

MySQL的表分区(转载)_MySQL

bitsCN.com
MySQL的表分区(转载)
一、什么是表分区 通俗地讲表分区是将一大表,根据条件分割成若干个小表。mysql5.1开始支持数据表分区了。 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区。当然也可根据其他的条件分区。
二、为什么要对表进行分区 为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。
分区的一些优点包括: 1)、与单个磁盘或文件系统分区相比,可以存储更多的数据。 2)、对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。通常和分区有关的其他优点包括下面列出的这些。MySQL分区中的这些功能目前还没有实现,但是在我们的优先级列表中,具有高的优先级;我们希望在5.1的生产版本中,能包括这些功能。 3)、一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。 4)、涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这种查询的一个简单例子如 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。通过“并行”,这意味着该查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。 5)、通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
三、分区类型
· RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。 · LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。 · HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。 · KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
- RANGE分区
基于属于一个给定连续区间的列值,把多行分配给分区。
这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。以下是实例。
Sql代码

- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- partition BY RANGE (store_id) (
- partition p0 VALUES LESS THAN (6),
- partition p1 VALUES LESS THAN (11),
- partition p2 VALUES LESS THAN (16),
- partition p3 VALUES LESS THAN (21)
- );
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求;在这点上,它类似于C或Java中的“switch ... case”语句。 对于包含数据(72, 'Michael', 'Widenius', '1998-06-25', NULL, 13)的一个新行,可以很容易地确定它将插入到p2分区中,但是如果增加了一个编号为第21的商店,将会发生什么呢?在这种方案下,由于没有规则把store_id大于20的商店包含在内,服务器将不知道把该行保存在何处,将会导致错误。 要避免这种错误,可以通过在CREATE TABLE语句中使用一个“catchall” VALUES LESS THAN子句,该子句提供给所有大于明确指定的最高值的值:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- PARTITION BY RANGE (store_id) (
- PARTITION p0 VALUES LESS THAN (6),
- PARTITION p1 VALUES LESS THAN (11),
- PARTITION p2 VALUES LESS THAN (16),
- PARTITION p3 VALUES LESS THAN MAXVALUE
- );
MAXVALUE 表示最大的可能的整数值。现在,store_id 列值大于或等于16(定义了的最高值)的所有行都将保存在分区p3中。在将来的某个时候,当商店数已经增长到25, 30, 或更多 ,可以使用ALTER TABLE语句为商店21-25, 26-30,等等增加新的分区。 在几乎一样的结构中,你还可以基于雇员的工作代码来分割表,也就是说,基于job_code 列值的连续区间。例如——假定2位数字的工作代码用来表示普通(店内的)工人,三个数字代码表示办公室和支持人员,四个数字代码表示管理层,你可以使用下面的语句创建该分区表:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT NOT NULL,
- store_id INT NOT NULL
- )
- PARTITION BY RANGE (job_code) (
- PARTITION p0 VALUES LESS THAN (100),
- PARTITION p1 VALUES LESS THAN (1000),
- PARTITION p2 VALUES LESS THAN (10000)
- );
在这个例子中, 店内工人相关的所有行将保存在分区p0中,办公室和支持人员相关的所有行保存在分区p1中,管理层相关的所有行保存在分区p2中。 在VALUES LESS THAN 子句中使用一个表达式也是可能的。这里最值得注意的限制是MySQL 必须能够计算表达式的返回值作为LESS THAN (Sql代码
- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY RANGE (YEAR(separated)) (
- PARTITION p0 VALUES LESS THAN (1991),
- PARTITION p1 VALUES LESS THAN (1996),
- PARTITION p2 VALUES LESS THAN (2001),
- PARTITION p3 VALUES LESS THAN MAXVALUE
- );
在这个方案中,在1991年前雇佣的所有雇员的记录保存在分区p0中,1991年到1995年期间雇佣的所有雇员的记录保存在分区p1中, 1996年到2000年期间雇佣的所有雇员的记录保存在分区p2中,2000年后雇佣的所有工人的信息保存在p3中。
RANGE分区在如下场合特别有用: 1)、 当需要删除一个分区上的“旧的”数据时,只删除分区即可。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用 “ALTER TABLE employees DROP PARTITION p0;”来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如“DELETE FROM employees WHERE YEAR (separated)
注释:这种优化还没有在MySQL 5.1源程序中启用,但是,有关工作正在进行中。
- LIST分区
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。 注释:在MySQL 5.1中,当使用LIST分区时,有可能只能匹配整数列表。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- );
