

LLM ウィザードの魔法の杖を解き明かし、UIUC 中国チームはコード データの 3 つの主要な利点を明らかにします

大規模モデル時代の言語モデル (LLM) のサイズとトレーニング データは、自然言語やコードを含めて増加しました。
コードは人間とコンピューターの間の仲介者であり、高レベルの目標を実行可能な中間ステップに変換します。文法標準、論理的一貫性、抽象化、モジュール性という特徴があります。
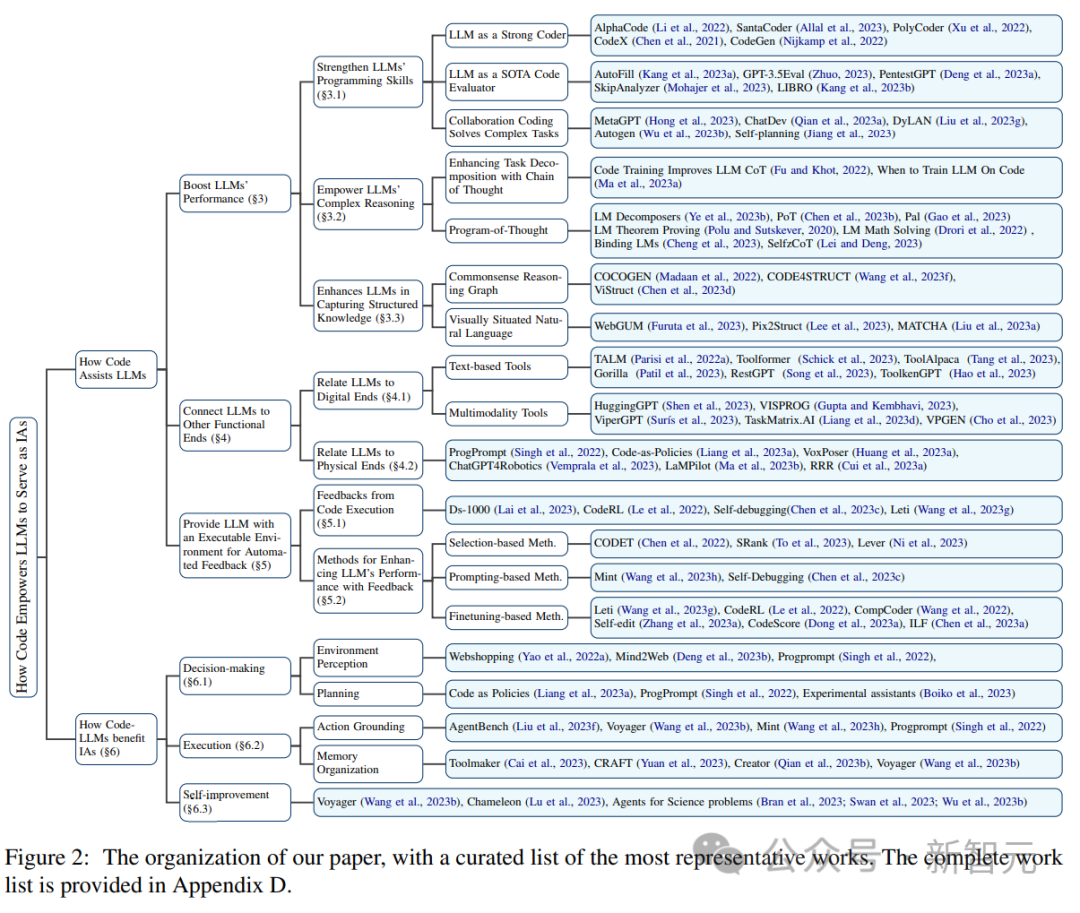
イリノイ大学アーバナシャンペーン校の研究チームは最近、コードを LLM トレーニング データに統合することの複数の利点をまとめたレビュー レポートを発表しました。

紙のリンク: https://arxiv.org/abs/2401.00812v1
詳細については、 LLM のコード生成機能の向上に加えて、次の 3 つの利点も含まれます:
1. LLM の推論機能のロックを解除し、それを一連のより複雑なコードに適用できるようにします。自然言語タスク;
#2. LLM をガイドして、構造化された正確な中間ステップを生成し、関数呼び出しを通じて外部の実行エンドに接続できます。 #3. コードのコンパイルおよび実行環境を使用して、モデルをさらに改善するためのより多様なフィードバック信号を提供できます。
さらに、研究者らは、指示を理解し、目標を分解し、計画を立て、アクションを実行してフィードバックを引き出す能力がどのように発揮されるのかについても追跡しました。下流のタスクで重要な役割を果たします。 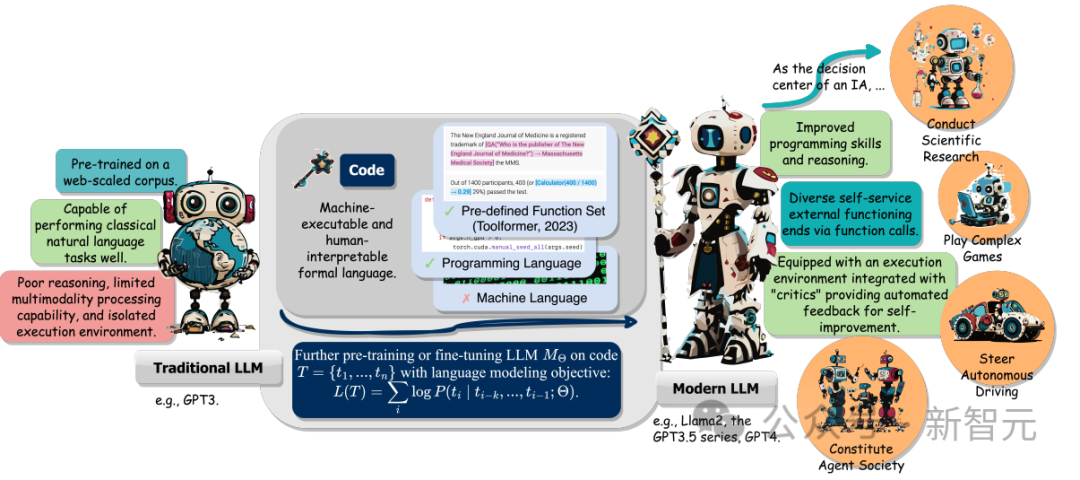
最後に、この記事では、「コードによる LLM の強化」の分野における主要な課題と今後の研究の方向性も提案しています。
コードの事前トレーニングにより LLM のパフォーマンスが向上します
コード生成タスクには 2 つの特徴があります。1) コード シーケンスは効果的に実行される必要があるため、一貫したロジックが必要です。2) 各中間ステップを段階的に検証できます (ステップバイステップのロジック検証)。
事前トレーニングでコードを利用して埋め込むと、従来の自然言語の下流タスクにおける LLM 思考連鎖 (CoT) テクノロジーのパフォーマンスが向上します。これは、コード トレーニングが LLM の実行能力を向上できることを示しています。複雑な推理。
コードの構造化された形式から暗黙的に学習することにより、コード LLM は、マークアップ、HTML、図の理解などの常識的な構造推論タスクでも優れたパフォーマンスを示します。
機能/機能エンドのサポート
