

NVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLM

1. TensorRT-LLM の製品の位置付け
TensorRT-LLM は、大規模言語モデル (LLM) 向けに NVIDIA によって開発されたスケーラブルな推論ソリューションです。 TensorRT 深層学習コンパイル フレームワークに基づいて計算グラフを構築、コンパイル、実行し、FastTransformer の効率的なカーネル実装を利用します。さらに、デバイス間の通信には NCCL を利用します。開発者は、カットラスに基づいてカスタマイズされた GEMM を開発するなど、技術開発や需要の違いに基づいて特定のニーズを満たすためにオペレーターをカスタマイズできます。 TensorRT-LLM は、NVIDIA の公式推論ソリューションであり、高いパフォーマンスを提供し、実用性を継続的に向上させることに尽力しています。

TensorRT-LLM は GitHub 上のオープンソースであり、Release ブランチと Dev ブランチの 2 つのブランチに分かれています。 Release ブランチは月に 1 回更新されますが、Dev ブランチは公式ソースまたはコミュニティ ソースからの機能をより頻繁に更新して、開発者が最新の機能を体験して評価できるようにします。以下の図は TensorRT-LLM のフレームワーク構造を示しており、緑色の TensorRT コンパイル部分とハードウェア情報に関わるカーネルを除き、その他の部分はオープンソースです。

TensorRT-LLM は、開発者の学習コストを削減するために Pytorch に似た API も提供し、ユーザーが使用できる事前定義されたモデルを多数提供します。

大規模な言語モデルはサイズが大きいため、推論は 1 つのグラフィック カードでは完了できない可能性があるため、TensorRT-LLM は 2 つの並列メカニズムを提供します。 : マルチカードまたはマルチマシン推論をサポートするテンソル並列処理とパイプライン並列処理。これらのメカニズムにより、モデルを複数の部分に分割し、複数のグラフィックス カードまたはマシンに分散して並列計算を行うことができ、推論パフォーマンスが向上します。 Tensor Parallelism は、モデル パラメーターをさまざまなデバイスに分散し、さまざまな部分の出力を同時に計算することで並列コンピューティングを実現します。パイプライン並列処理では、モデルを複数のステージに分割し、各ステージが異なるデバイス上で並列計算され、出力が次のステージに渡されることで、全体的な

#2. TensorRT-LLM の重要な機能
TensorRT-LLM は強力なツールです。豊富なモデルサポートと低精度の推論機能を備えています。 まず、TensorRT-LLM は、Qwen (Qianwen) などの開発者によって完成されたモデル適応を含む、主流の大規模言語モデルをサポートしており、公式サポートに含まれています。これは、ユーザーがこれらの事前定義モデルを簡単に拡張またはカスタマイズし、独自のプロジェクトに迅速かつ簡単に適用できることを意味します。 次に、TensorRT-LLM はデフォルトで FP16/BF16 精度推論メソッドを使用します。この低精度の推論では、推論のパフォーマンスが向上するだけでなく、業界の量子化手法を使用してハードウェアのスループットをさらに最適化することもできます。 TensorRT-LLM はモデルの精度を下げることで、精度をあまり犠牲にすることなく推論の速度と効率を大幅に向上させることができます。 要約すると、TensorRT-LLM の豊富なモデル サポートと低精度の推論機能により、TensorRT-LLM は非常に実用的なツールになります。開発者にとっても研究者にとっても、TensorRT-LLM は効率的な推論ソリューションを提供し、深層学習アプリケーションでより優れたパフォーマンスを達成できるように支援します。

もう 1 つの機能は、FMHA (融合マルチヘッド アテンション) カーネルの実装です。 Transformer で最も時間のかかる部分はセルフ アテンションの計算であるため、公式はセルフ アテンションの計算を最適化するように FMHA を設計し、fp16 と fp32 のアキュムレータを備えた異なるバージョンを提供しました。また、速度の向上に加えて、メモリ使用量も大幅に削減されます。また、シーケンス長を任意の長さに拡張できるフラッシュ アテンション ベースの実装も提供します。

