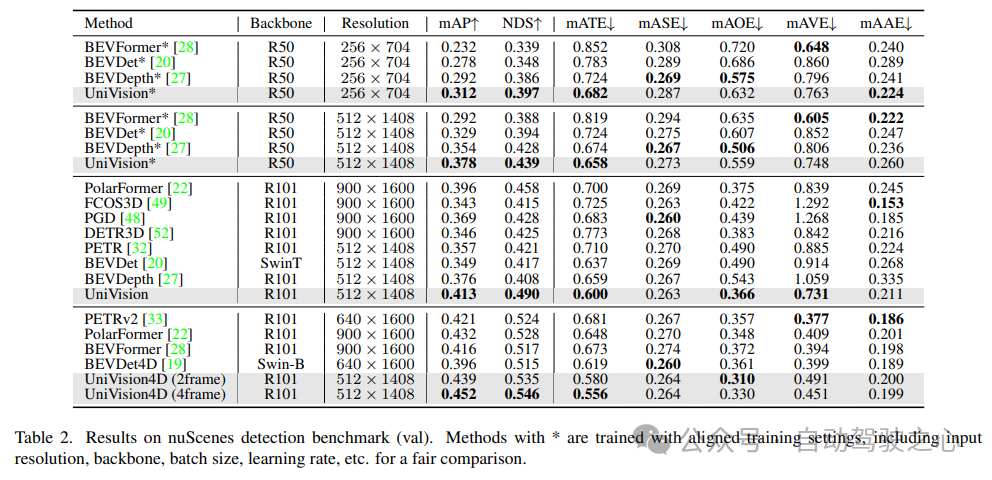
表 2 に示すように、公平な比較に同じトレーニング設定を使用する場合、 UniVision は他の方法よりも優れたパフォーマンスを発揮することが示されました。 512×1408 の画像解像度での BEVDepth と比較して、UniVision は mAP と NDS でそれぞれ 2.4% と 1.1% の向上を達成します。モデルをスケールアップし、UniVision を時間入力と組み合わせると、SOTA ベースの時間検出器を大幅に上回ります。 UniVision は、より小さい入力解像度でこれを実現し、CBGS を使用しません。
OpenOccupancy ベンチマーク テストの結果を表 3 に示します。 UniVision は、MonoScene、TPVFormer、C-CONet などの最近のビジョンベースの占有方法よりも、mIoU の点でそれぞれ 7.3%、6.5%、1.5% 大幅に優れています。さらに、UniVision は、LMSCNet や JS3C-Net などの LIDAR ベースのメソッドよりも優れたパフォーマンスを発揮します。
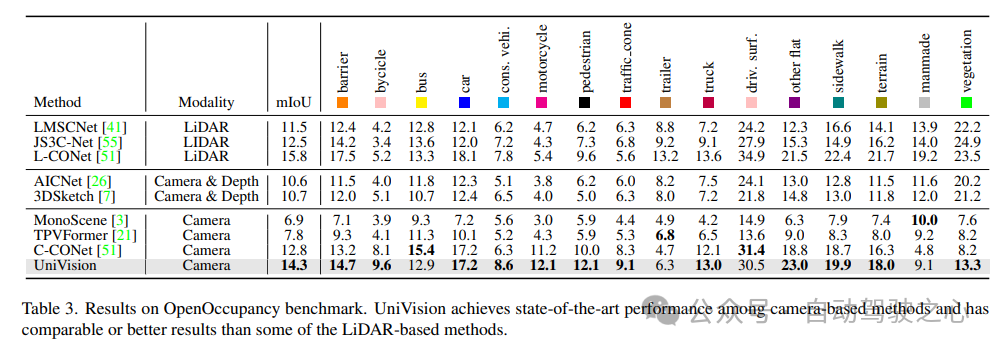
表 4 に、Occ3D ベンチマーク テストの結果を示します。 UniVision は、さまざまな入力画像解像度での mIoU の点で、最近のビジョンベースの手法よりも、それぞれ 2.7% および 1.8% 以上大幅に優れています。 BEVFormer と BEVDet-stereo は、事前にトレーニングされた重みをロードし、推論で時間入力を使用しますが、UniVision はそれらを使用しませんが、それでもより良いパフォーマンスを達成することに注目する価値があります。
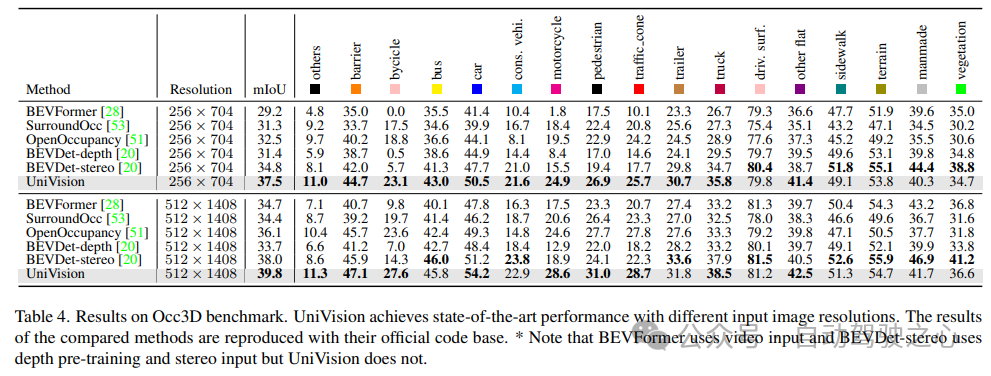
#5) 検出タスクにおけるコンポーネントの有効性
検出タスクのアブレーション研究を表 5 に示します。 BEV ベースのグローバル特徴抽出ブランチがベースライン モデルに挿入されると、パフォーマンスは mAP で 1.7%、NDS で 3.0% 向上します。ボクセルベースの占有タスクが補助タスクとして検出器に追加されると、モデルの mAP ゲインは 1.6% 増加します。相互表現相互作用がボクセル特徴から明示的に導入されると、モデルは最高のパフォーマンスを達成し、ベースラインと比較して mAP と NDS をそれぞれ 3.5% と 4.2% 改善します;
