

Transformer の画期的な研究は反対され、ICLR のレビューで疑問が生じました。国民はブラックボックス操作を非難、ルカン氏も同様の経験を明かす

昨年 12 月、CMU とプリンストンの 2 人の研究者が Mamba アーキテクチャをリリースし、即座に AI コミュニティに衝撃を与えました。
その結果、誰もが「トランスフォーマーの覇権を覆す」と期待していたこの論文が、今日、リジェクトの疑いがあることが明らかになった? !
今朝、コーネル大学准教授のサーシャ・ラッシュ氏は、基礎的研究であると期待されているこの論文がICLR 2024によって拒否されたようであることを初めて発見しました。
そして、「正直、わかりません。もし拒否されたら、チャンスはありますか?」と言いました。
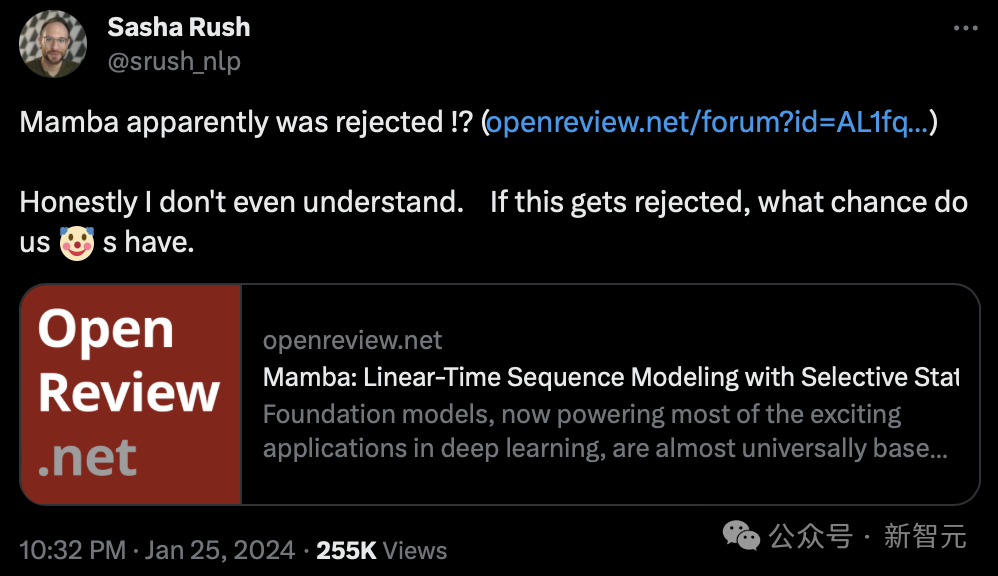
OpenReview でわかるように、4 人のレビュー担当者が与えたスコアは 3、6、8、8 です。
このスコアでは論文がリジェクトされることはないかもしれませんが、3 ポイントという低いスコアも法外です。
Niu Wen が 3 得点を挙げ、LeCun も苦情を言いに来ました。
この論文は、CMU とプリンストン大学の 2 人の研究者によって発表されました。 . 新しいアーキテクチャMambaが提案されています。
この SSM アーキテクチャは、言語モデリングにおいて Transformers に匹敵し、5 倍の推論スループットを持ちながら線形に拡張することもできます。

論文アドレス: https://arxiv.org/pdf/2312.00752.pdf
At当時この論文は発表されるやいなやAIコミュニティに衝撃を与え、ついにTransformerを打倒するアーキテクチャが誕生したと多くの人が言いました。
さて、マンバの論文は却下される可能性が高く、多くの人はそれを理解できません。
チューリングの巨人ルカン氏もこの議論に参加し、同様の「不正義」に遭遇したと述べた。
「当時、私が最も多く引用されていたと思います。Arxiv に投稿した論文だけでも 1,880 回以上引用されましたが、決して採用されませんでした。」
LeCun は、畳み込みニューラル ネットワーク (CNN) を使用した光学式文字認識とコンピューター ビジョンの研究で有名です。光学式文字認識とコンピュータ ビジョンで、2019 年にチューリング賞を受賞。
しかし、2015年に発表された彼の論文「グラフ構造データに基づく深層畳み込みネットワーク」は、トップカンファレンスに一度も受け入れられていません。

論文アドレス: https://arxiv.org/pdf/1506.05163.pdf
深さ学習 AI 研究者のセバスチャン・ラシュカ氏は、それにもかかわらず、Mamba は AI コミュニティに大きな影響を与えていると述べました。
最近、MoE-Mamba や Vision Mamba など、Mamba アーキテクチャに基づく研究の大きな波が押し寄せています。