以下は FMHA の詳細情報です。MQA はマルチ クエリ アテンション、GQA はグループ クエリ アテンションです。
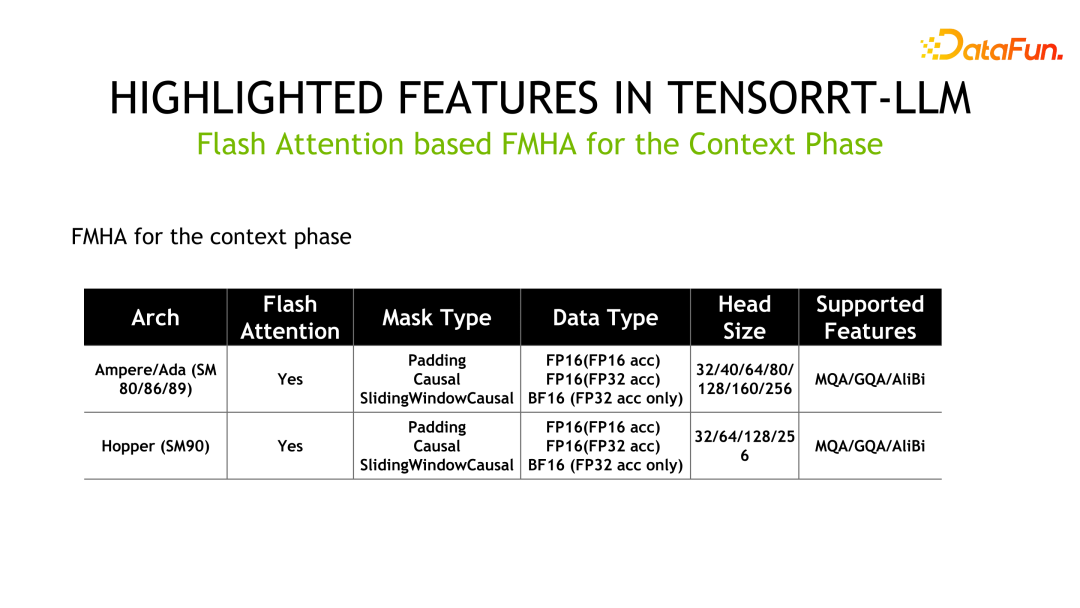
もう 1 つのカーネルは MMHA (Masked Multi-Head Attendance) です。 FMHA は主にコンテキスト フェーズでの計算に使用され、MMHA は主に生成フェーズでの注意の高速化を提供し、Volta 以降のアーキテクチャのサポートを提供します。 FastTransformer の実装と比較して、TensorRT-LLM はさらに最適化され、パフォーマンスが最大 2 倍向上します。

#もう 1 つの重要な機能は、精度は低くても推論の高速化を実現する量子化テクノロジです。一般的に使用される量子化手法は主に PTQ (Post Training Quantization) と QAT (Quantization-aware Training) に分けられますが、TensorRT-LLM ではこれら 2 つの量子化手法の推論ロジックは同じです。 LLM 定量化テクノロジの重要な特徴は、アルゴリズム設計とエンジニアリング実装の共同設計です。つまり、対応する定量化手法の設計の開始時にハードウェアの特性を考慮する必要があります。そうしないと、期待される推論速度の向上が達成されない可能性があります。

TensorRT の PTQ 定量化ステップは、一般的に次のステップに分かれています。最初にモデルを定量化し、次に重みとモデルを TensorRT に変換します。 -LLM.エクスプレス。一部のカスタマイズされた操作については、ユーザーが独自のカーネルを作成する必要もあります。一般的に使用される PTQ 定量化手法には、代表的な共同設計手法である INT8 重みのみ、SmoothQuant、GPTQ、および AWQ が含まれます。

#INT8 ウェイトのみはウェイトを INT8 に直接量子化しますが、アクティベーション値は FP16 のままです。この方法の利点は、モデルのストレージが 2 分の 1 に削減され、重みをロードするためのストレージ帯域幅が半分になり、推論パフォーマンスを向上させるという目的が達成されることです。このメソッドは業界では W8A16 と呼ばれています。つまり、重みは INT8、アクティベーション値は FP16/BF16 で、INT8 精度で保存され、FP16/BF16 形式で計算されます。この方法は直感的で、重みを変更せず、実装が簡単で、汎化パフォーマンスが優れています。

