
 テクノロジー周辺機器
AI
NTU Zhou Zhihua チームの 8 年間の傑作! 「ラーニングウェア」システムが機械学習の再利用の問題を解決し、「モデル融合」が科学研究の新たなパラダイムを出現させる
テクノロジー周辺機器
AI
NTU Zhou Zhihua チームの 8 年間の傑作! 「ラーニングウェア」システムが機械学習の再利用の問題を解決し、「モデル融合」が科学研究の新たなパラダイムを出現させる
NTU Zhou Zhihua チームの 8 年間の傑作! 「ラーニングウェア」システムが機械学習の再利用の問題を解決し、「モデル融合」が科学研究の新たなパラダイムを出現させる

HuggingFace は、300,000 の異なる機械学習モデルと 100,000 の利用可能なアプリケーションを備えた、最も人気のある機械学習オープン ソース コミュニティです。
HuggingFace 上の 300,000 のモデルを自由に組み合わせて、新しい学習タスクを一緒に完了できたらどうなるでしょうか?
実は、HuggingFace が登場した 2016 年に、南京大学の周志華教授が「Learnware」という概念を提案し、このような青写真を描きました。
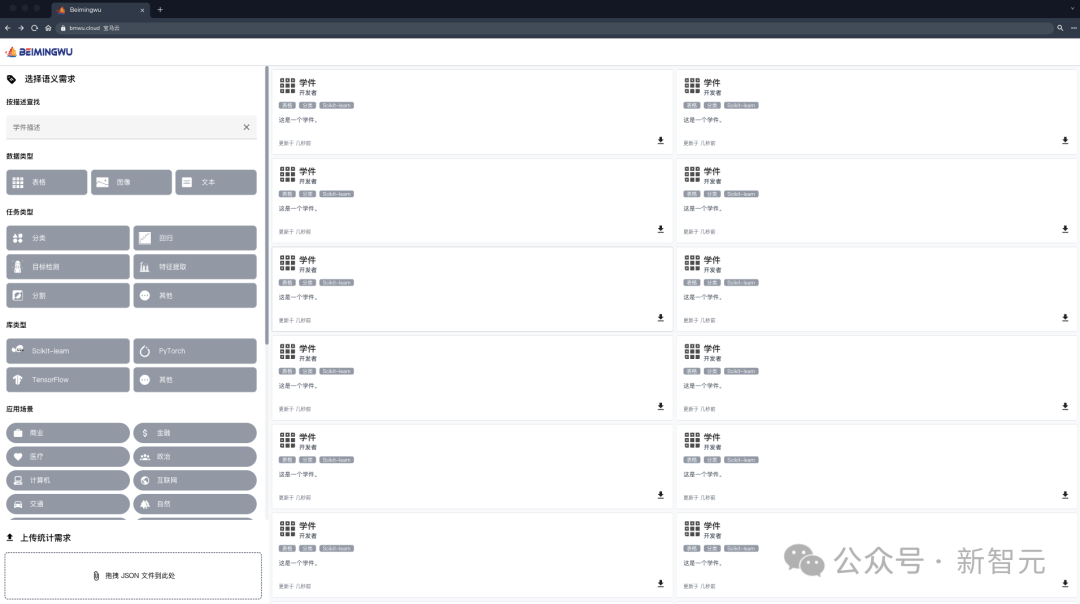
最近、南京大学の周志華教授のチームがそのようなプラットフォーム「Beimingwu」を立ち上げました。
アドレス: https://bmwu.cloud/
Beimingwu は、研究者やユーザーに独自のモデルをアップロードする機会を提供するだけでなく、ユーザーのニーズに応じてモデルマッチングや協調融合を実行し、学習タスクを効率的に処理することもできます。

紙のアドレス: https://arxiv.org/abs/2401.14427
