

Jia Yangqing の高効率による大規模推論コスト ランキングが公開

「大規模モデルのAPIは赤字ビジネスなのか?」
大規模言語モデル技術の実用化により、多くのテクノロジー 同社は、開発者が使用できる大規模なモデル API を立ち上げました。しかし、特に OpenAI が 1 日あたり 70 万ドルを消費していることを考えると、大規模モデルに基づくビジネスが維持できるかどうか疑問に思わざるを得ません。
今週木曜日、AI スタートアップの Martian が私たちのために注意深く計算してくれました。
リーダーボードのリンク: https://leaderboard.withmartian.com/
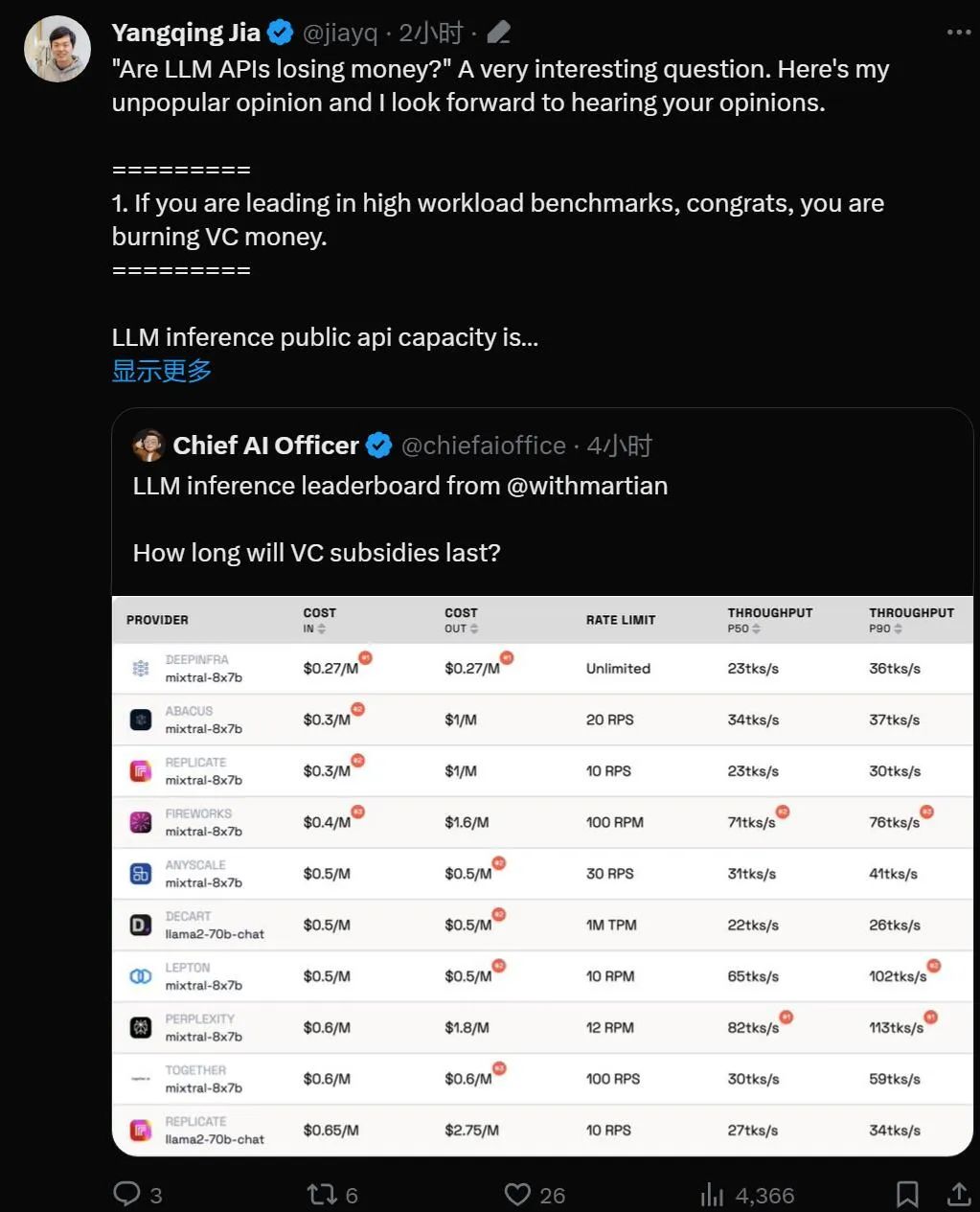
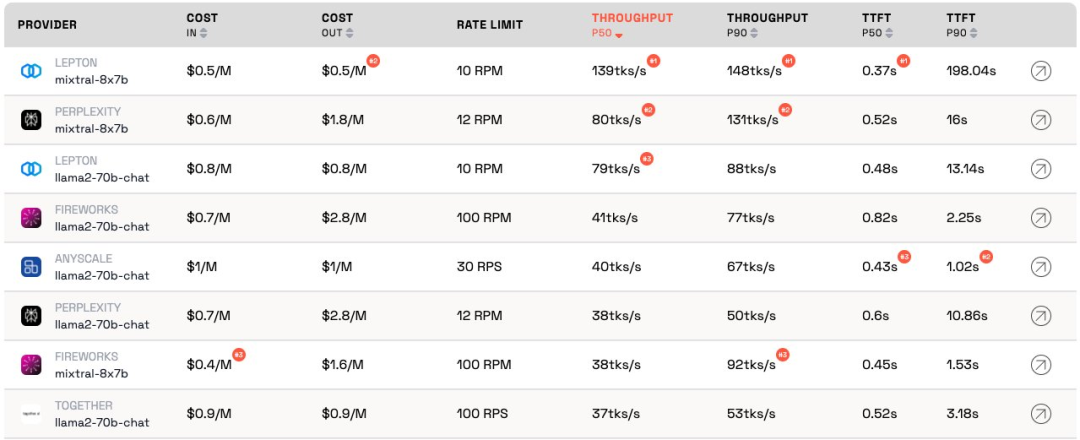
LLM 推論プロバイダーLeaderboard は、大規模モデル向けの API 推論製品のオープンソース ランキングであり、各ベンダーの Mixtral-8x7B および Llama-2-70B-Chat パブリック エンドポイントのコスト、レート制限、スループット、P50 および P90 TTFT をベンチマークします。
両社は相互に競合していますが、Martian は、各企業の大規模モデル サービスのコスト、スループット、およびレート制限に大きな違いがあることに気付きました。これらの違いは、5 倍のコストの違い、6 倍のスループットの違い、さらにはさらに大きなレート制限の違いを超えています。さまざまな API を選択することは、ビジネスの一部であっても、最高のパフォーマンスを得るために重要です。
現在のランキングによると、Anyscale が提供するサービスは、Llama-2-70B の中程度のサービス負荷の下で最高のスループットを示しています。サービス負荷が大きい場合、Togetter AI は、Llama-2-70B および Mixtral-8x7B で P50 および P90 のスループットで最高のパフォーマンスを発揮しました。
さらに、Jia Yangqing の LeptonAI は、短い入力キューと長い出力キューで小さなタスク負荷を処理する場合に最高のスループットを示しました。 130 tks/s の P50 スループットは、現在市場にあるすべてのメーカーが提供しているモデルの中で最速です。
