

Oracle12.2 のアーキテクチャを理解する: ファイル システムとマルチテナント

- RVWR: リカバリ ライター プロセス。データベースがフラッシュバック領域を設定すると、プロセスはメモリ内のフラッシュバック データ、具体的には共有プール内のフラッシュバック バッファをフラッシュバック ログに定期的に書き込みます。
- 結果キャッシュ –> RCBG:結果キャッシュは、SQL ステートメントまたは plsql 関数の実行中に元のデータ操作の結果を保存するために使用されます。データベースが同じ操作を同じデータに対して実行する場合、オブジェクトを再度操作すると、結果を直接取得できるため、コンピューティング リソースの無駄が回避されます。
- ASH バッファ–>MMNL: ASH バッファは、SQL 実行ステータス、アプリケーション接続ステータス、待機中のイベントなどを含む、アクティブなセッションの統計情報を保存するために使用されます。 ASH バッファがいっぱいになると、MMNL プロセスはバッファ内のデータをディスクに書き込みます。
- メモリ内アンドゥ (IMU): 一時的なアンドゥを保存するために共有プール内の領域を開きます。トランザクション内で複数のデータが変更された場合、バッファ キャッシュ内のアンドゥ データ ブロックは消去されません。修正しましたが、記録用の IMU ノードを追加します。主に、アンドゥによって生成されるやり直しを減らすためです。
- プライベート REDO ログ バッファ: 主に、IMU によって生成された一時 REDO を管理し、トランザクションの REDO 情報を共有プールに保存し、REDO ログ バッファの消費を削減するために使用されます。
- フラッシュ キャッシュ: 正式名称はデータベース スマート フラッシュ キャッシュで、11.2 から開発されたフラッシュ メモリの最適化テクノロジです。従来の低速ディスク デバイスの代わりにフラッシュ メモリを使用して一部のデータを保存することを目的としています。データベースの全体的な遅延を削減し、データベースの IOPS を改善し、データベースのパフォーマンスを向上させるという目的を達成するため。
