

LLM 大規模言語モデルと検索拡張の生成


LLM 大規模言語モデルは、通常、Transformer アーキテクチャを使用してトレーニングされ、自然言語を理解して生成する能力を向上させるために大量のテキスト データを使用します。これらのモデルは、チャットボット、テキスト要約、機械翻訳などの分野で広く使用されています。有名な LLM 大規模言語モデルには、OpenAI の GPT シリーズや Google の BERT などがあります。
自然言語処理の分野において、検索強化生成とは、検索と生成を組み合わせた技術です。大規模なテキストコーパスから関連情報を取得し、生成モデルを使用してこの情報を再結合および配置することで、要件を満たすテキストを生成します。この技術は、テキストの要約、機械翻訳、対話の生成、その他のタスクを含む幅広い用途に使用できます。検索と生成を利用することで、検索強化生成はテキスト生成の品質と精度を向上させることができ、それによって自然言語処理の分野で重要な役割を果たします。
LLM 大規模言語モデルでは、検索拡張生成はモデルのパフォーマンスを向上させる重要な技術的手段と考えられています。検索と生成を統合することで、LLM は大量のテキストから関連情報をより効果的に取得し、高品質の自然言語テキストを生成できます。この技術的手段により、モデルの生成効果と精度が大幅に向上し、さまざまな自然言語処理アプリケーションのニーズをより適切に満たすことができます。 LLM の大規模言語モデルは、取得と生成を組み合わせることで、生成されたコンテンツの一貫性や関連性など、従来の生成モデルのいくつかの制限を克服できます。したがって、検索拡張生成はモデルのパフォーマンスを向上させる大きな可能性を秘めており、将来の自然言語処理研究において重要な役割を果たすことが期待されています。
検索拡張生成テクノロジーを使用して、特定のユースケースに合わせて LLM 大規模言語モデルをカスタマイズする手順
検索拡張生成を使用して、特定のユースケースに合わせて LLM 大規模言語モデルをカスタマイズするには、次の手順を実行します。次の手順:
1. データの準備
まず、大量のテキスト データを準備することが、LLM 大規模言語モデルを確立するための重要な手順です。これらのデータには、トレーニング データと検索データが含まれます。トレーニング データはモデルをトレーニングするために使用され、取得データはモデルから関連情報を取得するために使用されます。 特定の使用例のニーズを満たすために、必要に応じて関連するテキスト データを選択できます。このデータは、関連する記事、ニュース、フォーラムの投稿など、インターネットから取得できます。高品質のモデルをトレーニングするには、適切なデータ ソースを選択することが重要です。 トレーニング データの品質を確保するには、データを前処理してクリーンアップする必要があります。これには、ノイズの除去、テキスト形式の正規化、欠損値の処理などが含まれます。クリーンアップされたデータは、モデルをトレーニングし、モデルの精度とパフォーマンスを向上させるためにより適切に使用できます。 さらに
#2. LLM 大規模言語モデルをトレーニングするOpenAI の GPT シリーズや Google の BERT などの既存の LLM 大規模言語モデル フレームワークを使用して、準備されたトレーニング データをトレーニングします。トレーニング プロセス中に、特定のユースケースに合わせてモデルのパフォーマンスを向上させるために微調整を行うことができます。 3. 検索システムの構築検索強化生成を実現するには、大規模なテキストコーパスから関連情報を検索する検索システムを構築する必要があります。キーワードベースまたはコンテンツベースの検索など、既存の検索エンジン技術を使用できます。さらに、Transformer ベースの検索モデルなどのより高度な深層学習テクノロジーを使用して、検索結果を向上させることもできます。これらのテクノロジーは、セマンティック情報とコンテキスト情報を分析することでユーザーのクエリの意図をより深く理解し、関連する結果を正確に返すことができます。継続的な最適化と反復を通じて、検索システムは大規模なテキスト コーパスからユーザーのニーズに関連する情報を効率的に取得できます。 