北明武システム ウェアハウス: https://www.gitlink.org.cn/beimingwu/beimingwu
科学研究ツールキット ウェアハウス: https://www.gitlink.org.cn/beimingwu/learnware
このプラットフォームの最大の特徴は、Learnware システムの導入であり、ユーザーのニーズに基づいたモデルの適応マッチングとコラボレーション機能で画期的な進歩を実現しました。
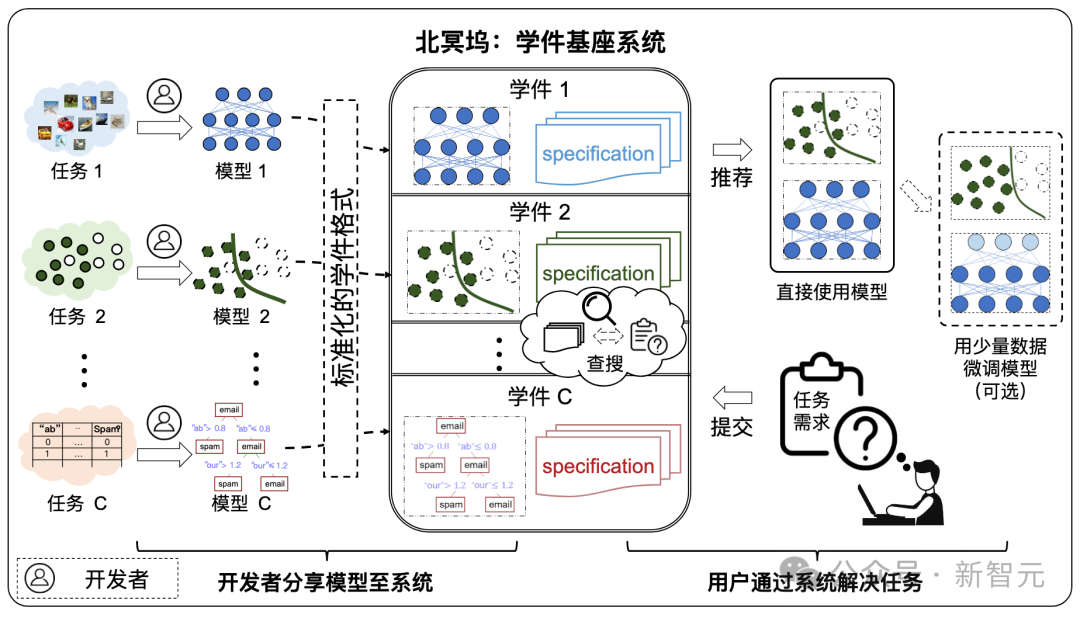
ラーニングウェアは、機械学習モデルとそれを記述する仕様、つまり「ラーニングウェア = モデル仕様」で構成されます。
学習ソフトウェアの仕様は、「セマンティック仕様」と「統計的仕様」の 2 つの部分で構成されます。
- セマンティック仕様は、テキストと関数を通じてモデルのタイプが説明されます。
- 統計ルールは、さまざまな機械学習テクノロジを使用して、モデルに含まれる統計情報を記述します。
学習ウェアの仕様には、ユーザーが事前に学習ウェアについて何も知らなくても、モデルを完全に認識して再利用できるようにモデルの機能が記述されており、ユーザーのニーズを満たすことができます。 . .
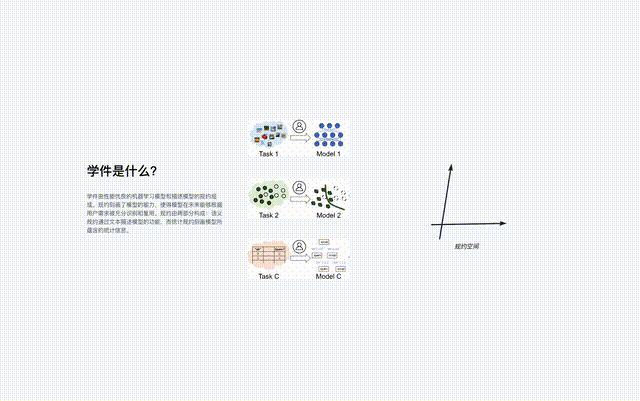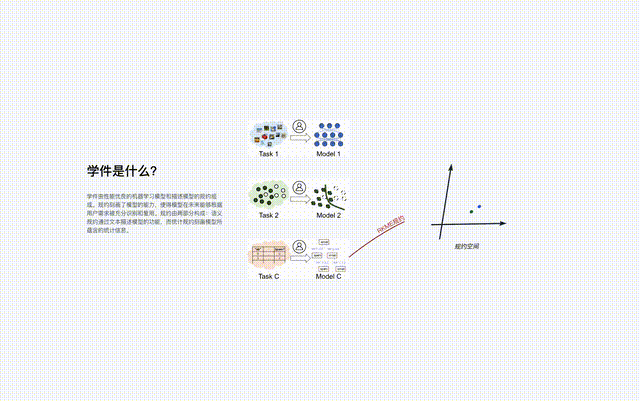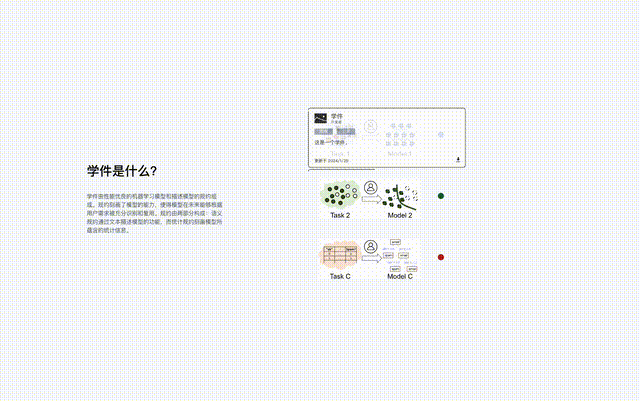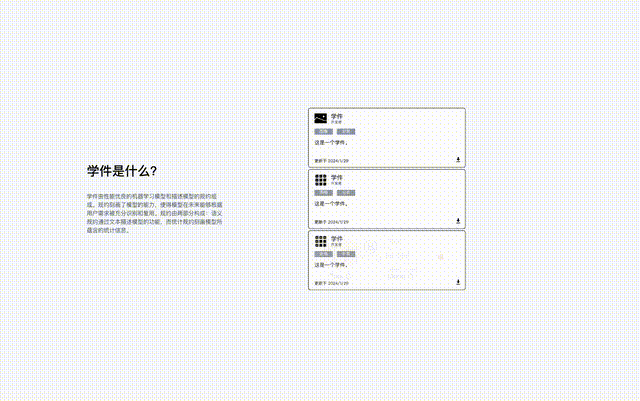