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
==================== 地区 商店ID 号
------------------------------------
北区 3, 5, 6, 9, 17 东区 1, 2, 10, 11, 19, 20 西区 4, 12, 13, 14, 18 中心区 7, 8, 15, 16
==================== 要按照属于同一个地区商店的行保存在同一个分区中的方式来分割表,可以使用下面的“CREATE TABLE”语句:
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY LIST(store_id)
- PARTITION pNorth VALUES IN (3,5,6,9,17),
- PARTITION pEast VALUES IN (1,2,10,11,19,20),
- PARTITION pWest VALUES IN (4,12,13,14,18),
- PARTITION pCentral VALUES IN (7,8,15,16)
- );
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE employees DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE (删除)查询“DELETE query DELETE FROM employees WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。 【要点】:如果试图插入列值(或分区表达式的返回值)不在分区值列表中的一行时,那么“INSERT”查询将失败并报错。例如,假定LIST分区的采用上面的方案,下面的查询将失败:
Sql代码- INSERT INTO employees VALUES(224, 'Linus', 'Torvalds', '2002-05-01', '2004-10-12', 42, 21);
这是因为“store_id”列值21不能在用于定义分区pNorth, pEast, pWest,或pCentral的值列表中找到。要重点注意的是,LIST分区没有类似如“VALUES LESS THAN MAXVALUE”这样的包含其他值在内的定义。将要匹配的任何值都必须在值列表中找到。
LIST分区除了能和RANGE分区结合起来生成一个复合的子分区,与HASH和KEY分区结合起来生成复合的子分区也是可能的。
- HASH分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL 整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY HASH(store_id)
- PARTITIONS 4;
如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1。 例外: 对于NDB Cluster(簇)表,默认的分区数量将与簇数据节点的数量相同,
这种修正可能是考虑任何MAX_ROWS 设置,以便确保所有的行都能合适地插入到分区中。
- LINER HASH
MySQL还支持线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规 哈希使用的是求哈希函数值的模数。 线性哈希分区和常规哈希分区在语法上的唯一区别在于,在“PARTITION BY” 子句中添加“LINEAR”关键字。
Sql代码- CREATE TABLE employees (
- id INT NOT NULL,
- fname VARCHAR(30),
- lname VARCHAR(30),
- hired DATE NOT NULL DEFAULT '1970-01-01',
- separated DATE NOT NULL DEFAULT '9999-12-31',
- job_code INT,
- store_id INT
- )
- PARTITION BY LINEAR HASH(YEAR(hired))
- PARTITIONS 4;
假设一个表达式expr, 当使用线性哈希功能时,记录将要保存到的分区是num 个分区中的分区N,其中N是根据下面的算法得到: 1. 找到下一个大于num.的、2的幂,我们把这个值称为V ,它可以通过下面的公式得到: 2. V = POWER(2, CEILING(LOG(2, num))) (例如,假定num是13。那么LOG(2,13)就是3.7004397181411。 CEILING(3.7004397181411)就是4,则V = POWER(2,4), 即等于16)。 3. 设置 N = F(column_list) & (V - 1). 4. 当 N >= num: · 设置 V = CEIL(V / 2) · 设置 N = N & (V - 1) 例如,假设表t1,使用线性哈希分区且有4个分区,是通过下面的语句创建的: CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY LINEAR HASH( YEAR(col3) ) PARTITIONS 6; 现在假设要插入两行记录到表t1中,其中一条记录col3列值为'2003-04-14',另一条记录col3列值为'1998-10-19'。第一条记录将要保存到的分区确定如下: V = POWER(2, CEILING(LOG(2,7))) = 8 N = YEAR('2003-04-14') & (8 - 1) = 2003 & 7 = 3 (3 >= 6 为假(FALSE): 记录将被保存到#3号分区中) 第二条记录将要保存到的分区序号计算如下: V = 8 N = YEAR('1998-10-19') & (8-1) = 1998 & 7 = 6 (6 >= 4 为真(TRUE): 还需要附加的步骤) N = 6 & CEILING(5 / 2) = 6 & 3 = 2 (2 >= 4 为假(FALSE): 记录将被保存到#2分区中) 按照线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量(1000吉)数据的表。它的缺点在于,与使用
常规HASH分区得到的数据分布相比,各个分区间数据的分布不大可能均衡。
- KSY分区
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
Sql代码- CREATE TABLE tk (
- col1 INT NOT NULL,
- col2 CHAR(5),
- col3 DATE
- )
- PARTITION BY LINEAR KEY (col1)
- PARTITIONS 3;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
bitsCN.com
ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7625
7625
 15
1389
52
89
11
31
138
15
1389
52
89
11
31
138

 Xiaohonshu アカウントを使用してユーザーを見つけるにはどうすればよいですか?私の携帯電話番号を見つけることはできますか?