4. 検索システムと LLM ラージ言語モデルを結合する 検索システムと LLM ラージ言語モデルを結合して、強化された検索生成を実現します。まず、検索システムを使用して、大規模なテキスト コーパスから関連情報を検索します。次に、LLM 大型言語モデルを使用してこの情報を再配置および結合し、要件を満たすテキストを生成します。このようにして、生成されるテキストの精度と多様性を向上させ、ユーザーのニーズをより適切に満たすことができます。 5. 最適化と評価特定のユースケースのニーズを満たすために、カスタマイズされた LLM の大規模言語モデルを最適化して評価できます。モデルのパフォーマンスを評価するには、精度、再現率、F1 スコアなどの評価指標を使用できます。さらに、実際のアプリケーション シナリオのデータを使用して、モデルの実用性をテストすることもできます。 例 1: 映画レビュー用の LLM 大きな言語モデル映画レビュー用の LLM 大きな言語モデルをカスタマイズし、ユーザーに映画名を入力させると、モデルは生成できるとします。映画のレビュー。 まず、トレーニング データを準備し、データを取得する必要があります。関連する映画レビュー記事、ニュース、フォーラムへの投稿などを学習データや検索データとしてインターネットから取得できます。 次に、OpenAI の GPT シリーズ フレームワークを使用して、LLM 大規模言語モデルをトレーニングできます。トレーニング プロセス中に、語彙やコーパスなどの調整など、映画レビューのタスクに合わせてモデルを微調整できます。次に、大規模なテキスト コーパスから関連情報を取得するためのキーワード ベースの検索システムを構築できます。この例では、映画のタイトルをキーワードとして、学習データと検索データから関連するレビューを取得できます。
最後に、検索システムを LLM ラージ言語モデルと組み合わせて、強化された検索生成を実現します。具体的には、まず検索システムを使用して大規模なテキスト コーパスから映画のタイトルに関連するコメントを取得し、次に LLM 大規模言語モデルを使用してこれらのコメントを並べ替えて結合し、要件を満たすテキストを生成できます。
以下は、Python と GPT ライブラリを使用して上記のプロセスを実装するサンプル コードです:
1 |
|
例 2: ユーザーがプログラミングに関する質問に答えられるようにします
まず、 Elasticsearch を使用するなど、単純な検索システムが必要です。次に、Python を使用してコードを記述し、LLM モデルを Elasticsearch に接続し、微調整します。以下は簡単なコード例です。
1 |
|
この Python コード例は、GPT-2 モデルを Elasticsearch と組み合わせて使用し、検索強化生成を実現する方法を示しています。この例では、プログラミング関連の情報を格納する「knowledge_base」というインデックスがあると仮定します。関数retrieve_informationでは、単純なElasticsearchクエリを実行し、generate_text_with_retrieval関数で、取得した情報を統合し、GPT-2モデルを使用して回答を生成します。
ユーザーが Python 関数に関する質問をクエリすると、コードは Elasticsearch から関連情報を取得し、それをユーザー クエリに統合し、GPT-2 モデルを使用して回答を生成します。
以上がLLM 大規模言語モデルと検索拡張の生成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7543
7543
 15
1381
52
83
11
21
87
15
1381
52
83
11
21
87

 RNN、LSTM、GRU の概念、違い、長所と短所を調べる
Jan 22, 2024 pm 07:51 PM
RNN、LSTM、GRU の概念、違い、長所と短所を調べる
Jan 22, 2024 pm 07:51 PM