#プロトコルは、ラーニングウェア ベース システムのコア コンポーネントであり、ラーニングウェアのアップロード、編成、検索など、システム内のすべてのラーニングウェア プロセスを接続します。 、展開して再利用します。
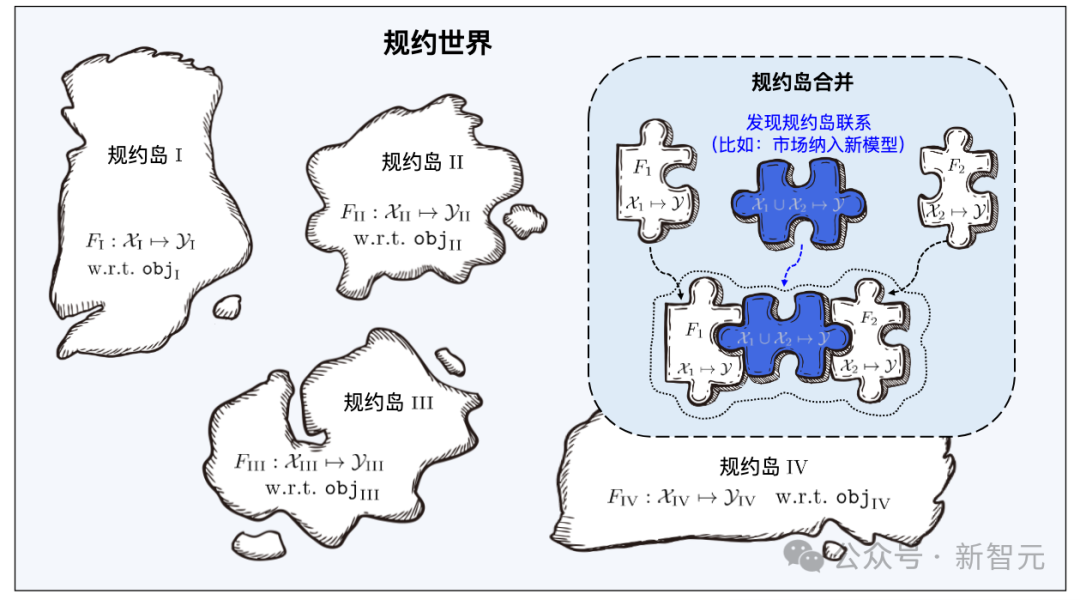
「ドラゴンバブ」の燕子烏がたくさんの小さな島で構成されているように、北明呉の条例も小さな島のようなものです。
ラーニングウェア パラダイムの下では、世界中の開発者がモデルをラーニングウェア ベース システムに共有できます。このシステムは、ユーザーがラーニングウェアを効果的に検索して再利用することで、機械学習タスクを効率的に解決するのに役立ちます。構築する必要はありません。機械学習モデルをゼロから作成します。
Beimingwu は、アカデミックウェアの初の体系的なオープンソース実装であり、アカデミックウェア関連の研究のための予備的な科学研究プラットフォームを提供します。
将来のユーザーは、ラーニング ウェアハウスに要件を送信でき、ラーニング ウェアハウスの支援を受けて、学習教材を検索して再利用して独自の機械学習タスクを完了できます。 Learning Warehouse に提出する必要はありません。ドックが独自のデータを漏洩しました。
そして将来、学習ドックに何百万もの学習ソフトウェアが存在するようになると、過去に特別に開発されたモデルがない機械学習タスクという「創発」動作が発生する可能性があります。いくつかの既存の学習ソフトウェアを再利用することで、「解決済み」を通じて解決できる可能性があります。
機械学習は多くの分野で大きな成功を収めていますが、大量のデータが必要になるなど、依然として多くの問題に直面しています。トレーニングデータと優れたトレーニング技術、継続的な学習の難しさ、壊滅的な忘れのリスク、データのプライバシー/所有権の漏洩など。 