フラッシュ キャッシュは次のように動作します:
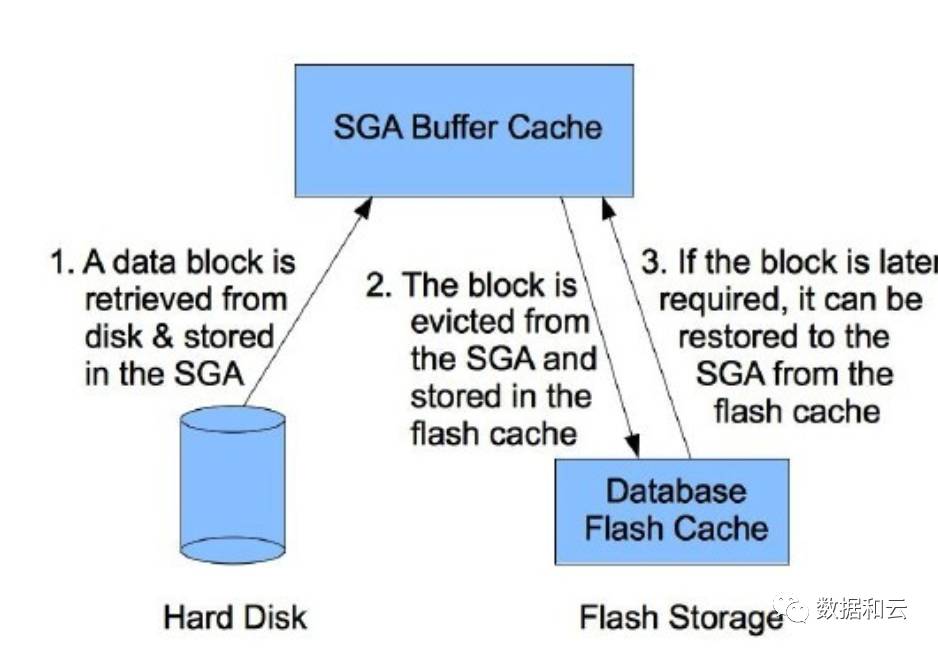
Flash Cache に保存されたコンテンツは 2 つの方法で制御されます:
1. フラッシュ キャッシュのインテリジェントな選択アルゴリズム: データ ブロックとインデックス ブロックのアクセス頻度を評価して決定します。
2. データベース オブジェクトの cell_flash_cache 属性を変更します。
フラッシュ キャッシュ ストレージ コンテンツの基本標準
主に小規模な IO 操作のほか、データ ブロック、インデックス ブロック、ファイル ヘッダー、制御ファイルなどがキャッシュされます;
RMAN バックアップ IO 操作、データ ポンプ IO 操作、ASM ミラーリング操作、表スペースのフォーマットなどの場合、キャッシュされません。
フル テーブル スキャンの IO 操作のキャッシュ優先度は比較的低いです。フラッシュ キャッシュにデータを格納する場合、主にクエリ速度の向上が目的であり、言い換えれば、メモリに加えてバッファ キャッシュ領域の一部を追加することに相当しますが、パフォーマンスは向上し、スピードが良くなります。次に、バッファ キャッシュと同様に、フラッシュ キャッシュ内のデータがいっぱいになるか、ある程度まで書き込まれた場合、新しい操作データ用のスペースを残すために、データをディスクに書き込む必要があります。
キャッシュ内のデータをディスクに書き込むことをフラッシュと呼びます。 キャッシュ フラッシュ レベルの開始および停止の値を構成できます。これは、占有されているキャッシュ サイズ全体の割合を表します。ディスクに書き込まれていないキャッシュ内のデータがフラッシュ開始値に達すると、コントローラーはフラッシュを開始します (キャッシュからディスクに書き込まれます)。キャッシュ内の未書き込みのディスク データの量がフラッシュ停止値よりも少ない場合、フラッシュ プロセスは停止します。