時系列データでは、観測間に依存関係があるため、相互に独立していません。ただし、従来のニューラル ネットワークは各観測値を独立したものとして扱うため、時系列データをモデル化するモデルの能力が制限されます。この問題を解決するために、リカレント ニューラル ネットワーク (RNN) が導入されました。これは、ネットワーク内のデータ ポイント間の依存関係を確立することにより、時系列データの動的特性をキャプチャするためのメモリの概念を導入しました。反復接続を通じて、RNN は以前の情報を現在の観測値に渡して、将来の値をより適切に予測できます。このため、RNN は時系列データを含むタスクにとって強力なツールになります。しかし、RNN はどのようにしてこの種の記憶を実現するのでしょうか? RNN は、ニューラル ネットワーク内のフィードバック ループを通じて記憶を実現します。これが RNN と従来のニューラル ネットワークの違いです。
 ニューラル ネットワークの浮動小数点オペランド (FLOPS) の計算
Jan 22, 2024 pm 07:21 PM
ニューラル ネットワークの浮動小数点オペランド (FLOPS) の計算
Jan 22, 2024 pm 07:21 PM
FLOPS はコンピュータの性能評価の規格の 1 つで、1 秒あたりの浮動小数点演算の回数を測定するために使用されます。ニューラル ネットワークでは、モデルの計算の複雑さとコンピューティング リソースの使用率を評価するために FLOPS がよく使用されます。これは、コンピューターの計算能力と効率を測定するために使用される重要な指標です。ニューラル ネットワークは、データ分類、回帰、クラスタリングなどのタスクを実行するために使用される、複数のニューロン層で構成される複雑なモデルです。ニューラル ネットワークのトレーニングと推論には、多数の行列の乗算、畳み込み、その他の計算操作が必要となるため、計算の複雑さは非常に高くなります。 FLOPS (FloatingPointOperationsperSecond) を使用すると、ニューラル ネットワークの計算の複雑さを測定し、モデルの計算リソースの使用効率を評価できます。フロップ
 テキスト分類に双方向 LSTM モデルを使用するケーススタディ
Jan 24, 2024 am 10:36 AM
テキスト分類に双方向 LSTM モデルを使用するケーススタディ
Jan 24, 2024 am 10:36 AM
双方向 LSTM モデルは、テキスト分類に使用されるニューラル ネットワークです。以下は、テキスト分類タスクに双方向 LSTM を使用する方法を示す簡単な例です。まず、必要なライブラリとモジュールをインポートする必要があります: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 ファジーニューラルネットワークの定義と構造解析
Jan 22, 2024 pm 09:09 PM
ファジーニューラルネットワークの定義と構造解析
Jan 22, 2024 pm 09:09 PM
ファジー ニューラル ネットワークは、ファジー ロジックとニューラル ネットワークを組み合わせたハイブリッド モデルで、従来のニューラル ネットワークでは処理が困難なファジーまたは不確実な問題を解決します。その設計は人間の認知における曖昧さと不確実性にインスピレーションを得ているため、制御システム、パターン認識、データマイニングなどの分野で広く使用されています。ファジー ニューラル ネットワークの基本アーキテクチャは、ファジー サブシステムとニューラル サブシステムで構成されます。ファジー サブシステムは、ファジー ロジックを使用して入力データを処理し、それをファジー セットに変換して、入力データの曖昧さと不確実性を表現します。ニューラル サブシステムは、ニューラル ネットワークを使用して、分類、回帰、クラスタリングなどのタスクのファジー セットを処理します。ファジー サブシステムとニューラル サブシステム間の相互作用により、ファジー ニューラル ネットワークはより強力な処理能力を持ち、
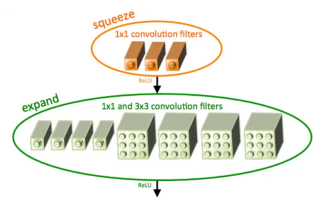 SqueezeNet の概要とその特徴
Jan 22, 2024 pm 07:15 PM
SqueezeNet の概要とその特徴
Jan 22, 2024 pm 07:15 PM
