

昨年 4 月、ウィスコンシン大学マディソン校、マイクロソフト リサーチ、コロンビア大学の研究者が共同で LLaVA (Large Language and Vision Assistant) をリリースしました。 LLaVA は小規模なマルチモーダル命令データセットでのみトレーニングされていますが、一部のサンプルでは GPT-4 と非常によく似た推論結果を示します。その後 10 月に、オリジナルの LLaVA に簡単な変更を加えて 11 のベンチマークの SOTA を更新した LLaVA-1.5 をリリースしました。このアップグレードの結果は非常に刺激的で、マルチモーダル AI アシスタントの分野に新たなブレークスルーをもたらします。
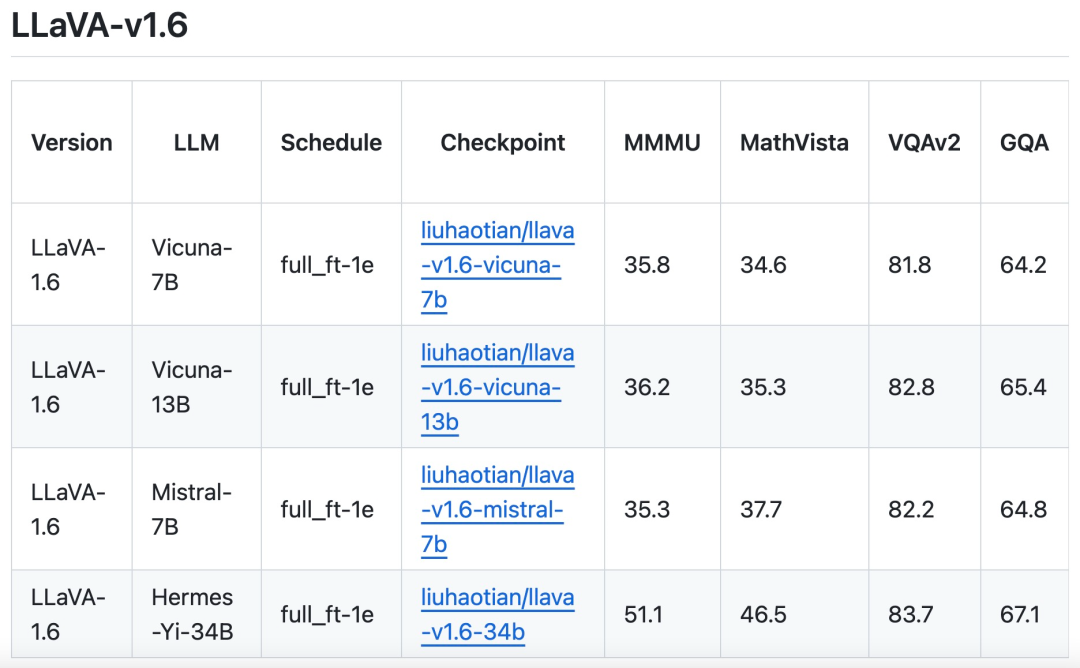
研究チームは、推論、OCR、世界知識のパフォーマンスが大幅に向上した LLaVA-1.6 バージョンのリリースを発表しました。このバージョンの LLaVA-1.6 は、複数のベンチマークで Gemini Pro よりも優れています。
 出典: https://twitter.com/imhaotian/status/1752621754273472927
出典: https://twitter.com/imhaotian/status/1752621754273472927
#LLaVA-1.6 は、LLaVA-1.5 に基づいて微調整および最適化されています。 LLaVA-1.5 のシンプルな設計と効率的なデータ処理機能を維持し、100 万未満のビジュアル命令チューニング サンプルを引き続き使用します。 32 枚の A100 グラフィックス カードを使用することで、最大の 34B モデルが約 1 日でトレーニングされました。さらに、LLaVA-1.6 は 130 万のデータ サンプルを利用し、その計算/学習データのコストは他の手法の 100 ~ 1000 倍にすぎません。これらの改善により、LLaVA-1.6 はより効率的でコスト効率の高いバージョンになっています。
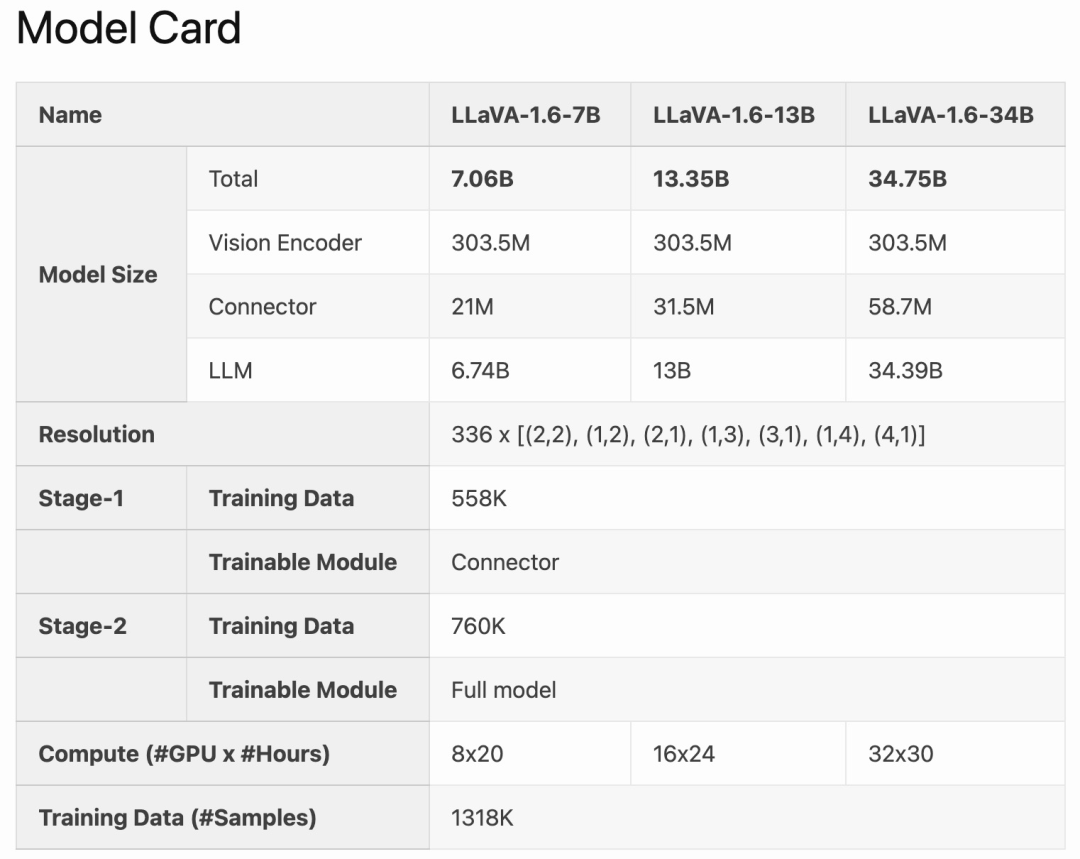 LLaVA-1.6 は、CogVLM や Yi-VL などのオープンソース LMM と比較して、SOTA パフォーマンスを実現します。商用製品と比較すると、LLaVA-1.6 は、特定のベンチマークにおいて Gemini Pro に匹敵し、Qwen-VL-Plus よりも優れています。
LLaVA-1.6 は、CogVLM や Yi-VL などのオープンソース LMM と比較して、SOTA パフォーマンスを実現します。商用製品と比較すると、LLaVA-1.6 は、特定のベンチマークにおいて Gemini Pro に匹敵し、Qwen-VL-Plus よりも優れています。
 LLaVA-1.6 が強力なゼロショット中国語機能を実証していることは言及する価値があります。 -モーダルベンチマークMMBench-CN。