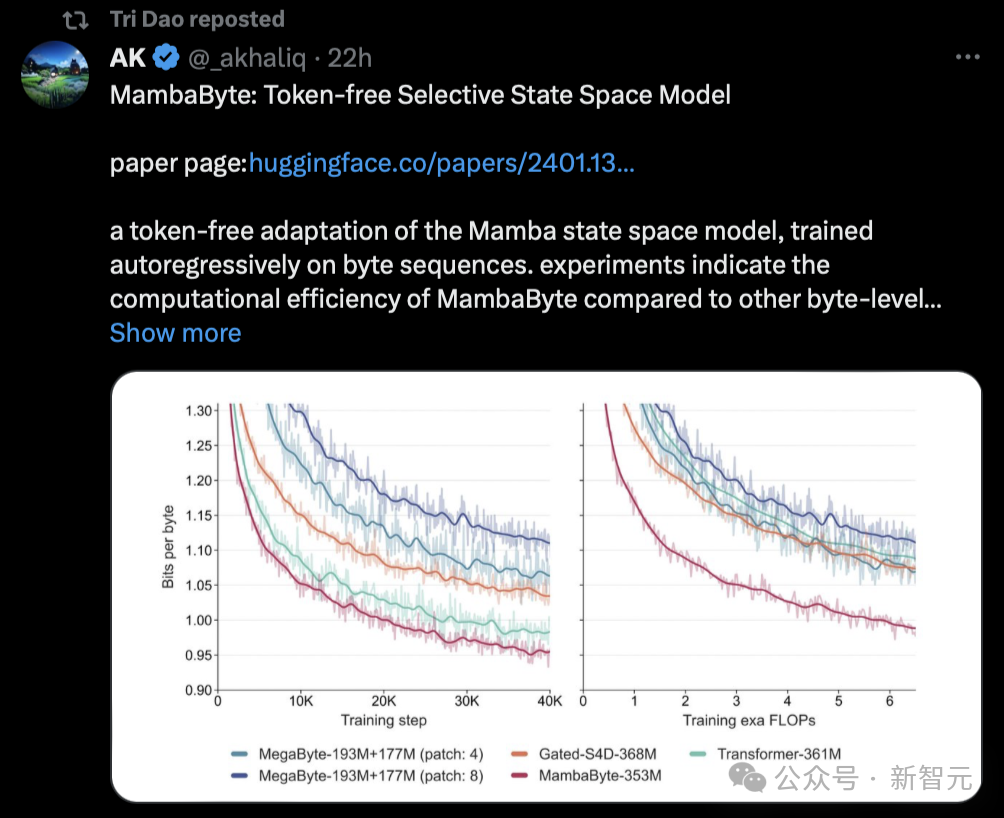
興味深いことに、マンバに低いスコアが与えられたというニュースを伝えたサーシャ・ラッシュも、今日そのような研究に基づいた新しい論文を発表しました—マンババイト。

実際、Mamba アーキテクチャには、「たった 1 つの火花が草原の火を引き起こす可能性がある」という考え方がすでに組み込まれています。学術界においても、その影響力はますます広がっています。
一部のネチズンは、Mamba の論文が arXiv を占拠し始めるだろうと言いました。
「たとえば、トークンのない選択的状態空間モデルである MambaByte を提案しているこの論文を目にしました。基本的に、これは Mamba SSM を元のトークンからの直接学習に適応させています。」

Mamba 紙の Tri Dao も本日、この研究を紹介しました。
このような人気のある論文に低いスコアが与えられたため、査読者はマーケティングにまったく注意を払っていないのではないかと言う人もいます。声が大きいです。
Mamba の論文が低いスコアを与えられた理由
Mamba の論文が与えられた理由スコアが低いのですが、それは何ですか?
レビューに 3 のスコアを付けたレビュー担当者の信頼レベルは 5 であることがわかります。これは、このスコアを非常に確信していることを意味します。