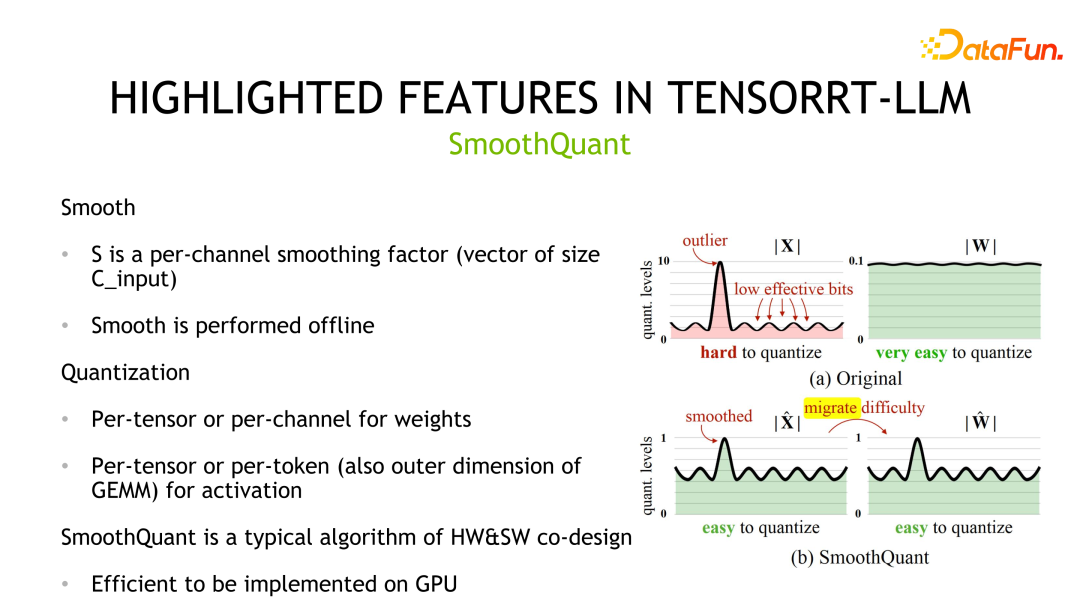
2 番目の定量化手法は、NVIDIA とコミュニティによって共同設計された SmoothQuant です。重みは通常ガウス分布に従い、量子化が容易ですが、活性化値には外れ値があり、量子化ビットの使用率は高くないことが観察されます。

SmoothQuant は、最初にアクティベーション値を平滑化する、つまりスケールで割ることによって、対応する分布を圧縮します。等価性を確保するには、重みに同じスケールを乗算する必要があります。その後、重みとアクティベーションの両方を定量化できます。対応するストレージおよび計算精度は INT8 または FP8 で、計算には INT8 または FP8 TensorCore を使用できます。実装の詳細に関しては、重みはテンソルごとおよびチャネルごとの量子化をサポートし、アクティベーション値はテンソルごとおよびトークンごとの量子化をサポートします。
 #4 番目の量子化方法は AWQ です。この方法では、すべての重みが同じように重要であるわけではなく、重みの 0.1% ~ 1% のみ (顕著な重み) がモデルの精度に大きく寄与し、これらの重みは重みの分布ではなく活性化値の分布に依存することを考慮します。このメソッドの定量化プロセスは SmoothQuant と似ていますが、主な違いは、スケールが活性化値の分布に基づいて計算されることです。
#4 番目の量子化方法は AWQ です。この方法では、すべての重みが同じように重要であるわけではなく、重みの 0.1% ~ 1% のみ (顕著な重み) がモデルの精度に大きく寄与し、これらの重みは重みの分布ではなく活性化値の分布に依存することを考慮します。このメソッドの定量化プロセスは SmoothQuant と似ていますが、主な違いは、スケールが活性化値の分布に基づいて計算されることです。


量子化に加えて、TensorRT-LLM のパフォーマンスを向上させるもう 1 つの方法は、マルチマシンとマルチカード推論を使用することです。シナリオによっては、大規模なモデルが大きすぎて推論用に 1 つの GPU に配置できないか、モデルを停止することはできますが、コンピューティング効率に影響があり、推論に複数のカードまたは複数のマシンが必要になります。

TensorRT-LLM は現在、Tensor Parallelism と Pipeline Parallelism という 2 つの並列戦略を提供しています。 TP は、モデルを垂直に分割し、各パーツを異なるデバイスに配置します。これにより、デバイス間の頻繁なデータ通信が導入され、NVLINK など、デバイス間の相互接続が高度なシナリオで一般的に使用されます。もう 1 つのセグメンテーション方法は水平セグメンテーションです。このとき、水平フロントは 1 つだけあり、対応する通信方法はポイントツーポイント通信であり、デバイスの通信帯域幅が弱いシナリオに適しています。