LLaVA-1.6 が強力なゼロショット中国語機能を実証していることは言及する価値があります。 -モーダルベンチマークMMBench-CN。
メソッドの改善
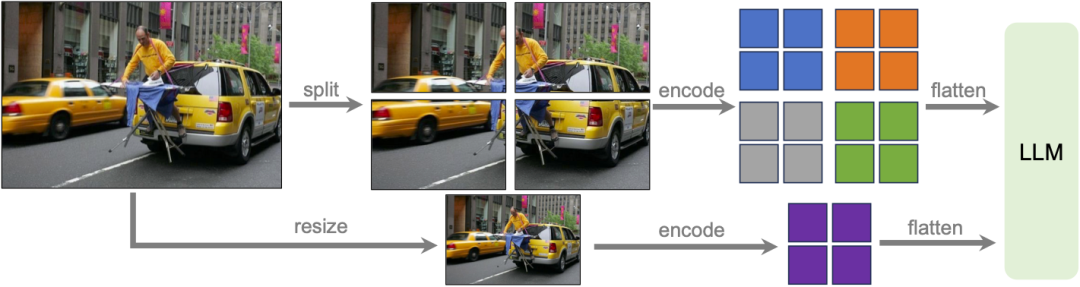
研究チームLLaVA-1.6 モデルは、データ効率を維持するために高解像度で設計されました。高解像度の画像と詳細を保持した表現が提供されると、画像内の複雑な詳細を認識するモデルの能力が大幅に向上します。これにより、低解像度の画像に直面したときのモデルの幻覚、つまり想像された視覚的内容の推測が軽減されます。
 #データミキシング
#データミキシング
高品質のユーザーコマンドデータ。
データに従う高品質の視覚的指示の研究の定義は、2 つの主な基準に基づいています。1 つは、タスク指示の多様性であり、現実生活で遭遇する可能性のある幅広いユーザーの意図を確実に反映することです。シナリオは適切に表現されています。特にモデル展開フェーズ中です。次に、ユーザーからの好意的なフィードバックを求めるために、応答の優先順位付けが重要です。 したがって、この研究では 2 つのデータ ソースを検討しました。
既存の GPT-V データ (LAION-GPT-V および ShareGPT -4V)。
より多くのシナリオでより優れた視覚的対話をさらに促進するために、研究チームはさまざまなアプリケーションをカバーする小規模な 15,000 個の視覚的命令調整データ セットを収集し、プライバシー上の問題がある可能性や有害な可能性があるサンプルを慎重にフィルタリングし、GPT を使用しました。 -4V で応答を生成します。
マルチモーダルなドキュメント/グラフ データ。 (1) TextCap が TextVQA と同じトレーニング画像セットを使用していることに研究チームが気付いたため、トレーニング データから TextCap を削除します。これにより、研究チームは TextVQA を評価する際に、モデルのゼロショット OCR 機能をより深く理解できるようになりました。モデルの OCR 機能を維持し、さらに向上させるために、この研究では TextCap を DocVQA および SynDog-EN に置き換えました。 (2) Qwen-VL-7B-Chat では、この研究では、プロットとチャートをよりよく理解するために、ChartQA、DVQA、および AI2D がさらに追加されています。
研究チームは、Vicuna-1.5 (7B および 13B) に加えて、Mistral-7B や Nous-Hermes-2 など、より多くの LLM ソリューションの使用も検討していると述べました。 Yi-34B、LLaVA がより広範囲のユーザーとより多くのシナリオをサポートできるようにします。
以上がGemini Pro に追いつき、推論機能と OCR 機能を向上させた LLaVA-1.6 は強力すぎますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