著名な AI 学者であり、Lepton AI の創設者でもある Jia Yangqing 氏は、ランキングの発表直後にコメントしました。

Jia Yangqing 氏は、まず人工知能分野における業界の現状を説明し、次にベンチマーク テストの重要性を確認し、最後に次のように指摘しました。 LeptonAI は、ユーザーが最適な AI 基本戦略を見つけるのに役立ちます。
1. 大きなモデルの API は「お金を燃やしている」
モデルが高ワークロードのベンチマーク テストにある場合それは主導的な位置にあります、おめでとうございます、それは「お金を燃やしています」。
LLM パブリック API の容量についての推論は、レストランの経営に似ています。シェフがいて、顧客のトラフィックを見積もる必要があります。シェフを雇うとお金がかかります。レイテンシーとスループットは、「顧客のためにどれだけ速く調理できるか」として理解できます。合理的なビジネスのためには、「合理的な」数のシェフが必要です。言い換えれば、数秒以内に発生する突然のトラフィックのバーストではなく、通常のトラフィックを処理できる容量が必要です。トラフィックの急増は待つことを意味し、そうでなければ「料理人」は何もすることができません。
人工知能の世界では、GPU は「シェフ」の役割を果たします。ベースライン負荷はバースト的です。ワークロードが低い場合、ベースライン負荷は通常のトラフィックに混合され、測定値は現在のワークロード下でサービスがどのように実行されるかを正確に表します。
サービス負荷が高いシナリオは、中断が発生するため興味深いものです。ベンチマークは 1 日または週に数回しか実行されないため、予想される通常のトラフィックではありません。シェフがどれほど早く調理するかを確認するために地元のレストランに 100 人が集まることを想像してみてください。結果は素晴らしいものになるでしょう。量子物理学の用語を借りると、これは「観察者効果」と呼ばれます。干渉が強いほど(つまり、バースト負荷が大きいほど)、精度は低くなります。言い換えれば、サービスに突然高負荷をかけ、サービスが非常に速く応答することが確認できれば、そのサービスにはかなりのアイドル容量があることがわかります。投資家として、この状況を見たとき、「このお金の使い方に責任はあるのか?」と問うべきです。