レビューでは、彼が提起した質問は 2 つの部分に分かれていました。1 つはモデルの設計に対する質問で、もう 1 つは実験に対する質問でした。 。
モデル設計
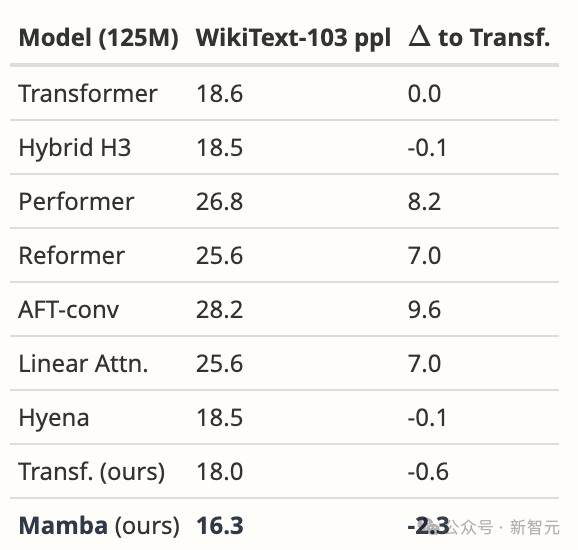
- Mamba の設計動機は、ループ モデルのパフォーマンスを向上させながら、ループ モデルの欠点を解決することです。 Transformer モデルの効率。この方向に沿った研究は数多くあります: S4-diagonal [1]、SGConv [2]、MEGA [3]、SPADE [4]、および多くの効率的な Transformer モデル ([5] など)。これらのモデルはすべてほぼ線形の複雑さを達成しており、著者はモデルのパフォーマンスと効率の点で Mamba とこれらの作品を比較する必要があります。モデルのパフォーマンスに関しては、いくつかの簡単な実験 (Wikitext-103 での言語モデリングなど) で十分です。
#- アテンションベースの Transformer モデルの多くは、長さを一般化する機能を備えています。つまり、モデルを短いシーケンス長でトレーニングしてから、より長いシーケンス長でテストを実行できます。例としては、相対位置エンコーディング (T5) や Alibi [6] などがあります。 SSM は一般に連続的であるため、Mamba にはこの長さの汎化能力があるのでしょうか?

実験
- 著者はより強力なベースラインと比較する必要があります。著者らは、H3 がモデル アーキテクチャの動機として使用されたことを認めています。ただし、実験的には H3 と比較できませんでした。 [7] の表 4 からわかるように、Pile データセットでは、H3 の ppl はそれぞれ 8.8 (125M)、7.1 (355M)、および 6.0 (1.3B) であり、Mamba よりも大幅に優れています。著者は H3 との比較を示す必要があります。
#- 事前トレーニング済みモデルについては、作成者はゼロショット推論の結果のみを示しています。この設定は非常に限定的であり、結果は Mamba の有効性をあまりよく示していません。著者らには、入力シーケンスが当然非常に長くなる(たとえば、arXiv データセットの平均シーケンス長が 8k を超える)ドキュメントの要約など、長いシーケンスを使った実験をさらに行うことをお勧めします。#- 著者は、彼の主な貢献の 1 つは長いシーケンスのモデリングであると主張しています。著者らは、基本的に長い配列を理解するための標準ベンチマークである LRA (Long Range Arena) 上のより多くのベースラインと比較する必要があります。
# - メモリ ベンチマークがありません。セクション 4.5 は「速度とメモリのベンチマーク」というタイトルですが、速度の比較のみをカバーしています。さらに、作成者は、図 8 の左側で、モデル層、モデル サイズ、畳み込みの詳細など、より詳細な設定を提供する必要があります。著者らは、シーケンス長が非常に長い場合に FlashAttend が最も遅くなる理由について直感的な説明を提供できますか (図 8 左)。
査読者の疑念について、著者も下調べをして、いくつかの実験データを考え出して反論しました。
たとえば、モデル設計に関する最初の質問に関して、著者は、チームが小規模なベンチマークではなく、大規模な事前トレーニングの複雑さに意図的に焦点を当てたと述べました。
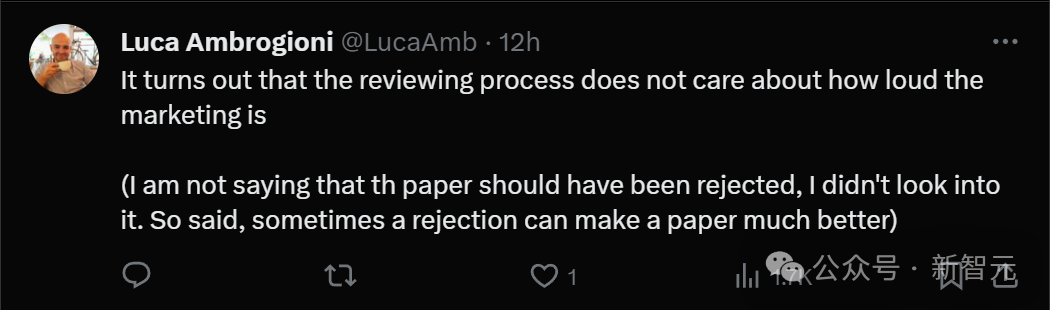
それにもかかわらず、Mamba は WikiText-103 で提案されているすべてのモデルなどを大幅に上回っており、これは言語の一般的な結果から予想されることです。
まず、ハイエナの論文とまったく同じ環境で Mamba を比較しました [Poli、表 4.3]。報告されたデータに加えて、私たちは独自の強力な Transformer ベースラインも調整しました。
その後、モデルを Mamba に変更しました。これにより、Transformer よりも 1.7 ppl、元のベースラインの Transformer よりも 2.3 ppl 改善されました。
「メモリ不足ベンチマーク」について、著者は次のように述べています:
ほとんどの深さのシーケンスの場合モデル (FlashAttend を含む) と同様に、メモリ使用量はアクティベーション テンソルのサイズのみです。実際、Mamba はメモリ効率が非常に高いため、A100 80GB GPU 上の 125M モデルのトレーニング メモリ要件も測定しました。各バッチは長さ 2048 のシーケンスで構成されます。これを、私たちが知っている中で最もメモリ効率の高い Transformer 実装 (torch.compile を使用したカーネル フュージョンおよび FlashAttendant-2) と比較しました。