最近の研究結果では、LLM を他の機能エンドポイントに接続する (つまり、外部ツールや実行モジュール拡張 LLM を使用する) と、LLM のパフォーマンスが向上することが示されています。タスクをより正確かつ確実に実行できます。これらの機能目的により、LLM は外部の知識を取得し、複数のモーダル データに参加し、環境と効果的に対話できるようになります。
関連研究から、研究者らは、LLM がプログラミング言語を生成するか、事前定義された関数を利用して他の言語とのインターフェイスを構築するという共通の傾向を観察しました。機能端末は「コード中心」のパラダイムです。 
LLM 推論メカニズムにおける厳密にハードコーディングされたツール呼び出しの固定された実際的なフローとは対照的に、コード中心のパラダイムにより、LLM は動的にトークンを生成し、適応可能なパラメーターを使用できます。モジュールは、LLM が他の機能端末と対話するためのシンプルかつ明確な方法を提供し、アプリケーションの柔軟性と拡張性を強化します。
重要なのは、このパラダイムにより、LLM がさまざまなモダリティやドメインにわたって多数の機能端末と対話できるようになり、アクセス可能な機能端末の数と種類を拡張することで、LLM はより複雑なタスクを処理できるようになります。
この記事では主に、LLM に接続されたテキストとマルチモーダル ツール、およびロボットや自動運転などの物理世界の機能的目的について研究し、LLM の役割を実証します。ドメインの問題に関するさまざまなモードと汎用性を解決します。
自動フィードバックを提供する実行可能環境
LLM は、特に静的でない場合にフィードバック信号を吸収するモデルの能力により、トレーニング パラメーターを超えるパフォーマンスを示します。現実世界のアプリケーション。
ただし、ノイズの多いキューは下流タスクでの LLM のパフォーマンスを妨げる可能性があるため、フィードバック信号の選択には注意する必要があります。
さらに、人件費がかかるため、ロイヤルティを維持しながらフィードバックを自動的に収集することが重要です。
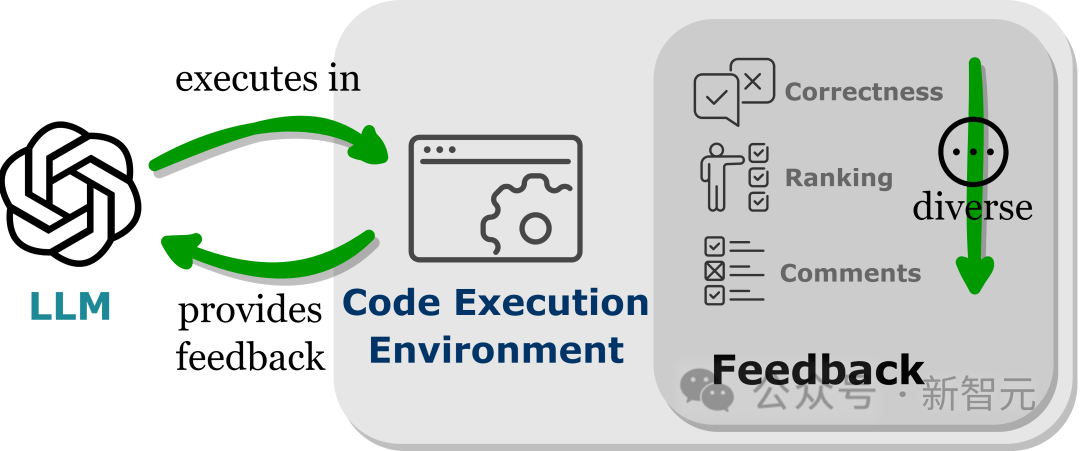
LLM をコード実行環境に埋め込むと、上記の条件の自動フィードバックを実現できます。
コードの実行はほぼ決定的であるため、LLM がコードの実行結果から取得するフィードバックは、ターゲット タスクに忠実なままです。コード インタープリタは、LLM に対する内部フィードバックも照会します。自動パスは次のとおりです。手動による注釈を付けずに、LLM によって生成されたエラー コードをデバッグおよび最適化するために提供されます。
さらに、コード環境により、LLM は、バイナリ正しさフィードバック、結果の自然言語説明、報酬値ランキングなどを含む (ただしこれらに限定されない) さまざまな外部フィードバック フォームを統合できます。これにより、パフォーマンスを向上させるための高度にカスタマイズ可能なアプローチ。