注目すべき最後の機能は、実行中のバッチ処理です。バッチ処理は推論パフォーマンスを向上させるための一般的な手法ですが、LLM 推論シナリオでは、バッチ内の各サンプル/リクエストの出力長は予測できません。静的バッチ処理方法に従う場合、バッチの遅延はサンプル/リクエスト内の最長の出力に依存します。したがって、短い方のサンプル/リクエストの出力は終了しましたが、コンピューティング リソースは解放されておらず、その遅延は最も長い出力サンプル/リクエストの遅延と同じになります。インフライトバッチ処理の方法は、サンプル/リクエストの最後に新しいサンプル/リクエストを挿入することです。このようにして、単一のサンプル/リクエストの遅延を削減し、リソースの無駄を回避するだけでなく、システム全体のスループットも向上します。

#3. TensorRT-LLM の使用プロセス
TensorRT-LLM は TensorRT に似ています。まず、事前トレーニング済みモデルを取得し、次に TensorRT-LLM が提供する API を使用してモデル計算グラフを書き換えて再構築し、TensorRT を使用します。最適化して、推論展開用のシリアル化エンジンとして保存します。

Llama を例に挙げると、まず TensorRT-LLM をインストールし、次に事前トレーニングされたモデルをダウンロードし、次に TensorRT-LLM を使用してモデルをコンパイルします。 、そして最後に推理。

モデル推論のデバッグについては、TensorRT-LLM のデバッグ方法は TensorRT と一致しています。深層学習コンパイラー、つまり TensorRT のおかげで提供される最適化の 1 つは、レイヤー融合です。したがって、特定の層の結果を出力したい場合は、コンパイラによって最適化されないように、対応する層を出力層としてマークし、ベースラインと比較して分析する必要があります。同時に、新しい出力層がマークされるたびに、TensorRT エンジンを再コンパイルする必要があります。

カスタム層の場合、TensorRT-LLM は、ユーザーがカーネルを自分で作成することなく関数を実装できるように、多くの Pytorch のような演算子を提供します。例に示すように、TensorRT-LLM が提供する API を使用して rms ノルムのロジックを実装し、TensorRT が対応する実行コードを GPU 上で自動的に生成します。

ユーザーがより高いパフォーマンス要件を持っている場合、または TensorRT-LLM が対応する関数を実装するためのビルディング ブロックを提供していない場合、ユーザーはカーネルをカスタマイズする必要があります現時点では、TensorRT-LLM で使用するプラグインとしてパッケージ化されています。サンプルコードは、SmoothQuant のカスタマイズされた GEMM を実装し、TensorRT-LLM が呼び出すためのプラグインにカプセル化するサンプル コードです。