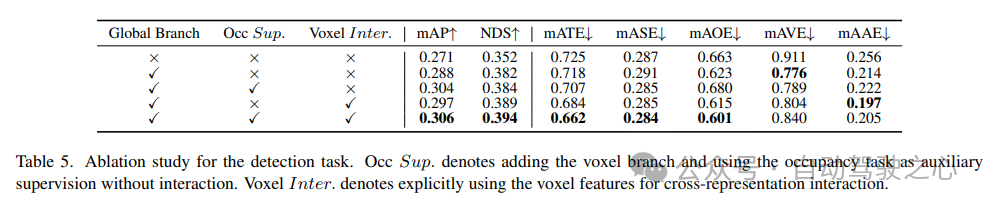
6) 占有タスクにおけるコンポーネントの有効性
占有タスクのアブレーション研究を表 6 に示します。ボクセルベースのローカル特徴抽出ネットワークにより、ベースライン モデルに対して 1.96% の mIoU ゲインの向上がもたらされます。検出タスクが補助監視信号として導入されると、モデルのパフォーマンスは 0.4% mIoU 向上します。

7) その他
表 5 と表 6 は、UniVision フレームワークにおいて、検出タスクと占有タスクが相互に補完していることを示しています。の。検出タスクの場合、占有監視により mAP および mATE メトリクスが改善され、ボクセルのセマンティック学習により、オブジェクトの幾何学形状、つまり中心性とスケールに対する検出器の認識が効果的に向上することが示されています。占有タスクの場合、検出監視により前景カテゴリ (つまり、検出カテゴリ) のパフォーマンスが大幅に向上し、全体的な向上が得られます。
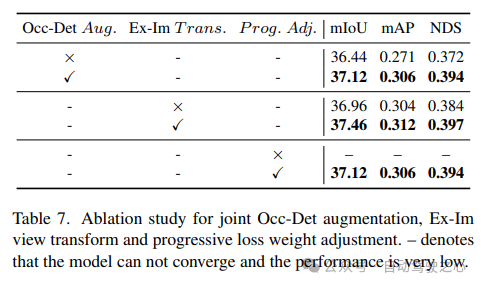
Occ-Det 空間強調、Ex-Im ビュー変換モジュール、および漸進的損失重量調整戦略を組み合わせた効果を表 7 に示します。提案された空間拡張と提案されたビュー変換モジュールにより、mIoU、mAP、NDS メトリックに関する検出タスクと占有タスクが大幅に改善されました。減量調整戦略は、マルチタスク フレームワークを効果的にトレーニングできます。これがないと、統合フレームワークのトレーニングは収束できず、パフォーマンスが非常に低くなります。
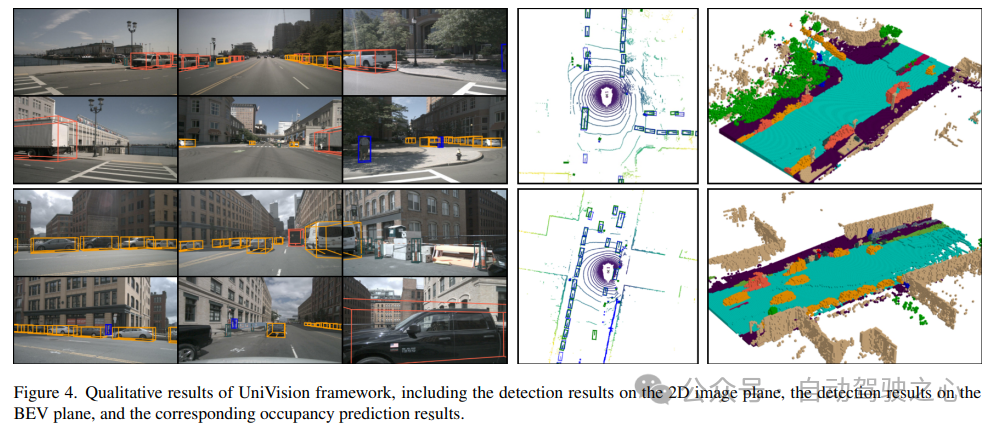
元のリンク: https://mp.weixin.qq.com/s/8jpS_I-wn1-svR3UlCF7KQ
以上がUniVision は、新世代の統合フレームワークを導入しています。BEV 検出と占有のデュアル タスクが最も高度なレベルに達しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
91
15
1382
52
83
11
22
91

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