Mar 22, 2024 am 08:40 AM
Xiaohonshu アカウントを使用してユーザーを見つけるにはどうすればよいですか?私の携帯電話番号を見つけることはできますか?
Mar 22, 2024 am 08:40 AM
ソーシャルメディアの急速な発展に伴い、Xiaohongshuは最も人気のあるソーシャルプラットフォームの1つになりました。ユーザーは、Xiaohongshu アカウントを作成して自分の個人情報を示し、他のユーザーと通信し、対話することができます。ユーザーの小紅樹番号を見つける必要がある場合は、次の簡単な手順に従ってください。 1. Xiaohonshu アカウントを使用してユーザーを見つけるにはどうすればよいですか? 1. 小紅書アプリを開き、右下隅の「検出」ボタンをクリックして、「メモ」オプションを選択します。 2. ノート一覧で、探したいユーザーが投稿したノートを見つけます。クリックしてノートの詳細ページに入ります。 3. ノートの詳細ページで、ユーザーのアバターの下にある「フォロー」ボタンをクリックして、ユーザーの個人ホームページに入ります。 4. ユーザーの個人ホームページの右上隅にある三点ボタンをクリックし、「個人情報」を選択します。
 Windows 11 でローカル ユーザーとグループが見つからない: 追加する方法
Sep 22, 2023 am 08:41 AM
Windows 11 でローカル ユーザーとグループが見つからない: 追加する方法
Sep 22, 2023 am 08:41 AM
ローカル ユーザーとグループ ユーティリティはコンピュータの管理に組み込まれており、コンソールからまたは独立してアクセスできます。ただし、一部のユーザーは、Windows 11 でローカル ユーザーとグループが見つからないことに気づきます。これにアクセスできる一部のユーザーに対して、このメッセージは、このスナップインがこのバージョンの Windows 10 では動作しない可能性があることを示唆しています。このコンピュータのユーザー アカウントを管理するには、コントロール パネルのユーザー アカウント ツールを使用します。この問題は Windows 10 の以前のバージョンでも報告されており、通常はユーザー側の問題や見落としが原因で発生します。 Windows 11 でローカル ユーザーとグループが表示されないのはなぜですか? Windows Home エディションを実行しています。ローカル ユーザーとグループは、Professional エディション以降で使用できます。活動
 スーパーユーザーとして Ubuntu にログインします
Mar 20, 2024 am 10:55 AM
スーパーユーザーとして Ubuntu にログインします
Mar 20, 2024 am 10:55 AM
Ubuntu システムでは、通常、root ユーザーは無効になっています。 root ユーザーをアクティブにするには、passwd コマンドを使用してパスワードを設定し、su-コマンドを使用して root としてログインします。 root ユーザーは、無制限のシステム管理権限を持つユーザーです。彼は、ファイルへのアクセスと変更、ユーザー管理、ソフトウェアのインストールと削除、およびシステム構成の変更を行う権限を持っています。 root ユーザーと一般ユーザーの間には明らかな違いがあり、root ユーザーはシステム内で最高の権限とより広範な制御権限を持ちます。 root ユーザーは、一般のユーザーでは実行できない重要なシステム コマンドを実行したり、システム ファイルを編集したりできます。このガイドでは、Ubuntu の root ユーザー、root としてログインする方法、および通常のユーザーとの違いについて説明します。知らせ
 Pinduoduo で購入したものの記録はどこで確認できますか? 購入した製品の記録を表示するにはどうすればよいですか?
Mar 12, 2024 pm 07:20 PM
Pinduoduo で購入したものの記録はどこで確認できますか? 購入した製品の記録を表示するにはどうすればよいですか?