4. TensorRT-LLM の推論パフォーマンス
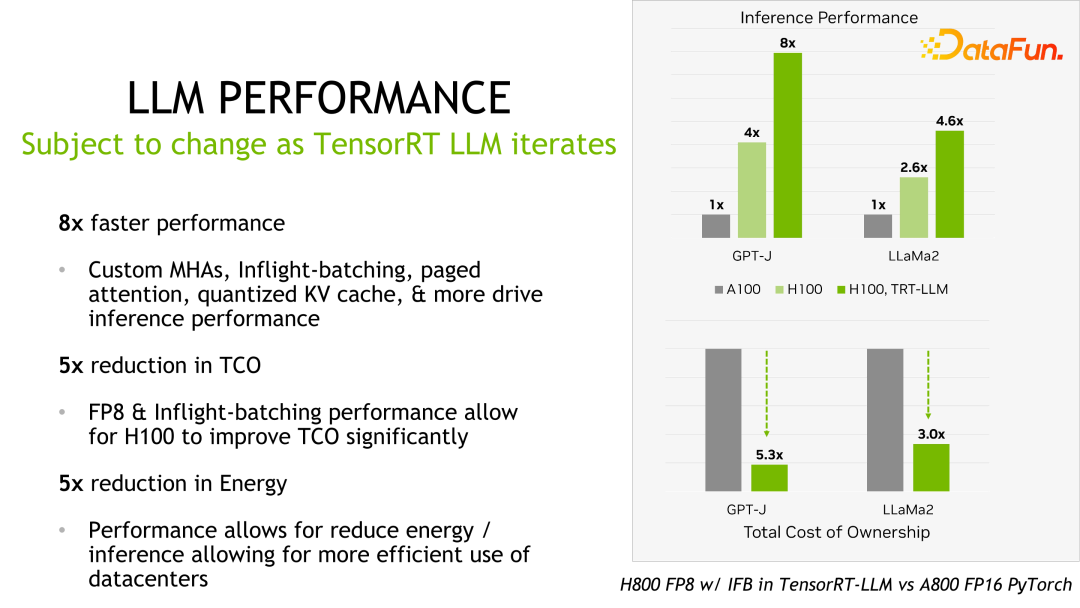
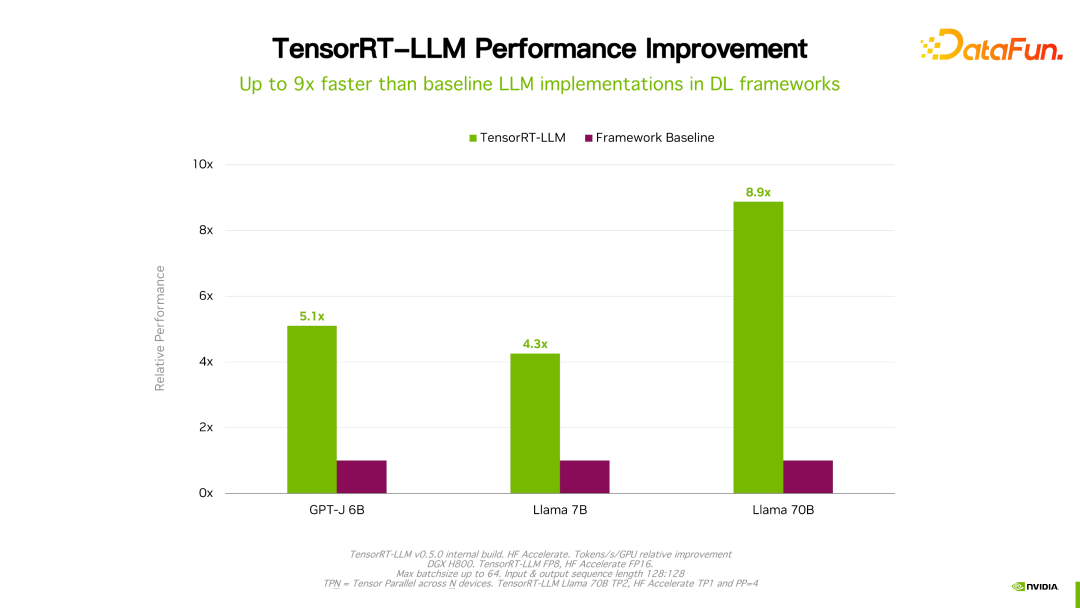
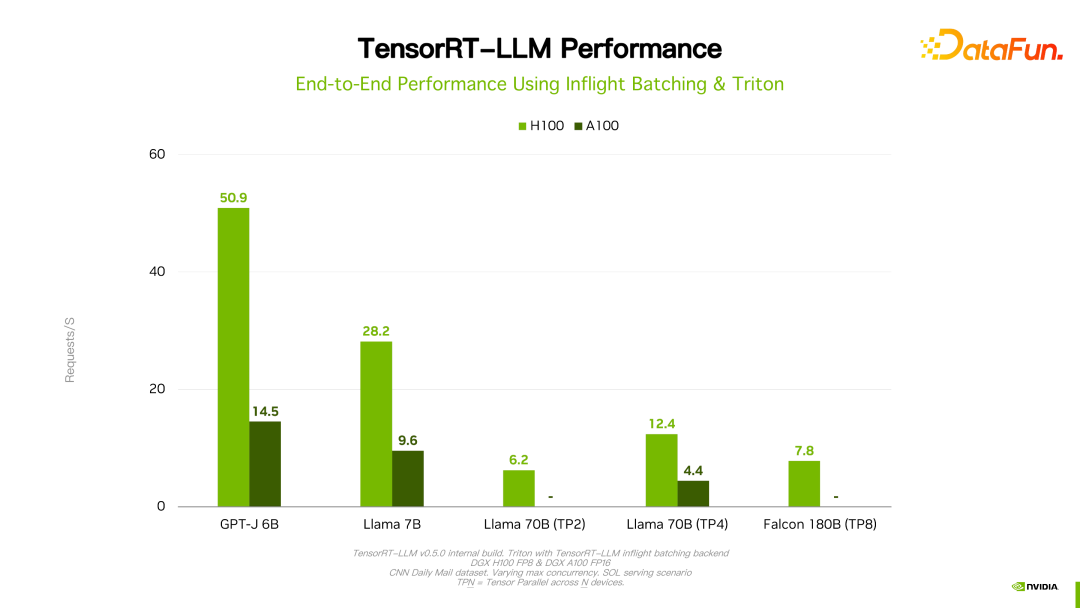
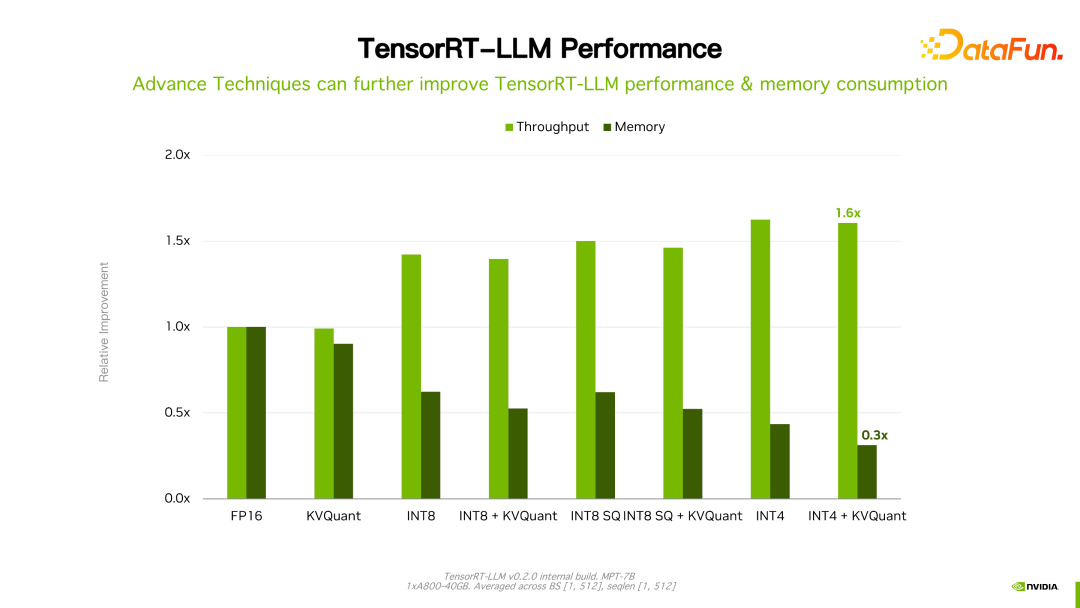
#価値があるものTensorRT-LLM のパフォーマンスは、以前のバージョンと比較して向上し続けていると述べました。上の図に示すように、FP16 に基づいて、KVQuant を使用すると、同じ速度を維持しながらビデオ メモリの使用量が削減されます。 INT8 を使用すると、スループットが大幅に向上すると同時に、メモリ使用量がさらに削減されます。 TensorRT-LLM 最適化テクノロジの継続的な進化により、パフォーマンスが向上し続けることがわかります。この傾向は今後も続くでしょう。
5. TensorRT-LLM の今後の展望
 LLM は、推論に非常にコストがかかり、コストに敏感なシナリオです。次の 100 倍の加速効果を達成するには、アルゴリズムとハードウェアの共同反復が必要であり、この目標はソフトウェアとハードウェアの共同設計によって達成できると考えています。ハードウェアは低精度の量子化を提供しますが、ソフトウェアの観点では最適化された量子化やネットワーク プルーニングなどのアルゴリズムを使用してパフォーマンスをさらに向上させます。
LLM は、推論に非常にコストがかかり、コストに敏感なシナリオです。次の 100 倍の加速効果を達成するには、アルゴリズムとハードウェアの共同反復が必要であり、この目標はソフトウェアとハードウェアの共同設計によって達成できると考えています。ハードウェアは低精度の量子化を提供しますが、ソフトウェアの観点では最適化された量子化やネットワーク プルーニングなどのアルゴリズムを使用してパフォーマンスをさらに向上させます。
 TensorRT-LLM、NVIDIA は今後も TensorRT-LLM のパフォーマンスの向上に取り組んでいきます。同時に、オープンソースを通じてフィードバックや意見を収集し、使いやすさを向上させます。さらに、使いやすさに重点を置き、モデルゾーンや定量ツールなど、より多くのアプリケーションツールを開発してオープンソース化し、主流のフレームワークとの互換性を向上させ、トレーニングから推論、展開までのエンドツーエンドのソリューションを提供します。
TensorRT-LLM、NVIDIA は今後も TensorRT-LLM のパフォーマンスの向上に取り組んでいきます。同時に、オープンソースを通じてフィードバックや意見を収集し、使いやすさを向上させます。さらに、使いやすさに重点を置き、モデルゾーンや定量ツールなど、より多くのアプリケーションツールを開発してオープンソース化し、主流のフレームワークとの互換性を向上させ、トレーニングから推論、展開までのエンドツーエンドのソリューションを提供します。
