

Wu-Manber アルゴリズムと Python 実装手順の概要


Wu-Manber アルゴリズムは、文字列を効率的に検索するために使用される文字列一致アルゴリズムです。これは、Boyer-Moore アルゴリズムと Knuth-Morris-Pratt アルゴリズムの利点を組み合わせたハイブリッド アルゴリズムで、高速かつ正確なパターン マッチングを提供します。
Wu-Manber アルゴリズムの手順
#1. パターンのすべての可能な部分文字列をその部分文字列にマップするハッシュ テーブルを作成します。文字列が出現する場所。
2. このハッシュ テーブルは、テキスト内のパターンの潜在的な開始位置を迅速に特定するために使用されます。
3. テキストをループし、各文字をパターン内の対応する文字と比較します。
4. 文字が一致する場合は、次の文字に移動して比較を続行できます。
5. 文字が一致しない場合は、ハッシュ テーブルを使用して、パターンの次の開始位置候補の前にスキップできる最大文字数を決定できます。
6. これにより、アルゴリズムは潜在的な一致を見逃すことなく、テキストの大部分をすばやくスキップできます。
Python は Wu-Manber アルゴリズムを実装します
# Define the hash_pattern() function to generate
# a hash for each subpattern
def hashPattern(pattern, i, j):
h = 0
for k in range(i, j):
h = h * 256 + ord(pattern[k])
return h
# Define the Wu Manber algorithm
def wuManber(text, pattern):
# Define the length of the pattern and
# text
m = len(pattern)
n = len(text)
# Define the number of subpatterns to use
s = 2
# Define the length of each subpattern
t = m // s
# Initialize the hash values for each
# subpattern
h = [0] * s
for i in range(s):
h[i] = hashPattern(pattern, i * t, (i + 1) * t)
# Initialize the shift value for each
# subpattern
shift = [0] * s
for i in range(s):
shift[i] = t * (s - i - 1)
# Initialize the match value
match = False
# Iterate through the text
for i in range(n - m + 1):
# Check if the subpatterns match
for j in range(s):
if hashPattern(text, i + j * t, i + (j + 1) * t) != h[j]:
break
else:
# If the subpatterns match, check if
# the full pattern matches
if text[i:i + m] == pattern:
print("Match found at index", i)
match = True
# Shift the pattern by the appropriate
# amount
for j in range(s):
if i + shift[j] < n - m + 1:
break
else:
i += shift[j]
# If no match was found, print a message
if not match:
print("No match found")
# Driver Code
text = "the cat sat on the mat"
pattern = "the"
# Function call
wuManber(text, pattern)KMP と Wu-Manber アルゴリズムの違い
KMP アルゴリズムと Wu Manber アルゴリズムはどちらも文字列照合アルゴリズムです。つまり、より大きな文字列内の部分文字列を見つけるために使用されます。どちらのアルゴリズムも同じ時間計算量を持っています。つまり、アルゴリズムの実行にかかる時間という点では、同じパフォーマンス特性を持っています。
ただし、これらの間にはいくつかの違いがあります:
1. KMP アルゴリズムは、前処理ステップを使用して部分一致テーブルを生成します。文字列のマッチング処理を高速化するために使用されます。これにより、検索されるパターンが比較的長い場合、KMP アルゴリズムは Wu Manber アルゴリズムよりも効率的になります。