開始フラッシュ レベルを高く設定すると、より多くの未書き込みデータをメモリにキャッシュできます。これにより、書き込み操作のパフォーマンスが向上しますが、データ保護が犠牲になります。データを保護したい場合は、より低い開始値と終了値を使用できます。テストの結果、クローズ開始および終了フラッシュ レベルを使用するとパフォーマンスが向上することがわかりました。停止レベルの値が開始値よりも大幅に低い場合、フラッシュ中にディスクの輻輳が発生します
スマートフラッシュロギング 長い間、REDO ログの IO ボトルネックは OLTP システムを悩ませてきた大きな問題でした。これは、REDO の書き込み遅延がシステム全体、さらにはクラスター全体の応答速度を直接低下させるためです。従来のデータベース アーキテクチャでは、一部の DBA は、読み取りおよび書き込みのレイテンシが低い小さなブロック ストレージを個別に Redo に割り当てます。
11204 以降、オラクルは、特にフラッシュ メモリ領域で Redo を提供する新しいソリューションを提案しました。一時的なREDOを保存する領域。
列ストレージをフラッシュ・キャッシュに配置して、頻繁に操作される列ストレージ・オブジェクトの書き込みIOを改善します
- 変更追跡ファイル:増分バックアップでブロックの変更を検出し、ファイルに記録します。記録単位はブロックです。
- wallet: Oracle Wallet は、キーを保管するために使用されるコンテナです。簡単に言うとパスワードボックスですが、このパスワードボックスにより、本来パスワードの入力が必要な場面でパスワードを入力せずに利用できるようになり、アカウントのパスワードなどの機密情報を保護し、セキュリティの向上と利便性の向上を図ることができます。使用します。
アプリケーション コンテナは、12.2 で提案された新しいコンポーネントです。同じアプリケーション下のデータベース システムをサブコンテナに分割し、マルチテナントの同一管理を保証しながら、相対的なビジネス分離とデータ セキュリティを実現します。
PDB には独自の UNDO テーブルスペースがあります12.2 以降、各 PDB には独自の UNDO 表領域があります。これにより、複数の PDB 間の競合が排除され、フラッシュバックまたはタイムスタンプ ベースのリカバリを実行する場合は、独自の UNDO データを検索するだけで効率が向上します。