#2. モデルは最終的に同様のパフォーマンスを達成します 人工知能の分野は競争が非常に好きで、確かに興味深いものです。全員が同じソリューションにすぐに集中し、最後には GPU のおかげで Nvidia が常に勝利します。これは優れたオープンソース プロジェクトのおかげであり、vLLM はその好例です。これは、プロバイダーとして、自分のモデルのパフォーマンスが他のモデルよりもはるかに悪い場合でも、オープンソース ソリューションを検討し、優れたエンジニアリングを適用することで簡単に追いつくことができることを意味します。 3. 「顧客として、プロバイダーのコストは気にしません」 人工知能の場合アプリケーションの構築 開発者にとって幸運なのは、「お金を燃やす」意欲のある API プロバイダーが常に存在することです。 AI 業界はトラフィックを獲得するために資金を浪費していますが、次のステップは利益を心配することです。 ベンチマークは退屈でエラーが発生しやすい作業です。良くも悪くも、勝者はあなたを賞賛し、敗者はあなたを非難することがよくあります。前回の畳み込みニューラル ネットワーク ベンチマークも同様でした。これは簡単な作業ではありませんが、ベンチマークは AI インフラストラクチャで次の 10 倍を達成するのに役立ちます。 人工知能フレームワークとクラウド インフラストラクチャに基づいて、LeptonAI はユーザーが最適な AI 基本戦略を見つけるのに役立ちます。
以上がJia Yangqing の高効率による大規模推論コスト ランキングが公開の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7448
7448
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueとElement-UIカスケードドロップダウンボックスv-Modelバインディング共通ピットポイント:V-Modelは、文字列ではなく、カスケード選択ボックスの各レベルで選択した値を表す配列をバインドします。 SelectedOptionsの初期値は、nullまたは未定義ではなく、空の配列でなければなりません。データの動的読み込みには、非同期でデータの更新を処理するために非同期プログラミングスキルを使用する必要があります。膨大なデータセットの場合、仮想スクロールや怠zyな読み込みなどのパフォーマンス最適化手法を考慮する必要があります。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