# 6. 質疑応答
Q1: すべての計算出力を逆量子化する必要がありますか?量子化中に精度オーバーフローが発生した場合はどうすればよいですか?
A1: 現在 TensorRT-LLM は 2 種類の方式、すなわち FP8 と先ほど述べた INT4/INT8 量子化方式を提供しています。低精度 INT8 が GEMM として使用される場合、アキュムレータはオーバーフローを防ぐために fp16、さらには fp32 などの高精度データ型を使用します。逆量子化に関しては、fp8 量子化を例に挙げますが、TensorRT-LLM が計算グラフを最適化するとき、最適化の目的を達成するために逆量子化ノードを自動的に移動し、他の演算にマージすることがあります。しかし、先ほど紹介したGPTQやQATは現状ではハードコーディングによってカーネルに記述されており、量子化ノードや逆量子化ノードの統一された処理がありません。
Q2: 現在、特定のモデル専用に逆量子化を行っていますか?
A2: 現在の定量化は実際に次のようになり、さまざまなモデルをサポートします。よりクリーンな API を作成したり、設定項目を通じてモデルの定量化を均一にサポートしたりする計画があります。
Q3: ベスト プラクティスとして、TensorRT-LLM は直接使用する必要がありますか、それとも Triton Inference Server と組み合わせて使用する必要がありますか?一緒に使用すると不足する機能はありますか?
###A3: 一部の機能はオープンソースではないため、自社サービスの場合は適応作業が必要ですが、triton であれば完全なソリューションになります。 ######Q4: 量子化キャリブレーションにはいくつかの量子化方法がありますが、加速比は何ですか?これらの定量化スキームの効果は何ポイントですか? In-flight 分岐の各例の出力長は不明です。動的バッチ処理を行うにはどうすればよいですか?
A4: 定量化のパフォーマンスについては非公開で話していいです。効果に関しては、実装されたカーネルが正常であることを確認するための基本的な検証のみを行いました。すべての定量化アルゴリズムが動作することを保証することはできません。そのため、定量化に使用するデータセットやその影響など、制御できない要素が依然として存在します。インフライトバッチ処理に関しては、実行時に特定のサンプル/リクエストの出力が終了したかどうかを検出して判断することを指します。そうである場合、他の到着リクエストを挿入すると、TensorRT-LLM は予測出力の長さを予測しませんし、予測できません。