柔軟なPDB作成方法1. PDB$seed (またはアプリケーション ルート) から作成: ファイルをコピーします
2. 既存の PDB はホット クローンによって作成されます
注: 12.1 では、PDB に基づいて新しい PDB を作成する場合、元のライブラリを読み取り専用モードで開く必要があります。
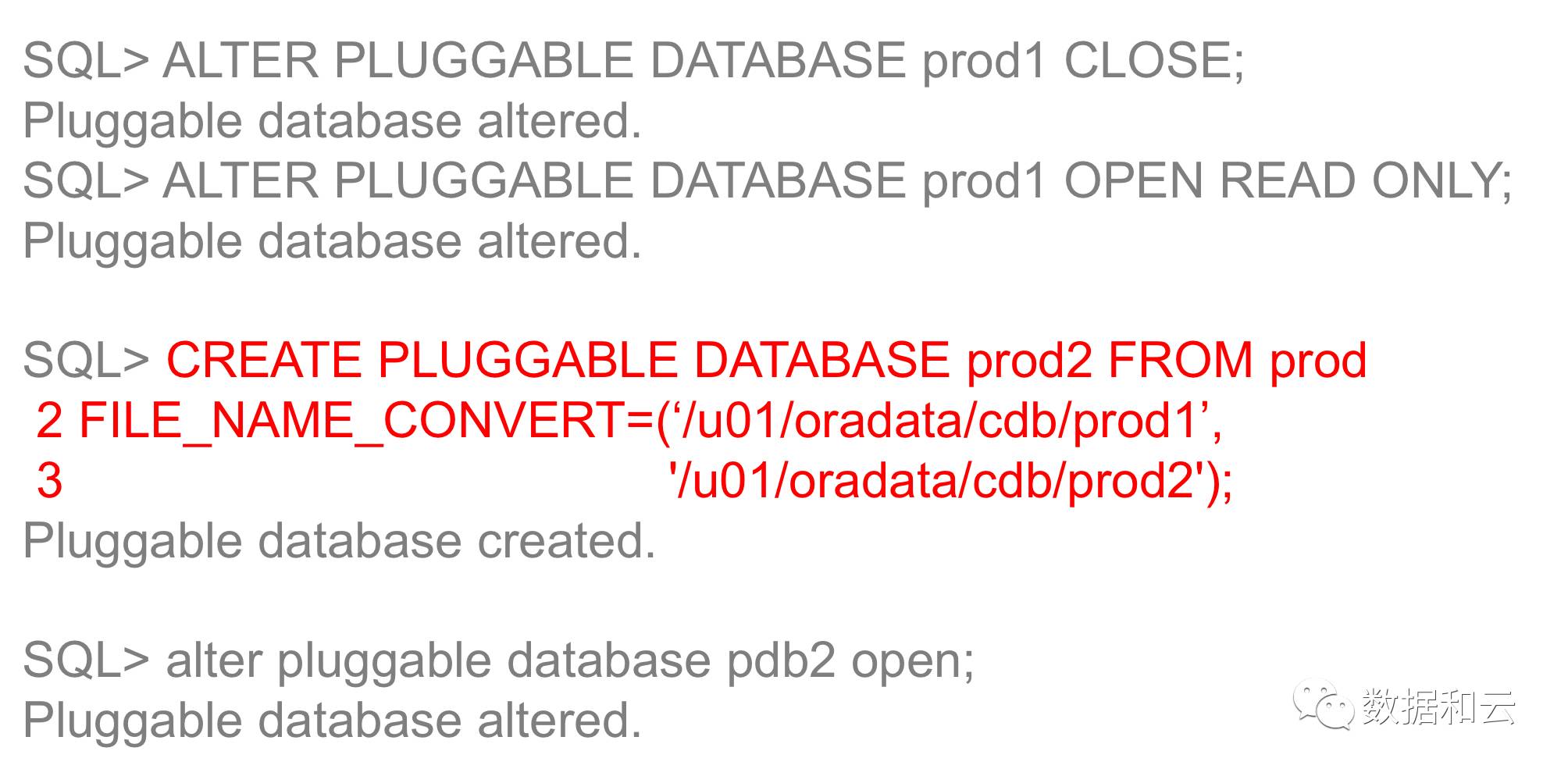
12.2 では、元のライブラリは影響を受けることなく DML 操作を引き続き実行できます。
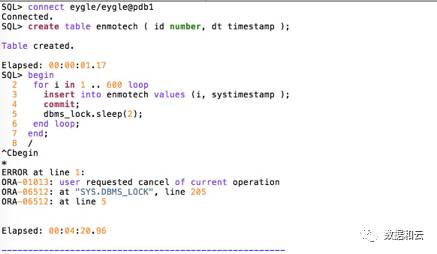
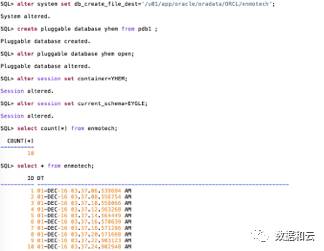
クローン作成が完了すると、データは引き続き新しいデータベースに更新されます。
3. 他の CDB への PDB からの移行: 再配置
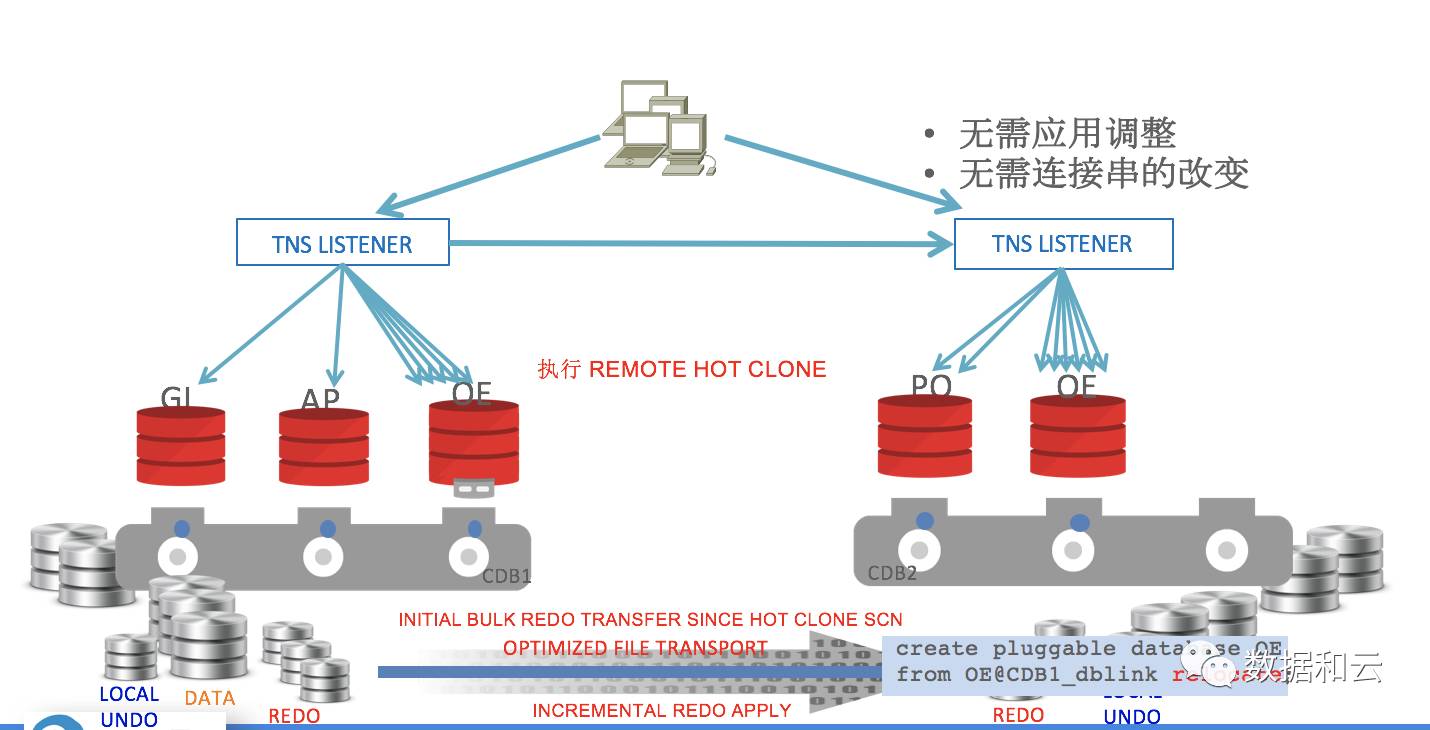
フロントエンドは、relocate からプラガブル データベースの作成などのコマンドを実行し、バックグラウンドではリモート ホット クローンが自動的に実行され、リモート ファイルのコピーと同期が実行されます。
4. ASM ディスク ファイルのシャドウ コピーを通じて新しい PDB を生成します。
PDB メモリ リソース管理
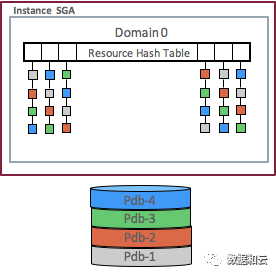
マルチテナント環境では、複数のPDBがメモリリソースを共有するため、PDBがバッファキャッシュをアドレス指定する必要がある場合、共有リソース全体から検索する必要があり、非常に不便です。 12.2 では、Oracle は一部のリソースに対して PDB ベースのドメイン分割を実装しました。
12.1 のメモリ リソースのハッシュ リストは次のとおりです:
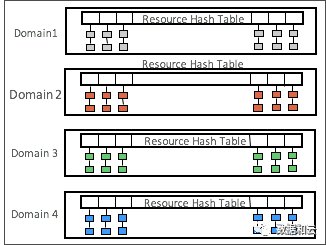
これは 12.2 で起こることです:
PDB のその他の新機能
1. キャラクタ セット: 12.2 では、CDB キャラクタ セットがスーパーセット、つまり AL32UTF8 の場合、異なるキャラクタ セットを持つ PDB がサポートされます。同時に、プロキシ PDB を介して、異なる文字セットを持つ PDB をクエリすることができ、プロキシは文字化けすることなく、双方の文字セットを識別して互換性を持たせます。