Mar 12, 2024 pm 07:20 PM
Pinduoduo ソフトウェアは多くの優れた製品を提供し、いつでもどこでも購入でき、各製品の品質は厳しく管理され、すべての製品は正規品であり、多くの優遇ショッピング割引があり、誰もがオンラインで買い物をすることができます。携帯電話番号を入力してオンラインにログインし、オンラインで複数の配送先住所や連絡先情報を追加し、最新の物流動向をいつでも確認できます さまざまなカテゴリの商品セクションが開き、検索して上下にスワイプして購入および注文することができます家から出ることなく利便性を体験することができます.オンライン ショッピング サービスでは、購入した商品を含むすべての購入記録を確認することもでき、数十のショッピング赤い封筒とクーポンを無料で受け取ることもできます.今回、編集者は Pinduoduo ユーザーに詳細なオンライン サービスを提供しました購入した製品の記録を表示する方法。 1. 携帯電話を開き、Pinduoduo アイコンをクリックします。
 Windows 11 ガイドの探索: 古いハード ドライブ上のユーザー フォルダーにアクセスする方法
Sep 27, 2023 am 10:17 AM
Windows 11 ガイドの探索: 古いハード ドライブ上のユーザー フォルダーにアクセスする方法
Sep 27, 2023 am 10:17 AM
特定のフォルダーは権限の関係で常にアクセスできるわけではありません。今日のガイドでは、Windows 11 で古いハード ドライブ上のユーザー フォルダーにアクセスする方法を説明します。このプロセスは簡単ですが、ドライブのサイズによっては、しばらく時間がかかり、場合によっては数時間もかかる場合があるため、特に忍耐強く、このガイドの指示に厳密に従ってください。古いハードドライブ上のユーザーフォルダーにアクセスできないのはなぜですか?ユーザー フォルダーは別のコンピューターによって所有されているため、変更できません。このフォルダーには所有権以外の権限がありません。古いハードドライブ上のユーザーファイルを開くにはどうすればよいですか? 1. フォルダーの所有権を取得し、アクセス許可を変更します。 古いユーザー ディレクトリを見つけて右クリックし、[プロパティ] を選択します。 「An」に移動します
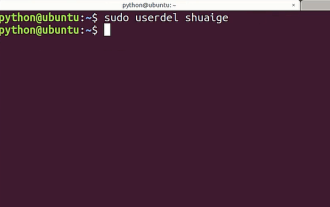 チュートリアル: Ubuntu システムで通常のユーザー アカウントを削除する方法は?
Jan 02, 2024 pm 12:34 PM
チュートリアル: Ubuntu システムで通常のユーザー アカウントを削除する方法は?
Jan 02, 2024 pm 12:34 PM
Ubuntu システムに多くのユーザーが追加されました。使用しなくなったユーザーを削除したいのですが、どうすればよいですか?以下の詳細なチュートリアルを見てみましょう。 1. ターミナルのコマンドラインを開き、userdel コマンドを使用して、指定したユーザーを削除します。下図に示すように、必ず sudo 権限コマンドを追加してください。 2. 削除するときは、必ず管理者ディレクトリにいることを確認してください。一般ユーザー以下の図に示すように、この権限がありません。 3. 削除コマンドを実行した後、本当に削除されたかどうかをどのように判断しますか?次に、下の図に示すように、cat コマンドを使用して passwd ファイルを開きます。 4. 次の図に示すように、削除されたユーザー情報が passwd ファイル内になくなっていることがわかり、ユーザーが削除されたことがわかります。 5. 次に、ホームファイルを入力します
 sudo とは何ですか?なぜ重要ですか?
Feb 21, 2024 pm 07:01 PM
sudo とは何ですか?なぜ重要ですか?
Feb 21, 2024 pm 07:01 PM
sudo (スーパーユーザー実行) は、一般ユーザーが root 権限で特定のコマンドを実行できるようにする、Linux および Unix システムの重要なコマンドです。 sudo の機能は主に次の側面に反映されています。 権限制御の提供: sudo は、ユーザーにスーパーユーザー権限を一時的に取得することを許可することで、システム リソースと機密性の高い操作を厳密に制御します。一般のユーザーは、必要な場合にのみ sudo を介して一時的な権限を取得できるため、常にスーパーユーザーとしてログインする必要はありません。セキュリティの向上: sudo を使用すると、日常的な操作中に root アカウントの使用を回避できます。すべての操作に root アカウントを使用すると、誤った操作や不注意な操作には完全な権限が与えられるため、予期しないシステムの損傷につながる可能性があります。そして
 Windows 11 KB5031455 のインストールに失敗し、一部のユーザーに他の問題が発生する
Nov 01, 2023 am 08:17 AM
Windows 11 KB5031455 のインストールに失敗し、一部のユーザーに他の問題が発生する
Nov 01, 2023 am 08:17 AM
Microsoft は、Windows 503145511H22 以降のオプションの更新プログラムとして KB2 の一般公開を開始しました。これは、サポートされている領域での Windows Copilot、スタート メニューの項目のプレビュー サポート、タスク バーのグループ解除などを含む、Windows 11 Moment 4 の機能をデフォルトで有効にする最初の更新プログラムです。さらに、メモリ リークを引き起こす潜在的なパフォーマンスの問題など、Windows 11 のいくつかのバグも修正されています。しかし皮肉なことに、2023 年 9 月のオプションのアップデートは、アップデートをインストールしようとしているユーザーにとっても、すでにインストールしているユーザーにとっても大惨事となるでしょう。多くのユーザーはこの Wi をインストールしないでしょう