SqueezeNet は、高精度と低複雑性のバランスが取れた小型で正確なアルゴリズムであり、リソースが限られているモバイル システムや組み込みシステムに最適です。 2016 年、DeepScale、カリフォルニア大学バークレー校、スタンフォード大学の研究者は、コンパクトで効率的な畳み込みニューラル ネットワーク (CNN) である SqueezeNet を提案しました。近年、研究者は SqueezeNetv1.1 や SqueezeNetv2.0 など、SqueezeNet にいくつかの改良を加えました。両方のバージョンの改良により、精度が向上するだけでなく、計算コストも削減されます。 ImageNet データセット上の SqueezeNetv1.1 の精度
 畳み込みニューラル ネットワークを使用した画像のノイズ除去
Jan 23, 2024 pm 11:48 PM
畳み込みニューラル ネットワークを使用した画像のノイズ除去
Jan 23, 2024 pm 11:48 PM
畳み込みニューラル ネットワークは、画像のノイズ除去タスクで優れたパフォーマンスを発揮します。学習したフィルターを利用してノイズを除去し、元の画像を復元します。この記事では、畳み込みニューラル ネットワークに基づく画像ノイズ除去方法を詳しく紹介します。 1. 畳み込みニューラル ネットワークの概要 畳み込みニューラル ネットワークは、複数の畳み込み層、プーリング層、全結合層の組み合わせを使用して画像の特徴を学習および分類する深層学習アルゴリズムです。畳み込み層では、畳み込み演算を通じて画像の局所的な特徴が抽出され、それによって画像内の空間相関が捕捉されます。プーリング層は、特徴の次元を削減することで計算量を削減し、主要な特徴を保持します。完全に接続された層は、学習した特徴とラベルをマッピングして画像分類やその他のタスクを実装する役割を果たします。このネットワーク構造の設計により、畳み込みニューラル ネットワークは画像処理と認識に役立ちます。
 Rust を使用して単純なニューラル ネットワークを作成する手順
Jan 23, 2024 am 10:45 AM
Rust を使用して単純なニューラル ネットワークを作成する手順
Jan 23, 2024 am 10:45 AM
Rust は、安全性、パフォーマンス、同時実行性に重点を置いたシステムレベルのプログラミング言語です。オペレーティング システム、ネットワーク アプリケーション、組み込みシステムなどのシナリオに適した安全で信頼性の高いプログラミング言語を提供することを目的としています。 Rust のセキュリティは主に、所有権システムと借用チェッカーという 2 つの側面から実現されます。所有権システムにより、コンパイラはコンパイル時にコードのメモリ エラーをチェックできるため、一般的なメモリの安全性の問題が回避されます。 Rust は、コンパイル時に変数の所有権の転送のチェックを強制することで、メモリ リソースが適切に管理および解放されることを保証します。ボロー チェッカーは、変数のライフ サイクルを分析して、同じ変数が複数のスレッドによって同時にアクセスされないようにすることで、一般的な同時実行セキュリティの問題を回避します。これら 2 つのメカニズムを組み合わせることで、Rust は以下を提供できます。
 ツイン ニューラル ネットワーク: 原理と応用分析
Jan 24, 2024 pm 04:18 PM
ツイン ニューラル ネットワーク: 原理と応用分析
Jan 24, 2024 pm 04:18 PM
シャム ニューラル ネットワークは、ユニークな人工ニューラル ネットワーク構造です。これは、同じパラメーターと重みを共有する 2 つの同一のニューラル ネットワークで構成されます。同時に、2 つのネットワークは同じ入力データも共有します。 2 つのニューラル ネットワークは構造的に同一であるため、このデザインは双子からインスピレーションを得ています。シャム ニューラル ネットワークの原理は、2 つの入力データ間の類似性や距離を比較することによって、画像マッチング、テキスト マッチング、顔認識などの特定のタスクを完了することです。トレーニング中、ネットワークは、類似したデータを隣接する領域にマッピングし、異なるデータを離れた領域にマッピングしようとします。このようにして、ネットワークはさまざまなデータを分類または照合する方法を学習して、対応するデータを実現できます。