上記の問題にはそれぞれ対応する研究がありますが、問題は相互に結合しているため、1 つの問題を解決すると他の問題がより深刻になる可能性があります。 学習ベース システムは、全体的なフレームワークを通じて上記の問題の多くを同時に解決することを目指しています: 下図に示すように、システムのワークフローは次の 2 つの段階に分かれています。 さまざまな機能/マーカー スペースからの学習教材は多数のプロトコル アイランドを構成し、すべてのプロトコル アイランドが一緒になって学習コンポーネント ベース システムのプロトコル ワールドを構成します。プロトコルの世界では、異なるアイランド間の接続を発見して確立できれば、対応するプロトコル アイランドをマージできるようになります。
Learningware Paradigm は、コミュニティで共有される機械学習モデルの機能を最大限に活用して統一された仕様空間を構築し、新規ユーザーの機械学習タスクを統一された方法で効率的に解決します。学習ピースの数が増加するにつれて、学習ピース構造を効果的に編成することにより、タスクを解決する学習ピース基本システムの全体的な能力が大幅に向上します。 北明呉のアーキテクチャ
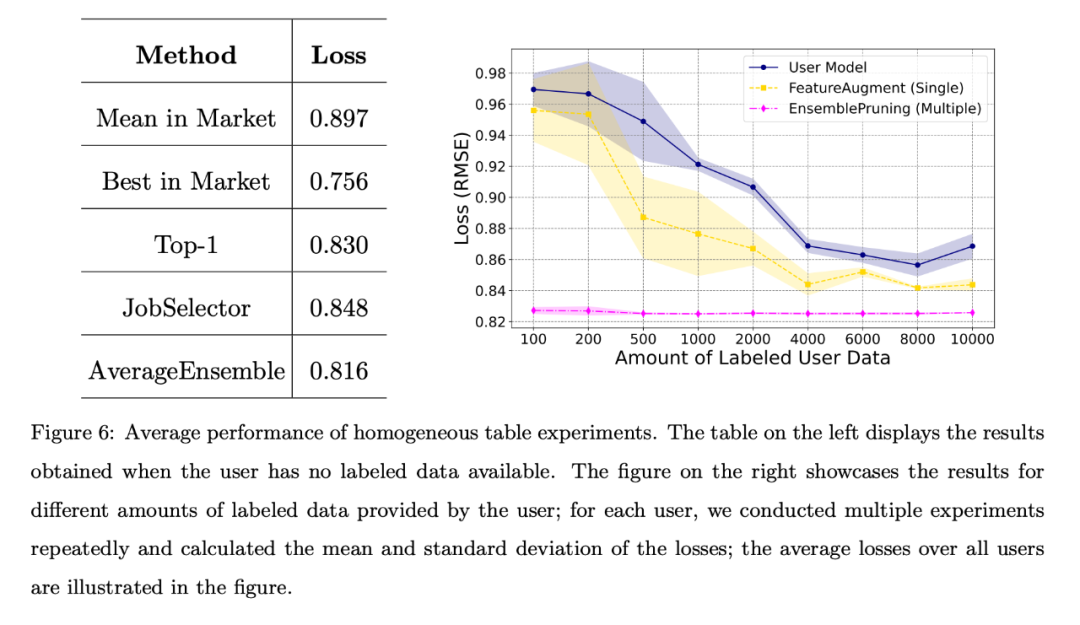
表形式データ実験 さらに、フォーム タスクは通常、異なる特徴空間から取得されるため、研究チームは、異なる特徴空間からの学習部分の認識と再利用も評価しました。
均一なケース 各ストアは独自のテスト データをユーザー タスク データとして利用し、統一された特徴エンジニアリング アプローチを採用しています。これらのユーザーは、タスクと同じ特徴空間を共有する同種の学習項目をベース システムで検索できます。 