反論の詳細については、https://openreview.net/forum?id=AL1fq05o7H
をご覧ください。 全体として、査読者のコメントは著者によって対処されていますが、これらの反論は査読者によって完全に無視されています。
誰かがこの査読者の意見に「要点」を見つけました: おそらく彼は rnn が何なのか理解していませんか?
その一部始終を見たネチズンは、全過程を読むのが苦痛だったと言っており、論文の著者は非常に丁寧な回答をしていましたが、査読者 迷うことも、再評価することもありません。

信頼度 5 で 3 点を与え、著者の十分に根拠のある反論は無視してください。この種の査読者は迷惑すぎます。バー。
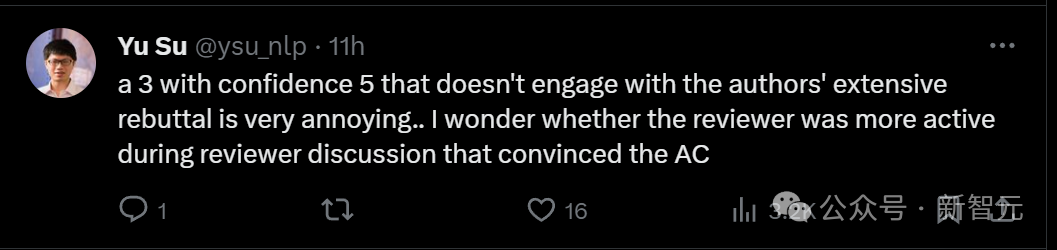
他の 3 人のレビュー担当者は、6、8、8 という高いスコアを付けました。
6 点を獲得したレビューアーは、「モデルはトレーニング中に Transformer のような二次記憶を依然として必要とする」という弱点を指摘しました。

#8 点を獲得した査読者は、この記事の弱点は単に「いくつかの関連著作への引用が欠如していること」であると述べました。
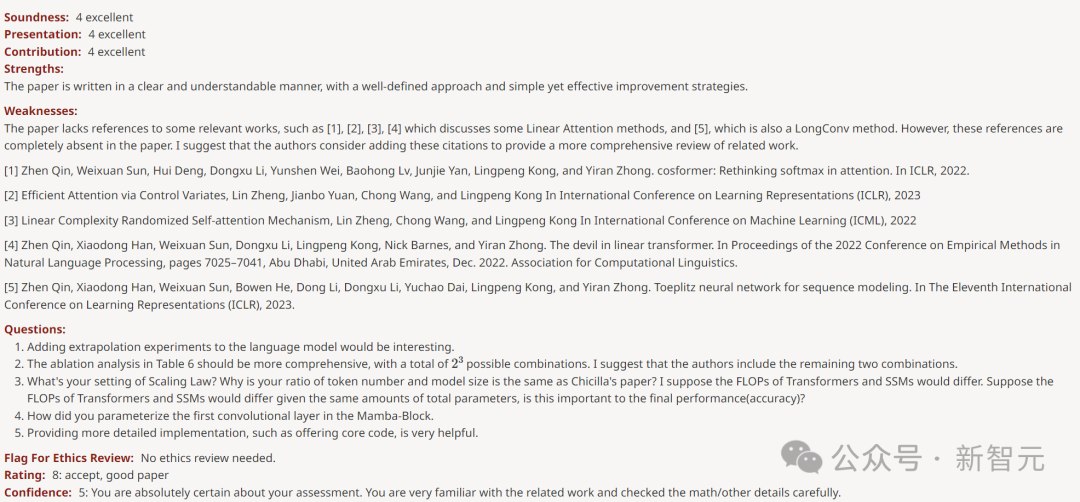
8 点を与えた別の査読者は、「実証的な部分が非常に徹底的で、結果は強力である」とこの論文を賞賛しました。
弱点すら見つかりませんでした。