Q5: In-flight ブランチの C インターフェイスと Python インターフェイスは一致しますか? TensorRT-LLM の導入コストは高いのですが、今後改善する予定はありますか? TensorRT-LLM は VLLM とは異なる開発観点を持つのでしょうか?
A5: C ランタイムと Python ランタイムの間に一貫したインターフェイスを提供できるよう最善を尽くしますが、これはすでに計画中です。これまではパフォーマンスの向上と機能の改善に注力してきましたが、今後も使いやすさの向上を継続していきます。ここで vllm と直接比較するのは簡単ではありませんが、NVIDIA は業界に最高の LLM 推論ソリューションを提供するために、TensorRT-LLM 開発、コミュニティ、顧客サポートへの投資を継続して増やしていきます。
以上がNVIDIA の大規模モデル推論フレームワークを明らかにする: TensorRT-LLMの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 2009 年から 2025 年の誕生以来のビットコインの価格 BTC 過去の価格の最も完全な概要
Jan 15, 2025 pm 08:11 PM
2009 年から 2025 年の誕生以来のビットコインの価格 BTC 過去の価格の最も完全な概要
Jan 15, 2025 pm 08:11 PM
2009 年の誕生以来、ビットコインは暗号通貨の世界のリーダーとなり、その価格は大きな変動を経験しました。包括的な歴史的概要を提供するために、この記事では 2009 年から 2025 年までのビットコイン価格データをまとめ、主要な市場イベント、市場センチメントの変化、価格変動に影響を与える重要な要因を取り上げます。
 ビットコインの誕生以来の歴史的な価格の概要。ビットコインの歴史的な価格動向を完全にまとめています。
Jan 15, 2025 pm 08:14 PM
ビットコインの誕生以来の歴史的な価格の概要。ビットコインの歴史的な価格動向を完全にまとめています。
Jan 15, 2025 pm 08:14 PM
暗号通貨としてのビットコインは、その誕生以来、市場の大きな変動を経験してきました。この記事では、読者がビットコインの価格傾向と重要な瞬間を理解できるように、誕生以来のビットコインの歴史的な価格の概要を提供します。ビットコインの過去の価格データを分析することで、その価値に対する市場の評価やその変動に影響を与える要因を理解し、将来の投資決定の基礎を提供することができます。
 ビットコインBTC歴史的価格動向チャートの誕生以来の歴史的価格のリスト(最新の要約)
Feb 11, 2025 pm 11:36 PM
ビットコインBTC歴史的価格動向チャートの誕生以来の歴史的価格のリスト(最新の要約)
Feb 11, 2025 pm 11:36 PM