現在の課題
コードの事前トレーニングと LLM 推論の強化との因果関係
コード データの特定のプロパティが LLM の推論能力に寄与している可能性があることは直感的に思われますが、推論スキルの強化に対するそれらの影響の正確な範囲は不明のままです。
研究作業の次のステップでは、これらのコード属性がトレーニング データ内のトレーニング済み LLM の推論能力を実際に強化できるかどうかを研究することが重要です。
コードの特定のプロパティに関する事前トレーニングによって LLM の推論能力が直接向上することが本当であれば、この現象を理解することが、現在の複雑な推論能力をさらに向上させるための鍵となります。モデル。
#推論能力はコードに限定されません
推論能力はコードの事前トレーニングによって強化されますが、 , 基礎となるモデルには、真の汎用人工知能に期待される人間のような推論能力がまだ欠けています。
コードに加えて、他の多数のテキスト データ ソースには、LLM 推論機能を強化する可能性があります。曖昧さのなさ、実行可能性、およびコード固有の特性が向上します。論理的な順序構造を使用して、データセットを収集するためのより良い方法を提供したり、これらのデータセットを作成するための指針を提供したりできます。
しかし、言語モデリングの目標を掲げて大規模なコーパスで言語モデルをトレーニングするというパラダイムにこだわり続けると、形式的な言語よりも抽象的な、逐次的に読み取り可能な言語を実現するのは困難になります。言語: 高度に構造化されており、記号言語と密接に関連しており、デジタル ネットワーク環境に豊富に存在します。
研究者らは、代替データ パターン、多様なトレーニング目標、新しいアーキテクチャを探索することで、モデル推論機能をさらに強化する機会が増えると想定しています。
コード中心のパラダイムを適用する際の課題
LLM では、コードはさまざまなメイン ネットワークに接続するために使用されます。関数端子の課題は、正しい関数 (関数) 端子の選択や、適切なタイミングで正しいパラメーターの受け渡しなど、さまざまな関数を呼び出す正しい方法を学習することです。
たとえば、単純なタスク (Web ページ ナビゲーション) の場合、マウスの移動、クリック、ページ スクロールなどの限られたアクション プリミティブのセットを考慮して、いくつかの例を示します (いくつかの例は示しています)。 -shot)、強力な基本 LLM では、多くの場合、LLM がこれらのプリミティブの使用法を正確に習得する必要があります。