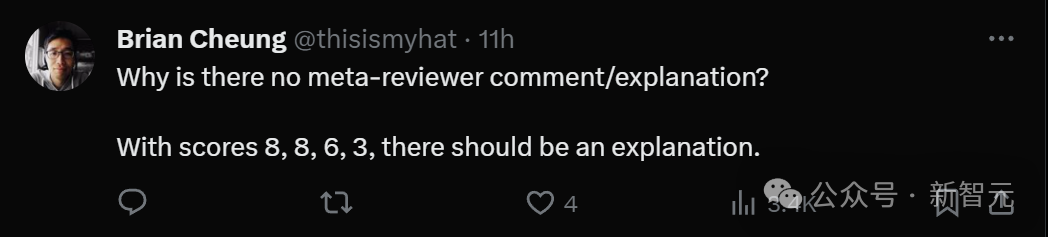
#このように大きく異なる分類については説明が必要です。しかし、メタレビューアーのコメントはまだありません。
ネチズンは「学術界も衰退した!」と叫びました。
コメント欄で魂の拷問について質問がありましたが、3 という低いスコアを付けたのは誰ですか? ?

明らかに、この論文は非常に低いパラメータでより良い結果を達成しており、GitHub コードも明確で誰でもテストできるため、この論文が勝利しました。広く賞賛されているので、誰もがそれはとんでもないことだと考えています。
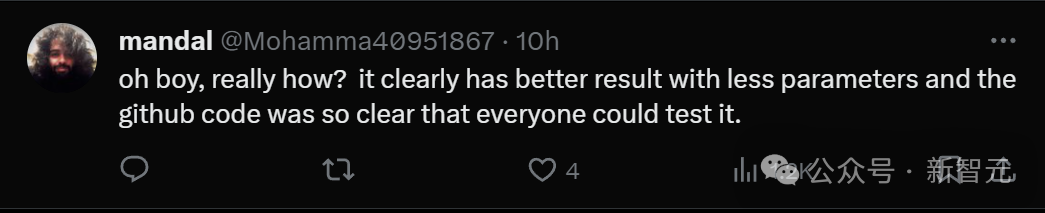
「なんてことだ」と単純に叫ぶ人もいます。たとえ Mamba アーキテクチャが LLM の状況を変えることができなかったとしても、Mamba は長いシーケンスで複数の用途に使用できる信頼性の高いモデルです。 。このスコアを獲得するということは、今日の学術界が衰退したことを意味するのでしょうか?
誰もが感動のため息をつきました。幸いなことに、これは 4 件のコメントのうちの 1 件にすぎません。他のレビューアーは高得点を付けました。現時点では、最終 A です。まだ決定は下されていない。
査読者は疲れすぎて判断力を失ったのではないかと推測する人もいます。
もう 1 つの理由は、状態空間モデルのような新しい研究の方向性が、トランスフォーマー分野で大きな成果を上げている一部の査読者や専門家を脅かす可能性があることです。状況は非常に複雑です。
マンバの論文が 3 ポイントを獲得したのは、業界では単なるジョークだという人もいます。
彼らは非常に詳細なベンチマークを比較することに重点を置いていますが、この論文の本当に興味深い部分はエンジニアリングと効率です。非常に狭い分野のサブセットの時代遅れのベンチマークに基づいているにもかかわらず、SOTA のみを気にしているため、研究は死につつあります。
「理論が足りず、プロジェクトが多すぎます。」

現時点では、この「謎の事件」はまだ明らかになっておらず、AI コミュニティ全体が結果を待っています。
以上がTransformer の画期的な研究は反対され、ICLR のレビューで疑問が生じました。国民はブラックボックス操作を非難、ルカン氏も同様の経験を明かすの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7751
7751
 15
1643
14
1398
52
1293
25
1234
29
15
1643
14
1398
52
1293
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