ユーザーがラベル付きデータを持たないか、ラベル付きデータの量が限られている場合、チームはさまざまなベンチマーク アルゴリズムを比較し、全ユーザーの平均損失を次の図に示します。左の表は、市場から学習ウェアをランダムに選択して導入するよりも、データフリーのアプローチの方がはるかに優れていることを示しています。右のグラフは、ユーザーのトレーニング データが限られている場合、単一または複数の学習ウェアを特定して再利用する方が、ユーザーがトレーニングしたものよりも優れていることを示しています。モデルのパフォーマンスが向上しました。
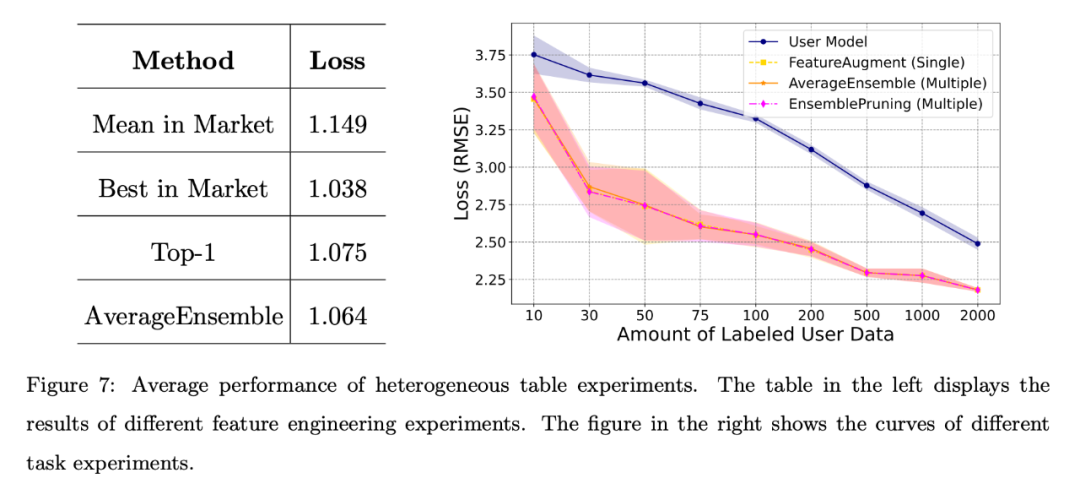
異種のケース さまざまな特徴量エンジニアリング シナリオ: 下図の左側に示されている結果は、ユーザーにアノテーション データがない場合でも、システム内の学習ソフトウェア 特に複数の学習ピースを再利用する AverageEnsemble メソッドで優れたパフォーマンスを発揮できます。
上の右の図は、ユーザーの自己トレーニング モデルといくつかのシナリオを示しています。学習ウェアの再利用方法の損失曲線。 ユーザーの注釈付きデータの量が限られている場合、異種の学習部分を実験的に検証することは明らかに有益であり、ユーザーの特徴空間との整合性を高めるのに役立ちます。
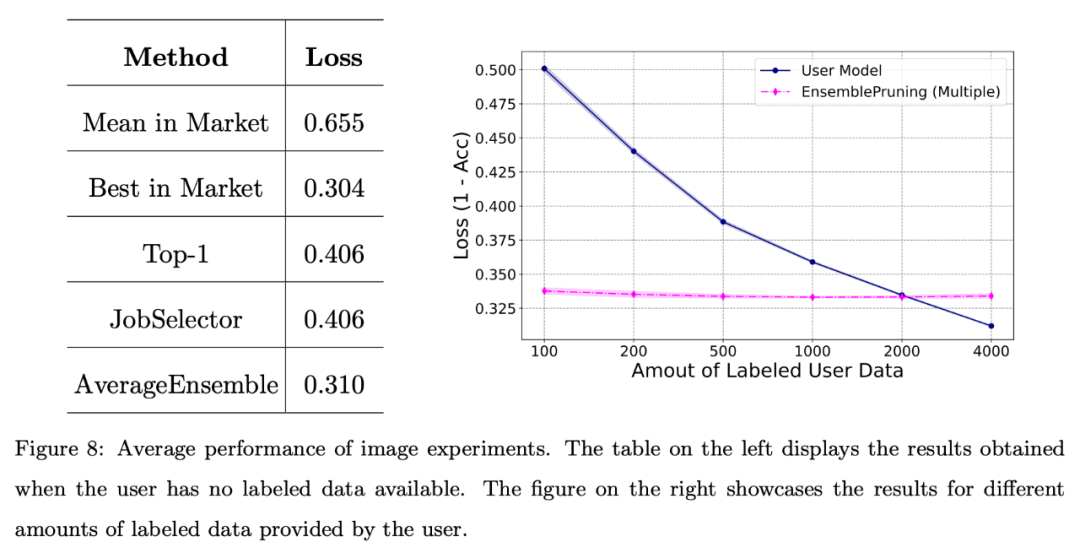
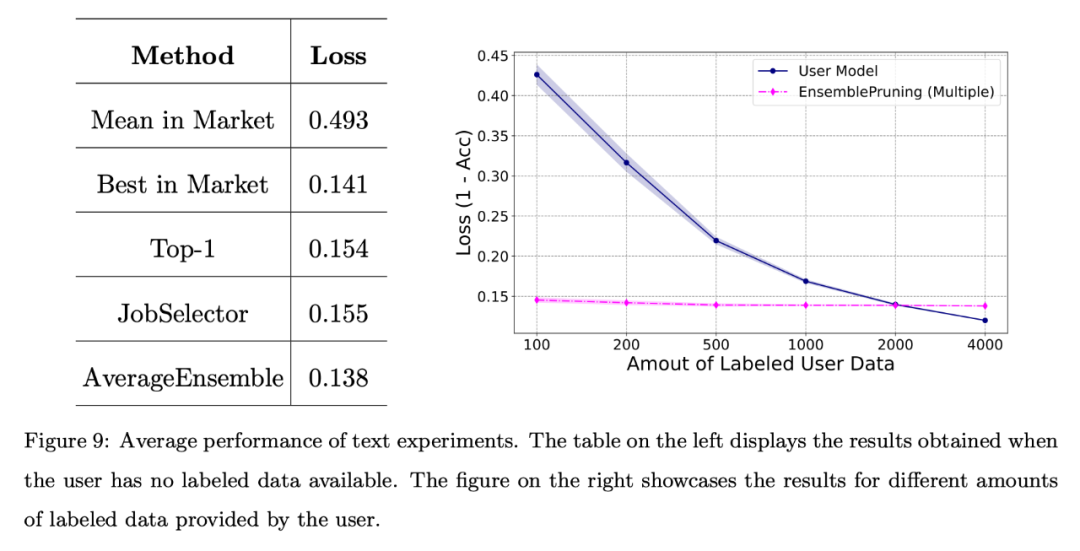
画像データとテキストデータの実験 下の図は、ユーザーが注釈付きデータの不足に直面している場合、または限られた量のデータしか持っていない場合 (インスタンスが 2000 未満) に、学習ベース システムを活用すると良好なパフォーマンスが得られることを示しています。