化学、生物学、天文学などのデータ集約型の分野でのより複雑なタスクには、さまざまな機能を持つ多くの複雑な関数を含むドメイン固有の Python ライブラリへの呼び出しが含まれます。これらの学習機能を正しく呼び出せるように LLM を強化します。機能の統合は、LLM がきめ細かい領域で専門家レベルのタスクを実行できるようにする将来を見据えた方向性です。
複数ラウンドのインタラクションとフィードバックから学ぶ
LLM は多くの場合、ユーザーや環境と継続的に複数のインタラクションを必要とします。自分自身を修正して、複雑なタスクの完了を向上させます。
コードの実行により、信頼性が高くカスタマイズ可能なフィードバックが提供されますが、このフィードバックを完全に活用する完璧な方法はまだ確立されていません。
現在の選択ベースの方法は便利ですが、パフォーマンスの向上は保証できず、非効率的です。再帰ベースの方法は LLM のコンテキスト学習能力に大きく依存しているため、LLM のコンテキスト学習能力が制限される可能性があります。適用性 ; 微調整方法は継続的に改善されていますが、データ収集と微調整はリソースを大量に消費するため、実際に使用するのは困難です。
研究者らは、強化学習がフィードバックを活用して改善するためのより効果的な方法である可能性があり、場合によっては慎重に設計された報酬関数を通じてフィードバックに適応する動的な方法を提供し、制限に対処できると考えています。現在の技術。
しかし、報酬関数を設計する方法や、複雑なタスクを完了するために強化学習と LLM を最適に統合する方法を理解するには、まだ多くの研究が必要です。
以上がLLM ウィザードの魔法の杖を解き明かし、UIUC 中国チームはコード データの 3 つの主要な利点を明らかにしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7444
7444
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueおよびElement-UIカスケードドロップダウンボックスVモデルバインディング
Apr 07, 2025 pm 08:06 PM
VueとElement-UIカスケードドロップダウンボックスv-Modelバインディング共通ピットポイント:V-Modelは、文字列ではなく、カスケード選択ボックスの各レベルで選択した値を表す配列をバインドします。 SelectedOptionsの初期値は、nullまたは未定義ではなく、空の配列でなければなりません。データの動的読み込みには、非同期でデータの更新を処理するために非同期プログラミングスキルを使用する必要があります。膨大なデータセットの場合、仮想スクロールや怠zyな読み込みなどのパフォーマンス最適化手法を考慮する必要があります。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