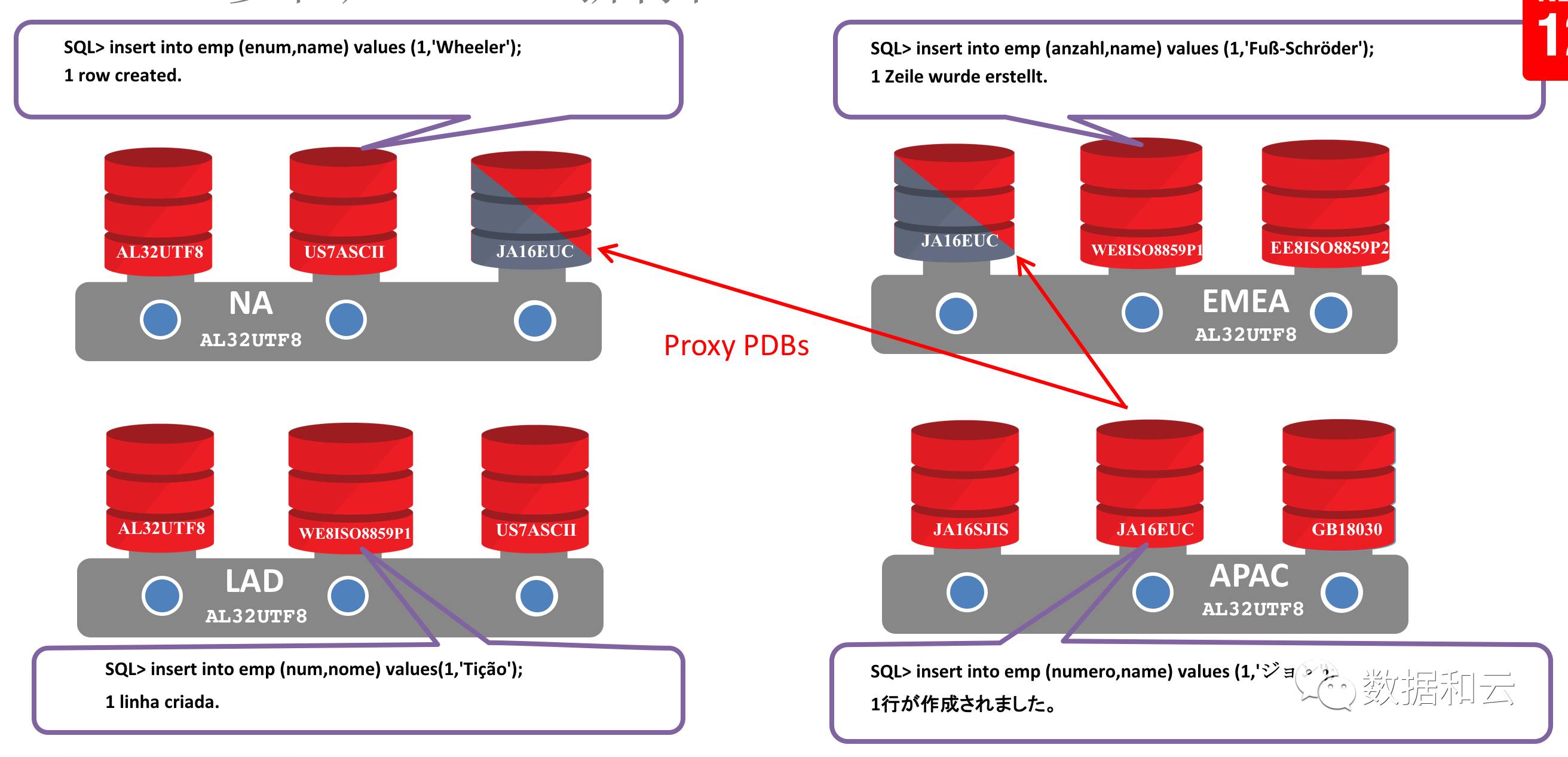
マルチテナントテクノロジはユーザーによって広く使用されており、Yunhe Enmo はデータサービス業界のリーダーとして、zData ソリューションと Oracle マルチテナントの組み合わせを通じてユーザーがインターネット時代のシステムのクラウド変革を実現できるよう支援してきました。テナント。
マルチテナントの新機能の詳細については、
を参照してください。
YH9:Oracle マルチテナントナレッジベース
マルチテナント技術はユーザーに広く使用されており、Yunhe Enmo はデータサービス業界のリーダーとして、zData ソリューションと Oracle マルチテナントの組み合わせを通じて、ユーザーがインターネット時代のシステムのクラウド変革を実現できるよう支援してきました。
WeChat パブリック アカウントの記事: データとクラウド
以上がOracle12.2 のアーキテクチャを理解する: ファイル システムとマルチテナントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを開始する手順は次のとおりです。Apache(コマンド:sudo apt-get install apache2または公式Webサイトからダウンロード)をインストールします(linux:linux:sudo systemctl start apache2; windows:apache2.4 "serviceを右クリックして「開始」を右クリック) (オプション、Linux:Sudo SystemCtl
 Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache80ポートが占有されている場合はどうすればよいですか
Apr 13, 2025 pm 01:24 PM