2. Wu Manber アルゴリズムは、文字列一致に別の方法を使用し、パターンを複数のサブパターンに分割し、これらのサブパターンを使用してテキスト内の一致を検索します。これにより、検索されるパターンが比較的短い場合、Wu Manber アルゴリズムが KMP アルゴリズムよりも効率的になります。
以上がWu-Manber アルゴリズムと Python 実装手順の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

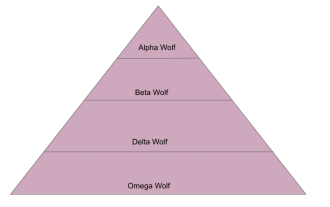 Gray Wolf 最適化アルゴリズム (GWO) とその長所と短所の詳細な分析
Jan 19, 2024 pm 07:48 PM
Gray Wolf 最適化アルゴリズム (GWO) とその長所と短所の詳細な分析
Jan 19, 2024 pm 07:48 PM
ハイイロオオカミ最適化アルゴリズム (GWO) は、自然界のハイイロオオカミのリーダーシップ階層と狩猟メカニズムをシミュレートする個体群ベースのメタヒューリスティック アルゴリズムです。ハイイロオオカミ アルゴリズムのインスピレーション 1. ハイイロオオカミは頂点捕食者であると考えられており、食物連鎖の頂点に位置します。 2. ハイイロオオカミは集団で生活すること(集団生活)を好み、各群れには平均 5 ~ 12 頭のオオカミがいます。 3. ハイイロオオカミには、以下に示すように、非常に厳格な社会的支配階層があります。 アルファオオカミ: アルファオオカミは、ハイイロオオカミのグループ全体で支配的な地位を占め、ハイイロオオカミのグループ全体を指揮する権利を持っています。アルゴリズムの適用において、Alpha Wolf は最良のソリューションの 1 つであり、最適化アルゴリズムによって生成される最適なソリューションです。ベータ オオカミ: ベータ オオカミはアルファ オオカミに定期的に報告し、アルファ オオカミが最善の決定を下せるように支援します。アルゴリズム アプリケーションでは、Beta Wolf は次のことができます。
 ネストされたサンプリング アルゴリズムの基本原理と実装プロセスを調べる
Jan 22, 2024 pm 09:51 PM
ネストされたサンプリング アルゴリズムの基本原理と実装プロセスを調べる
Jan 22, 2024 pm 09:51 PM
ネストされたサンプリング アルゴリズムは、複雑な確率分布の下で積分または合計を計算するために使用される効率的なベイズ統計推論アルゴリズムです。これは、パラメーター空間を等しい体積の複数のハイパーキューブに分解し、最小体積のハイパーキューブの 1 つを徐々に反復的に「押し出し」、そのハイパーキューブをランダムなサンプルで満たして、確率分布の整数値をより適切に推定することによって機能します。ネストされたサンプリング アルゴリズムは、継続的な反復を通じて、高精度の整数値とパラメーター空間の境界を取得でき、モデルの比較、パラメーターの推定、モデルの選択などの統計的問題に適用できます。このアルゴリズムの中心的な考え方は、複雑な積分問題を一連の単純な積分問題に変換し、パラメーター空間の体積を徐々に減らすことで実際の積分値に近づくことです。各反復ステップはパラメータ空間からランダムにサンプリングします。
 Sparrow Search Algorithm (SSA) の原理、モデル、構成を分析する
Jan 19, 2024 pm 10:27 PM
Sparrow Search Algorithm (SSA) の原理、モデル、構成を分析する
Jan 19, 2024 pm 10:27 PM
スズメ検索アルゴリズム (SSA) は、スズメの対捕食行動と採餌行動に基づいたメタヒューリスティック最適化アルゴリズムです。スズメの採餌行動は、生産者とスカベンジャーの 2 つの主なタイプに分類できます。生産者は積極的に食料を探しますが、スカベンジャーは生産者からの食料を奪い合います。スズメ検索アルゴリズム (SSA) の原理 スズメ検索アルゴリズム (SSA) では、各スズメは隣のスズメの行動に細心の注意を払います。さまざまな採餌戦略を採用することで、個体は蓄えられたエネルギーを効率的に利用して、より多くの食物を追求することができます。さらに、鳥は探索空間では捕食者に対してより脆弱であるため、より安全な場所を見つける必要があります。コロニーの中心にいる鳥は、隣の鳥の近くにいることで、自分自身の危険範囲を最小限に抑えることができます。鳥は捕食者を見つけると、警報を発します。
 id3 アルゴリズムにおける情報獲得の役割は何ですか?
Jan 23, 2024 pm 11:27 PM
id3 アルゴリズムにおける情報獲得の役割は何ですか?