次の図に示すように、アノテーション データが提供されない場合でも、学習ウェアの識別と再利用によって得られるパフォーマンスは、システム内の最高の学習ウェアと同等です。 さらに、学習ベース システムを使用すると、モデルを最初からトレーニングする場合と比較して、約 2,000 個のサンプルを削減できます。 
ラーニングウェア ベース システム
#学習基盤システムの構成
 #プロトコルの世界
#プロトコルの世界
プロトコルは、学習ベース システムのコア コンポーネントであり、システムを接続します。シリーズ 学習ソフトウェアのアップロード、整理、検索、展開、再利用など、学習ソフトウェアの全プロセスについて。
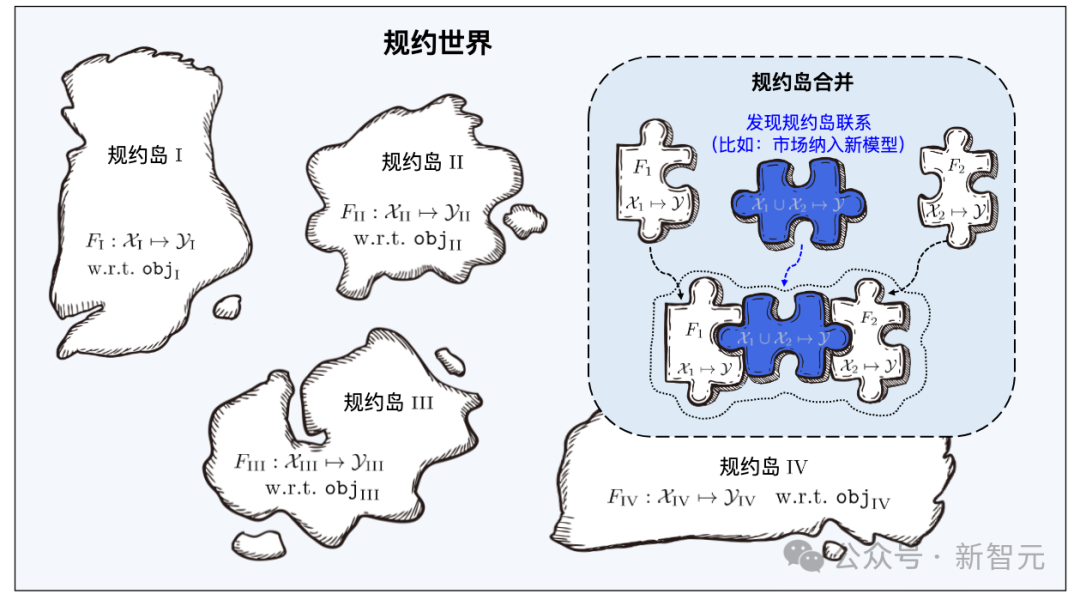 学習ベース システムが検索するとき、まずユーザー要件のセマンティック仕様を通じて特定のプロトコル アイランドを見つけてから、ユーザー要件を使用します。プロトコル内の統計プロトコルは、プロトコル アイランド上の学習アーティファクトを正確に識別します。異なるプロトコル アイランドのマージは、対応する学習ソフトウェアを異なる特徴/マーカー空間のタスクに使用できること、つまり、本来の目的を超えたタスクに再利用できることを意味します。
学習ベース システムが検索するとき、まずユーザー要件のセマンティック仕様を通じて特定のプロトコル アイランドを見つけてから、ユーザー要件を使用します。プロトコル内の統計プロトコルは、プロトコル アイランド上の学習アーティファクトを正確に識別します。異なるプロトコル アイランドのマージは、対応する学習ソフトウェアを異なる特徴/マーカー空間のタスクに使用できること、つまり、本来の目的を超えたタスクに再利用できることを意味します。