2009年の作成以来、ビットコインの価格はいくつかの大きな変動を経験し、2021年11月に69,044.77ドルに上昇し、2018年12月に3,191.22ドルに減少しました。 2024年12月の時点で、最新の価格は100,204ドルを超えています。
 2018-2024 USDのビットコインの最新価格
Feb 15, 2025 pm 07:12 PM
2018-2024 USDのビットコインの最新価格
Feb 15, 2025 pm 07:12 PM
リアルタイムのビットコインUSD価格 ビットコインの価格に影響を与える要因 将来のビットコイン価格を予測するための指標 2018年から2024年のビットコインの価格に関する重要な情報を次に示します。
 CSSを介してサイズ変更シンボルをカスタマイズし、背景色で均一にする方法は?
Apr 05, 2025 pm 02:30 PM
CSSを介してサイズ変更シンボルをカスタマイズし、背景色で均一にする方法は?
Apr 05, 2025 pm 02:30 PM
CSSでサイズ変更シンボルをカスタマイズする方法は、背景色で統一されています。毎日の開発では、調整など、ユーザーインターフェイスの詳細をカスタマイズする必要がある状況に遭遇することがよくあります...
 H5ページの生産はフロントエンド開発ですか?
Apr 05, 2025 pm 11:42 PM
H5ページの生産はフロントエンド開発ですか?
Apr 05, 2025 pm 11:42 PM
はい、H5ページの生産は、HTML、CSS、JavaScriptなどのコアテクノロジーを含むフロントエンド開発のための重要な実装方法です。開発者は、< canvas>の使用など、これらのテクノロジーを巧みに組み合わせることにより、動的で強力なH5ページを構築します。グラフィックを描画するタグまたはJavaScriptを使用して相互作用の動作を制御します。
 フレックスレイアウトの下のテキストは省略されていますが、コンテナは開かれていますか?それを解決する方法は?
Apr 05, 2025 pm 11:00 PM
フレックスレイアウトの下のテキストは省略されていますが、コンテナは開かれていますか?それを解決する方法は?
Apr 05, 2025 pm 11:00 PM
フレックスレイアウトとソリューションの下でのテキストの過度の省略によるコンテナの開口部の問題が使用されます...
 CSSのクリップパス属性を使用して、セグメルターの45度曲線効果を実現する方法は?
Apr 04, 2025 pm 11:45 PM
CSSのクリップパス属性を使用して、セグメルターの45度曲線効果を実現する方法は?
Apr 04, 2025 pm 11:45 PM
セグメントターの45度の曲線効果を達成する方法は?セグメンテーションデバイスを実装する過程で、左ボタンをクリックすると、適切な境界線を45度の曲線に変える方法とポイント...