Apache 80ポートが占有されている場合、ソリューションは次のとおりです。ポートを占有するプロセスを見つけて閉じます。ファイアウォールの設定を確認して、Apacheがブロックされていないことを確認してください。上記の方法が機能しない場合は、Apacheを再構成して別のポートを使用してください。 Apacheサービスを再起動します。
 DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
DebianのNginx SSLパフォーマンスを監視する方法
Apr 12, 2025 pm 10:18 PM
この記事では、Debianシステム上のNginxサーバーのSSLパフォーマンスを効果的に監視する方法について説明します。 Nginxexporterを使用して、NginxステータスデータをPrometheusにエクスポートし、Grafanaを介して視覚的に表示します。ステップ1:NGINXの構成最初に、NGINX構成ファイルのSTUB_STATUSモジュールを有効にして、NGINXのステータス情報を取得する必要があります。 NGINX構成ファイルに次のスニペットを追加します(通常は/etc/nginx/nginx.confにあるか、そのインクルードファイルにあります):location/nginx_status {stub_status
 Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
Debianシステムでリサイクルビンをセットアップする方法
Apr 12, 2025 pm 10:51 PM
この記事では、デビアンシステムでリサイクルビンを構成する2つの方法を紹介します:グラフィカルインターフェイスとコマンドライン。方法1:Nautilusグラフィカルインターフェイスを使用して、ファイルマネージャーを開きます。デスクトップまたはアプリケーションメニューでNautilusファイルマネージャー(通常は「ファイル」と呼ばれる)を見つけて起動します。リサイクルビンを見つけてください:左ナビゲーションバーのリサイクルビンフォルダーを探してください。見つからない場合は、「他の場所」または「コンピューター」をクリックして検索してみてください。リサイクルビンプロパティの構成:「リサイクルビン」を右クリックし、「プロパティ」を選択します。プロパティウィンドウで、次の設定を調整できます。最大サイズ:リサイクルビンで使用可能なディスクスペースを制限します。保持時間:リサイクルビンでファイルが自動的に削除される前に保存を設定します