以下の図に示すように、北明呉のシステム アーキテクチャは学習ソフトウェアのストレージ層から 4 つのレベルで構成されています。ユーザーインタラクション層に関しては、ラーニングウェアのパラダイムが初めてボトムアップで体系的に実装されています。 4 つのレベルの具体的な機能は次のとおりです。
実験評価論文では、研究チームは表、画像、テキストデータを評価するためのさまざまな種類の基本的な実験シナリオも構築しました。仕様の生成、学習アーティファクトの識別および再利用のためのベンチマーク アルゴリズム。
以上がNTU Zhou Zhihua チームの 8 年間の傑作! 「ラーニングウェア」システムが機械学習の再利用の問題を解決し、「モデル融合」が科学研究の新たなパラダイムを出現させるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7781
7781
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
不安定な暗号通貨市場では、投資家は人気のある通貨を超えた代替品を探しています。 Solana(Sol)、Cardano(ADA)、XRP、Dogecoin(DOGE)などのよく知られた暗号通貨も、市場の感情、規制の不確実性、スケーラビリティなどの課題に直面しています。ただし、新しい新興プロジェクトであるRexasFinance(RXS)が出現しています。それは有名人の効果や誇大広告に依存するのではなく、現実世界の資産(RWA)とブロックチェーン技術を組み合わせて投資家に革新的な投資方法を提供することに焦点を当てています。この戦略により、2025年の最も成功したプロジェクトの1つになることを望んでいます。Rexasfi