Jan 23, 2024 pm 11:27 PM
ID3 アルゴリズムは、決定木学習の基本アルゴリズムの 1 つです。各特徴の情報ゲインを計算して決定木を生成することにより、最適な分割点を選択します。情報ゲインは ID3 アルゴリズムの重要な概念であり、分類タスクに対する特徴の寄与を測定するために使用されます。この記事では、ID3 アルゴリズムにおける情報ゲインの概念、計算方法、応用について詳しく紹介します。 1. 情報エントロピーの概念 情報エントロピーは情報理論の概念であり、確率変数の不確実性を測定します。離散乱数の場合、p(x_i) は乱数 X が値 x_i をとる確率を表します。手紙
 Wu-Manber アルゴリズムと Python 実装手順の概要
Jan 23, 2024 pm 07:03 PM
Wu-Manber アルゴリズムと Python 実装手順の概要
Jan 23, 2024 pm 07:03 PM
Wu-Manber アルゴリズムは、文字列を効率的に検索するために使用される文字列一致アルゴリズムです。これは、Boyer-Moore アルゴリズムと Knuth-Morris-Pratt アルゴリズムの利点を組み合わせたハイブリッド アルゴリズムで、高速かつ正確なパターン マッチングを提供します。 Wu-Manber アルゴリズムのステップ 1. パターンの考えられる各部分文字列を、その部分文字列が出現するパターン位置にマップするハッシュ テーブルを作成します。 2. このハッシュ テーブルは、テキスト内のパターンの潜在的な開始位置を迅速に特定するために使用されます。 3. テキストを繰り返し処理し、各文字をパターン内の対応する文字と比較します。 4. 文字が一致する場合は、次の文字に移動して比較を続行できます。 5. 文字が一致しない場合は、ハッシュ テーブルを使用して、パターン内の次の文字候補を決定できます。
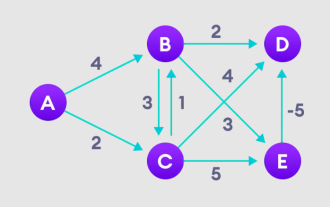 Bellman Ford アルゴリズムと Python での実装の詳細な説明
Jan 22, 2024 pm 07:39 PM
Bellman Ford アルゴリズムと Python での実装の詳細な説明
Jan 22, 2024 pm 07:39 PM
Bellman Ford アルゴリズムは、重み付きグラフ内のターゲット ノードから他のノードへの最短パスを見つけることができます。これはダイクストラ アルゴリズムに非常に似ており、ベルマン フォード アルゴリズムは負の重みを持つグラフを処理でき、実装の点では比較的単純です。ベルマン フォード アルゴリズムの原理の詳細な説明 ベルマン フォード アルゴリズムは、開始頂点から他のすべての頂点までのパスの長さを過大評価することにより、過大評価されたパスよりも短い新しいパスを繰り返し見つけます。各ノードのパス距離を記録したいので、それをサイズ n の配列に格納できます。ここで、n はノードの数も表します。例 図 1. 開始ノードを選択し、それを他のすべての頂点に無限に割り当て、パス値を記録します。 2. 各エッジを訪問し、緩和操作を実行して、最短パスを継続的に更新します。 3. 私たちが必要とするのは
 数値最適化原理とWhale Optimization Algorithm (WOA) の分析
Jan 19, 2024 pm 07:27 PM
数値最適化原理とWhale Optimization Algorithm (WOA) の分析
Jan 19, 2024 pm 07:27 PM
Whale Optimization Algorithm (WOA) は、ザトウクジラの狩猟行動をシミュレートし、数値問題の最適化に使用される、自然にヒントを得たメタヒューリスティック最適化アルゴリズムです。 Whale Optimization Algorithm (WOA) は、ランダムなソリューションのセットから開始し、ランダムに選択された検索エージェント、または各反復での検索エージェントの位置更新を通じてこれまでの最良のソリューションに基づいて最適化します。 Whale Optimization アルゴリズムのインスピレーション Whale Optimization アルゴリズムは、ザトウクジラの狩猟行動からインスピレーションを受けています。ザトウクジラは、オキアミや魚の群れなど、水面近くにある餌を好みます。そのため、ザトウクジラは狩りの際、ボトムアップスパイラルに泡を吹きながら餌を集めて泡のネットワークを形成します。 「上向きスパイラル」操縦では、ザトウクジラは約 12 メートル潜水し、獲物の周りにらせん状の泡を形成し始め、上向きに泳ぎます。
 スケール不変特徴量 (SIFT) アルゴリズム
Jan 22, 2024 pm 05:09 PM
スケール不変特徴量 (SIFT) アルゴリズム
Jan 22, 2024 pm 05:09 PM
スケール不変特徴変換 (SIFT) アルゴリズムは、画像処理およびコンピューター ビジョンの分野で使用される特徴抽出アルゴリズムです。このアルゴリズムは、コンピュータ ビジョン システムにおけるオブジェクト認識とマッチングのパフォーマンスを向上させるために 1999 年に提案されました。 SIFT アルゴリズムは堅牢かつ正確であり、画像認識、3 次元再構成、ターゲット検出、ビデオ追跡などの分野で広く使用されています。複数のスケール空間内のキーポイントを検出し、キーポイントの周囲の局所特徴記述子を抽出することにより、スケール不変性を実現します。 SIFT アルゴリズムの主なステップには、スケール空間の構築、キー ポイントの検出、キー ポイントの位置決め、方向の割り当て、および特徴記述子の生成が含まれます。これらのステップを通じて、SIFT アルゴリズムは堅牢でユニークな特徴を抽出することができ、それによって効率的な画像処理を実現します。