 ネットワーク監視におけるDebian Snifferの重要性
Apr 12, 2025 pm 11:03 PM
ネットワーク監視におけるDebian Snifferの重要性
Apr 12, 2025 pm 11:03 PM
検索結果は「DebiansNiffer」とネットワークモニタリングにおけるその特定のアプリケーションに直接言及するわけではありませんが、「Sniffer」はネットワークパケットキャプチャ分析ツールを指し、Debianシステムでのアプリケーションは他のLinux分布と本質的に違いはありません。ネットワークの監視は、ネットワークの安定性を維持し、パフォーマンスを最適化するために重要であり、パケットキャプチャ分析ツールが重要な役割を果たします。以下は、ネットワーク監視ツールの重要な役割(Debianシステムで実行されるSnifferなど)を説明しています。ネットワーク監視ツールの価値:高速障害場所:帯域幅の使用状況、遅延、パケット損失率など、ネットワーク障害の根本原因を迅速に特定し、トラブルシューティング時間を短縮できるようなネットワークメトリックのリアルタイム監視。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Apacheサーバーを再起動する方法
Apr 13, 2025 pm 01:12 PM
Apacheサーバーを再起動する方法
Apr 13, 2025 pm 01:12 PM
Apacheサーバーを再起動するには、次の手順に従ってください。Linux/MacOS:sudo systemctl restart apache2を実行します。 Windows:Net Stop apache2.4を実行し、ネット開始apache2.4を実行します。 Netstat -A |を実行しますサーバーのステータスを確認するには、STR 80を見つけます。
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
